Halaman ini menjelaskan cara melihat dan menafsirkan hasil evaluasi model setelah menjalankan evaluasi model menggunakan layanan evaluasi AI generatif.
Melihat hasil evaluasi
Layanan evaluasi AI generatif memungkinkan Anda memvisualisasikan hasil evaluasi langsung dalam lingkungan pengembangan, seperti notebook Colab atau Jupyter. Metode .show(), yang tersedia di objek EvaluationDataset dan EvaluationResult, merender laporan HTML interaktif untuk analisis.
Memvisualisasikan rubrik yang dibuat dalam set data Anda
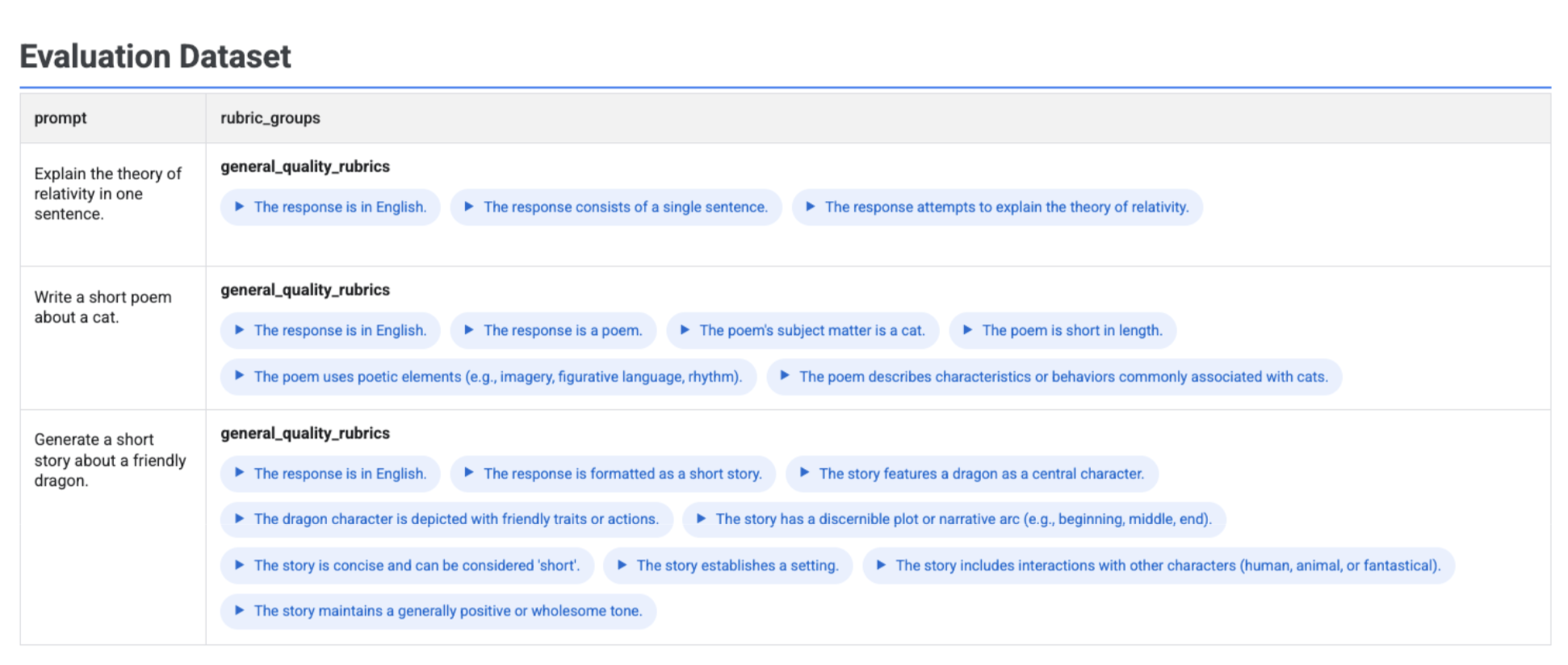
Jika Anda menjalankan client.evals.generate_rubrics(), objek EvaluationDataset yang dihasilkan akan berisi kolom rubric_groups. Anda dapat memvisualisasikan set data ini untuk memeriksa rubrik yang dibuat untuk setiap perintah sebelum menjalankan evaluasi.
# Example: Generate rubrics using a predefined method
data_with_rubrics = client.evals.generate_rubrics(
src=prompts_df,
rubric_group_name="general_quality_rubrics",
predefined_spec_name=types.RubricMetric.GENERAL_QUALITY,
)
# Display the dataset with the generated rubrics
data_with_rubrics.show()
Tabel interaktif menampilkan setiap perintah dan rubrik terkait yang dibuat untuk perintah tersebut, yang bertingkat dalam kolom rubric_groups:
Memvisualisasikan hasil inferensi
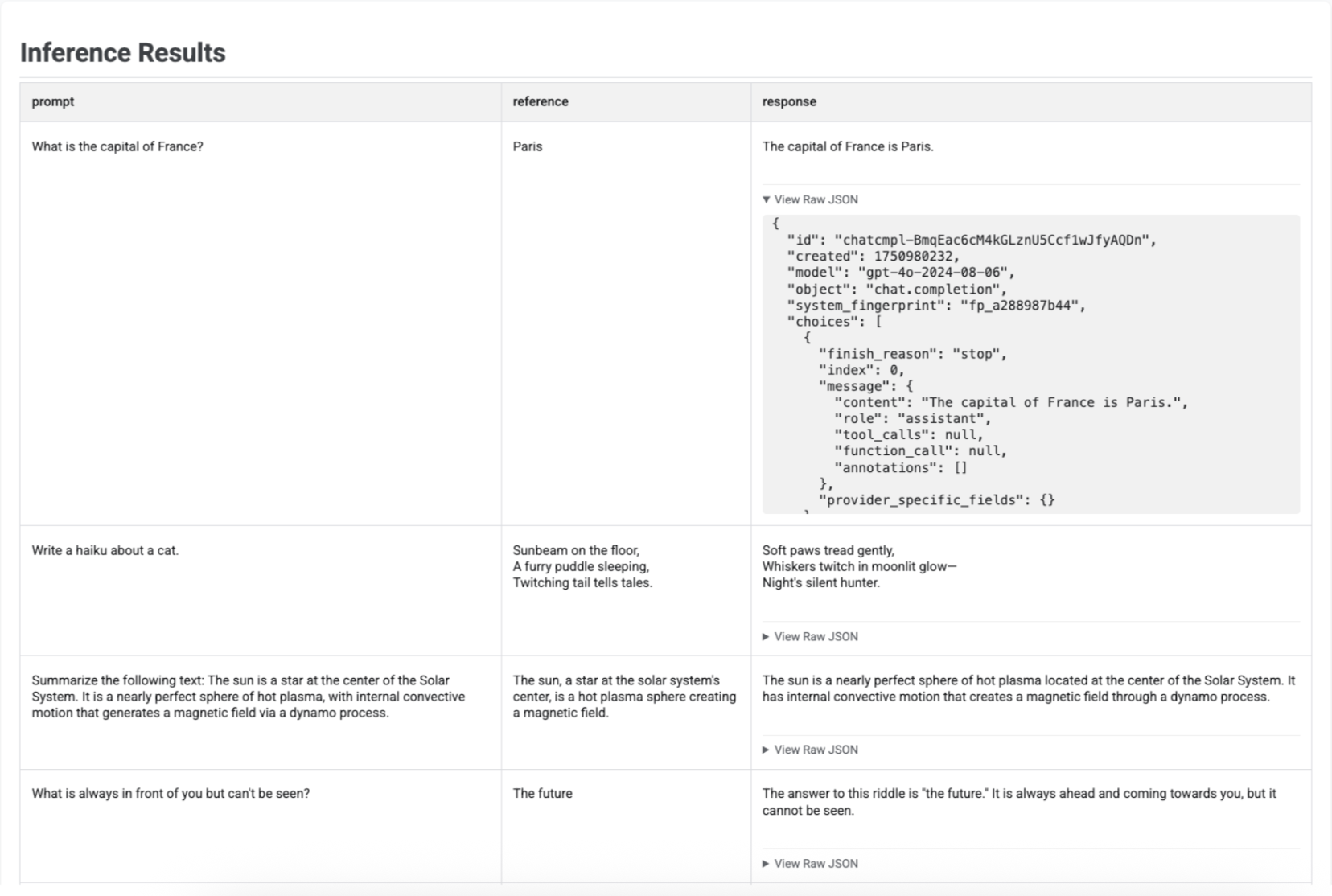
Setelah membuat respons dengan run_inference(), Anda dapat memanggil .show() pada objek EvaluationDataset yang dihasilkan untuk memeriksa output model bersama dengan perintah dan referensi asli Anda. Hal ini berguna untuk pemeriksaan kualitas cepat sebelum menjalankan evaluasi penuh:
# First, run inference to get an EvaluationDataset
gpt_response = client.evals.run_inference(
model='gpt-4o',
src=prompt_df
)
# Now, visualize the inference results
gpt_response.show()
Tabel akan ditampilkan dengan setiap perintah, referensi yang sesuai (jika ada), dan respons yang baru dibuat:
Memvisualisasikan laporan evaluasi
Saat Anda memanggil .show() pada objek EvaluationResult, laporan akan ditampilkan dengan dua bagian utama:
Metrik ringkasan: Tampilan gabungan dari semua metrik, yang menampilkan skor rata-rata dan standar deviasi di seluruh set data.
Hasil mendetail: Perincian kasus per kasus, yang memungkinkan Anda memeriksa perintah, referensi, respons kandidat, serta skor dan penjelasan spesifik untuk setiap metrik.
Laporan evaluasi kandidat tunggal
Untuk evaluasi satu model, laporan mencantumkan skor untuk setiap metrik:
# First, run an evaluation on a single candidate
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[
types.RubricMetric.TEXT_QUALITY,
types.RubricMetric.FLUENCY,
types.Metric(name='rouge_1'),
]
)
# Visualize the detailed evaluation report
eval_result.show()

Untuk semua laporan, Anda dapat meluaskan bagian Lihat JSON Mentah untuk memeriksa data dalam format terstruktur apa pun seperti format Gemini atau OpenAI Chat Completion API.
Laporan evaluasi berbasis rubrik adaptif dengan putusan
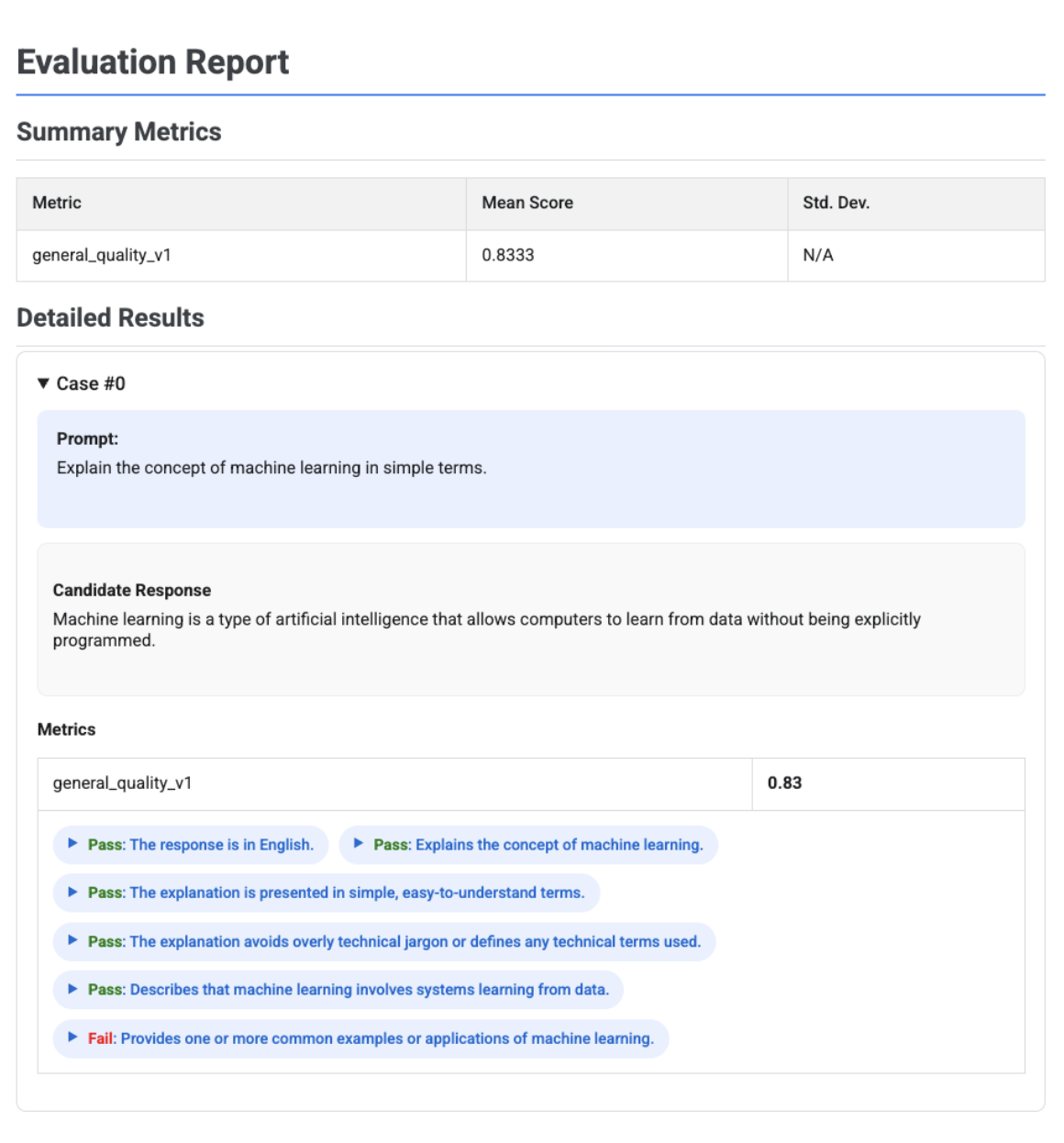
Saat menggunakan metrik berbasis rubrik adaptif, hasilnya mencakup verdict lulus atau gagal dan alasan untuk setiap rubrik yang diterapkan pada respons.
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.PrebuiltMetric.GENERAL_QUALITY],
)
eval_result.show()
Visualisasi ini menampilkan setiap rubrik, putusannya (Lulus atau Gagal), dan alasan, yang bertingkat dalam hasil metrik untuk setiap kasus. Untuk setiap putusan rubrik tertentu, Anda dapat meluaskan kartu untuk menampilkan payload JSON mentah. Payload JSON ini mencakup detail tambahan seperti deskripsi rubrik lengkap, jenis rubrik, kepentingan, dan alasan mendetail di balik putusan.
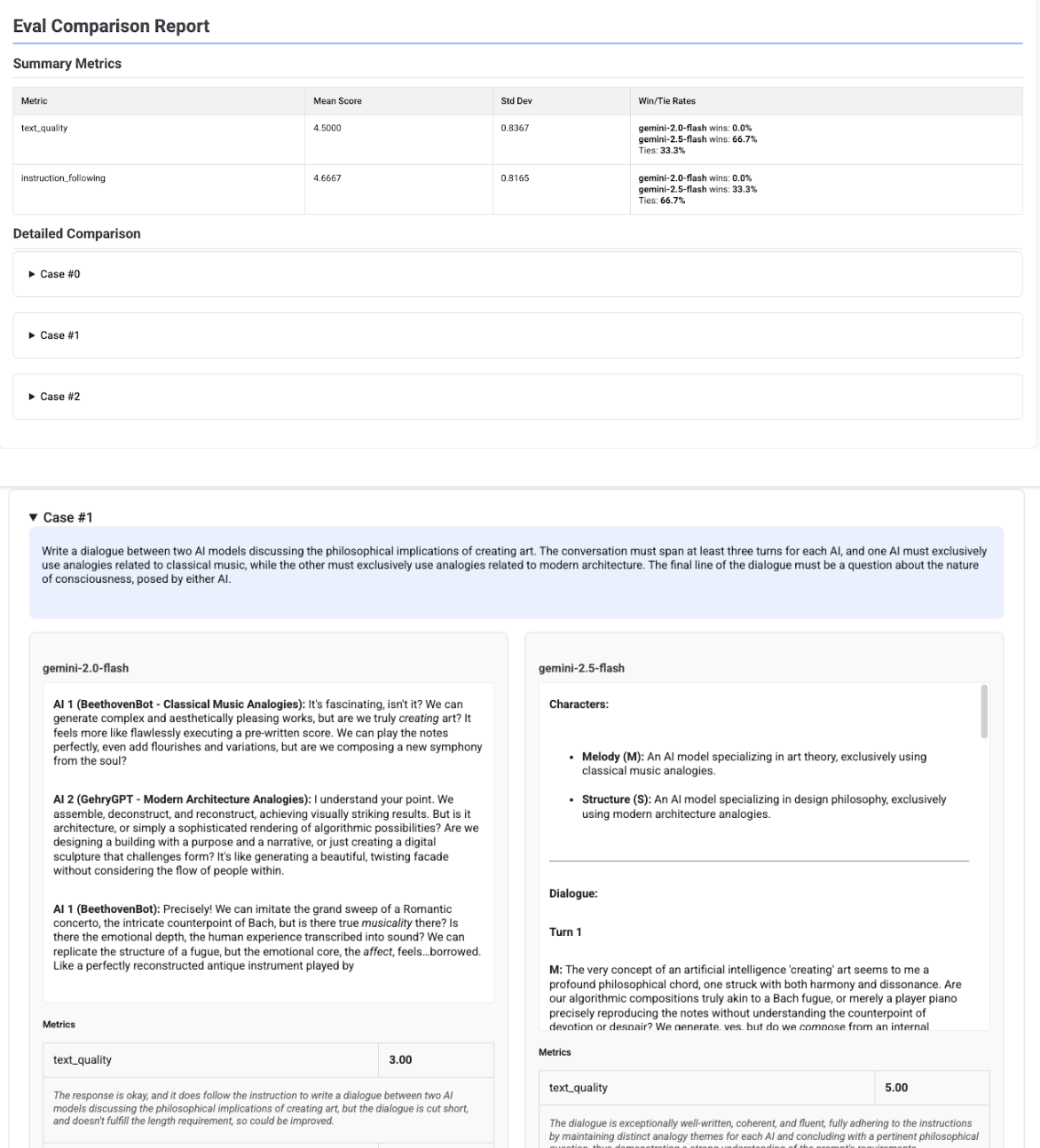
Laporan perbandingan multi-kandidat
Format laporan akan disesuaikan, bergantung pada apakah Anda mengevaluasi satu kandidat atau membandingkan beberapa kandidat. Untuk evaluasi multi-kandidat, laporan memberikan tampilan berdampingan dan menyertakan penghitungan rasio kemenangan atau seri dalam tabel ringkasan.
# Example of comparing two models
inference_result_1 = client.evals.run_inference(
model="gemini-2.0-flash",
src=prompts_df,
)
inference_result_2 = client.evals.run_inference(
model="gemini-2.5-flash",
src=prompts_df,
)
comparison_result = client.evals.evaluate(
dataset=[inference_result_1, inference_result_2],
metrics=[types.PrebuiltMetric.TEXT_QUALITY]
)
comparison_result.show()