Vertex AI Agent Engine, parte di Vertex AI Platform, è un insieme di servizi che consente agli sviluppatori di distribuire, gestire e scalare gli agenti AI in produzione. Agent Engine gestisce l'infrastruttura per scalare gli agenti in produzione, così da potersi concentrare sulla creazione di applicazioni. Vertex AI Agent Engine offre i seguenti servizi che puoi utilizzare singolarmente o in combinazione:
Runtime:
- Esegui il deployment e scala gli agenti con un runtime gestito e funzionalità di gestione end-to-end.
- Personalizza l'immagine container dell'agente con script di installazione in fase di compilazione per le dipendenze di sistema.
- Utilizza le funzionalità di sicurezza, tra cui la conformità a VPC-SC e la configurazione dell'autenticazione e di IAM.
- Accedi a modelli e strumenti come la chiamata di funzione.
- Esegui il deployment di agenti creati utilizzando diversi framework Python e il protocollo aperto Agent2Agent.
- Comprendi il comportamento dell'agente con Google Cloud Trace (che supporta OpenTelemetry), Cloud Monitoring e Cloud Logging.
Qualità e valutazione (anteprima): valuta la qualità dell'agente con il servizio di valutazione dell'AI generativa integrato e ottimizza gli agenti con le esecuzioni di addestramento del modello Gemini.
Example Store (anteprima): archivia e recupera in modo dinamico esempi few-shot per migliorare il rendimento dell'agente.
Sessioni (anteprima): le sessioni di Agent Engine consentono di archiviare le singole interazioni tra utenti e agenti, fornendo fonti definitive per il contesto della conversazione.
Memory Bank (anteprima): Memory Bank di Agent Engine ti consente di archiviare e recuperare informazioni dalle sessioni per personalizzare le interazioni dell'agente.
Esecuzione del codice (Anteprima): l'esecuzione del codice di Agent Engine consente all'agente di eseguire il codice in un ambiente sandbox sicuro, isolato e gestito.

Vertex AI Agent Engine fa parte di Vertex AI Agent Builder, una suite di funzionalità per il rilevamento, la creazione e l'implementazione di agenti AI.
Crea ed esegui il deployment su Vertex AI Agent Engine
Nota:per un'esperienza di sviluppo e deployment basata su IDE semplificata con Vertex AI Agent Engine, valuta la possibilità di utilizzare l'agent-starter-pack. Fornisce modelli pronti all'uso, un'interfaccia utente integrata per la sperimentazione e semplifica il deployment, le operazioni, la valutazione, la personalizzazione e l'osservabilità.
Il flusso di lavoro per la creazione di un agente su Vertex AI Agent Engine è il seguente:
| Passaggi | Descrizione |
|---|---|
| 1. Configura l'ambiente | Configura il tuo progetto Google e installa l'ultima versione dell'SDK Vertex AI per Python. |
| 2. Sviluppare un agente | Sviluppa un agente che può essere implementato su Vertex AI Agent Engine. |
| 3. Esegui il deployment dell'agente | Esegui il deployment dell'agente nel runtime gestito di Vertex AI Agent Engine. |
| 4. Utilizzare l'agente | Esegui query sull'agente inviando una richiesta API. |
| 5. Gestire l'agente di cui è stato eseguito il deployment | Gestisci ed elimina gli agenti di cui hai eseguito il deployment in Vertex AI Agent Engine. |
I passaggi sono illustrati nel seguente diagramma:
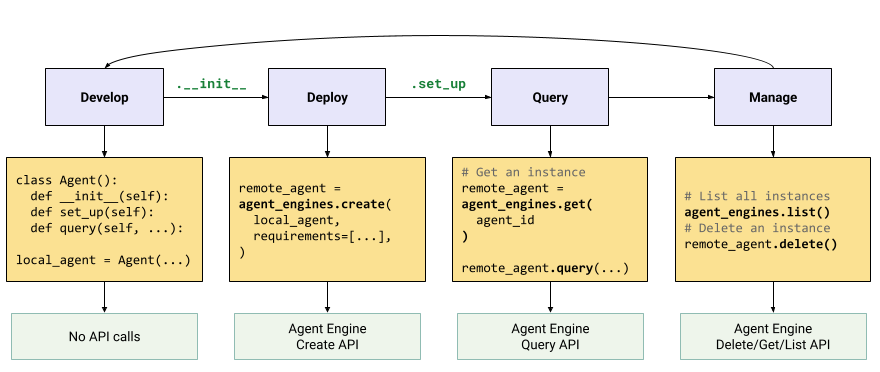
Framework supportati
La tabella seguente descrive il livello di supporto fornito da Vertex AI Agent Engine per vari framework di agenti:
| Livello di assistenza | Framework degli agenti |
|---|---|
| Modello personalizzato: puoi adattare un modello personalizzato per supportare il deployment su Vertex AI Agent Engine dal tuo framework. | CrewAI, framework personalizzati |
| Integrazione dell'SDK Vertex AI: Vertex AI Agent Engine fornisce modelli gestiti per framework nell'SDK Vertex AI e nella documentazione. | AG2, LlamaIndex |
| Integrazione completa: le funzionalità sono integrate per funzionare nel framework, in Vertex AI Agent Engine e nell'ecosistema Google Cloud più ampio. | Agent Development Kit (ADK), LangChain, LangGraph |
Esegui il deployment in produzione con Agent Starter Pack
L'Agent Starter Pack è una raccolta di modelli di agenti di AI generativa pronti per la produzione creati per Vertex AI Agent Engine. Lo starter pack dell'agente fornisce quanto segue:
- Modelli di agenti predefiniti:ReAct, RAG, multi-agente e altri modelli.
- Playground interattivo: testa il tuo agente e interagisci con lui.
- Infrastruttura automatizzata: utilizza Terraform per una gestione semplificata delle risorse.
- Pipeline CI/CD: workflow di deployment automatizzati che sfruttano Cloud Build.
- Osservabilità: supporto integrato per Cloud Trace e Cloud Logging.
Per iniziare, consulta la guida rapida.
Casi d'uso
Per scoprire di più su Vertex AI Agent Engine con esempi end-to-end, consulta le seguenti risorse:
| Caso d'uso | Descrizione | Link |
|---|---|---|
| Creare agenti connettendosi alle API pubbliche | Convertire tra valute. Crea una funzione che si connette a un'app di cambio valuta, consentendo al modello di fornire risposte accurate a query come "Qual è il tasso di cambio euro-dollaro oggi?" |
Notebook SDK Vertex AI per Python - Introduzione alla creazione e al deployment di un agente con Vertex AI Agent Engine |
| Progettazione di un progetto di energia solare per la comunità. Identifica le potenziali posizioni, cerca gli uffici governativi e i fornitori pertinenti e rivedi le immagini satellitari e il potenziale solare di regioni ed edifici per trovare la posizione ottimale per installare i pannelli solari. |
Notebook SDK Vertex AI per Python - Creazione e deployment di un agente API Google Maps con Vertex AI Agent Engine | |
| Creare agenti connettendosi ai database | Integrazione con AlloyDB e Cloud SQL per PostgreSQL. | Post del blog - Annuncio di LangChain su Vertex AI per AlloyDB e Cloud SQL per PostgreSQL Notebook SDK Vertex AI per Python - Deployment di un'applicazione RAG con Cloud SQL per PostgreSQL in Vertex AI Agent Engine Notebook SDK Vertex AI per Python - Deployment di un'applicazione RAG con AlloyDB per PostgreSQL in Vertex AI Agent Engine |
| Crea agenti con strumenti che accedono ai dati nel tuo database. | Blocco note dell'SDK Vertex AI per Python - Deployment di un agente con Vertex AI Agent Engine e MCP Toolbox for Databases | |
| Esegui query e comprendi i datastore strutturati utilizzando il linguaggio naturale. | Notebook SDK Vertex AI Python - Building a Conversational Search Agent with Vertex AI Agent Engine and RAG on Vertex AI Search | |
| Esegui query e comprendi i database grafici utilizzando il linguaggio naturale | Post del blog - GenAI GraphRAG e agenti AI che utilizzano Vertex AI Agent Engine con LangChain e Neo4j | |
| Esegui query e comprendi gli spazi vettoriali utilizzando il linguaggio naturale | Post del blog - Simplify GenAI RAG with MongoDB Atlas and Vertex AI Agent Engine | |
| Creare agenti con Agent Development Kit | Crea ed esegui il deployment di agenti utilizzando Agent Development Kit. | Agent Development Kit - Deploy to Vertex AI Agent Engine |
| Gestisci il contesto con le sessioni e la banca di memoria di Vertex AI Agent Engine in modalità express di Vertex AI senza fatturazione. | Agent Development Kit: sessioni di Vertex AI Agent Engine e banca di memoria in modalità Vertex AI Express. | |
| Crea agenti con framework OSS | Crea ed esegui il deployment di agenti utilizzando il framework open source OneTwo. | Post del blog - OneTwo e Vertex AI Agent Engine: esplorare lo sviluppo avanzato di agenti AI su Google Cloud |
| Crea ed esegui il deployment di agenti utilizzando il framework open source LangGraph. | Blocco note dell'SDK Vertex AI Python - Creazione e deployment di un'applicazione LangGraph con Vertex AI Agent Engine | |
| Debug e ottimizzazione degli agenti | Crea e traccia agenti utilizzando OpenTelemetry e Cloud Trace. | Notebook SDK Vertex AI per Python - Debug e ottimizzazione degli agenti: una guida al tracciamento in Vertex AI Agent Engine |
| Crea sistemi multi-agente con il protocollo A2A (anteprima) | Crea agenti interoperabili che comunicano e collaborano con altri agenti indipendentemente dal loro framework. | Per ulteriori informazioni, consulta la documentazione del protocollo A2A. |
Sicurezza aziendale
Vertex AI Agent Engine supporta diverse funzionalità per aiutarti a soddisfare i requisiti di sicurezza aziendale, rispettare le norme di sicurezza della tua organizzazione e seguire le best practice di sicurezza. Sono supportate le seguenti funzionalità:
Controlli di servizio VPC: Vertex AI Agent Engine supporta i Controlli di servizio VPC per rafforzare la sicurezza dei dati e mitigare i rischi di esfiltrazione di dati. Quando i Controlli di servizio VPC sono configurati, l'agente di cui è stato eseguito il deployment mantiene l'accesso sicuro alle API e ai servizi Google, come l'API BigQuery, l'API Cloud SQL Admin e l'API Vertex AI, verificando il funzionamento senza problemi all'interno del perimetro definito. Fondamentalmente, Controlli di servizio VPC blocca efficacemente tutto l'accesso a internet pubblico, limitando il movimento dei dati ai confini della rete autorizzata e migliorando in modo significativo il livello di sicurezza della tua azienda.
Interfaccia Private Service Connect: per Vertex AI Agent Engine Runtime, PSC-I consente agli agenti di interagire con i servizi ospitati privatamente nel VPC di un utente. Per maggiori informazioni, vedi Utilizzare l'interfaccia Private Service Connect con Vertex AI Agent Engine.
Chiavi di crittografia gestite dal cliente (CMEK): Vertex AI Agent Engine supporta le CMEK per proteggere i tuoi dati con le tue chiavi di crittografia, che ti danno la proprietà e il controllo completo delle chiavi che proteggono i tuoi dati at-rest in Google Cloud. Per ulteriori informazioni, consulta CMEK di Agent Engine.
Residenza dei dati (DRZ): Vertex AI Agent Engine supporta la residenza dei dati (DRZ) per garantire che tutti i dati at-rest e in uso vengano archiviati nella regione specificata.
HIPAA: nell'ambito di Vertex AI Platform, Vertex AI Agent Engine supporta i carichi di lavoro HIPAA.
Access Transparency: Access Transparency ti fornisce log che acquisiscono le azioni intraprese dal personale di Google quando accede ai tuoi contenuti. Per ulteriori informazioni su come abilitare Access Transparency per Vertex AI Agent Engine, consulta Access Transparency in Vertex AI.
La tabella seguente mostra quali funzionalità di sicurezza aziendale sono supportate per ciascun servizio Agent Engine:
| Funzionalità di sicurezza | Runtime | Sessioni | Memory Bank | Example Store | esegui il codice |
|---|---|---|---|---|---|
| Controlli di servizio VPC | Sì | Sì | Sì | No | No |
| Chiavi di crittografia gestite dal cliente | Sì | Sì | Sì | No | No |
| Residenza dei dati (DRZ) at-rest | Sì | Sì | Sì | No | No |
| Residenza dei dati (DRZ) in uso | No | Sì | Sì* | No | Sì |
| HIPAA | Sì | Sì | Sì | Sì | No |
| Access Transparency | Sì | Sì | Sì | No | No |
* Solo quando utilizzi un endpoint regionale Gemini.
Aree geografiche supportate
Vertex AI Agent Engine Runtime, Agent Engine Sessions e Vertex AI Agent Engine Memory Bank sono supportati nelle seguenti regioni:
| Regione | Località | Versioni supportate |
|---|---|---|
us-central1 |
Iowa | v1 è supportato per le funzionalità GA. v1beta1 è supportato per le funzionalità di anteprima. |
us-east4 |
Virginia del Nord | v1 è supportato per le funzionalità GA. v1beta1 è supportato per le funzionalità di anteprima. |
us-west1 |
Oregon | v1 è supportato per le funzionalità GA. v1beta1 è supportato per le funzionalità di anteprima. |
europe-west1 |
Belgio | v1 è supportato per le funzionalità GA. v1beta1 è supportato per le funzionalità di anteprima. |
europe-west2 |
Londra | v1 è supportato per le funzionalità GA. v1beta1 è supportato per le funzionalità di anteprima. |
europe-west3 |
Francoforte | v1 è supportato per le funzionalità GA. v1beta1 è supportato per le funzionalità di anteprima. |
europe-west4 |
Paesi Bassi | v1 è supportato per le funzionalità GA. v1beta1 è supportato per le funzionalità di anteprima. |
europe-southwest1 |
Madrid | v1 è supportato per le funzionalità GA. v1beta1 è supportato per le funzionalità di anteprima. |
asia-east1 |
Taiwan | v1 è supportato per le funzionalità GA. v1beta1 è supportato per le funzionalità di anteprima. |
asia-northeast1 |
Tokyo | v1 è supportato per le funzionalità GA. v1beta1 è supportato per le funzionalità di anteprima. |
asia-south1 |
Mumbai | v1 è supportato per le funzionalità GA. v1beta1 è supportato per le funzionalità di anteprima. |
asia-southeast1 |
Singapore | v1 è supportato per le funzionalità GA. v1beta1 è supportato per le funzionalità di anteprima. |
australia-southeast2 |
Melbourne | v1 è supportato per le funzionalità GA. v1beta1 è supportato per le funzionalità di anteprima. |
Per l'esecuzione del codice di Agent Engine (anteprima), sono supportate le seguenti regioni.
| Regione | Località | Versioni supportate |
|---|---|---|
us-central1 |
Iowa | La versione v1beta1 è supportata. |
Quota
I seguenti limiti si applicano a Vertex AI Agent Engine per un determinato progetto in ogni regione:| Descrizione | Limite |
|---|---|
| Crea, elimina o aggiorna Vertex AI Agent Engine al minuto | 10 |
| Crea, elimina o aggiorna le sessioni di Vertex AI Agent Engine al minuto | 100 |
Query o StreamQuery Vertex AI Agent Engine al minuto |
90 |
| Aggiungi evento alle sessioni al minuto di Vertex AI Agent Engine | 300 |
| Numero massimo di risorse Vertex AI Agent Engine | 100 |
| Crea, elimina o aggiorna le risorse di memoria di Vertex AI Agent Engine al minuto | 100 |
| Recupera, elenca o recupera da Vertex AI Agent Engine Memory Bank al minuto | 300 |
| Richieste di esecuzione al minuto dell'ambiente sandbox (esecuzione del codice) | 1000 |
| Entità dell'ambiente sandbox (esecuzione del codice) per regione | 1000 |
Richieste di post dell'agente A2A come sendMessage e cancelTaskal minuto |
60 |
Richieste di recupero dell'agente A2A come getTask e getCard al minuto |
600 |
Connessioni bidirezionali live simultanee che utilizzano l'API BidiStreamQuery al minuto |
10 |
Prezzi
Per informazioni sui prezzi di Agent Engine Runtime, consulta la pagina Prezzi di Vertex AI.
Migrazione all'SDK basata sul client
Il modulo agent_engines all'interno dell'SDK Vertex AI per Python viene sottoposto a refactoring in un
design basato sul client per i seguenti motivi principali:
- Per allinearsi all'ADK di Google e all'SDK Google Gen AI nelle rappresentazioni dei tipi canonici. Ciò garantisce un modo coerente e standardizzato di rappresentare i tipi di dati in diversi SDK, il che semplifica l'interoperabilità e riduce l'overhead di conversione.
- Per la definizione dell'ambito a livello di cliente dei parametri Google Cloud nelle applicazioni multiprogetto e multisede. Ciò consente a un'applicazione di gestire le interazioni con le risorse in diversi Google Cloud progetti e posizioni geografiche configurando ogni istanza client con le impostazioni specifiche di progetto e posizione.
- Per migliorare la rilevabilità e la coesione dei servizi Vertex AI Agent Engine