En esta página se explica cómo llevar a cabo una evaluación basada en modelos por pares con AutoSxS, una herramienta que se ejecuta a través del servicio de la canalización de evaluación. Te explicamos cómo puedes usar AutoSxS a través de la API de Vertex AI, el SDK de Vertex AI para Python o la Google Cloud consola.
AutoSxS
La evaluación automática en paralelo (AutoSxS) es una herramienta de evaluación basada en modelos emparejados que se ejecuta a través del servicio de la canalización de evaluación. AutoSxS se puede usar para evaluar el rendimiento de los modelos de IA generativa en Vertex AI Model Registry o de las predicciones pregeneradas, lo que le permite admitir modelos básicos de Vertex AI, modelos de IA generativa ajustados y modelos de lenguaje de terceros. AutoSxS usa un evaluador automático para decidir qué modelo ofrece la mejor respuesta a una petición. Está disponible bajo demanda y evalúa modelos de lenguaje con un rendimiento comparable al de los evaluadores humanos.
El evaluador automático
A grandes rasgos, el diagrama muestra cómo compara AutoSxS las predicciones de los modelos A y B con un tercer modelo, el evaluador automático.
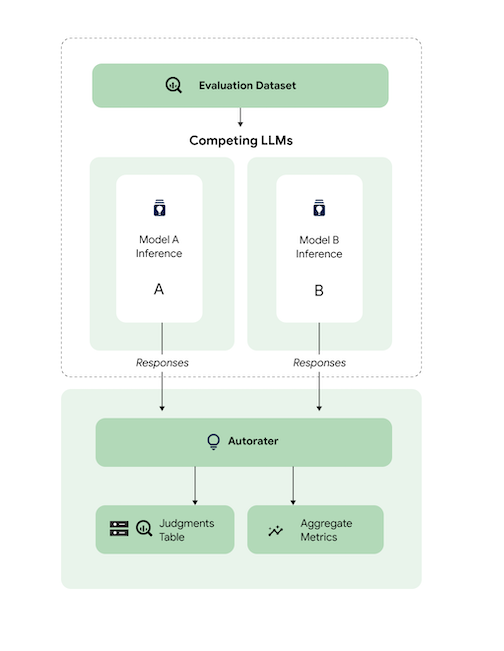
Los modelos A y B reciben peticiones y cada uno genera respuestas que se envían al calificador automático. Al igual que un evaluador humano, un evaluador automático es un modelo de lenguaje que evalúa la calidad de las respuestas del modelo a partir de una petición de inferencia original. Con AutoSxS, el evaluador automático compara la calidad de dos respuestas del modelo en función de su instrucción de inferencia mediante un conjunto de criterios. Los criterios se usan para determinar qué modelo ha dado mejores resultados comparando los resultados del modelo A con los del modelo B. El evaluador automático genera las preferencias de respuesta como métricas agregadas y las explicaciones de las preferencias, así como las puntuaciones de confianza de cada ejemplo. Para obtener más información, consulta la tabla de sentencias.
Modelos admitidos
AutoSxS admite la evaluación de cualquier modelo cuando se proporcionan predicciones pregeneradas. AutoSxS también permite generar respuestas automáticamente para cualquier modelo del registro de modelos de Vertex AI que admita la predicción por lotes en Vertex AI.
Si tu modelo de texto no es compatible con Vertex AI Model Registry, AutoSxS también acepta predicciones pregeneradas almacenadas como JSONL en Cloud Storage o en una tabla de BigQuery. Para obtener información sobre los precios, consulta la sección Generación de texto.
Tareas y criterios admitidos
AutoSxS permite evaluar modelos para tareas de resumen y respuesta a preguntas. Los criterios de evaluación están predefinidos para cada tarea, lo que hace que la evaluación del lenguaje sea más objetiva y mejora la calidad de las respuestas.
Los criterios se indican por tarea.
Creación de resúmenes
La tarea summarization tiene un límite de 4096 tokens
de entrada.
La lista de criterios de evaluación de summarization es la siguiente:
| Criterios | |
|---|---|
| 1. Sigue las instrucciones | ¿En qué medida demuestra el modelo que ha entendido la instrucción de la petición? |
| 2. Fundamentado | ¿La respuesta incluye solo información del contexto y las instrucciones de inferencia? |
| 3. Integral | ¿En qué medida recoge el modelo los detalles clave en el resumen? |
| 4. Breve | ¿La función de resumen es demasiado detallada? ¿Incluye un lenguaje florido? ¿Es demasiado conciso? |
Respuesta a la pregunta
La tarea question_answering tiene un límite de 4096 tokens
de entrada.
La lista de criterios de evaluación de question_answering es la siguiente:
| Criterios | |
|---|---|
| 1. Responde completamente a la pregunta | La respuesta responde a la pregunta por completo. |
| 2. Fundamentado | ¿La respuesta incluye solo información del contexto de la instrucción y de la instrucción de inferencia? |
| 3. Relevancia | ¿El contenido de la respuesta está relacionado con la pregunta? |
| 4. Integral | ¿En qué medida recoge el modelo los detalles clave de la pregunta? |
Preparar el conjunto de datos de evaluación para AutoSxS
En esta sección se detalla la información que debe proporcionar en su conjunto de datos de evaluación de AutoSxS y las prácticas recomendadas para crear conjuntos de datos. Los ejemplos deben reflejar las entradas del mundo real que pueden recibir tus modelos en producción y mostrar el contraste entre el comportamiento de tus modelos activos.
Formato del conjunto de datos
AutoSxS acepta un único conjunto de datos de evaluación con un esquema flexible. El conjunto de datos puede ser una tabla de BigQuery o almacenarse como JSON Lines en Cloud Storage.
Cada fila del conjunto de datos de evaluación representa un ejemplo, y las columnas son de uno de los siguientes tipos:
- Columnas de ID: se usan para identificar cada ejemplo único.
- Columnas de datos: se usan para rellenar plantillas de peticiones. Consulta Parámetros de las peticiones.
- Predicciones pregeneradas: predicciones realizadas por el mismo modelo con la misma petición. Usar predicciones pregeneradas ahorra tiempo y recursos.
- Preferencias humanas validadas: se usan para comparar AutoSxS con tus datos de preferencias validadas cuando se proporcionan predicciones pregeneradas para ambos modelos.
A continuación, se muestra un ejemplo de un conjunto de datos de evaluación en el que context y question son columnas de datos, y model_b_response contiene predicciones pregeneradas.
context |
question |
model_b_response |
|---|---|---|
| Algunos podrían pensar que el acero o el titanio son los materiales más duros, pero en realidad es el diamante. | ¿Cuál es el material más duro? | El diamante es el material más duro. Es más duro que el acero o el titanio. |
Para obtener más información sobre cómo llamar a AutoSxS, consulta Evaluar modelos. Para obtener más información sobre la longitud de los tokens, consulta Tareas y criterios admitidos. Para subir tus datos a Cloud Storage, consulta Subir un conjunto de datos de evaluación a Cloud Storage.
Parámetros de petición
Muchos modelos de lenguaje toman parámetros de peticiones como entradas en lugar de una sola cadena de petición. Por ejemplo, chat-bison toma varios parámetros de petición (mensajes, ejemplos y contexto) que forman parte de la petición. Sin embargo, text-bison solo tiene un parámetro de petición, llamado petición, que contiene toda la petición.
Te explicamos cómo puedes especificar de forma flexible los parámetros de las peticiones de modelos en el momento de la inferencia y la evaluación. AutoSxS te ofrece la flexibilidad de llamar a modelos de lenguaje con entradas esperadas variables a través de parámetros de peticiones con plantillas.
Inferencia
Si alguno de los modelos no tiene predicciones generadas previamente, AutoSxS usa la predicción por lotes de Vertex AI para generar respuestas. Se deben especificar los parámetros de la petición de cada modelo.
En AutoSxS, puedes proporcionar una sola columna del conjunto de datos de evaluación como parámetro de petición.
{'some_parameter': {'column': 'my_column'}}
También puede definir plantillas usando columnas del conjunto de datos de evaluación como variables para especificar parámetros de peticiones:
{'some_parameter': {'template': 'Summarize the following: {{ my_column }}.'}}
Cuando los usuarios proporcionan parámetros de petición de modelo para la inferencia, pueden usar la palabra clave protegida default_instruction como argumento de plantilla, que se sustituye por la instrucción de inferencia predeterminada de la tarea en cuestión:
model_prompt_parameters = {
'prompt': {'template': '{{ default_instruction }}: {{ context }}'},
}
Si vas a generar predicciones, proporciona los parámetros de la petición del modelo y una columna de salida. Consulta los siguientes ejemplos:
Gemini
En el caso de los modelos de Gemini, las claves de los parámetros de las peticiones del modelo son contents (obligatoria) y system_instruction (opcional), que se corresponden con el esquema del cuerpo de la solicitud de Gemini.
model_a_prompt_parameters={
'contents': {
'column': 'context'
},
'system_instruction': {'template': '{{ default_instruction }}'},
},
text-bison
Por ejemplo, text-bison usa "petición" como entrada y "contenido" como salida. Sigue estos pasos:
- Identifica las entradas y salidas que necesitan los modelos que se van a evaluar.
- Define las entradas como parámetros de petición del modelo.
- Transfiere el resultado a la columna de respuesta.
model_a_prompt_parameters={
'prompt': {
'template': {
'Answer the following question from the point of view of a college professor: {{ context }}\n{{ question }}'
},
},
},
response_column_a='content', # Column in Model A response.
response_column_b='model_b_response', # Column in eval dataset.
Evaluación
Al igual que debes proporcionar parámetros de peticiones para la inferencia, también debes proporcionar parámetros de peticiones para la evaluación. autorater requiere los siguientes parámetros de petición:
| Parámetro de petición de Autorater | ¿El usuario puede configurarlo? | Descripción | Ejemplo |
|---|---|---|---|
| Instrucciones para el evaluador automático | No | Una instrucción calibrada que describe los criterios que debe usar el calificador automático para evaluar las respuestas proporcionadas. | Elige la respuesta que responda a la pregunta y siga mejor las instrucciones. |
| Instrucción de inferencia | Sí | Una descripción de la tarea que debe realizar cada modelo candidato. | Responde a la pregunta con precisión: ¿cuál es el material más duro? |
| Contexto de inferencia | Sí | Contexto adicional de la tarea que se está realizando. | Aunque tanto el titanio como el diamante son más duros que el cobre, el diamante tiene una dureza de 98, mientras que el titanio tiene una dureza de 36. Cuanto mayor sea la clasificación, mayor será la dureza. |
| Respuestas | No1 | Un par de respuestas para evaluar, una de cada modelo candidato. | Diamante |
1 Solo puedes configurar el parámetro de petición mediante respuestas pregeneradas.
Código de ejemplo que usa los parámetros:
autorater_prompt_parameters={
'inference_instruction': {
'template': 'Answer the following question from the point of view of a college professor: {{ question }}.'
},
'inference_context': {
'column': 'context'
}
}
Los modelos A y B pueden tener instrucciones de inferencia y contexto con un formato diferente, independientemente de si se proporciona la misma información. Esto significa que el evaluador automático toma una instrucción y un contexto de inferencia independientes, pero únicos.
Ejemplo de conjunto de datos de evaluación
En esta sección se proporciona un ejemplo de un conjunto de datos de evaluación de tareas de preguntas y respuestas, incluidas las predicciones pregeneradas del modelo B. En este ejemplo, AutoSxS solo realiza inferencias para el modelo A. Proporcionamos una columna id para diferenciar los ejemplos que tienen la misma pregunta y el mismo contexto.
{
"id": 1,
"question": "What is the hardest material?",
"context": "Some might think that steel is the hardest material, or even titanium. However, diamond is actually the hardest material.",
"model_b_response": "Diamond is the hardest material. It is harder than steel or titanium."
}
{
"id": 2,
"question": "What is the highest mountain in the world?",
"context": "K2 and Everest are the two tallest mountains, with K2 being just over 28k feet and Everest being 29k feet tall.",
"model_b_response": "Mount Everest is the tallest mountain, with a height of 29k feet."
}
{
"id": 3,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "Francis Ford Coppola directed The Godfather."
}
{
"id": 4,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "John Smith."
}
Prácticas recomendadas
Sigue estas prácticas recomendadas al definir tu conjunto de datos de evaluación:
- Proporciona ejemplos que representen los tipos de entradas que procesan tus modelos en producción.
- El conjunto de datos debe incluir al menos un ejemplo de evaluación. Te recomendamos que uses unos 100 ejemplos para asegurarte de que las métricas agregadas sean de alta calidad. La tasa de mejoras de calidad de las métricas agregadas tiende a disminuir cuando se proporcionan más de 400 ejemplos.
- Para obtener una guía sobre cómo escribir peticiones, consulta Diseñar peticiones de texto.
- Si usas predicciones pregeneradas para cualquiera de los modelos, inclúyelas en una columna de tu conjunto de datos de evaluación. Proporcionar predicciones pregeneradas es útil porque te permite comparar la salida de modelos que no están en Vertex Model Registry y reutilizar respuestas.
Realizar una evaluación del modelo
Puedes evaluar modelos mediante la API REST, el SDK de Vertex AI para Python o laGoogle Cloud consola.
Utiliza esta sintaxis para especificar la ruta a tu modelo:
- Modelo de editor:
publishers/PUBLISHER/models/MODELEjemplo:publishers/google/models/text-bison Modelo ajustado:
projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL@VERSIONEjemplo:projects/123456789012/locations/us-central1/models/1234567890123456789
REST
Para crear una tarea de evaluación de modelos, envía una solicitud POST con el método pipelineJobs.
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- PIPELINEJOB_DISPLAYNAME : nombre visible de
pipelineJob. - PROJECT_ID : Google Cloud proyecto que ejecuta los componentes de la canalización.
- LOCATION : región en la que se ejecutarán los componentes del flujo de procesamiento. Se admite
us-central1. - OUTPUT_DIR : URI de Cloud Storage para almacenar la salida de la evaluación.
- EVALUATION_DATASET : tabla de BigQuery o lista separada por comas de rutas de Cloud Storage a un conjunto de datos JSONL que contenga ejemplos de evaluación.
- TASK: tarea de evaluación, que puede ser una de las siguientes:
[summarization, question_answering]. - ID_COLUMNS : columnas que distinguen ejemplos de evaluación únicos.
- AUTORATER_PROMPT_PARAMETERS : parámetros de peticiones de Autorater asignados a columnas o plantillas. Los parámetros esperados son
inference_instruction(detalles sobre cómo realizar una tarea) yinference_context(contenido de referencia para realizar la tarea). Por ejemplo,{'inference_context': {'column': 'my_prompt'}}usa la columna `my_prompt` del conjunto de datos de evaluación para el contexto del evaluador automático. - RESPONSE_COLUMN_A : el nombre de una columna del conjunto de datos de evaluación que contiene predicciones predefinidas o el nombre de la columna de la salida del modelo A que contiene predicciones. Si no se proporciona ningún valor, se intentará inferir el nombre de la columna de salida del modelo correcto.
- RESPONSE_COLUMN_B : el nombre de una columna del conjunto de datos de evaluación que contiene predicciones predefinidas o el nombre de la columna de la salida del modelo B que contiene predicciones. Si no se proporciona ningún valor, se intentará inferir el nombre de la columna de salida del modelo correcto.
- MODEL_A (Opcional): Nombre de recurso de modelo completo (
projects/{project}/locations/{location}/models/{model}@{version}) o nombre de recurso de modelo de editor (publishers/{publisher}/models/{model}). Si se especifican respuestas del modelo A, no se debe proporcionar este parámetro. - MODEL_B (Opcional): Nombre de recurso de modelo completo (
projects/{project}/locations/{location}/models/{model}@{version}) o nombre de recurso de modelo de editor (publishers/{publisher}/models/{model}). Si se especifican respuestas del modelo B, no se debe proporcionar este parámetro. - MODEL_A_PROMPT_PARAMETERS (Opcional): parámetros de la plantilla de petición de Modelo A asignados a columnas o plantillas. Si las respuestas del modelo A están predefinidas, no se debe proporcionar este parámetro. Ejemplo:
{'prompt': {'column': 'my_prompt'}}usa la columnamy_promptdel conjunto de datos de evaluación para el parámetro de petición llamadoprompt. - MODEL_B_PROMPT_PARAMETERS (Opcional): parámetros de la plantilla de petición del modelo B asignados a columnas o plantillas. Si las respuestas del modelo B están predefinidas, no se debe proporcionar este parámetro. Ejemplo:
{'prompt': {'column': 'my_prompt'}}usa la columnamy_promptdel conjunto de datos de evaluación para el parámetro de petición llamadoprompt. - JUDGMENTS_FORMAT
(Opcional): el formato en el que se escribirán los juicios. Puede ser
jsonl(valor predeterminado),jsonobigquery. - BIGQUERY_DESTINATION_PREFIX: tabla de BigQuery en la que se escribirán las valoraciones si el formato especificado es
bigquery.
Cuerpo JSON de la solicitud
{
"displayName": "PIPELINEJOB_DISPLAYNAME",
"runtimeConfig": {
"gcsOutputDirectory": "gs://OUTPUT_DIR",
"parameterValues": {
"evaluation_dataset": "EVALUATION_DATASET",
"id_columns": ["ID_COLUMNS"],
"task": "TASK",
"autorater_prompt_parameters": AUTORATER_PROMPT_PARAMETERS,
"response_column_a": "RESPONSE_COLUMN_A",
"response_column_b": "RESPONSE_COLUMN_B",
"model_a": "MODEL_A",
"model_a_prompt_parameters": MODEL_A_PROMPT_PARAMETERS,
"model_b": "MODEL_B",
"model_b_prompt_parameters": MODEL_B_PROMPT_PARAMETERS,
"judgments_format": "JUDGMENTS_FORMAT",
"bigquery_destination_prefix":BIGQUERY_DESTINATION_PREFIX,
},
},
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default"
}
Usa curl para enviar tu solicitud.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/pipelineJobs"
Respuesta
"state": "PIPELINE_STATE_PENDING",
"labels": {
"vertex-ai-pipelines-run-billing-id": "1234567890123456789"
},
"runtimeConfig": {
"gcsOutputDirectory": "gs://my-evaluation-bucket/output",
"parameterValues": {
"evaluation_dataset": "gs://my-evaluation-bucket/output/data.json",
"id_columns": [
"context"
],
"task": "question_answering",
"autorater_prompt_parameters": {
"inference_instruction": {
"template": "Answer the following question: {{ question }} }."
},
"inference_context": {
"column": "context"
}
},
"response_column_a": "",
"response_column_b": "response_b",
"model_a": "publishers/google/models/text-bison@002",
"model_a_prompt_parameters": {
"prompt": {
"template": "Answer the following question from the point of view of a college professor: {{ question }}\n{{ context }} }"
}
},
"model_b": "",
"model_b_prompt_parameters": {}
}
},
"serviceAccount": "123456789012-compute@developer.gserviceaccount.com",
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default",
"templateMetadata": {
"version": "sha256:7366b784205551ed28f2c076e841c0dbeec4111b6df16743fc5605daa2da8f8a"
}
}
SDK de Vertex AI para Python
Para saber cómo instalar o actualizar el SDK de Vertex AI para Python, consulta el artículo Instalar el SDK de Vertex AI para Python. Para obtener más información sobre la API de Python, consulta la API del SDK de Vertex AI para Python.
Para obtener más información sobre los parámetros de los flujos de procesamiento, consulta la documentación de referencia de los componentes de flujos de procesamiento de Google Cloud.
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- PIPELINEJOB_DISPLAYNAME : nombre visible de
pipelineJob. - PROJECT_ID : Google Cloud proyecto que ejecuta los componentes de la canalización.
- LOCATION : región en la que se ejecutarán los componentes del flujo de procesamiento. Se admite
us-central1. - OUTPUT_DIR : URI de Cloud Storage para almacenar la salida de la evaluación.
- EVALUATION_DATASET : tabla de BigQuery o lista separada por comas de rutas de Cloud Storage a un conjunto de datos JSONL que contenga ejemplos de evaluación.
- TASK: tarea de evaluación, que puede ser una de las siguientes:
[summarization, question_answering]. - ID_COLUMNS : columnas que distinguen ejemplos de evaluación únicos.
- AUTORATER_PROMPT_PARAMETERS : parámetros de peticiones de Autorater asignados a columnas o plantillas. Los parámetros esperados son
inference_instruction(detalles sobre cómo realizar una tarea) yinference_context(contenido de referencia para realizar la tarea). Por ejemplo,{'inference_context': {'column': 'my_prompt'}}usa la columna `my_prompt` del conjunto de datos de evaluación para el contexto del evaluador automático. - RESPONSE_COLUMN_A : el nombre de una columna del conjunto de datos de evaluación que contiene predicciones predefinidas o el nombre de la columna de la salida del modelo A que contiene predicciones. Si no se proporciona ningún valor, se intentará inferir el nombre de la columna de salida del modelo correcto.
- RESPONSE_COLUMN_B : el nombre de una columna del conjunto de datos de evaluación que contiene predicciones predefinidas o el nombre de la columna de la salida del modelo B que contiene predicciones. Si no se proporciona ningún valor, se intentará inferir el nombre de la columna de salida del modelo correcto.
- MODEL_A (Opcional): Nombre de recurso de modelo completo (
projects/{project}/locations/{location}/models/{model}@{version}) o nombre de recurso de modelo de editor (publishers/{publisher}/models/{model}). Si se especifican respuestas del modelo A, no se debe proporcionar este parámetro. - MODEL_B (Opcional): Nombre de recurso de modelo completo (
projects/{project}/locations/{location}/models/{model}@{version}) o nombre de recurso de modelo de editor (publishers/{publisher}/models/{model}). Si se especifican respuestas del modelo B, no se debe proporcionar este parámetro. - MODEL_A_PROMPT_PARAMETERS (Opcional): parámetros de la plantilla de petición de Modelo A asignados a columnas o plantillas. Si las respuestas del modelo A están predefinidas, no se debe proporcionar este parámetro. Ejemplo:
{'prompt': {'column': 'my_prompt'}}usa la columnamy_promptdel conjunto de datos de evaluación para el parámetro de petición llamadoprompt. - MODEL_B_PROMPT_PARAMETERS (Opcional): parámetros de la plantilla de petición del modelo B asignados a columnas o plantillas. Si las respuestas del modelo B están predefinidas, no se debe proporcionar este parámetro. Ejemplo:
{'prompt': {'column': 'my_prompt'}}usa la columnamy_promptdel conjunto de datos de evaluación para el parámetro de petición llamadoprompt. - JUDGMENTS_FORMAT
(Opcional): el formato en el que se escribirán los juicios. Puede ser
jsonl(valor predeterminado),jsonobigquery. - BIGQUERY_DESTINATION_PREFIX: tabla de BigQuery en la que se escribirán las valoraciones si el formato especificado es
bigquery.
import os
from google.cloud import aiplatform
parameters = {
'evaluation_dataset': 'EVALUATION_DATASET',
'id_columns': ['ID_COLUMNS'],
'task': 'TASK',
'autorater_prompt_parameters': AUTORATER_PROMPT_PARAMETERS,
'response_column_a': 'RESPONSE_COLUMN_A',
'response_column_b': 'RESPONSE_COLUMN_B',
'model_a': 'MODEL_A',
'model_a_prompt_parameters': MODEL_A_PROMPT_PARAMETERS,
'model_b': 'MODEL_B',
'model_b_prompt_parameters': MODEL_B_PROMPT_PARAMETERS,
'judgments_format': 'JUDGMENTS_FORMAT',
'bigquery_destination_prefix':
BIGQUERY_DESTINATION_PREFIX,
}
aiplatform.init(project='PROJECT_ID', location='LOCATION', staging_bucket='gs://OUTPUT_DIR')
aiplatform.PipelineJob(
display_name='PIPELINEJOB_DISPLAYNAME',
pipeline_root=os.path.join('gs://OUTPUT_DIR', 'PIPELINEJOB_DISPLAYNAME'),
template_path=(
'https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default'),
parameter_values=parameters,
).run()
Consola
Para crear un trabajo de evaluación de modelos por pares mediante la Google Cloud consola, sigue estos pasos:
Empieza con un modelo básico de Google o usa un modelo que ya esté en tu registro de modelos de Vertex AI:
Para evaluar un modelo básico de Google, sigue estos pasos:
Ve a Model Garden de Vertex AI y selecciona un modelo que admita la evaluación por pares, como
text-bison.Haz clic en Evaluar.
En el menú que aparece, haz clic en Seleccionar para elegir una versión del modelo.
En el panel Guardar modelo, se te pedirá que guardes una copia del modelo en el registro de modelos de Vertex AI si aún no tienes una. Introduce un Nombre del modelo y haz clic en Guardar.
Aparecerá la página Crear evaluación. En el paso Método de evaluación, selecciona Evaluar este modelo con otro modelo.
Haz clic en Continuar.
Para evaluar un modelo que ya tengas en el registro de modelos de Vertex AI, sigue estos pasos:
Ve a la página Registro de modelos de Vertex AI:
Haz clic en el nombre del modelo que quieras evaluar. Asegúrate de que el tipo de modelo admita la evaluación por pares. Por ejemplo,
text-bison.En la pestaña Evaluar, haz clic en SxS.
Haz clic en Crear evaluación SxS.
En cada paso de la página de creación de la evaluación, introduce la información que se te pida y haz clic en Continuar:
En el paso Conjunto de datos de evaluación, selecciona un objetivo de evaluación y un modelo para compararlo con el modelo que has seleccionado. Selecciona un conjunto de datos de evaluación e introduce las columnas de ID (columnas de respuesta).
En el paso Configuración del modelo, especifica si quieres usar las respuestas del modelo que ya están en tu conjunto de datos o si quieres usar la predicción por lotes de Vertex AI para generar las respuestas. Especifica las columnas de respuesta de ambos modelos. En la opción de predicción por lotes de Vertex AI, puedes especificar los parámetros de la petición del modelo de inferencia.
En el paso Ajustes de Autorater, introduce los parámetros de la petición de Autorater y una ubicación de salida para las evaluaciones.
Haz clic en Iniciar evaluación.
Ver los resultados de la evaluación
Puedes encontrar los resultados de la evaluación en Vertex AI Pipelines. Para ello, inspecciona los siguientes artefactos generados por la canalización AutoSxS:
- La tabla judgments se genera mediante el árbitro de AutoSxS.
- El componente de métricas AutoSxS genera métricas agregadas.
- El componente de métricas AutoSxS genera las métricas de alineación de preferencias humanas.
Sentencias
AutoSxS genera juicios (métricas a nivel de ejemplo) que ayudan a los usuarios a comprender el rendimiento del modelo a nivel de ejemplo. Las sentencias incluyen la siguiente información:
- Peticiones de inferencia
- Respuestas del modelo
- Decisiones de Autorater
- Explicaciones sobre las clasificaciones
- Puntuaciones de confianza
Los juicios se pueden escribir en Cloud Storage en formato JSONL o en una tabla de BigQuery con estas columnas:
| Columna | Descripción |
|---|---|
| columnas de ID | Columnas que distinguen ejemplos de evaluación únicos. |
inference_instruction |
Instrucción usada para generar respuestas del modelo. |
inference_context |
Contexto usado para generar respuestas del modelo. |
response_a |
Respuesta del modelo A, teniendo en cuenta la instrucción de inferencia y el contexto. |
response_b |
Respuesta del modelo B, teniendo en cuenta las instrucciones de inferencia y el contexto. |
choice |
El modelo con la mejor respuesta. Los valores posibles son Model A, Model B o Error. Error significa que se ha producido un error que ha impedido que el evaluador automático determine si la respuesta del modelo A o la del modelo B era la mejor. |
confidence |
Una puntuación entre 0 y 1 que indica el grado de confianza del corrector automático en su elección. |
explanation |
El motivo por el que el evaluador automático ha tomado esa decisión. |
Métricas globales
AutoSxS calcula las métricas agregadas (tasa de victorias) mediante la tabla de juicios. Si no se proporcionan datos de preferencias humanas, se generan las siguientes métricas agregadas:
| Métrica | Descripción |
|---|---|
| Tasa de victorias del modelo A de AutoRater | Porcentaje de tiempo que el evaluador automático ha determinado que el modelo A tenía la mejor respuesta. |
| Tasa de victorias del modelo B de AutoRater | Porcentaje del tiempo en el que el evaluador automático ha determinado que el modelo B tenía una mejor respuesta. |
Para entender mejor la tasa de victorias, consulta los resultados basados en filas y las explicaciones del evaluador automático para determinar si los resultados y las explicaciones se ajustan a tus expectativas.
Métricas de alineación de preferencias humanas
Si se proporcionan datos de preferencias humanas, AutoSxS genera las siguientes métricas:
| Métrica | Descripción | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tasa de victorias del modelo A de AutoRater | Porcentaje de tiempo que el evaluador automático ha determinado que el modelo A tenía la mejor respuesta. | ||||||||||||||
| Tasa de victorias del modelo B de AutoRater | Porcentaje del tiempo en el que el evaluador automático ha determinado que el modelo B tenía una mejor respuesta. | ||||||||||||||
| Tasa de victorias del modelo A de preferencias humanas | Porcentaje de tiempo en el que los humanos decidieron que el modelo A tenía la mejor respuesta. | ||||||||||||||
| Tasa de victorias del modelo B de preferencias humanas | Porcentaje de tiempo en el que los humanos decidieron que el modelo B tenía la mejor respuesta. | ||||||||||||||
| TP | Número de ejemplos en los que tanto la valoración automática como las preferencias humanas indicaban que el modelo A ofrecía una mejor respuesta. | ||||||||||||||
| FP | Número de ejemplos en los que el evaluador automático eligió el modelo A como la mejor respuesta, pero la preferencia humana era que el modelo B tenía la mejor respuesta. | ||||||||||||||
| TN | Número de ejemplos en los que tanto el evaluador automático como las preferencias humanas indicaban que el modelo B ofrecía una mejor respuesta. | ||||||||||||||
| FN | Número de ejemplos en los que el evaluador automático eligió el modelo B como la mejor respuesta, pero la preferencia humana era que el modelo A tenía la mejor respuesta. | ||||||||||||||
| Precisión | Porcentaje del tiempo en el que el sistema de valoración automática ha coincidido con los valoradores humanos. | ||||||||||||||
| Precisión | Porcentaje de tiempo en el que tanto el evaluador automático como los humanos han considerado que el modelo A ha ofrecido una mejor respuesta, de todos los casos en los que el evaluador automático ha considerado que el modelo A ha ofrecido una mejor respuesta. | ||||||||||||||
| Recuperación | Porcentaje de tiempo en el que tanto el evaluador automático como los humanos pensaron que el modelo A tenía una mejor respuesta, de todos los casos en los que los humanos pensaron que el modelo A tenía una mejor respuesta. | ||||||||||||||
| F1 | Indica la media armónica de precisión y recuperación. | ||||||||||||||
| Kappa de Cohen | Medida de la concordancia entre el evaluador automático y los evaluadores humanos que tiene en cuenta la probabilidad de que la concordancia se produzca de forma aleatoria. Cohen sugiere la siguiente interpretación:
|
Casos prácticos de AutoSxS
Puedes descubrir cómo usar AutoSxS con tres casos prácticos.
Comparar modelos
Evalúa un modelo propio (1P) ajustado en comparación con un modelo propio de referencia.
Puedes especificar que la inferencia se ejecute en ambos modelos simultáneamente.
Este código de ejemplo evalúa un modelo optimizado de Vertex Model Registry con respecto a un modelo de referencia del mismo registro.
# Evaluation dataset schema:
# my_question: str
# my_context: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'model_a': 'publishers/google/models/text-bison@002',
'model_a_prompt_parameters': {QUESTION: {'template': '{{my_question}}\nCONTEXT: {{my_context}}'}},
'response_column_a': 'content',
'model_b': 'projects/abc/locations/abc/models/tuned_bison',
'model_b_prompt_parameters': {'prompt': {'template': '{{my_context}}\n{{my_question}}'}},
'response_column_b': 'content',
}
Comparar predicciones
Evalúa un modelo de terceros ajustado en comparación con un modelo de terceros de referencia.
Puedes omitir la inferencia proporcionando directamente las respuestas del modelo.
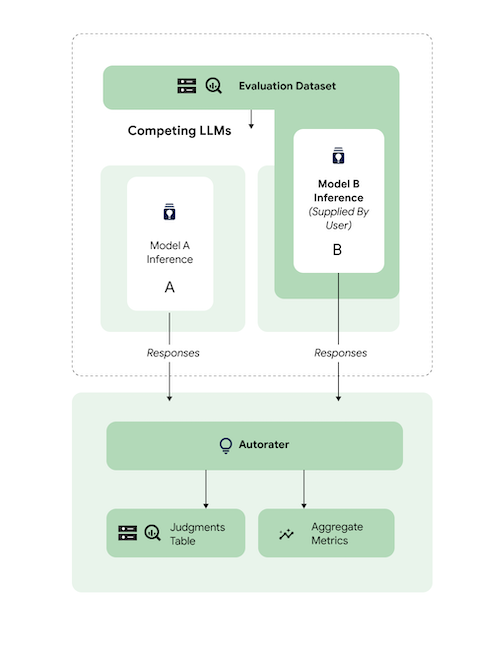
Este código de ejemplo evalúa un modelo de terceros optimizado con respecto a un modelo de terceros de referencia.
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_b: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters':
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'content',
'response_column_b': 'response_b',
}
Comprobar la alineación
Todas las tareas admitidas se han comparado con datos de evaluadores humanos para asegurar que las respuestas de la evaluación automática se ajusten a las preferencias de los humanos. Si quieres comparar AutoSxS con tus casos prácticos, proporciona datos de preferencias humanas directamente a AutoSxS, que genera estadísticas agregadas de alineación.
Para comprobar la alineación con un conjunto de datos de preferencias humanas, puedes especificar ambas salidas (resultados de predicción) en el evaluador automático. También puedes proporcionar tus resultados de inferencia.
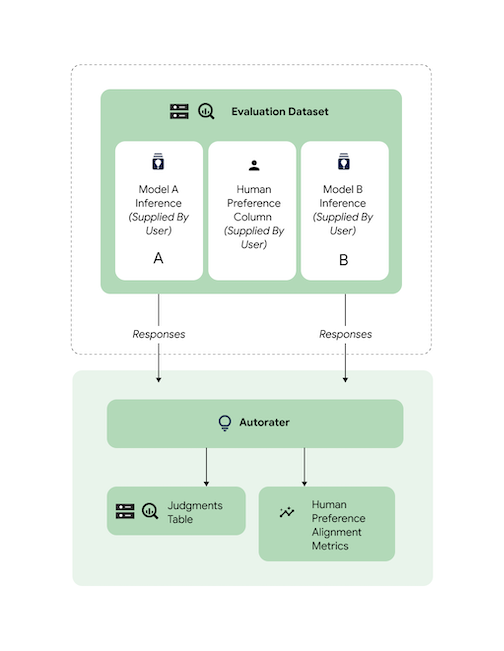
Este ejemplo de código verifica que los resultados y las explicaciones del evaluador automático se ajustan a tus expectativas.
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_a: str
# response_b: str
# actual: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'response_a',
'response_column_b': 'response_b',
'human_preference_column': 'actual',
}
Siguientes pasos
- Consulta información sobre la evaluación de la IA generativa.
- Consulta información sobre la evaluación online con el servicio de evaluación de la IA generativa.
- Consulta cómo ajustar modelos de cimentación de lenguaje.