El modelo de detector de objetos puede identificar y localizar más de 500 tipos de objetos en un vídeo. El modelo acepta un flujo de vídeo como entrada y genera un protocol buffer con los resultados de la detección en BigQuery. El modelo se ejecuta a un FPS. Cuando creas una aplicación que usa el modelo de detector de objetos, debes dirigir la salida del modelo a un conector de BigQuery para ver el resultado de la predicción.
Especificaciones de la aplicación del modelo de detector de objetos
Sigue estas instrucciones para crear un modelo de detector de objetos en la consola deGoogle Cloud .
Consola
Crear una aplicación en la Google Cloud consola
Para crear una aplicación de detección de objetos, sigue las instrucciones que se indican en Crear una aplicación.
Añadir un modelo de detector de objetos
- Cuando añadas nodos de modelo, selecciona Detector de objetos en la lista de modelos preentrenados.
Añadir un conector de BigQuery
Para usar la salida, conecta la aplicación a un conector de BigQuery.
Para obtener información sobre cómo usar el conector BigQuery, consulta el artículo Conectar y almacenar datos con BigQuery. Para obtener información sobre los precios de BigQuery, consulta la página Precios de BigQuery.
Ver los resultados en BigQuery
Una vez que el modelo haya enviado los datos a BigQuery, consulta las anotaciones de salida en el panel de control de BigQuery.
Si no has especificado una ruta de BigQuery, puedes ver la ruta creada por el sistema en la página Studio de Vertex AI Vision.
En la Google Cloud consola, abre la página de BigQuery.
Selecciona Expand (Ampliar) junto al proyecto de destino, el nombre del conjunto de datos y el nombre de la aplicación.
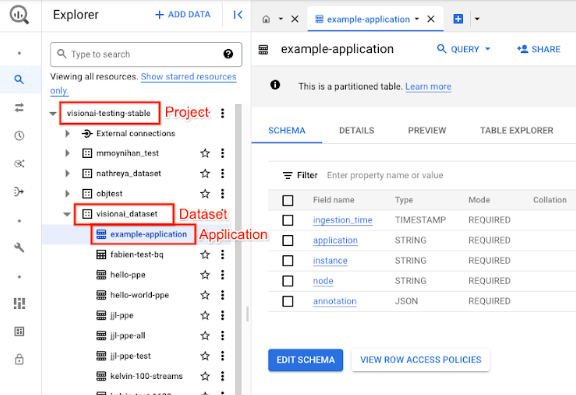
En la vista de detalles de la tabla, haga clic en Vista previa. Consulte los resultados en la columna Anotación. Para ver una descripción del formato de salida, consulta Salida del modelo.
La aplicación almacena los resultados en orden cronológico. Los resultados más antiguos se encuentran al principio de la tabla, mientras que los más recientes se añaden al final. Para consultar los resultados más recientes, haz clic en el número de página para ir a la última página de la tabla.
Salida del modelo
El modelo genera cuadros delimitadores, las etiquetas de los objetos y las puntuaciones de confianza de cada fotograma del vídeo. El resultado también contiene una marca de tiempo. La velocidad del flujo de salida es de un fotograma por segundo.
En el ejemplo de salida de protocol buffer que se muestra a continuación, ten en cuenta lo siguiente:
- Marca de tiempo: la marca de tiempo corresponde a la hora de este resultado de inferencia.
- Recuadros identificados: el resultado de detección principal que incluye la identidad del recuadro, información del recuadro delimitador, puntuación de confianza y predicción del objeto.
Objeto JSON de salida de anotación de muestra
{
"currentTime": "2022-11-09T02:18:54.777154048Z",
"identifiedBoxes": [
{
"boxId":"0",
"normalizedBoundingBox": {
"xmin": 0.6963465,
"ymin": 0.23144785,
"width": 0.23944569,
"height": 0.3544306
},
"confidenceScore": 0.49874997,
"entity": {
"labelId": "0",
"labelString": "Houseplant"
}
}
]
}
Definición de búfer de protocolo
// The prediction result protocol buffer for object detection
message ObjectDetectionPredictionResult {
// Current timestamp
protobuf.Timestamp timestamp = 1;
// The entity information for annotations from object detection prediction
// results
message Entity {
// Label id
int64 label_id = 1;
// The human-readable label string
string label_string = 2;
}
// The identified box contains the location and the entity of the object
message IdentifiedBox {
// An unique id for this box
int64 box_id = 1;
// Bounding Box in normalized coordinates [0,1]
message NormalizedBoundingBox {
// Min in x coordinate
float xmin = 1;
// Min in y coordinate
float ymin = 2;
// Width of the bounding box
float width = 3;
// Height of the bounding box
float height = 4;
}
// Bounding Box in the normalized coordinates
NormalizedBoundingBox normalized_bounding_box = 2;
// Confidence score associated with this bounding box
float confidence_score = 3;
// Entity of this box
Entity entity = 4;
}
// A list of identified boxes
repeated IdentifiedBox identified_boxes = 2;
}
Prácticas recomendadas y limitaciones
Para obtener los mejores resultados al usar el detector de objetos, tenga en cuenta lo siguiente al obtener datos y usar el modelo.
Recomendaciones de datos de origen
Recomendación: Asegúrate de que los objetos de la imagen se vean bien y no estén cubiertos ni ocultos en gran medida por otros objetos.
Datos de imagen de muestra que el detector de objetos puede procesar correctamente:

|
Si se envían estos datos de imagen al modelo, se devuelve la siguiente información de detección de objetos:*
* Las anotaciones de la siguiente imagen se muestran solo con fines ilustrativos. Los cuadros delimitadores, las etiquetas y las puntuaciones de confianza se dibujan manualmente y no los añade el modelo ni ninguna herramienta de la consola. Google Cloud

No recomendado: evita los datos de imagen en los que los elementos clave del objeto sean demasiado pequeños en el encuadre.
Datos de imagen de muestra que el detector de objetos no puede procesar correctamente:

|
No se recomienda: evite los datos de imagen que muestren los elementos clave del objeto parcial o totalmente cubiertos por otros objetos.
Datos de imagen de muestra que el detector de objetos no puede procesar correctamente:

|
Limitaciones
- Resolución de vídeo: la resolución de vídeo de entrada máxima recomendada es 1920x1080, y la mínima recomendada es 160x120.
- Iluminación: el rendimiento del modelo depende de las condiciones de iluminación. Si la imagen es demasiado brillante u oscura, la calidad de la detección puede ser menor.
- Tamaño del objeto: el detector de objetos tiene un tamaño mínimo de objeto detectable. Asegúrate de que los objetos de destino sean lo suficientemente grandes y visibles en los datos de vídeo.