Después de crear el flujo de ingestión de datos y añadir los nodos de procesamiento a tu aplicación, debes elegir dónde enviar los datos procesados. Una opción es recibir directamente la salida de la aplicación de emisión en directo para poder tomar medidas en función de estas analíticas en tiempo real.
Por lo general, se configura la aplicación para que almacene las respuestas del modelo en un
Google Cloud almacén de datos, como Media Warehouse de Vertex AI Vision o BigQuery.
Una vez que los datos se almacenan en uno de estos almacenes, se pueden usar para tareas analíticas offline basadas en el gráfico de tu aplicación. Sin embargo, también puedes recibir los resultados del modelo
en tiempo real. Puedes hacer que Vertex AI Vision reenvíe las salidas del modelo a un recurso de flujo y usar la herramienta de línea de comandos (vaictl) o la API de Vertex AI Vision para consumirlas en tiempo real.
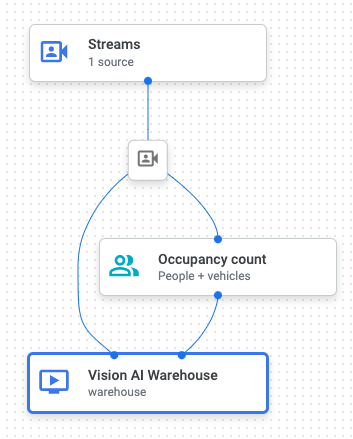
Supongamos que tienes el siguiente gráfico de aplicación con estos tres nodos:
- El nodo de fuente de datos "Input Stream" (
input-stream) - El nodo de procesamiento "Recuento de ocupación" (
occupancy-count) - El nodo de destino de la salida de la aplicación "Media Warehouse" (
warehouse)
Actualmente, la salida de la aplicación se envía desde el flujo al proceso de recuento de ocupación y, después, a Media Warehouse de Vertex AI Vision, donde se almacena.
Configuración de la aplicación de la API:
|
{
"applicationConfigs": {
"nodes": [
{
"displayName": "Input Stream",
"name": "input-stream",
"processor": "builtin:stream-input"
},
{
"displayName": "Occupancy Count",
"name": "occupancy-count",
"nodeConfig": {
"occupancyCountConfig": {
"enablePeopleCounting": true,
"enableVehicleCounting": true
}
},
"parents": [
{
"parentNode": "input-stream"
}
],
"processor": "builtin:occupancy-count"
},
{
"displayName": "Media Warehouse",
"name": "warehouse",
"nodeConfig": {
"mediaWarehouseConfig": {
"corpus": "projects/PROJECT_ID/locations/LOCATION_ID/corpora/CORPUS_ID",
"ttl": "86400s"
}
},
"parents": [
{
"parentNode": "input-stream"
},
{
"parentNode": "occupancy-count"
}
],
"processor": "builtin:media-warehouse"
}
]
}
} |
Habilitar la salida de la emisión (consolaGoogle Cloud )
Puedes habilitar la salida de la emisión en la Google Cloud consola cuando implementes tu modelo por primera vez o cuando lo desactives y lo vuelvas a activar.
Consola
Abre la pestaña Aplicaciones del panel de control de Vertex AI Vision.
Selecciona Ver gráfico junto al nombre de tu aplicación en la lista.
En la página del creador de gráficos de aplicaciones, haz clic en el botón Implementar.
En el menú de opciones Implementar aplicación que se abre, selecciona Habilitar streaming de salida.
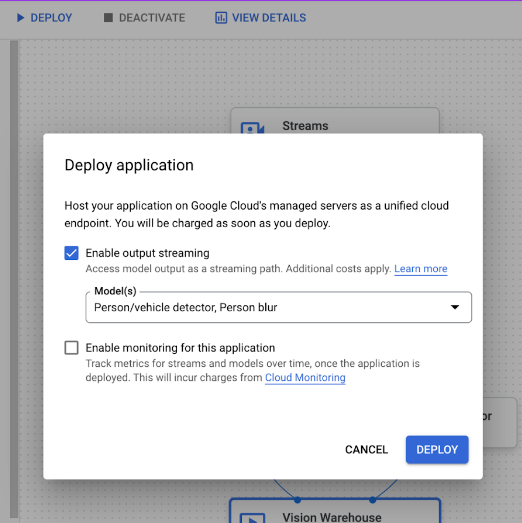
En el menú desplegable Modelos correspondiente, selecciona los modelos para los que quieras habilitar la salida de streaming.
Haz clic en Desplegar.
Habilitar la salida de la emisión (API)
Actualizar el nodo de la aplicación
Puedes actualizar la configuración de una aplicación en la línea de comandos para que un nodo de modelo envíe específicamente la salida a un flujo.
Una vez que haya completado este paso, podrá actualizar la instancia de la aplicación para especificar el recurso de flujo que recibe los datos de salida del nodo de análisis.
REST
En este ejemplo se usa el método projects.locations.applications.patch. Esta solicitud actualiza la configuración de la aplicación de la API del ejemplo anterior para que el nodo occupancy-count envíe anotaciones de salida a un flujo de Vertex AI Vision. Este comportamiento se habilita mediante el campo output_all_output_channels_to_stream.
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- PROJECT: tu Google Cloud ID de proyecto o número de proyecto.
- LOCATION_ID: la región en la que usas Vertex AI Vision. Por ejemplo:
us-central1,europe-west4. Consulta las regiones disponibles. - APPLICATION_ID: ID de la aplicación de destino.
Método HTTP y URL:
PATCH https://visionai.googleapis.com/v1/projects/PROJECT_NUMBER/locations/LOCATION_ID/applications/APPLICATION_ID
Cuerpo JSON de la solicitud:
{
"applicationConfigs": {
"nodes": [
{
"displayName": "Input Stream",
"name": "input-stream",
"processor": "builtin:stream-input"
},
{
"displayName": "Occupancy Count",
"name": "occupancy-count",
"nodeConfig": {
"occupancyCountConfig": {
"enablePeopleCounting": true,
"enableVehicleCounting": true
}
},
"parents": [
{
"parentNode": "input-stream"
}
],
"processor": "builtin:occupancy-count",
"output_all_output_channels_to_stream": true
}
]
}
}
Para enviar tu solicitud, elige una de estas opciones:
curl
Guarda el cuerpo de la solicitud en un archivo llamado request.json
y ejecuta el siguiente comando:
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://visionai.googleapis.com/v1/projects/PROJECT_NUMBER/locations/LOCATION_ID/applications/APPLICATION_ID"
PowerShell
Guarda el cuerpo de la solicitud en un archivo llamado request.json
y ejecuta el siguiente comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method PATCH `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://visionai.googleapis.com/v1/projects/PROJECT_NUMBER/locations/LOCATION_ID/applications/APPLICATION_ID" | Select-Object -Expand Content
200 OK sin ningún error y el servicio actualiza el recurso de aplicación en consecuencia.
Actualizar la instancia de la aplicación
En el ejemplo anterior se muestra cómo actualizar la aplicación, lo que permite que el nodo de destino envíe la salida a un flujo. Después de habilitar esta opción, puede actualizar la instancia de la aplicación para especificar el recurso de flujo que recibe los datos de salida del nodo de análisis.
Si no especificas un flujo con este comando, la plataforma de la aplicación seguirá usando un flujo predeterminado que se crea cuando se implementa el nodo de la aplicación.
Debes crear un recurso de flujo al que el nodo envíe la salida.
antes de enviar la siguiente solicitud.
REST
En este ejemplo se usa el método
projects.locations.applications.updateApplicationInstances. Esta solicitud usa la configuración de la aplicación de la API actualizada de la aplicación de ejemplo anterior. El comando de actualización anterior configuró el nodo occupancy-count para que pudiera enviar anotaciones de salida a un flujo de Vertex AI Vision. Este comando actualiza la instancia de la aplicación para enviar los datos de ese nodo de productor occupancy-count a un recurso de flujo ya creado.
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- PROJECT: tu Google Cloud ID de proyecto o número de proyecto.
- LOCATION_ID: la región en la que usas Vertex AI Vision. Por ejemplo:
us-central1,europe-west4. Consulta las regiones disponibles. - APPLICATION_ID: ID de la aplicación de destino.
inputResources: el recurso o los recursos de entrada de la instancia actual de la aplicación. Es una matriz de objetos que contiene los siguientes campos:consumerNode: El nombre del nodo del gráfico que recibe el recurso de entrada.inputResource: nombre completo del recurso de entrada.
outputResources.outputResource: el recursostreamal que se enviarán los datos de la aplicación.outputResources.producerNode: nombre del nodo productor de salida de la aplicación. En este ejemplo, este es el nodo de análisis,occupancy-count.- INSTANCE_ID: ID de la instancia de la aplicación.
Método HTTP y URL:
POST https://visionai.googleapis.com/v1/projects/PROJECT_NUMBER/locations/LOCATION_ID/applications/APPLICATION_ID:updateApplicationInstances
Cuerpo JSON de la solicitud:
{
"applicationInstances": [
{
"instance": {
"inputResources": [
{
"consumerNode": "input-stream",
"inputResource": "projects/PROJECT_NUMBER/locations/LOCATION_ID/clusters/application-cluster-0/streams/INPUT_STREAM_ID"
}
],
"outputResources":[
{
"outputResource": "projects/PROJECT_NUMBER/locations/LOCATION_ID/clusters/application-cluster-0/streams/OUTPUT_STREAM_ID",
"producerNode": "occupancy-count"
}
]
},
"instanceId": INSTANCE_ID
}
]
}
Para enviar tu solicitud, elige una de estas opciones:
curl
Guarda el cuerpo de la solicitud en un archivo llamado request.json
y ejecuta el siguiente comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://visionai.googleapis.com/v1/projects/PROJECT_NUMBER/locations/LOCATION_ID/applications/APPLICATION_ID:updateApplicationInstances"
PowerShell
Guarda el cuerpo de la solicitud en un archivo llamado request.json
y ejecuta el siguiente comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://visionai.googleapis.com/v1/projects/PROJECT_NUMBER/locations/LOCATION_ID/applications/APPLICATION_ID:updateApplicationInstances" | Select-Object -Expand Content
200 OK sin ningún error y el servicio actualiza la instancia de la aplicación en consecuencia.