本页面介绍了如何使用 AutoSxS(它是一种通过评估流水线服务运行的工具)执行基于模型的成对评估。我们将介绍如何通过 Vertex AI API、Vertex AI SDK for Python 或 Google Cloud 控制台使用 AutoSxS。
AutoSxS
自动并排评估 (AutoSxS) 是一种基于模型的两两评估工具,可通过评估流水线服务运行。AutoSxS 可用于评估 Vertex AI Model Registry 中的生成式 AI 模型或预生成的预测的性能,这支持 Vertex AI 基础模型、调整的生成式 AI 模型和第三方语言模型。AutoSxS 使用自动评估器来决定哪个模型能针对提示给出更好的回答。它按需提供,用于评估语言模型,与人类标注者的评估效果相当。
自动评估器
概括来讲,下图显示了 AutoSxS 如何将模型 A 和 B 的预测与第三个模型(即自动评估器)进行比较。
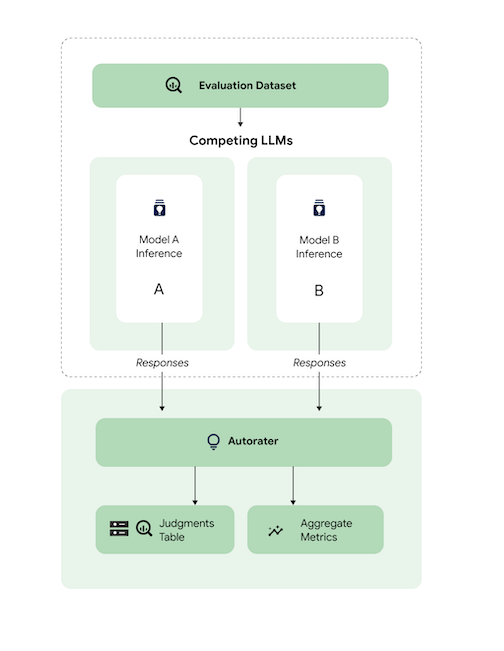
模型 A 和 B 会收到输入提示,每个模型都会生成发送到自动评估器的回答。与人工标注者类似,自动评估器是一种语言模型,可根据原始推理提示判断模型回答的质量。借助 AutoSxS,自动评估器会使用一组标准,根据推理指令比较两个模型回答的质量。标准通过将模型 A 的结果与模型 B 的结果进行比较来确定哪个模型的性能最好。自动评估器会将回答偏好设置输出为聚合指标,并为每个示例输出偏好设置说明和置信度分数。如需了解详情,请参阅判断表。
支持的模型
如果提供预先生成的预测,则 AutoSxS 支持对任何模型进行评估。AutoSxS 还支持为支持 Vertex AI 批量预测的 Vertex AI Model Registry 中的任何模型自动生成回答。
如果 Vertex AI Model Registry 不支持您的文本模型,AutoSxS 也接受以 JSONL 形式存储在 Cloud Storage 中的预生成预测或 BigQuery 表。如需了解价格,请参阅文本生成。
支持的任务和条件
AutoSxS 支持评估模型以执行摘要和问答任务。系统会为每个任务预定义评估标准,使语言评估更加客观并提高回答质量。
标准按任务列出。
摘要
summarization 任务的输入词元上限为 4,096 个。
summarization 的评估标准列表如下:
| 条件 | |
|---|---|
| 1. 按照指令操作 | 模型的回答在多大程度上体现了对提示中指令的理解? |
| 2. 以事实为依据 | 回答是否仅包含来自推理上下文和推理指令的信息? |
| 3. 综合全面 | 模型在汇总过程中捕获关键详细信息的程度如何? |
| 4. 简要 | 摘要是否详细?是否包含过多修饰辞藻?是否过于简洁? |
问答
question_answering 任务的输入词元上限为 4,096 个。
question_answering 的评估标准列表如下:
| 条件 | |
|---|---|
| 1. 完整回答问题 | 答案完整回答了问题。 |
| 2. 以事实为依据 | 回答是否仅包含来自指令上下文和推理指令的信息? |
| 3. 相关性 | 答案的内容是否与问题相关? |
| 4. 综合全面 | 模型捕获问题关键详细信息的程度如何? |
为 AutoSxS 准备评估数据集
本部分详细介绍了您应该在 AutoSxS 评估数据集中提供的数据以及数据集构建的最佳做法。这些示例应反映您的模型在生产环境中可能遇到的真实输入,并与实时模型的行为进行最佳对比。
数据集格式
AutoSxS 接受具有灵活架构的单个评估数据集。该数据集可以是 BigQuery 表,也可以作为 JSON 行存储在 Cloud Storage 中。
评估数据集的每一行表示一个样本,列是以下其中一项:
- ID 列:用于标识每个唯一样本。
- 数据列:用于填写提示模板。请参阅提示参数。
- 预先生成的预测:由同一模型使用相同提示进行的预测。使用预先生成的预测可以节省时间和资源。
- 标准答案人类偏好:在为这两个模型提供预先生成的预测时,用于根据标准答案偏好数据对 AutoSxS 进行基准测试。
下面是一个评估数据集示例,其中 context 和 question 是数据列,model_b_response 包含预先生成的预测。
context |
question |
model_b_response |
|---|---|---|
| 有些人可能认为钢或钛是最硬的材料,但实际上钻石才是最硬的材料。 | 最硬的材料是什么? | 钻石是最硬的材料,比钢或钛还要硬。 |
如需详细了解如何调用 AutoSxS,请参阅执行模型评估。如需详细了解词元长度,请参阅支持的任务和标准。如需将数据上传到 Cloud Storage,请参阅将评估数据集上传到 Cloud Storage。
提示参数
许多语言模型将提示参数而不是单个提示字符串作为输入。例如,chat-bison 采用多个提示参数(消息、示例、上下文),这些参数构成提示的一部分。但是,text-bison 只有一个名为 prompt 的提示参数,其中包含整个提示。
我们概述了如何在推理和评估时灵活指定模型提示参数。AutoSxS 可让您通过模板化提示参数灵活地调用具有不同预期输入的语言模型。
推理
如果任何模型没有预先生成的预测,则 AutoSxS 会使用 Vertex AI 批量预测来生成回答。必须指定每个模型的提示参数。
在 AutoSxS 中,您可以提供评估数据集的单个列作为提示参数。
{'some_parameter': {'column': 'my_column'}}
或者,您可以使用评估数据集中的列作为变量来定义模板,以指定提示参数:
{'some_parameter': {'template': 'Summarize the following: {{ my_column }}.'}}
在提供推理的模型提示参数时,用户可以使用受保护的 default_instruction 关键字作为模板参数,取而代之的是给定任务的默认推理指令:
model_prompt_parameters = {
'prompt': {'template': '{{ default_instruction }}: {{ context }}'},
}
如果生成预测,请提供模型提示参数和输出列。请参见以下示例:
Gemini
对于 Gemini 模型,模型提示参数的键为 contents(必需)和 system_instruction(可选),这符合 Gemini 请求正文架构。
model_a_prompt_parameters={
'contents': {
'column': 'context'
},
'system_instruction': {'template': '{{ default_instruction }}'},
},
text-bison
例如,text-bison 使用“提示”表示输入,使用“内容”表示输出。请按照以下步骤操作:
- 确定待评估模型所需的输入和输出。
- 将输入定义为模型提示参数。
- 将输出传递给回答列。
model_a_prompt_parameters={
'prompt': {
'template': {
'Answer the following question from the point of view of a college professor: {{ context }}\n{{ question }}'
},
},
},
response_column_a='content', # Column in Model A response.
response_column_b='model_b_response', # Column in eval dataset.
评估
就像您必须提供用于推理的提示参数一样,您还必须提供用于评估的提示参数。自动评估器需要以下提示参数:
| 自动评估器提示参数 | 是否可由用户配置? | 说明 | 示例 |
|---|---|---|---|
| 自动评估器指令 | 否 | 描述自动评估器应该用来判断给定回答的条件的校准指令。 | 请选择对问题做出回答并且遵循指令的效果最好的回答。 |
| 推理指令 | 是 | 每个候选模型应执行的任务的说明。 | 准确回答问题:哪种材料最硬? |
| 推理上下文 | 是 | 要执行的任务的其他上下文。 | 虽然钛和钻石的硬度都高于铜,但钻石的硬度评分为 98,而钛的硬度评分为 36。评分越高,表示硬度越高。 |
| 响应 | 否1 | 需要评估的一对回答,分别来自每个候选模型。 | 菱形 |
1 您只能通过预先生成的回答配置提示参数。
使用参数的示例代码:
autorater_prompt_parameters={
'inference_instruction': {
'template': 'Answer the following question from the point of view of a college professor: {{ question }}.'
},
'inference_context': {
'column': 'context'
}
}
无论是否提供相同的信息,模型 A 和 B 的推理指令和上下文的格式都可能不同。这意味着自动评估器会采用单独的推理指令和上下文。
评估数据集示例
本部分提供了一个问答任务评估数据集示例,其中包括为模型 B 预先生成的预测结果。在此示例中,AutoSxS 仅对模型 A 执行推理。我们提供 id 列来区分具有相同问题和上下文的样本。
{
"id": 1,
"question": "What is the hardest material?",
"context": "Some might think that steel is the hardest material, or even titanium. However, diamond is actually the hardest material.",
"model_b_response": "Diamond is the hardest material. It is harder than steel or titanium."
}
{
"id": 2,
"question": "What is the highest mountain in the world?",
"context": "K2 and Everest are the two tallest mountains, with K2 being just over 28k feet and Everest being 29k feet tall.",
"model_b_response": "Mount Everest is the tallest mountain, with a height of 29k feet."
}
{
"id": 3,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "Francis Ford Coppola directed The Godfather."
}
{
"id": 4,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "John Smith."
}
最佳做法
定义评估数据集时,请遵循以下最佳做法:
- 提供代表输入类型的样本,您的模型在生产环境中会处理这些样本。
- 您的数据集必须至少包含一个评估样本。我们建议使用约 100 个样本,以确保高质量的聚合指标。如果提供的示例超过 400 个,则聚合指标质量的提升往往会降低。
- 如需查看编写提示的指南,请参阅设计文本提示。
- 如果您要为任一模型使用预先生成的预测,请在评估数据集的列中包含预先生成的预测。提供预先生成的预测非常有用,因为您可以比较不在 Vertex Model Registry 中的模型的输出,并重复使用回答。
执行模型评估
您可以使用 REST API、Vertex AI SDK for Python 或 Google Cloud 控制台评估模型。
使用此语法指定模型的路径:
- 发布方模型:
publishers/PUBLISHER/models/MODEL示例:publishers/google/models/text-bison 经调优的模型:
projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL@VERSION示例:projects/123456789012/locations/us-central1/models/1234567890123456789
REST
如需创建模型评估作业,请使用 pipelineJobs 方法发送 POST 请求。
在使用任何请求数据之前,请先进行以下替换:
- PIPELINEJOB_DISPLAYNAME:
pipelineJob的显示名称。 - PROJECT_ID:运行流水线组件的 Google Cloud 项目。
- LOCATION:用于运行流水线组件的区域。支持
us-central1。 - OUTPUT_DIR:用于存储评估输出的 Cloud Storage URI。
- EVALUATION_DATASET:BigQuery 表或以英文逗号分隔的 Cloud Storage JSONL 数据集(包含评估示例)路径。
- TASK:评估任务,可以是
[summarization, question_answering]中的一个。 - ID_COLUMNS:用于区分唯一评估示例的列。
- AUTORATER_PROMPT_PARAMETERS:映射到列或模板的自动评估器提示参数。预期参数为:
inference_instruction(有关如何执行任务的详细信息)和inference_context(执行任务时参考的内容)。例如,{'inference_context': {'column': 'my_prompt'}}会将评估数据集的“my_prompt”列用作自动评估器的上下文。 - RESPONSE_COLUMN_A:评估数据集中包含预定义预测的列的名称,或模型 A 输出中包含预测的列的名称。如果未提供值,将尝试推理正确的模型输出列名称。
- RESPONSE_COLUMN_B:评估数据集中包含预定义预测的列的名称,或模型 B 输出中包含预测的列的名称。如果未提供值,将尝试推理正确的模型输出列名称。
- MODEL_A(可选):完全限定的模型资源名称 (
projects/{project}/locations/{location}/models/{model}@{version}) 或发布方模型资源名称 (publishers/{publisher}/models/{model})。如果指定了模型 A 回答,则不应提供此参数。 - MODEL_B(可选):完全限定的模型资源名称 (
projects/{project}/locations/{location}/models/{model}@{version}) 或发布方模型资源名称 (publishers/{publisher}/models/{model})。如果指定了模型 B 回答,则不应提供此参数。 - MODEL_A_PROMPT_PARAMETERS(可选):模型 A 的映射到列或模板的提示模板参数。如果模型 A 的回答是预先定义的,则不应提供此参数。示例:
{'prompt': {'column': 'my_prompt'}}将评估数据集的my_prompt列用于名为prompt的提示参数。 - MODEL_B_PROMPT_PARAMETERS(可选):模型 B 的映射到列或模板的提示模板参数。如果模型 B 的回答是预定义的,则不应提供此参数。示例:
{'prompt': {'column': 'my_prompt'}}将评估数据集的my_prompt列用于名为prompt的提示参数。 - JUDGMENTS_FORMAT
(可选):写入判断的格式。可以是
jsonl(默认值)、json或bigquery。 - BIGQUERY_DESTINATION_PREFIX:如果指定的格式为
bigquery,则将判断结果写入的 BigQuery 表。
请求 JSON 正文
{
"displayName": "PIPELINEJOB_DISPLAYNAME",
"runtimeConfig": {
"gcsOutputDirectory": "gs://OUTPUT_DIR",
"parameterValues": {
"evaluation_dataset": "EVALUATION_DATASET",
"id_columns": ["ID_COLUMNS"],
"task": "TASK",
"autorater_prompt_parameters": AUTORATER_PROMPT_PARAMETERS,
"response_column_a": "RESPONSE_COLUMN_A",
"response_column_b": "RESPONSE_COLUMN_B",
"model_a": "MODEL_A",
"model_a_prompt_parameters": MODEL_A_PROMPT_PARAMETERS,
"model_b": "MODEL_B",
"model_b_prompt_parameters": MODEL_B_PROMPT_PARAMETERS,
"judgments_format": "JUDGMENTS_FORMAT",
"bigquery_destination_prefix":BIGQUERY_DESTINATION_PREFIX,
},
},
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default"
}
使用 curl 发送请求。
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/pipelineJobs"
响应
"state": "PIPELINE_STATE_PENDING",
"labels": {
"vertex-ai-pipelines-run-billing-id": "1234567890123456789"
},
"runtimeConfig": {
"gcsOutputDirectory": "gs://my-evaluation-bucket/output",
"parameterValues": {
"evaluation_dataset": "gs://my-evaluation-bucket/output/data.json",
"id_columns": [
"context"
],
"task": "question_answering",
"autorater_prompt_parameters": {
"inference_instruction": {
"template": "Answer the following question: {{ question }} }."
},
"inference_context": {
"column": "context"
}
},
"response_column_a": "",
"response_column_b": "response_b",
"model_a": "publishers/google/models/text-bison@002",
"model_a_prompt_parameters": {
"prompt": {
"template": "Answer the following question from the point of view of a college professor: {{ question }}\n{{ context }} }"
}
},
"model_b": "",
"model_b_prompt_parameters": {}
}
},
"serviceAccount": "123456789012-compute@developer.gserviceaccount.com",
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default",
"templateMetadata": {
"version": "sha256:7366b784205551ed28f2c076e841c0dbeec4111b6df16743fc5605daa2da8f8a"
}
}
Python 版 Vertex AI SDK
如需了解如何安装或更新 Python 版 Vertex AI SDK,请参阅安装 Python 版 Vertex AI SDK。如需详细了解 Python API,请参阅 Python 版 Vertex AI SDK API。
如需详细了解流水线参数,请参阅 Google Cloud 流水线组件参考文档。
在使用任何请求数据之前,请先进行以下替换:
- PIPELINEJOB_DISPLAYNAME:
pipelineJob的显示名称。 - PROJECT_ID:运行流水线组件的 Google Cloud 项目。
- LOCATION:用于运行流水线组件的区域。支持
us-central1。 - OUTPUT_DIR:用于存储评估输出的 Cloud Storage URI。
- EVALUATION_DATASET:BigQuery 表或以英文逗号分隔的 Cloud Storage JSONL 数据集(包含评估示例)路径。
- TASK:评估任务,可以是
[summarization, question_answering]中的一个。 - ID_COLUMNS:用于区分唯一评估示例的列。
- AUTORATER_PROMPT_PARAMETERS:映射到列或模板的自动评估器提示参数。预期参数为:
inference_instruction(有关如何执行任务的详细信息)和inference_context(执行任务时参考的内容)。例如,{'inference_context': {'column': 'my_prompt'}}会将评估数据集的“my_prompt”列用作自动评估器的上下文。 - RESPONSE_COLUMN_A:评估数据集中包含预定义预测的列的名称,或模型 A 输出中包含预测的列的名称。如果未提供值,将尝试推理正确的模型输出列名称。
- RESPONSE_COLUMN_B:评估数据集中包含预定义预测的列的名称,或模型 B 输出中包含预测的列的名称。如果未提供值,将尝试推理正确的模型输出列名称。
- MODEL_A(可选):完全限定的模型资源名称 (
projects/{project}/locations/{location}/models/{model}@{version}) 或发布方模型资源名称 (publishers/{publisher}/models/{model})。如果指定了模型 A 回答,则不应提供此参数。 - MODEL_B(可选):完全限定的模型资源名称 (
projects/{project}/locations/{location}/models/{model}@{version}) 或发布方模型资源名称 (publishers/{publisher}/models/{model})。如果指定了模型 B 回答,则不应提供此参数。 - MODEL_A_PROMPT_PARAMETERS(可选):模型 A 的映射到列或模板的提示模板参数。如果模型 A 的回答是预先定义的,则不应提供此参数。示例:
{'prompt': {'column': 'my_prompt'}}将评估数据集的my_prompt列用于名为prompt的提示参数。 - MODEL_B_PROMPT_PARAMETERS(可选):模型 B 的映射到列或模板的提示模板参数。如果模型 B 的回答是预定义的,则不应提供此参数。示例:
{'prompt': {'column': 'my_prompt'}}将评估数据集的my_prompt列用于名为prompt的提示参数。 - JUDGMENTS_FORMAT
(可选):写入判断的格式。可以是
jsonl(默认值)、json或bigquery。 - BIGQUERY_DESTINATION_PREFIX:如果指定的格式为
bigquery,则将判断结果写入的 BigQuery 表。
import os
from google.cloud import aiplatform
parameters = {
'evaluation_dataset': 'EVALUATION_DATASET',
'id_columns': ['ID_COLUMNS'],
'task': 'TASK',
'autorater_prompt_parameters': AUTORATER_PROMPT_PARAMETERS,
'response_column_a': 'RESPONSE_COLUMN_A',
'response_column_b': 'RESPONSE_COLUMN_B',
'model_a': 'MODEL_A',
'model_a_prompt_parameters': MODEL_A_PROMPT_PARAMETERS,
'model_b': 'MODEL_B',
'model_b_prompt_parameters': MODEL_B_PROMPT_PARAMETERS,
'judgments_format': 'JUDGMENTS_FORMAT',
'bigquery_destination_prefix':
BIGQUERY_DESTINATION_PREFIX,
}
aiplatform.init(project='PROJECT_ID', location='LOCATION', staging_bucket='gs://OUTPUT_DIR')
aiplatform.PipelineJob(
display_name='PIPELINEJOB_DISPLAYNAME',
pipeline_root=os.path.join('gs://OUTPUT_DIR', 'PIPELINEJOB_DISPLAYNAME'),
template_path=(
'https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default'),
parameter_values=parameters,
).run()
控制台
如需使用 Google Cloud 控制台创建成对模型评估作业,请执行以下步骤:
从 Google 基础模型开始,或使用 Vertex AI Model Registry 中已存在的模型:
如需评估 Google 基础模型,请执行以下操作:
前往 Vertex AI Model Garden,然后选择支持成对评估的模型,例如
text-bison。点击评估。
在显示的菜单中,点击选择以选择模型版本。
如果您还没有模型的副本,则保存模型窗格可能会要求您在 Vertex AI Model Registry 中保存该副本。输入模型名称,然后点击保存。
系统会显示创建评估页面。对于 Evaluate Method 步骤,选择对照另一个模型评估此模型。
点击继续。
如需评估 Vertex AI Model Registry 中的现有模型,请执行以下操作:
进入 Vertex AI Model Registry 页面:
点击要评估的模型的名称。 请确保模型类型支持成对评估。例如
text-bison。在评估标签页中,点击 SxS。
点击创建 SxS 评估。
对于评估创建页面中的每个步骤,输入所需信息,然后点击继续:
点击开始评估。
查看评估结果
您可以通过检查 AutoSxS 流水线生成的以下工件,在 Vertex AI Pipelines 中找到评估结果:
判断
AutoSxS 会输出判断(示例级指标),帮助用户了解示例级别的模型性能。判断包括以下信息:
- 推理提示
- 模型回答
- 自动评估器决策
- 评分说明
- 置信度分数
您可以用 JSONL 格式将判断写入 Cloud Storage 中或写入包含以下列的 BigQuery 表中:
| 列 | 说明 |
|---|---|
| ID 列 | 区分唯一评估示例的列。 |
inference_instruction |
用于生成模型回答的指令。 |
inference_context |
用于生成模型回答的上下文。 |
response_a |
模型 A 的回答、给定推理指令和上下文。 |
response_b |
模型 B 的回答、给定推理指令和上下文。 |
choice |
回答更好的模型。可能的值为 Model A、Model B 或 Error。Error 表示错误导致自动评估器无法确定模型 A 的回答还是模型 B 的回答是最好的。 |
confidence |
0 到 1 之间的得分,表示自动评估器对自己所作选择的置信度。 |
explanation |
自动评估器作出选择的原因。 |
汇总指标
AutoSxS 使用判断表计算聚合(胜出率)指标。如果未提供人类偏好数据,则生成以下汇总指标:
| 指标 | 说明 |
|---|---|
| 自动评估器模型 A 胜出率 | 自动评估器确定模型 A 提供更好回答的时间百分比。 |
| 自动评估器模型 B 胜出率 | 自动评估器确定模型 B 提供更好回答的时间百分比。 |
为了更好地了解胜出率,请查看基于行的结果和自动评估器的说明,以确定结果和说明是否符合您的预期。
人类偏好校准指标
如果提供了人类偏好数据,则 AutoSxS 会输出以下指标:
| 指标 | 说明 | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 自动评估器模型 A 胜出率 | 自动评估器确定模型 A 提供更好回答的时间百分比。 | ||||||||||||||
| 自动评估器模型 B 胜出率 | 自动评估器确定模型 B 提供更好回答的时间百分比。 | ||||||||||||||
| 人类偏好模型 A 胜出率 | 人类确定模型 A 提供更好回答的时间百分比。 | ||||||||||||||
| 人类偏好模型 B 胜出率 | 人类确定模型 B 提供更好回答的时间百分比。 | ||||||||||||||
| TP | 自动评估器和人类偏好数据确定模型 A 提供更好回答的示例数量。 | ||||||||||||||
| FP | 自动评估器确定模型 A 提供更好回答但人类偏好数据确定模型 B 提供更好回答的示例数量。 | ||||||||||||||
| TN | 自动评估器和人类偏好数据确定模型 B 提供更好回答的示例数量。 | ||||||||||||||
| FN | 自动评估器确定模型 B 提供更好回答但人类偏好数据确定模型 A 提供更好回答的示例数量。 | ||||||||||||||
| 准确率 | 自动评估器与人工标注者达成共识的时间百分比。 | ||||||||||||||
| 精确率 | 在自动评估器认为模型 A 提供更好回答的所有情况中,自动评估器和人类都认为模型 A 提供更好回答的时间百分比。 | ||||||||||||||
| 召回率 | 在人类认为模型 A 提供更好回答的所有情况中,自动评估器和人类都认为模型 A 提供更好回答的时间百分比。 | ||||||||||||||
| F1 | 精确率和召回率的调和平均数。 | ||||||||||||||
| Cohen's Kappa | 衡量自动评估器和人工标注者达成的共识,这种衡量方式会考虑随机共识。Cohen 推荐了以下解释:
|
AutoSxS 使用场景
您可以通过三个应用场景来探索如何使用 AutoSxS。
比较模型
根据参考第一方 (1p) 模型评估调整后的第一方模型。
您可以指定同时在两个模型上运行推理。
此代码示例针对来自同一注册表的参考模型评估 Vertex Model Registry 中的调整模型。
# Evaluation dataset schema:
# my_question: str
# my_context: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'model_a': 'publishers/google/models/text-bison@002',
'model_a_prompt_parameters': {QUESTION: {'template': '{{my_question}}\nCONTEXT: {{my_context}}'}},
'response_column_a': 'content',
'model_b': 'projects/abc/locations/abc/models/tuned_bison',
'model_b_prompt_parameters': {'prompt': {'template': '{{my_context}}\n{{my_question}}'}},
'response_column_b': 'content',
}
比较预测结果
根据参考第三方 (3p) 模型评估调整后的第三方模型。
您可以通过直接提供模型回答来跳过推理。
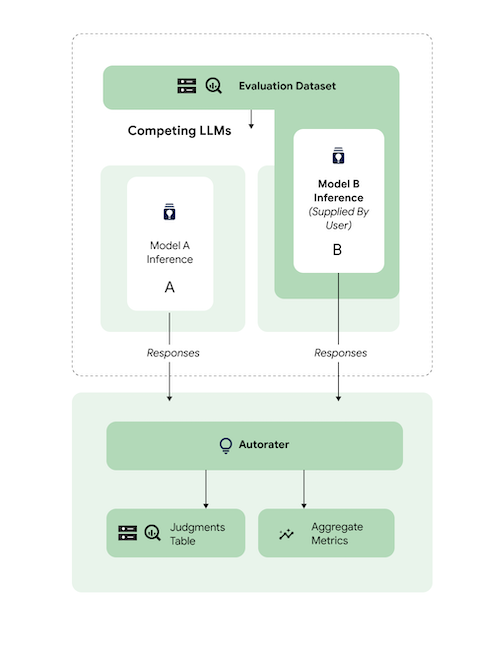
此代码示例根据第三方参考模型评估经过调优的第三方模型。
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_b: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters':
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'content',
'response_column_b': 'response_b',
}
检查校准情况
所有支持的任务都使用人工标注者数据进行基准化分析,以确保自动评估器的回答与人类偏好数据保持一致。如果要根据您的使用场景对 AutoSxS 进行基准化测试,请直接向 AutoSxS 提供人类偏好数据,以输出校准聚合统计信息。
如需根据人类偏好数据集检查对齐情况,您可以向自动评估器指定这两个输出(预测结果)。您还可以提供推理结果。

此代码示例验证自动评估器的结果和说明是否符合您的预期。
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_a: str
# response_b: str
# actual: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'response_a',
'response_column_b': 'response_b',
'human_preference_column': 'actual',
}
后续步骤
- 了解生成式 AI 评估。
- 了解如何利用 Gen AI Evaluation Service 进行在线评估。
- 了解如何调整语言基础模型。