Vertex AI Vision アプリに BigQuery コネクタを追加すると、接続されたアプリモデルの出力がすべてターゲット テーブルに取り込まれます。
独自の BigQuery テーブルを作成して、BigQuery コネクタをアプリに追加するときにそのテーブルを指定するか、Vertex AI Vision アプリ プラットフォームにテーブルを自動的に作成させることができます。
テーブルの自動作成
Vertex AI Vision アプリ プラットフォームにテーブルの自動作成を許可する場合は、BigQuery コネクタ ノードを追加するときにこのオプションを指定できます。
テーブルの自動作成を使用する場合は、次のデータセットとテーブルの条件が適用されます。
- データセット: 自動作成されたデータセット名は
visionai_datasetです。 - テーブル: 自動作成されたテーブル名は
visionai_dataset.APPLICATION_IDです。 エラー処理:
- 同じデータセットに同じ名前のテーブルが存在する場合、自動作成は行われません。
Console
Vertex AI Vision ダッシュボードの [アプリケーション] タブを開きます。
リストからアプリケーション名の横にある [アプリを表示] を選択します。
アプリケーション ビルダー ページの [コネクタ] セクションで [BigQuery] を選択します。
[BigQuery パス] フィールドは空白のままにします。
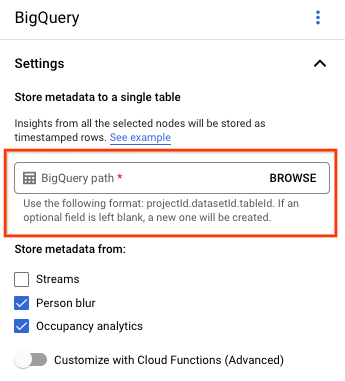
その他の設定を変更します。
REST とコマンドライン
アプリ プラットフォームにテーブル スキーマを推測させるには、アプリの作成または更新時に BigQueryConfig の createDefaultTableIfNotExists フィールドを使用します。
テーブルを手動で作成して指定する
出力テーブルを手動で管理する場合は、テーブル スキーマのサブセットとして必要なスキーマをテーブルに指定する必要があります。
既存のテーブルに互換性のないスキーマがある場合、デプロイは拒否されます。
デフォルトのスキーマを使用する
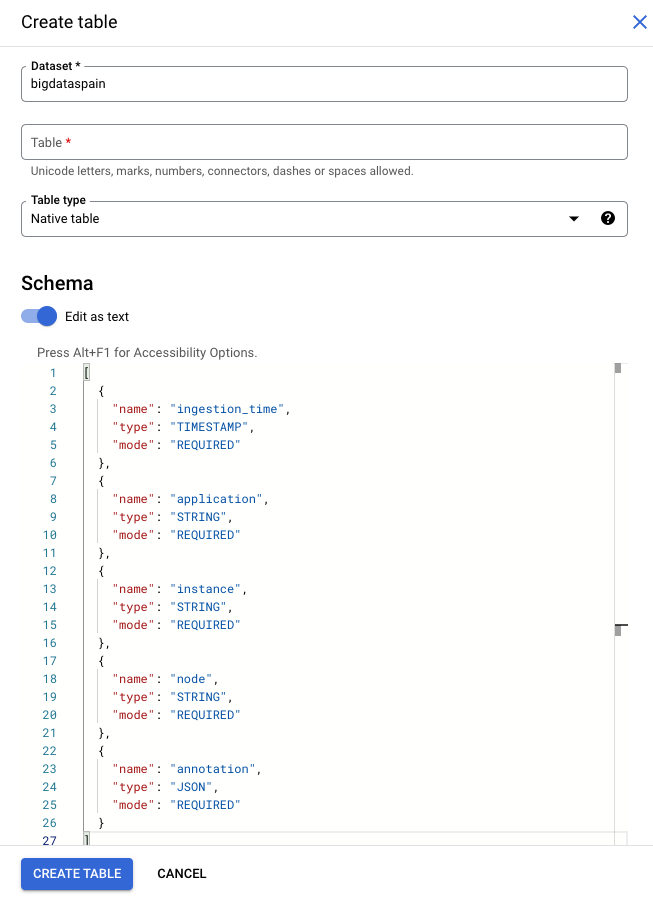
モデル出力テーブルにデフォルト スキーマを使用する場合は、テーブルに次の必須列のみが含まれていることを確認してください。BigQuery テーブルを作成するときに、次のスキーマテキストを直接コピーできます。BigQuery テーブルの作成の詳細については、テーブルの作成と使用をご覧ください。テーブルの作成時にスキーマを指定する方法については、スキーマの指定をご覧ください。
テーブルを作成するときに、次のテキストを使用してスキーマを記述します。JSON 列型("type": "JSON")の使用方法については、標準 SQL での JSON データの操作をご覧ください。アノテーション クエリには JSON 列型をおすすめします。"type" : "STRING" を使用することもできます。
[
{
"name": "ingestion_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "application",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "instance",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "node",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "annotation",
"type": "JSON",
"mode": "REQUIRED"
}
]
Google Cloud コンソール
Google Cloud コンソールで、[BigQuery] ページに移動します。
プロジェクトを選択します。
その他アイコン を選択します。
[テーブルを作成] をクリックします。
[スキーマ] セクションで、[テキストとして編集] を有効にします。
gcloud
次の例では、まずリクエスト JSON ファイルを作成してから、gcloud alpha bq tables create コマンドを使用します。
まず、リクエスト JSON ファイルを作成します。
echo "{ \"schema\": [ { \"name\": \"ingestion_time\", \"type\": \"TIMESTAMP\", \"mode\": \"REQUIRED\" }, { \"name\": \"application\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"instance\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"node\", \"type\": \"STRING\", \"mode\": \"REQUIRED\" }, { \"name\": \"annotation\", \"type\": \"JSON\", \"mode\": \"REQUIRED\" } ] } " >> bigquery_schema.jsongcloudコマンドを送信します。次のように置き換えます。TABLE_NAME: テーブルの ID またはテーブルの完全修飾識別子。
DATASET: BigQuery データセットの ID。
gcloud alpha bq tables create TABLE_NAME \ --dataset=DATASET \ --schema-file=./bigquery_schema.json
Vertex AI Vision アプリによって生成された BigQuery 行の例:
| ingestion_time | アプリケーション | インスタンス | ノード | アノテーション |
|---|---|---|---|---|
| 2022-05-11 23:3211.911378 UTC | my_application | 5 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE1Eg5teV9hcHBsaWNhdGlvbgjS+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3211.911338 UTC | my_application | 1 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgExEg5teV9hcHBsaWNhdGlvbgiq+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3211.911313 UTC | my_application | 4 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE0Eg5teV9hcHBsaWNhdGlvbgiR+YnOzdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
| 2022-05-11 23:3212.235327 UTC | my_application | 4 | just-one-node | {"bytesFields": ["Ig1qdXN0LW9uZS1ub2RIGgE0Eg5teV9hcHBsaWNhdGlvbgi/3J3Ozdj3Ag=="],"displayNames":["hello","world"],"ids":["12345","34567"]} |
カスタマイズされたスキーマを使用する
デフォルトのスキーマがユースケースに適していない場合は、Cloud Run 関数を使用して、ユーザー定義スキーマを持つ BigQuery 行を生成できます。カスタム スキーマを使用する場合、BigQuery テーブル スキーマの前提条件はありません。
BigQuery ノードが選択されたアプリグラフ
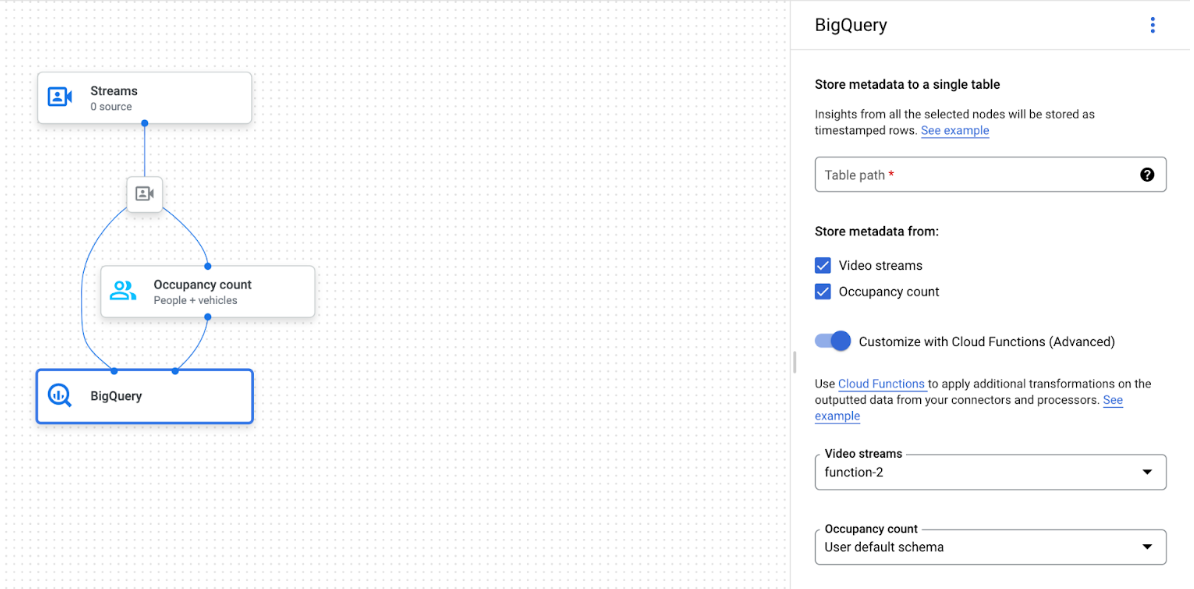
BigQuery コネクタは、動画またはプロトコルベースのアノテーションを出力する任意のモデルに接続できます。
- 動画入力の場合、BigQuery コネクタは、ストリーム ヘッダーに保存されているメタデータのみを抽出し、このデータを他のモデル アノテーション出力として BigQuery に取り込みます。動画自体は保存されません。
- ストリームにメタデータが含まれていない場合、BigQuery に何も保存されません。
テーブルデータをクエリする
デフォルトの BigQuery テーブル スキーマを使用すると、テーブルにデータが入力された後に強力な分析を実行できます。
サンプルクエリ
BigQuery で次のサンプルクエリを使用すると、Vertex AI Vision モデルから分析情報を取得できます。
たとえば、BigQuery を使用して、次のクエリで 人物 / 車両検出モデルのデータを使用して、1 分あたりの検出された人物の最大数の時間ベースの曲線を描画できます。
WITH nested3 AS( WITH nested2 AS ( WITH nested AS ( SELECT t.ingestion_time AS ingestion_time, JSON_QUERY_ARRAY(t.annotation.stats["fullFrameCount"]) AS counts FROM `PROJECT_ID.DATASET_NAME.TABLE_NAME` AS t) SELECT ingestion_time, e FROM nested, UNNEST(nested.counts) AS e) SELECT STRING(TIMESTAMP_TRUNC(nested2.ingestion_time, MINUTE, "America/Los_Angeles"),"America/Los_Angeles") AS time, IFNULL(INT64(nested2.e["count"]), 0) AS person_count FROM nested2 WHERE JSON_VALUE(nested2.e["entity"]["labelString"])="Person") SELECT time, MAX(person_count) FROM nested3 GROUP BY time
同様に、BigQuery と占有率分析モデルの交差点ライン数機能を使用して、交差点ラインを通過する車両の合計数を 1 分あたりでカウントするクエリを作成できます。
WITH nested4 AS ( WITH nested3 AS ( WITH nested2 AS ( WITH nested AS ( SELECT t.ingestion_time AS ingestion_time, JSON_QUERY_ARRAY(t.annotation.stats["crossingLineCounts"]) AS lines FROM `PROJECT_ID.DATASET_NAME.TABLE_NAME` AS t) SELECT nested.ingestion_time, JSON_QUERY_ARRAY(line["positiveDirectionCounts"]) AS entities FROM nested, UNNEST(nested.lines) AS line WHERE JSON_VALUE(line.annotation.id) = "LINE_ANNOTATION_ID") SELECT ingestion_time, entity FROM nested2, UNNEST(nested2.entities) AS entity ) SELECT STRING(TIMESTAMP_TRUNC(nested3.ingestion_time, MINUTE, "America/Los_Angeles"),"America/Los_Angeles") AS time, IFNULL(INT64(nested3.entity["count"]), 0) AS vehicle_count FROM nested3 WHERE JSON_VALUE(nested3.entity["entity"]["labelString"])="Vehicle" ) SELECT time, SUM(vehicle_count) FROM nested4 GROUP BY time
クエリを実行する
Google 標準 SQL クエリをフォーマットしたら、コンソールを使用してクエリを実行できます。
コンソール
Google Cloud コンソールで、[BigQuery] ページを開きます。
データセット名の横にある [展開] を選択し、テーブル名を選択します。
テーブルの詳細ビューで、[クエリを新規作成] をクリックします。

[クエリエディタ] のテキスト領域に、Google 標準 SQL クエリを入力します。クエリの例については、サンプルクエリをご覧ください。
省略可: データを処理するロケーションを変更するには、[展開]、[クエリの設定] の順にクリックします。[処理を行うロケーション] で [自動選択] をクリックし、データのロケーションを選択します。最後に [保存] をクリックしてクエリの設定を更新します。
[実行] をクリックします。
これにより、出力を一時テーブルに書き込むクエリジョブが作成されます。
Cloud Run functions の統合
カスタマイズされた BigQuery 取り込みで追加のデータ処理をトリガーするには、Cloud Run 関数を使用します。カスタマイズされた BigQuery 取り込みに Cloud Run functions 関数を使用する手順は次のとおりです。
Google Cloud コンソールを使用する場合は、接続されている各モデルのプルダウン メニューから対応する Cloud Functions の関数を選択します。
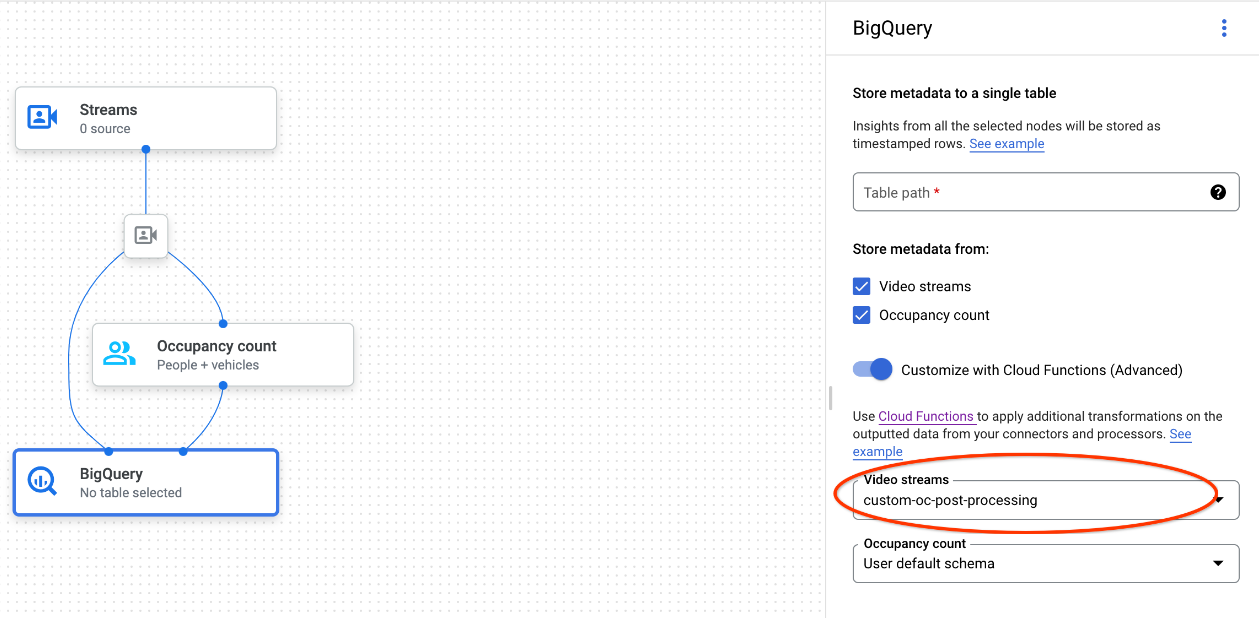
Vertex AI Vision API を使用する場合は、BigQuery ノードの
BigQueryConfigのcloud_function_mappingフィールドに Key-Value ペアを 1 つ追加します。キーは BigQuery ノード名で、値はターゲット関数の HTTP トリガーです。
カスタマイズされた BigQuery 取り込みで Cloud Run functions を使用するには、関数が次の要件を満たしている必要があります。
- BigQuery ノードを作成する前に、Cloud Run functions インスタンスを作成する必要があります。
- Vertex AI Vision API は、Cloud Run functions から返された
AppendRowsRequestアノテーションを受け取ることを想定しています。 - すべての
CloudFunctionレスポンスでproto_rows.writer_schemaフィールドを設定する必要があります。write_streamは無視できます。
Cloud Run functions の統合例
次の例は、占有人数ノード出力(OccupancyCountPredictionResult)を解析し、そこから ingestion_time、person_count、vehicle_count テーブル スキーマを抽出する方法を示しています。
次のサンプルの結果は、次のスキーマを持つ BigQuery テーブルです。
[
{
"name": "ingestion_time",
"type": "TIMESTAMP",
"mode": "REQUIRED"
},
{
"name": "person_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "vehicle_count",
"type": "INTEGER",
"mode": "NULLABLE"
},
]
次のコードを使用してテーブルを作成します。
書き込むテーブル フィールドのプロト(
test_table_schema.protoなど)を定義します。syntax = "proto3"; package visionai.testing; message TestTableSchema { int64 ingestion_time = 1; int32 person_count = 2; int32 vehicle_count = 3; }proto ファイルをコンパイルして、プロトコル バッファの Python ファイルを生成します。
protoc -I=./ --python_out=./ ./test_table_schema.proto生成された Python ファイルをインポートして、Cloud Functions 関数を作成します。
Python
import base64 import sys from flask import jsonify import functions_framework from google.protobuf import descriptor_pb2 from google.protobuf.json_format import MessageToDict import test_table_schema_pb2 def table_schema(): schema = descriptor_pb2.DescriptorProto() test_table_schema_pb2.DESCRIPTOR.message_types_by_name[ 'TestTableSchema'].CopyToProto(schema) return schema def bigquery_append_row_request(row): append_row_request = {} append_row_request['protoRows'] = { 'writerSchema': { 'protoDescriptor': MessageToDict(table_schema()) }, 'rows': { 'serializedRows': base64.b64encode(row.SerializeToString()).decode('utf-8') } } return append_row_request @functions_framework.http def hello_http(request): request_json = request.get_json(silent=False) annotations = [] payloads = [] if request_json and 'annotations' in request_json: for annotation_with_timestamp in request_json['annotations']: row = test_table_schema_pb2.TestTableSchema() row.person_count = 0 row.vehicle_count = 0 if 'ingestionTimeMicros' in annotation_with_timestamp: row.ingestion_time = int( annotation_with_timestamp['ingestionTimeMicros']) if 'annotation' in annotation_with_timestamp: annotation = annotation_with_timestamp['annotation'] if 'stats' in annotation: stats = annotation['stats'] for count in stats['fullFrameCount']: if count['entity']['labelString'] == 'Person': if 'count' in count: row.person_count = count['count'] elif count['entity']['labelString'] == 'Vehicle': if 'count' in count: row.vehicle_count = count['count'] payloads.append(bigquery_append_row_request(row)) for payload in payloads: annotations.append({'annotation': payload}) return jsonify(annotations=annotations)
Cloud Run functions に依存関係を含めるには、生成された
test_table_schema_pb2.pyファイルをアップロードし、次のようにrequirements.txtを指定する必要があります。functions-framework==3.* click==7.1.2 cloudevents==1.2.0 deprecation==2.1.0 Flask==1.1.2 gunicorn==20.0.4 itsdangerous==1.1.0 Jinja2==2.11.2 MarkupSafe==1.1.1 pathtools==0.1.2 watchdog==1.0.2 Werkzeug==1.0.1 protobuf==3.12.2Cloud Functions の関数をデプロイし、
BigQueryConfigで対応する HTTP トリガーを設定します。