Dopo aver addestrato un modello, AutoML Translation utilizza gli elementi della classe TEST per valutare la qualità e l'accuratezza nuovo modello. AutoML Translation esprime la qualità del modello utilizzando la sua tecnologia BLEU (Bilingual Evaluation Understudy), che indica quanto simile il testo candidato è rappresentato dai testi di riferimento, con valori più vicini a uno che rappresentano testi più simili.
Il punteggio BLEU fornisce una valutazione complessiva della qualità del modello. Puoi anche valuta l'output del modello per specifici elementi di dati esportando il file TEST impostate con le previsioni del modello. I dati esportati includono il testo di riferimento (dal set di dati originale) e il testo candidato del modello.
Usa questi dati per valutare l'idoneità del modello. Se non sei soddisfatto del livello qualitativo, prendi in considerazione l'aggiunta di più (e più diversi) coppie di frasi di addestramento. Un'opzione è aggiungere più coppie di frasi. Utilizza il link Aggiungi file nella barra del titolo. Dopo aver aggiunto i file, addestra un nuovo modello facendo clic sul pulsante Addestra nuovo modello nella pagina Addestra. Ripeti fino a quando non raggiungi un livello qualitativo sufficiente.
Recupero della valutazione del modello
UI web
Apri la console Translation di AutoML e fai clic sull'icona a forma di lampadina accanto a Modelli nella barra di navigazione a sinistra. Vengono visualizzati i modelli disponibili. Per ogni modello, le seguenti informazioni sono inclusi: set di dati (da cui è stato addestrato il modello), Origine (lingua), Target (lingua), modello di base (utilizzato per addestrare il modello).
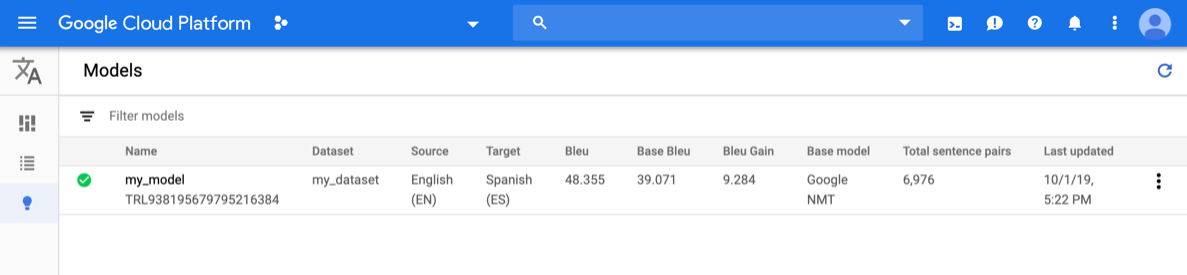
Per visualizzare i modelli di un altro progetto, seleziona il progetto dal menu a discesa in alto a destra nella barra del titolo.
Fai clic sulla riga relativa al modello da valutare.
Viene aperta la scheda Previsione.
Qui puoi testare il tuo modello e vedere i risultati sia per il modello personalizzato e il modello di base utilizzato per l'addestramento.
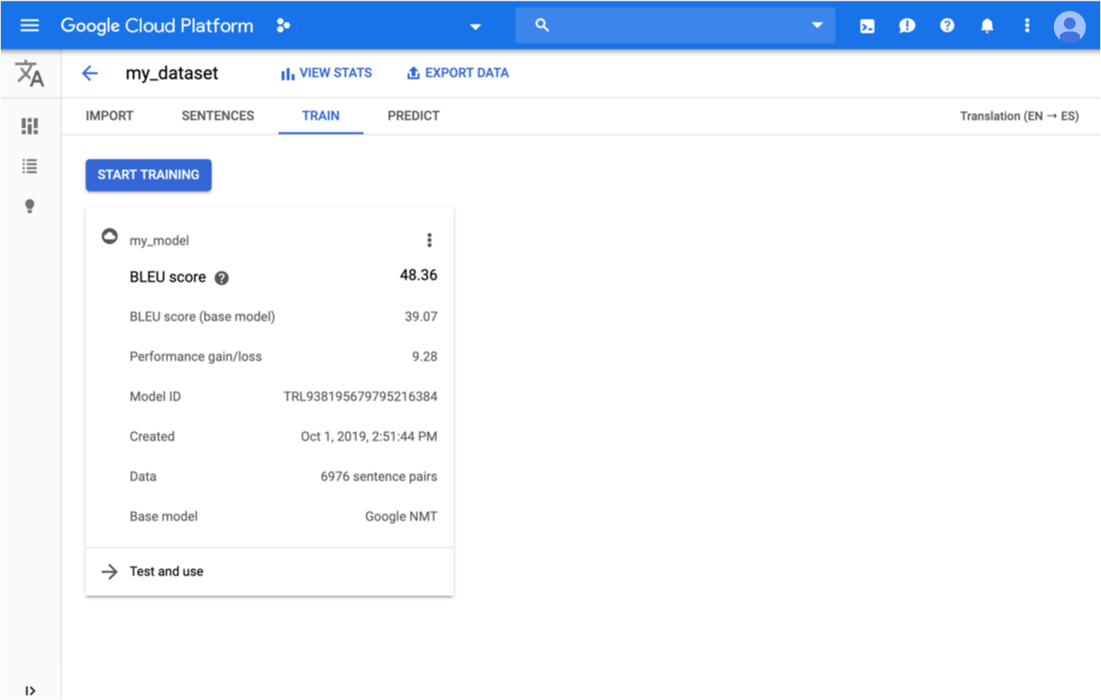
Fai clic sulla scheda Addestra appena sotto la barra del titolo.
Al termine dell'addestramento del modello, AutoML Translation mostra e le metriche di valutazione.
REST
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
- model-name: nome completo del modello. L'intero
del modello include il nome e la località del progetto. R
del modello è simile al seguente esempio:
projects/project-id/locations/us-central1/models/model-id. - project-id: il tuo ID progetto Google Cloud Platform
Metodo HTTP e URL:
GET https://automl.googleapis.com/v1/model-name/modelEvaluations
Per inviare la richiesta, espandi una delle seguenti opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
{
"modelEvaluation": [
{
"name": "projects/project-number/locations/us-central1/models/model-id/modelEvaluations/evaluation-id",
"createTime": "2019-10-02T00:20:30.972732Z",
"evaluatedExampleCount": 872,
"translationEvaluationMetrics": {
"bleuScore": 48.355409502983093,
"baseBleuScore": 39.071375131607056
}
}
]
}
Go
Per scoprire come installare e utilizzare la libreria client per AutoML Translation, consulta Librerie client di AutoML Translation. Per ulteriori informazioni, consulta API AutoML Translation Go documentazione di riferimento.
Per eseguire l'autenticazione su AutoML Translation, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, vedi Configura l'autenticazione per un ambiente di sviluppo locale.
Java
Per scoprire come installare e utilizzare la libreria client per AutoML Translation, consulta Librerie client di AutoML Translation. Per ulteriori informazioni, consulta API AutoML Translation Java documentazione di riferimento.
Per eseguire l'autenticazione su AutoML Translation, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, vedi Configura l'autenticazione per un ambiente di sviluppo locale.
Node.js
Per scoprire come installare e utilizzare la libreria client per AutoML Translation, consulta Librerie client di AutoML Translation. Per ulteriori informazioni, consulta API AutoML Translation Node.js documentazione di riferimento.
Per eseguire l'autenticazione su AutoML Translation, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, vedi Configura l'autenticazione per un ambiente di sviluppo locale.
Python
Per scoprire come installare e utilizzare la libreria client per AutoML Translation, consulta Librerie client di AutoML Translation. Per ulteriori informazioni, consulta API AutoML Translation Python documentazione di riferimento.
Per eseguire l'autenticazione su AutoML Translation, configura le credenziali predefinite dell'applicazione. Per ulteriori informazioni, vedi Configura l'autenticazione per un ambiente di sviluppo locale.
Linguaggi aggiuntivi
C#: Segui le Istruzioni per la configurazione di C# Nella pagina delle librerie client e poi visita Documentazione di riferimento di AutoML Translation per .NET.
PHP Segui le Istruzioni per la configurazione dei file PHP Nella pagina delle librerie client e poi visita Documentazione di riferimento di AutoML Translation per PHP.
Rubino: Segui le Istruzioni per la configurazione di Ruby Nella pagina delle librerie client e poi visita Documentazione di riferimento di AutoML Translation per Ruby.
Esportazione dei dati di test con le previsioni del modello
Dopo l'addestramento di un modello, AutoML Translation utilizza gli elementi TEST set per valutare la qualità e l'accuratezza del nuovo modello. Dalla console AutoML Translation, puoi esportare impostato per confrontare l'output del modello con il testo di riferimento dell'originale del set di dati. AutoML Translation salva un file TSV nel tuo account Google Cloud Storage bucket, dove ogni riga ha questo formato:
Source sentence scheda Reference translation scheda Model candidate translation
UI web
Apri la console Translation di AutoML e fai clic sull'icona a forma di lampadina a sinistra di "Modelli". nel menu di navigazione a sinistra barra per visualizzare i modelli disponibili.
Per visualizzare i modelli di un altro progetto, seleziona il progetto dal menu a discesa in alto a destra nella barra del titolo.
Seleziona il modello.
Fai clic sul pulsante Esporta dati nella barra del titolo.
Inserisci il percorso completo del bucket Google Cloud Storage in cui vuoi salvare il file .tsv esportato.
Devi utilizzare un bucket associato al progetto attuale.
Scegli il modello di cui vuoi esportare i dati TEST.
Nell'elenco a discesa Set di test con previsioni del modello sono elencati i modelli. addestrati utilizzando lo stesso set di dati di input.
Fai clic su Esporta.
AutoML Translation scrive un file denominato model-name
_evaluated.tsvnel bucket Google Cloud Storage specificato.
Valutare e confrontare i modelli utilizzando un nuovo set di test
Dalla console AutoML Translation, puoi rivalutare i modelli esistenti utilizzando un un nuovo set di dati di test. In una singola valutazione, puoi includere fino a 5 diverse di valutazione e confrontare i risultati.
Carica i dati di test in Cloud Storage come file separati da tabulazioni
value (.tsv)
o come memoria di traduzione
eXchange
(.tmx).
AutoML Translation valuta i tuoi modelli rispetto al set di test, quindi produce
punteggi di valutazione. Facoltativamente, puoi salvare i risultati per ogni modello come
.tsv in un bucket Cloud Storage, dove ogni riga contiene quanto segue
formato:
Source sentence tab Model candidate translation tab Reference translation
UI web
Apri la console Translation di AutoML e fai clic su Modelli nel riquadro di navigazione a sinistra per visualizzare di machine learning.
Per visualizzare i modelli di un altro progetto, seleziona il progetto dal nell'elenco a discesa in alto a destra della barra del titolo.
Seleziona uno dei modelli che vuoi valutare.
Fai clic sulla scheda Valuta sotto la barra del titolo.
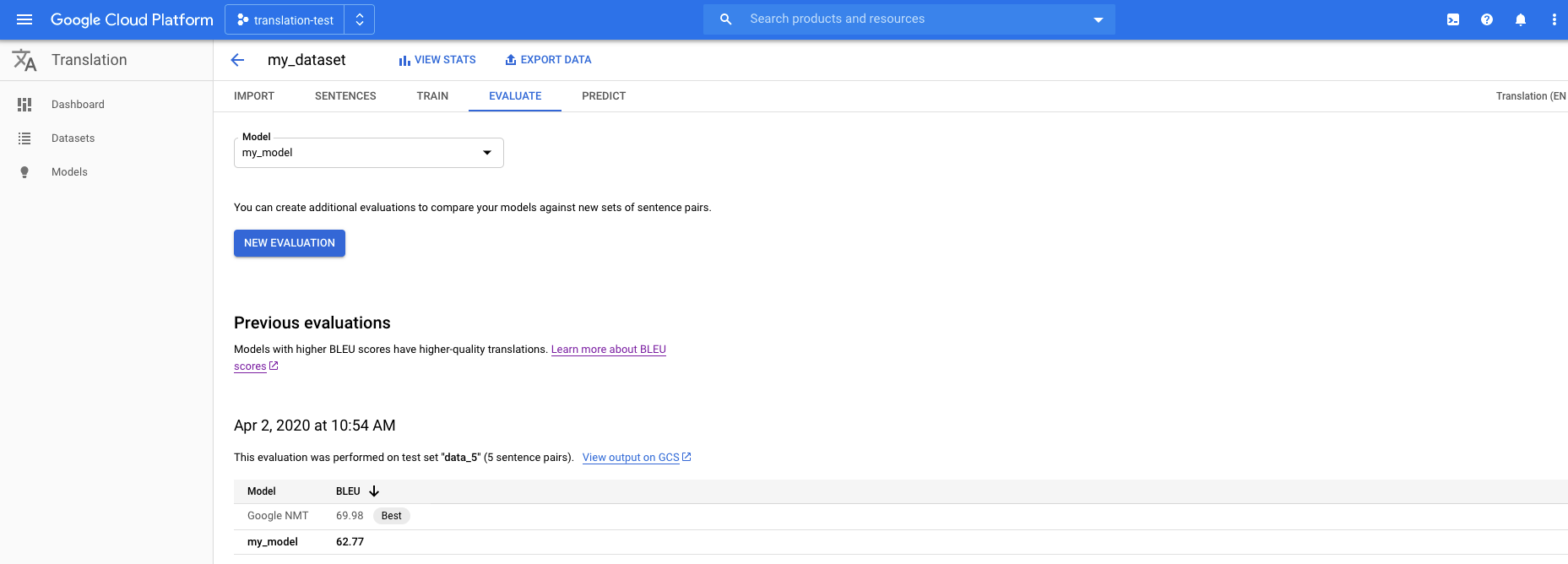
Nella scheda Valuta, fai clic su Nuova valutazione.
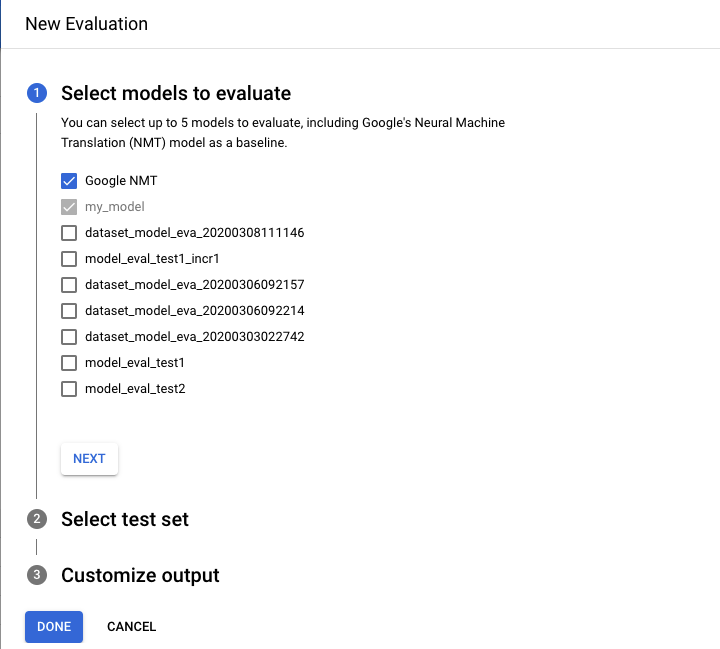
- Seleziona i modelli che vuoi valutare e confrontare. Il modello attuale e Google NMT è selezionata per impostazione predefinita, che puoi deseleziona.
- Specifica un nome per il Nome set di test per distinguerlo dalla altre valutazioni, quindi seleziona il nuovo set di test da Cloud Storage.
- Se vuoi esportare le previsioni basate sul set di test, specificare un bucket Cloud Storage in cui verranno archiviati i risultati (tariffa standard per carattere prezzo .
Fai clic su Fine.
AutoML Translation presenta i punteggi di valutazione in un formato tabella nella console al termine della valutazione. Puoi eseguire una sola valutazione alla volta. Se hai specificato un bucket per archiviare i risultati della previsione, AutoML Translation scrive file denominati model-name_test-set-name
.tsval di sincronizzare la directory di una VM con un bucket.
Comprensione del punteggio BLEU
BLEU (Esiingual Evaluation Understudy) è una metrica per per valutare automaticamente il testo tradotto automaticamente. Il punteggio BLEU è un numero tra zero e uno che misura la somiglianza del testo tradotto automaticamente a un insieme di traduzioni di riferimento di alta qualità. Il valore 0 indica che l'output tradotto automaticamente non si sovrappone alla traduzione di riferimento (bassa qualità) mentre il valore 1 indica una perfetta sovrapposizione con le traduzioni dei riferimenti (alta qualità).
È stato dimostrato che i punteggi BLEU sono ben correlati al giudizio umano della traduzione qualità. Tieni presente che anche i traduttori umani non ottengono un punteggio perfetto di 1,0.
AutoML esprime i punteggi BLEU in percentuale anziché in decimale compreso tra 0 e 1.
Interpretazione
Il confronto tra i punteggi BLEU e i diversi corpora scoraggiati. Anche il confronto dei punteggi BLEU per lo stesso corpus, ma con valori il numero di traduzioni dei riferimenti può essere molto fuorviante.
Tuttavia, come linea guida approssimativa, la seguente interpretazione di BLEU (espressi in percentuale anziché come decimali).
| Punteggio BLEU | Interpretazione |
|---|---|
| < 10 | Quasi inutile |
| 10-19 | Difficile capire il concetto |
| 20 - 29 | La sostanza è chiara, ma presenta errori grammaticali significativi |
| 30 - 40 | Comprensibili per traduzioni di qualità |
| 40 - 50 | Traduzioni di alta qualità |
| 50 - 60 | Traduzioni di altissima qualità, adeguate e fluenti |
| > 60 | La qualità è spesso migliore di quella umana |
Il seguente gradiente di colore può essere utilizzato come interpretazione di scala generale del punteggio BLEU:

I dettagli matematici
Da punto di vista matematico, il punteggio BLEU è definito come segue:
grazie a
\[ precision_i = \dfrac{\sum_{\text{snt}\in\text{Cand-Corpus}}\sum_{i\in\text{snt}}\min(m^i_{cand}, m^i_{ref})} {w_t^i = \sum_{\text{snt'}\in\text{Cand-Corpus}}\sum_{i'\in\text{snt'}} m^{i'}_{cand}} \]
dove
- \(m_{cand}^i\hphantom{xi}\) è il conteggio di i-gram nel candidato corrispondente a riferimento alla traduzione
- \(m_{ref}^i\hphantom{xxx}\) è il conteggio di i-gram nella traduzione di riferimento
- \(w_t^i\hphantom{m_{max}}\) è il numero totale di i-grammi nel candidato traduzione
La formula è composta da due parti: la penalità di brevità e la sovrapposizione n-grammi.
Benalità di frequenza respiratoria
La penalità di brevità penalizza le traduzioni generate troppo brevi rispetto alla lunghezza di riferimento più vicina con un decadimento esponenziale. La la penalità di brevità compensa il fatto che il punteggio BLEU non ha termine di richiamo.Sovrapposizione n-grammi
La sovrapposizione n-grammi conteggia il numero di unigrammi, bigram, trigrammi e quattro grammi (i=1,...,4) corrispondono alla loro controparte in n-grammi nel riferimento le traduzioni. Questo termine funge da metrica di precisione. Gli unigrammi prendono in considerazione adeguatezza, mentre n-grammi più lunghi tengono conto della fluenza della traduzione. Per evitare una sovrastima, il numero di n-grammi viene troncato al massimo numero di n-grammi conteggio che si verifica nel riferimento (\(m_{ref}^n\)).
Esempi
Calcolo in corso \(precision_1\)
Considera questa frase di riferimento e la traduzione candidata:
Riferimento: the cat is on the mat
Candidato: the the the cat mat
Il primo passaggio consiste nel contare le occorrenze di ogni unigramma nel riferimento il candidato. Tieni presente che la metrica BLEU è sensibile alle maiuscole.
| Unigramma | \(m_{cand}^i\hphantom{xi}\) | \(m_{ref}^i\hphantom{xxx}\) | \(\min(m^i_{cand}, m^i_{ref})\) |
|---|---|---|---|
the |
3 | 2 | 2 |
cat |
1 | 1 | 1 |
is |
0 | 1 | 0 |
on |
0 | 1 | 0 |
mat |
1 | 1 | 1 |
Il numero totale di unigrammi nel candidato (\(w_t^1\)) è 5, quindi \(precision_1\) = (2 + 1 + 1)/5 = 0,8.
Calcolo del punteggio BLEU
Riferimento:
The NASA Opportunity rover is battling a massive dust storm on Mars .
Candidato 1:
The Opportunity rover is combating a big sandstorm on Mars .
Candidato 2:
A NASA rover is fighting a massive storm on Mars .
L'esempio riportato sopra è costituito da un singolo riferimento e da due traduzioni candidate. Le frasi vengono tokenizzate prima di calcolare il punteggio BLEU come descritto sopra; Ad esempio, il periodo finale viene conteggiato come un token separato.
Per calcolare il punteggio BLEU per ogni traduzione, calcoliamo le seguenti statistiche.
- Precisioni n-grammi
La tabella seguente contiene le precisione in n-grammi per entrambi i candidati. - Brevità e penalità
La brevità-penalità è la stessa per il candidato 1 e per il candidato 2 poiché entrambi sono composte da 11 token. - Punteggio BLEU
Tieni presente che è necessario almeno un 4 grammi corrispondente per ottenere un punteggio BLEU > 0. Poiché la traduzione candidata 1 non ha 4 grammi corrispondenti, ha un punteggio BLEU di 0.
| Metrica | Candidato 1 | Candidato 2 |
|---|---|---|
| \(precision_1\) (1 grammo) | 11/8 | 11/9 |
| \(precision_2\) (2 grammi) | 10/4 | 10/5 |
| \(precision_3\) (3 grammi) | 9/2 | 9/2 |
| \(precision_4\) (4 grammi) | 8/0 | 8/1 |
| Brevità e penalità | 0,83 | 0,83 |
| Punteggio BLEU | 0,0 | 0,27 |
Proprietà
BLEU è una metrica basata su corpus
La metrica BLEU non funziona correttamente quando viene utilizzata per valutare le singole frasi. Per Ad esempio, entrambe le frasi di esempio ricevono punteggi BLEU molto bassi anche se cogliere gran parte del significato. Poiché le statistiche n-gram per singole le frasi sono meno significative, BLEU è per definizione una metrica basata su corpus; che è che le statistiche vengono accumulate su un intero corpus quando si calcolano punteggio. Tieni presente che la metrica BLEU definita sopra non può essere fattorizzata per singole frasi.Nessuna distinzione tra contenuti e parole funzionali
La metrica BLEU non fa distinzione tra contenuto e parole funzionali, cioè una parola funzione ignorata come "a" riceve la stessa sanzione che il nome "NASA" sono stati erroneamente sostituiti con "ESA".Non brava a cogliere il significato e la grammaticalità di una frase
Il calo di una singola parola, come "non" può cambiare la polarità di una frase. Inoltre, prendere in considerazione solo n-grammi con n≤4 ignora l'intervallo delle dipendenze, pertanto BLEU spesso impone solo una piccola frasi sgrammatiche.Normalizzazione e tokenizzazione
Prima di calcolare il punteggio BLEU, sia il riferimento che il candidato le traduzioni sono normalizzate e tokenizzate. La scelta della normalizzazione i passaggi di tokenizzazione e di tokenizzazione influiscono in modo significativo sul punteggio BLEU finale.