テキスト、画像、動画のデータについては、ラベル付きデータをインポートできます。またはラベルなしデータをインポートし、Google Cloud コンソールを使用してラベルを追加することもできます。既存のラベル付きデータセットに対して、ラベルを削除または新しいラベルを追加することもできます。
データをインポートする方法については、トレーニングの概要ページで、扱うデータのタイプと目的のデータを準備するページをご覧ください。データのタイプと目的に応じて、それぞれのデータセットの作成ページに進みます。
データセットを作成してラベルなしデータをインポートすると、[ブラウズ] モードになります。

ラベルを追加する方法
ラベルを付ける手順を、データタイプごとに説明します。
画像
データセットにインポートしたばかりの画像には、もちろんラベルは付いていません。
分類
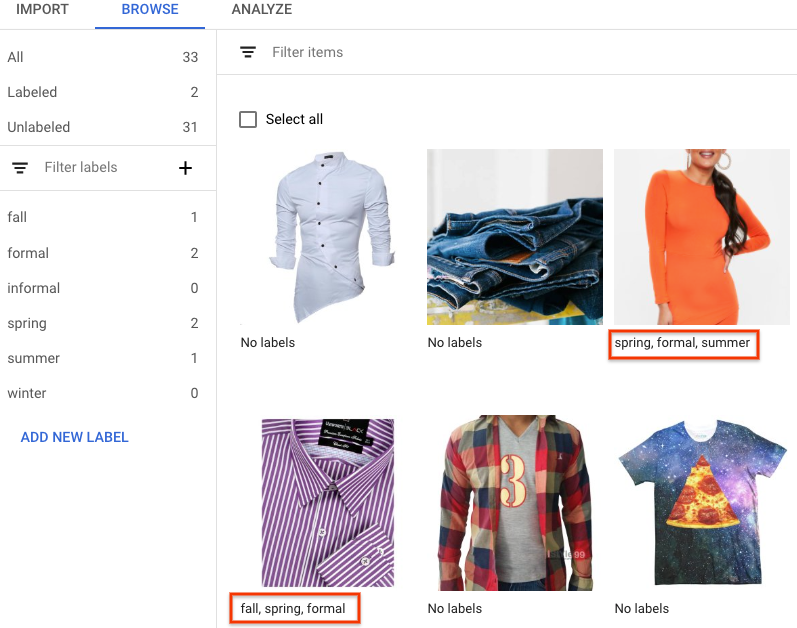
[ブラウズ] モードで、ラベルのない画像を含むデータセットを選択すると、アップロードされている画像が表示されます。
- [新しいラベルを追加] をクリックし、新しいラベルを入力します。
- [完了] をクリックします。
追加するラベルごとに手順を繰り返します。 - ラベルを付ける画像を選択します。
ラベルのリストが表示されます。 - 画像に関連付けるラベルを選択します。
- [保存] をクリックします。
分類
[ブラウズ] モードで、ラベルのない画像を含むデータセットを選択すると、アップロードされている画像が表示されます。
- [新しいラベルを追加] をクリックし、新しいラベルを入力します。
- [完了] をクリックします。
追加するラベルごとに手順を繰り返します。 - ラベルを付ける画像を選択します。
ラベルのリストが表示されます。 - 画像に関連付けるラベルを選択します。
- [保存] をクリックします。
- 各画像に適用されたラベルは [参照] タブで確認できます。
オブジェクト検出
[ブラウズ] モードで、ラベルのない画像を含むデータセットを選択すると、アップロードされている画像が表示されます。
- [新しいラベルを追加] をクリックし、新しいラベルを入力します。
- [完了] をクリックします。
追加するラベルごとに手順を繰り返します。 - ラベルを付ける画像を選択します。
- ラベル オブジェクトのリストが表示されます(存在する場合)。
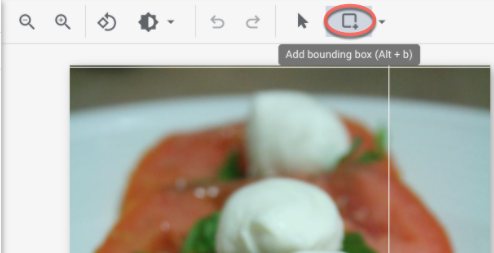
- [アノテーションの追加] ウィンドウで、[境界ボックスを追加] ボタンを選択して、画像にオブジェクト境界ボックスを追加します。
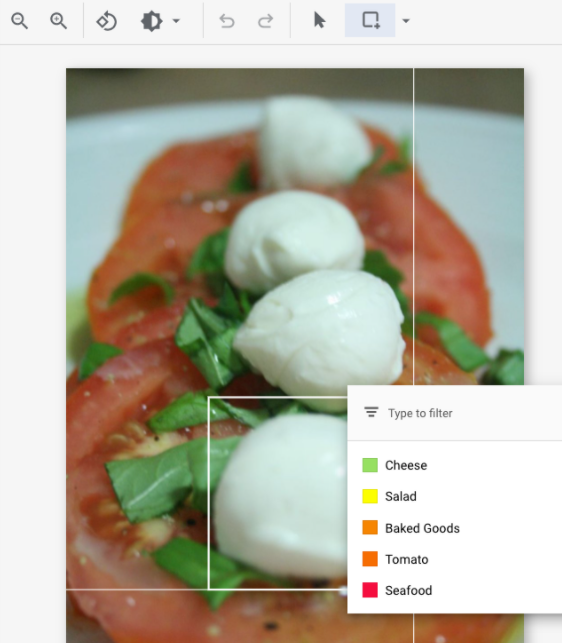
- 境界ボックスを描画すると、オブジェクトに適用できるラベルのリストが表示されます。適切なラベルを選択します。
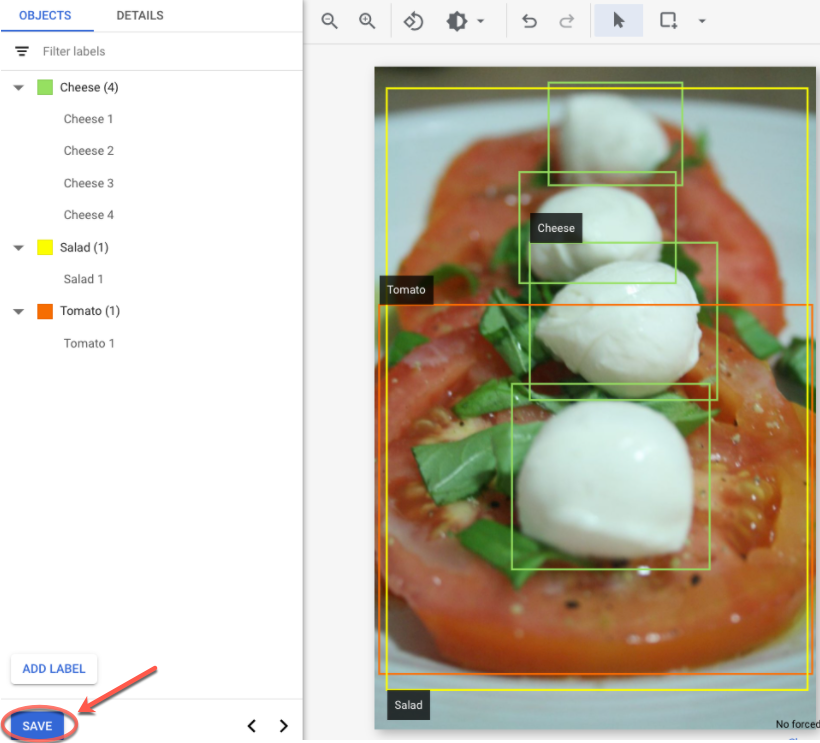
- すべてのラベルと境界ボックスを追加したら、[保存] をクリックして画像のアノテーションを更新します。
テキスト
データセットにインポートしたばかりのテキストには、ラベルが付いていない場合があります。
単一ラベル分類
- ラベルを付けるテキストをクリックします。
- 新しいラベルを追加するには、[ラベルを追加] をクリックします。
- 単一ラベル分類データセットの場合は、テキストに関連付けるラベルを 1 つ選択します。
- [保存] をクリックします。
マルチラベル分類
- ラベルを付けるテキストをクリックします。
- 新しいラベルを追加するには、[ラベルを追加] をクリックします。
- マルチラベル分類データセットの場合、テキストに関連付けるラベルを 1 つ以上選択します。
- [保存] をクリックします。
エンティティの抽出
- ラベルを付けるテキストをクリックします。
- 新しいラベルを追加するには、[ラベルを追加] をクリックします。
- ラベルを付ける単語を選択します(複数可)。
- 選択したテキストに関連付けるラベルを選択します。
- [保存] をクリックします。
感情分析
- ラベルを付けるテキストをクリックします。
- 新しいラベルを追加するには、[ラベルを追加] をクリックします。
- テキストに関連付けるスコアを選択します。
- [保存] をクリックします。
動画
データセットにインポートした動画には、想定されるとおりラベルは付加されていません。
- 新しいデータセットに移動するには、ナビゲーション メニューで [データセット] をクリックします。
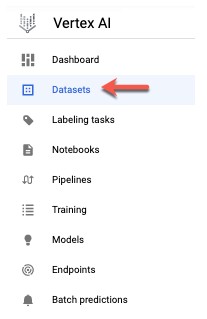
- ラベルを追加するデータセットを選択します。
データセットが表示されます。
動作認識
[ブラウズ] モードで、ラベルのない動画を含むデータセットを選択すると、動画が表示されます。
- ラベルを追加します。
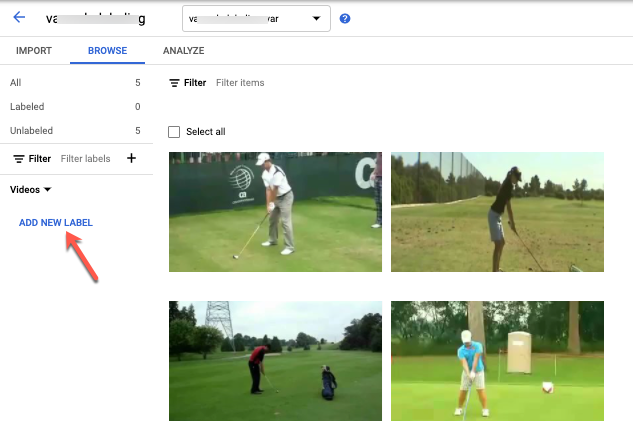
- 動画を選択して視聴を開始します。
- 特定したい動作が表示され始めたら、[次のフレーム] オプションを使用して、動作の中心(その動作を最も代表する時点)までゆっくり進めます。
- [アノテーションを追加] をクリックします。
ラベルのリストが表示されます。 - この動画セグメントに適用するラベルを選択します。
- [保存] をクリックします。
分類
ラベルのない動画を含むデータセットを選択すると、動画が表示されます。
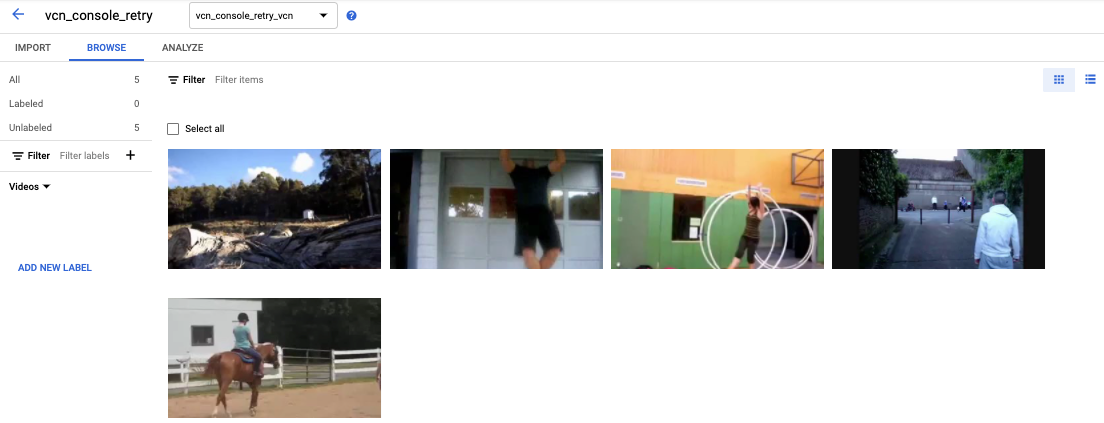
- ラベルを追加します。
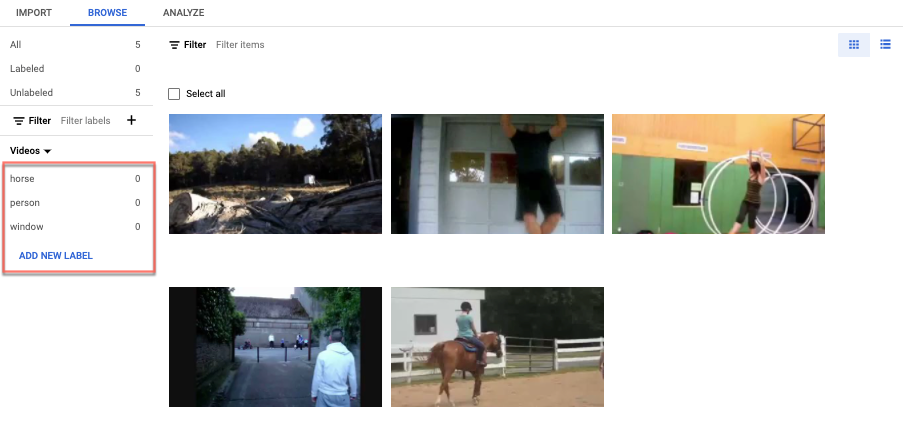
- ラベルを付ける動画を選択します。動画と、その下に色分けされたラベルのリストが表示されます。
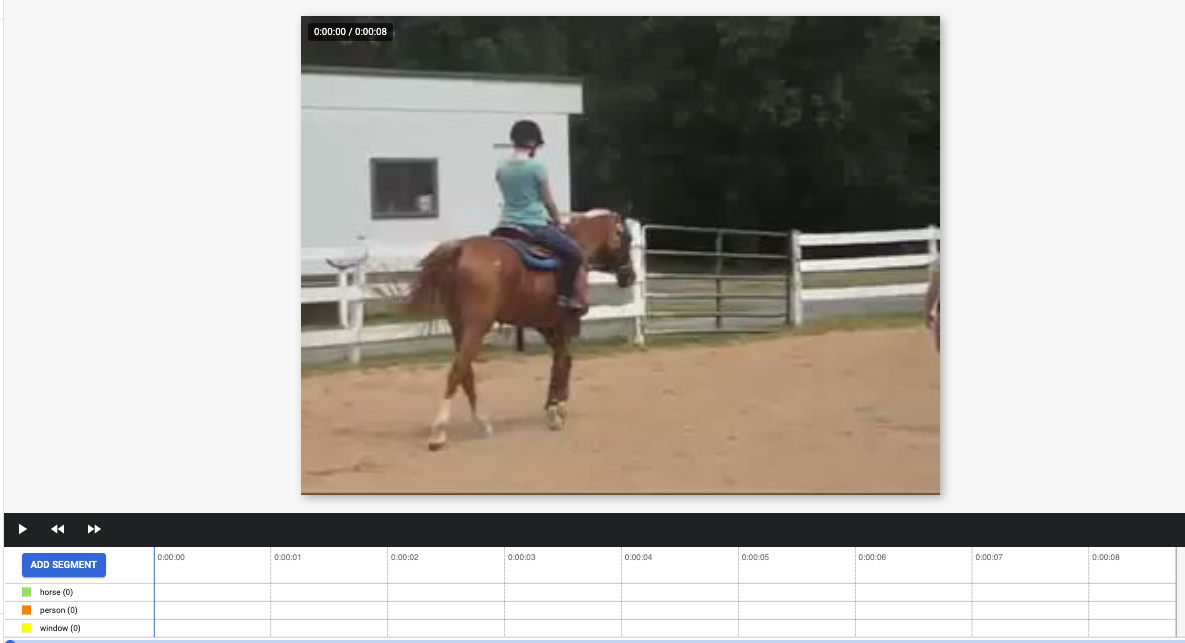
- セグメントの開始点に移動します。[セグメントを追加] をクリックします。
- セグメントを選択します。調整して、特定のラベルのトレーニングに使用するセグメントを指定します。
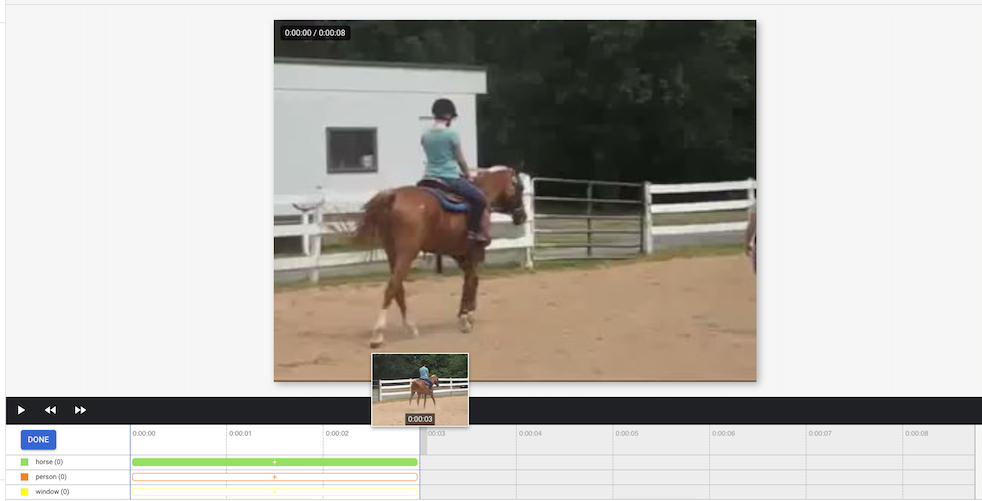
- ラベルを選択します。1 つのセグメントに複数のラベルを選択できます。
- [完了] をクリックして、[保存] をクリックします。
- この手順を繰り返して、同じ動画に時間セグメントの異なる別のラベルを追加します。次の例では、さらに 2 つのラベルを追加しています。

- セグメントを選択します。調整して、特定のラベルのトレーニングに使用するセグメントを指定します。
- [データセット] リストに戻り、繰り返します。
オブジェクト トラッキング
[ブラウズ] モードで、ラベルのない動画を含むデータセットを選択すると、動画が表示されます。

- [ラベルを追加] をクリックして、使用する予定のラベル(「sedan」、「pickup」、「SUV」など)を追加します。
- [保存] をクリックします。後でラベルを追加する必要がある場合は、[新しいラベルを追加] をクリックし、[保存] をクリックします。
- 動画を選択して視聴を開始します。
- トラッキングするオブジェクトが表示されたら、
- 動画を停止します。
- 境界ボックスを左上隅から右下隅にドラッグします。オブジェクトの周囲を、できる限りタイトに囲むようにボックスを描画してください。
境界ボックスの右下にラベルのリストが表示されます。 - 適切なラベルを選択します。
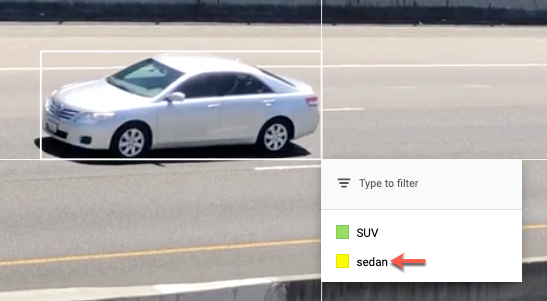 注: このプロセス中でいつでもラベルを追加できます。今後リストに表示されるように、追加したラベルは必ず保存してください。
注: このプロセス中でいつでもラベルを追加できます。今後リストに表示されるように、追加したラベルは必ず保存してください。 - [保存] をクリックします。