Il modello di rilevamento di oggetti può identificare e localizzare più di 500 tipi di oggetti in un video. Il modello accetta uno stream video come input e genera un buffer di protocollo con i risultati del rilevamento in BigQuery. Il modello viene eseguito a un FPS. Quando crei un'app che utilizza il modello di rilevamento degli oggetti, devi indirizzare l'output del modello a un connettore BigQuery per visualizzare l'output della previsione.
Specifiche dell'app del modello di rilevamento di oggetti
Segui le istruzioni riportate di seguito per creare un modello di rilevamento di oggetti nella Google Cloud console.
Console
Creare un'app nella Google Cloud console
Per creare un'app di rilevamento di oggetti, segui le istruzioni riportate in Creare un'applicazione.
Aggiungere un modello di rilevamento di oggetti
- Quando aggiungi i nodi del modello, seleziona Rilevamento di oggetti dall'elenco dei modelli preaddestrati.
Aggiungere un connettore BigQuery
Per utilizzare l'output, collega l'app a un connettore BigQuery.
Per informazioni sull'utilizzo del connettore BigQuery, consulta Connetti e archivia i dati in BigQuery. Per informazioni sui prezzi di BigQuery, consulta la pagina Prezzi di BigQuery.
Visualizzare i risultati dell'output in BigQuery
Dopo che il modello ha generato i dati in BigQuery, visualizza le annotazioni di output nella dashboard di BigQuery.
Se non hai specificato un percorso BigQuery, puoi visualizzare il percorso creato dal sistema nella pagina Studio di Vertex AI Vision.
Nella console Google Cloud , apri la pagina BigQuery.
Seleziona Espandi accanto al progetto di destinazione, al nome del set di dati e al nome dell'applicazione.
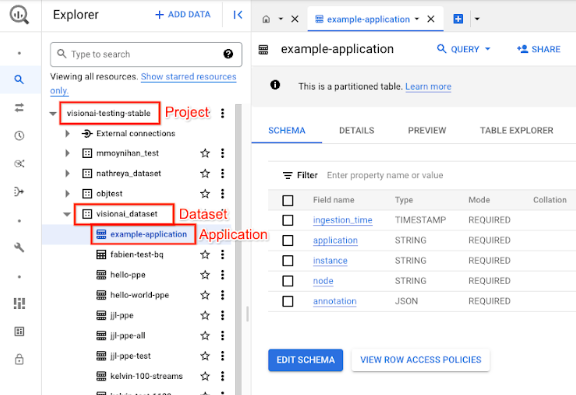
Nella visualizzazione dei dettagli della tabella, fai clic su Anteprima. Visualizza i risultati nella colonna annotazione. Per una descrizione del formato di output, consulta Output del modello.
L'applicazione memorizza i risultati in ordine cronologico. I risultati più antichi sono all'inizio della tabella, mentre quelli più recenti vengono aggiunti alla fine. Per controllare i risultati più recenti, fai clic sul numero di pagina per andare all'ultima pagina della tabella.
Output del modello
Il modello genera riquadri di delimitazione, le relative etichette degli oggetti e i punteggi di affidabilità per ogni fotogramma video. L'output contiene anche un timestamp. La frequenza dello stream di output è di un frame al secondo.
Nell'esempio di output del buffer del protocollo che segue, tieni presente quanto segue:
- Timestamp: il timestamp corrisponde all'ora di questo risultato di inferenza.
- Caselle identificate: il risultato principale del rilevamento che include l'identità della casella, informazioni sul riquadro delimitante, punteggio di attendibilità e previsione dell'oggetto.
Oggetto JSON di output dell'annotazione di esempio
{
"currentTime": "2022-11-09T02:18:54.777154048Z",
"identifiedBoxes": [
{
"boxId":"0",
"normalizedBoundingBox": {
"xmin": 0.6963465,
"ymin": 0.23144785,
"width": 0.23944569,
"height": 0.3544306
},
"confidenceScore": 0.49874997,
"entity": {
"labelId": "0",
"labelString": "Houseplant"
}
}
]
}
Definizione del buffer di protocollo
// The prediction result protocol buffer for object detection
message ObjectDetectionPredictionResult {
// Current timestamp
protobuf.Timestamp timestamp = 1;
// The entity information for annotations from object detection prediction
// results
message Entity {
// Label id
int64 label_id = 1;
// The human-readable label string
string label_string = 2;
}
// The identified box contains the location and the entity of the object
message IdentifiedBox {
// An unique id for this box
int64 box_id = 1;
// Bounding Box in normalized coordinates [0,1]
message NormalizedBoundingBox {
// Min in x coordinate
float xmin = 1;
// Min in y coordinate
float ymin = 2;
// Width of the bounding box
float width = 3;
// Height of the bounding box
float height = 4;
}
// Bounding Box in the normalized coordinates
NormalizedBoundingBox normalized_bounding_box = 2;
// Confidence score associated with this bounding box
float confidence_score = 3;
// Entity of this box
Entity entity = 4;
}
// A list of identified boxes
repeated IdentifiedBox identified_boxes = 2;
}
Best practice e limitazioni
Per ottenere i risultati migliori quando utilizzi il rilevatore di oggetti, tieni presente quanto segue quando ottieni i dati e utilizzi il modello.
Consigli per i dati di origine
Consigliato: assicurati che gli oggetti nella fotografia siano nitidi e non siano coperti o oscurati in gran parte da altri oggetti.
Dati di immagini di esempio che il rilevatore di oggetti è in grado di elaborare correttamente:

|
L'invio al modello di questi dati immagine restituisce le seguenti informazioni sul rilevamento degli oggetti*:
* Le annotazioni nell'immagine seguente sono solo a scopo illustrativo. I riquadri di delimitazione, le etichette e i punteggi di affidabilità vengono disegnati manualmente e non aggiunti dal modello o da alcun Google Cloud strumento della console.

Non consigliato:evita i dati delle immagini in cui gli elementi dell'oggetto principale sono troppo piccoli nell'inquadratura.
Dati di immagini di esempio che il rilevatore di oggetti non è in grado di elaborare correttamente:

|
Non consigliato: evita i dati delle immagini che mostrano gli elementi chiave degli oggetti parzialmente o completamente coperti da altri oggetti.
Dati di immagini di esempio che il rilevatore di oggetti non è in grado di elaborare correttamente:

|
Limitazioni
- Risoluzione video: la risoluzione video di input massima consigliata è 1920 x 1080 e la risoluzione minima consigliata è 160 x 120.
- Illuminazione: le prestazioni del modello sono sensibili alle condizioni di illuminazione. Luminosità o oscurità estreme potrebbero comportare una qualità di rilevamento inferiore.
- Dimensioni dell'oggetto: il rilevatore di oggetti ha una dimensione minima dell'oggetto rilevabile. Assicurati che gli oggetti target siano sufficientemente grandi e visibili nei dati video.