Fitur eksekusi kode Gemini API memungkinkan model untuk membuat dan menjalankan kode Python, serta belajar dari hasil secara berulang hingga mencapai output akhir. Anda dapat menggunakan kemampuan eksekusi kode ini untuk membangun aplikasi yang memanfaatkan penalaran berbasis kode dan menghasilkan output teks. Misalnya, Anda dapat menggunakan eksekusi kode dalam aplikasi yang menyelesaikan persamaan atau memproses teks.
Gemini API menyediakan eksekusi kode sebagai alat, mirip dengan panggilan fungsi. Setelah Anda menambahkan eksekusi kode sebagai alat, model akan memutuskan kapan harus menggunakannya.
Lingkungan eksekusi kode mencakup library berikut. Anda tidak dapat menginstal library Anda sendiri.
- Altair
- Catur
- Cv2
- Matplotlib
- Mpmath
- NumPy
- Pandas
- Pdfminer
- Reportlab
- Seaborn
- Sklearn
- Statsmodels
- Striprtf
- SymPy
- Tabulasi
Model yang didukung
Model berikut memberikan dukungan untuk eksekusi kode:
- Gemini 2.5 Flash (Pratinjau)
- Gemini 2.5 Flash-Lite (Pratinjau)
- Gemini 2.5 Flash-Lite
- Gemini 2.0 Flash dengan Live API (Pratinjau)
- Gemini 2.5 Pro
- Gemini 2.5 Flash
- Gemini 2.0 Flash
Mulai eksekusi kode
Bagian ini mengasumsikan bahwa Anda telah menyelesaikan langkah-langkah penyiapan dan konfigurasi yang ditunjukkan dalam panduan memulai Gemini API.
Mengaktifkan eksekusi kode pada model
Anda dapat mengaktifkan eksekusi kode dasar seperti yang ditunjukkan di sini:
Python
Instal
pip install --upgrade google-genai
Untuk mempelajari lebih lanjut, lihat dokumentasi referensi SDK.
Tetapkan variabel lingkungan untuk menggunakan Gen AI SDK dengan Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Go
Pelajari cara menginstal atau mengupdate Go.
Untuk mempelajari lebih lanjut, lihat dokumentasi referensi SDK.
Tetapkan variabel lingkungan untuk menggunakan Gen AI SDK dengan Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Node.js
Instal
npm install @google/genai
Untuk mempelajari lebih lanjut, lihat dokumentasi referensi SDK.
Tetapkan variabel lingkungan untuk menggunakan Gen AI SDK dengan Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Java
Pelajari cara menginstal atau mengupdate Java.
Untuk mempelajari lebih lanjut, lihat dokumentasi referensi SDK.
Tetapkan variabel lingkungan untuk menggunakan Gen AI SDK dengan Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
REST
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
GENERATE_RESPONSE_METHOD: Jenis respons yang Anda inginkan dari model. Pilih metode yang menghasilkan cara yang Anda inginkan untuk menampilkan respons model:streamGenerateContent: Respons di-streaming saat dibuat untuk mengurangi persepsi latensi bagi audiens manusia.generateContent: Respons ditampilkan setelah sepenuhnya dihasilkan.
LOCATION: Region untuk memproses permintaan. Opsi yang tersedia meliputi:Klik untuk meluaskan daftar sebagian wilayah yang tersedia
us-central1us-west4northamerica-northeast1us-east4us-west1asia-northeast3asia-southeast1asia-northeast1
PROJECT_ID: Project ID Anda.MODEL_ID: ID model yang ingin Anda gunakan.ROLE: Peran dalam percakapan yang terkait dengan konten. Menentukan peran diperlukan bahkan dalam kasus penggunaan satu putaran. Nilai yang dapat diterima mencakup hal berikut:USER: Menentukan konten yang dikirim oleh Anda.MODEL: Menentukan respons model.
TEXT
Untuk mengirim permintaan Anda, pilih salah satu opsi berikut:
curl
Simpan isi permintaan dalam file bernama request.json.
Jalankan perintah berikut di terminal untuk membuat atau menimpa file ini di direktori saat ini:
cat > request.json << 'EOF'
{
"tools": [{'codeExecution': {}}],
"contents": {
"role": "ROLE",
"parts": { "text": "TEXT" }
},
}
EOFKemudian, jalankan perintah berikut untuk mengirim permintaan REST Anda:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:GENERATE_RESPONSE_METHOD"
PowerShell
Simpan isi permintaan dalam file bernama request.json.
Jalankan perintah berikut di terminal untuk membuat atau menimpa file ini di direktori saat ini:
@'
{
"tools": [{'codeExecution': {}}],
"contents": {
"role": "ROLE",
"parts": { "text": "TEXT" }
},
}
'@ | Out-File -FilePath request.json -Encoding utf8Kemudian, jalankan perintah berikut untuk mengirim permintaan REST Anda:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:GENERATE_RESPONSE_METHOD" | Select-Object -Expand Content
Anda akan menerima respons JSON yang mirip dengan berikut ini.
Menggunakan eksekusi kode dalam percakapan
Anda juga dapat menggunakan eksekusi kode sebagai bagian dari percakapan.
REST
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://aiplatform.googleapis.com/v1/projects/test-project/locations/global/publishers/google/models/gemini-2.0-flash-001:generateContent -d \
$'{
"tools": [{'code_execution': {}}],
"contents": [
{
"role": "user",
"parts": {
"text": "Can you print \"Hello world!\"?"
}
},
{
"role": "model",
"parts": [
{
"text": ""
},
{
"executable_code": {
"language": "PYTHON",
"code": "\nprint(\"hello world!\")\n"
}
},
{
"code_execution_result": {
"outcome": "OUTCOME_OK",
"output": "hello world!\n"
}
},
{
"text": "I have printed \"hello world!\" using the provided python code block. \n"
}
],
},
{
"role": "user",
"parts": {
"text": "What is the sum of the first 50 prime numbers? Generate and run code for the calculation, and make sure you get all 50."
}
}
]
}'
Eksekusi kode versus panggilan fungsi
Eksekusi kode dan panggilan fungsi adalah fitur serupa:
- Eksekusi kode memungkinkan model menjalankan kode di backend API dalam lingkungan yang tetap dan terisolasi.
- Panggilan fungsi memungkinkan Anda menjalankan fungsi yang diminta model, di lingkungan apa pun yang Anda inginkan.
Secara umum, sebaiknya gunakan eksekusi kode jika dapat menangani kasus penggunaan Anda. Eksekusi kode lebih mudah digunakan (Anda hanya perlu mengaktifkannya) dan diselesaikan dalam satu permintaan GenerateContent. Panggilan fungsi memerlukan permintaan
GenerateContent tambahan untuk mengirim kembali output dari setiap panggilan fungsi.
Untuk sebagian besar kasus, Anda harus menggunakan panggilan fungsi jika memiliki fungsi sendiri yang ingin dijalankan secara lokal, dan Anda harus menggunakan eksekusi kode jika ingin API menulis dan menjalankan kode Python untuk Anda serta menampilkan hasilnya.
Penagihan
Tidak ada biaya tambahan untuk mengaktifkan eksekusi kode dari Gemini API. Anda akan ditagih dengan tarif token input dan output saat ini berdasarkan model Gemini yang Anda gunakan.
Berikut beberapa hal lain yang perlu diketahui tentang penagihan untuk eksekusi kode:
- Anda hanya ditagih satu kali untuk token input yang Anda teruskan ke model dan token input perantara yang dihasilkan oleh penggunaan alat eksekusi kode.
- Anda akan ditagih untuk token output akhir yang dikembalikan kepada Anda dalam respons API.
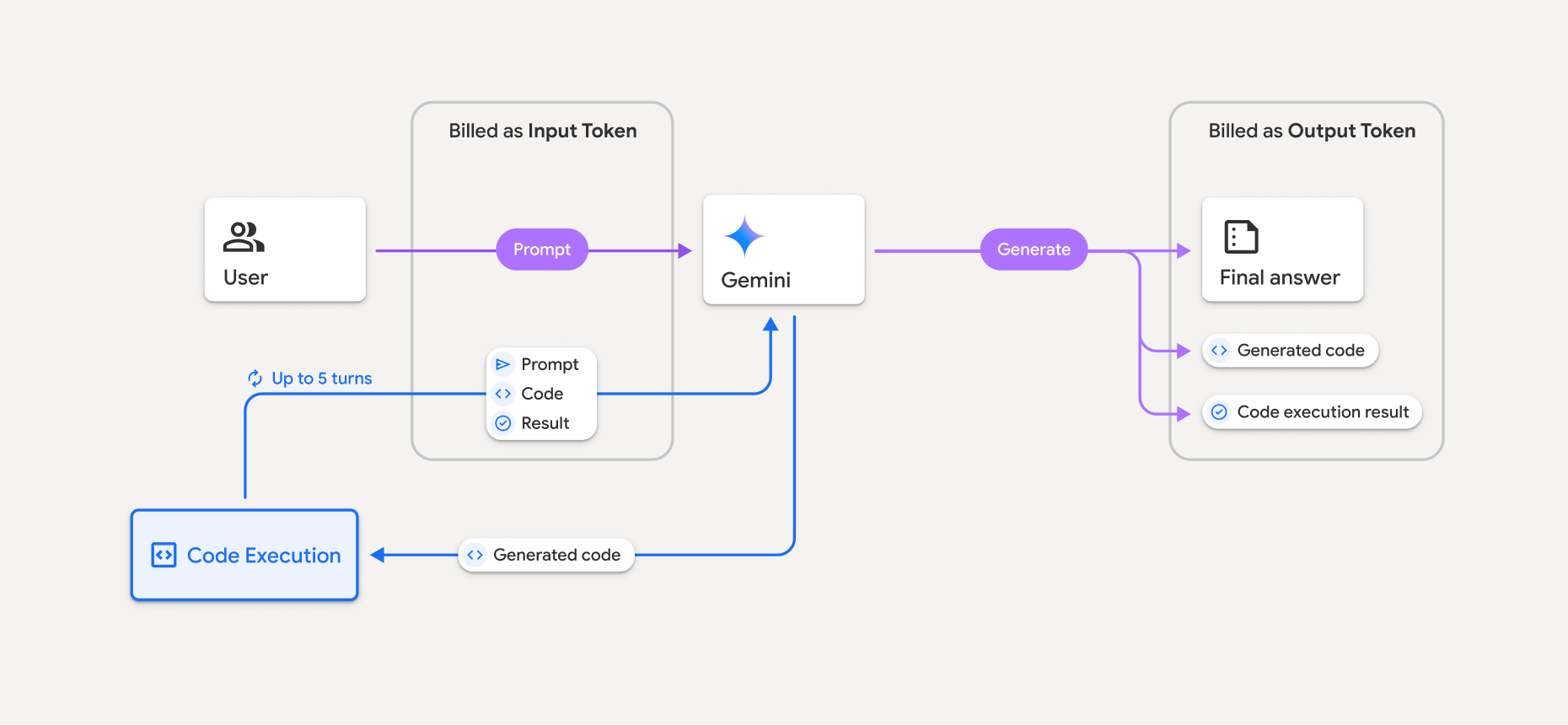
- Anda akan ditagih dengan tarif token input dan output saat ini berdasarkan model Gemini yang Anda gunakan.
- Jika Gemini menggunakan eksekusi kode saat membuat respons Anda, perintah asli, kode yang dihasilkan, dan hasil kode yang dieksekusi akan diberi label token perantara dan ditagih sebagai token input.
- Kemudian, Gemini membuat ringkasan dan menampilkan kode yang dihasilkan, hasil dari kode yang dieksekusi, dan ringkasan akhir. Token ini ditagih sebagai token output.
- Gemini API menyertakan jumlah token perantara dalam respons API, sehingga Anda dapat melacak token input tambahan di luar token yang diteruskan dalam perintah awal Anda.
Kode yang dihasilkan dapat mencakup output teks dan multimodal, seperti gambar.
Batasan
- Model hanya dapat membuat dan mengeksekusi kode. Metode ini tidak dapat menampilkan artefak lain seperti file media.
- Alat eksekusi kode tidak mendukung URI file sebagai input/output. Namun,
alat eksekusi kode mendukung input file dan output grafik sebagai
byte sebaris. Dengan menggunakan kemampuan input dan output ini, Anda dapat mengupload file CSV dan teks, mengajukan pertanyaan tentang file, dan membuat grafik Matplotlib sebagai bagian dari hasil eksekusi kode.
Jenis MIME yang didukung untuk byte inline adalah
.cpp,.csv,.java,.jpeg,.js,.png,.py,.ts, dan.xml. - Eksekusi kode dapat berjalan selama maksimal 30 detik sebelum waktu habis.
- Dalam beberapa kasus, mengaktifkan eksekusi kode dapat menyebabkan regresi di area output model lainnya (misalnya, menulis cerita).