En esta página, se describe cómo usar un servidor Zipkin con el fin de recibir seguimientos de clientes Zipkin y reenviar esos seguimientos a Cloud Trace para su análisis.
Se recomienda usar un servidor Zipkin si tu aplicación está instrumentada con Zipkin y no deseas ejecutar tu propio backend de seguimiento o deseas acceder a las herramientas de análisis avanzado de Cloud Trace.
En esta página se describen varias formas de configurar el servidor Zipkin:
- Mediante una imagen de contenedor
- Ejecuta fuera de Google Cloud
- Cómo modificar un servidor Zipkin existente
Cómo usar una imagen de contenedor para configurar el servidor
Una imagen de contenedor del recopilador Zipkin de Cloud Trace se encuentra disponible en GitHub. Este repositorio contiene la definición y las capas de compilación de Docker que admite Google Cloud en la imagen base de Docker para Zipkin, además de los pasos de configuración detallados.
Puedes ejecutar esta imagen en el host de contenedor que desees, incluido Google Kubernetes Engine.
Para ejecutar la imagen:
$ docker run -d -p 9411:9411 \
-e STORAGE_TYPE=stackdriver \
-e GOOGLE_APPLICATION_CREDENTIALS=/root/.gcp/credentials.json \
-e STACKDRIVER_PROJECT_ID=your_project \
-v $HOME/.gcp:/root/.gcp:ro \
openzipkin/zipkin-gcp
Si ejecutas este contenedor dentro de Google Cloud, como en una instancia de Compute Engine o un clúster de Google Kubernetes Engine, las credenciales predeterminadas del entorno se capturan de forma automática y los seguimientos se envían de forma automática a Cloud Trace.
Para ver el proceso de configuración completo, ve al repositorio de GitHub de la imagen de Docker para Zipkin.
Como se describe en esta página, también debes configurar los rastreadores de Zipkin.
Ejecuta tu servidor fuera de Google Cloud
Si deseas compilar y ejecutar el recopilador fuera de Google Cloud, como en un servidor físico que se ejecuta de forma local, completa los siguientes pasos:
Crea o selecciona un proyecto
- Accede a tu cuenta de Google Cloud. Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
-
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
No se requiere una cuenta de facturación porque el colector no se está ejecutando en Google Cloud.
Crea una cuenta de servicio
Para permitir que tu servicio se autentique en la API de Cloud Trace, haz lo siguiente:
- Crea una cuenta de servicio.
- Asegúrate de que se haya concedido una función de editor del proyecto a la cuenta de servicio nueva, de manera que pueda escribir datos en la API de Trace.
- Selecciona Proporcionar una clave privada nueva y elige JSON.
- Guarda el archivo de credenciales de JSON en un directorio de la máquina que ejecute el servicio de recopilación.
Configura el firewall
Configura los ajustes de red con el fin de permitir el tráfico de TCP en el puerto 9411 para pasar a la máquina que ejecuta el recopilador Zipkin.
Si tus aplicaciones están alojadas fuera del firewall, ten en cuenta que el tráfico del rastreador al recopilador Zipkin no está encriptado o autenticado. Las conexiones entre el recopilador Zipkin de Cloud Trace y la API de Cloud Trace están encriptadas y autenticadas, así como lo están las conexiones que se originan en las bibliotecas de instrumentación de Cloud Trace.
Configura el servidor con la imagen de contenedor
Para obtener más información, consulta Usa una imagen de contenedor.
Configura los rastreadores Zipkin
Sigue las instrucciones de la sección Configura rastreadores de Zipkin de esta página.
Cómo modificar un servidor Zipkin existente
El proyecto Zipkin mantiene instrucciones sobre cómo usar Cloud Trace como destino de almacenamiento para un servidor Zipkin existente. Estas instrucciones están disponibles en el repositorio de GitHub para la imagen de Docker de Zipkin.
Cómo configurar los rastreadores Zipkin
Independientemente de cómo alojes el colector Zipkin de Cloud Trace, debes configurar tus rastreadores Zipkin para enviarle datos.
Para hacer referencia al colector, usa su dirección IP interna, la dirección IP externa (si recibe seguimientos de aplicaciones alojadas fuera de Google Cloud) o el nombre de host. Cada rastreador Zipkin se configura de diferentes maneras; por ejemplo, para dirigir un rastreador Brave hacia un recopilador con la dirección IP 1.2.3.4, se deben agregar las siguientes líneas a la base de código Java:
Reporter reporter = AsyncReporter.builder(OkHttpSender.create("1.2.3.4:9411/api/v1/spans")).build();
Brave brave = Brave.Builder("example").reporter(reporter).build()
Preguntas frecuentes
P: ¿Qué limitaciones tiene?
Esta versión tiene dos limitaciones conocidas:
Los rastreadores Zipkin deben admitir la semántica de Zipkin correcta para tiempo y duración. Para obtener más información, ve a Instrumenta una biblioteca y desplázate hacia abajo hasta la sección Marcas de tiempo y duración.
Los rastreadores de Zipkin y las bibliotecas de instrumentación de Cloud Trace no pueden agregar intervalos a los mismos seguimientos porque utilizan diferentes formatos para propagar el contexto de seguimiento entre servicios. El resultado es que los seguimientos que captura una biblioteca no contienen intervalos para servicios instrumentados por la otra biblioteca.
Por este motivo, recomendamos que los proyectos que deseen usar Cloud Trace usen de forma exclusiva rastreadores compatibles con Zipkin junto con el colector Zipkin o bibliotecas de instrumentación que funcionen con Cloud Trace. Para obtener más información sobre las bibliotecas de Cloud Trace, consulta Node.js, Java y Go.
Por ejemplo:
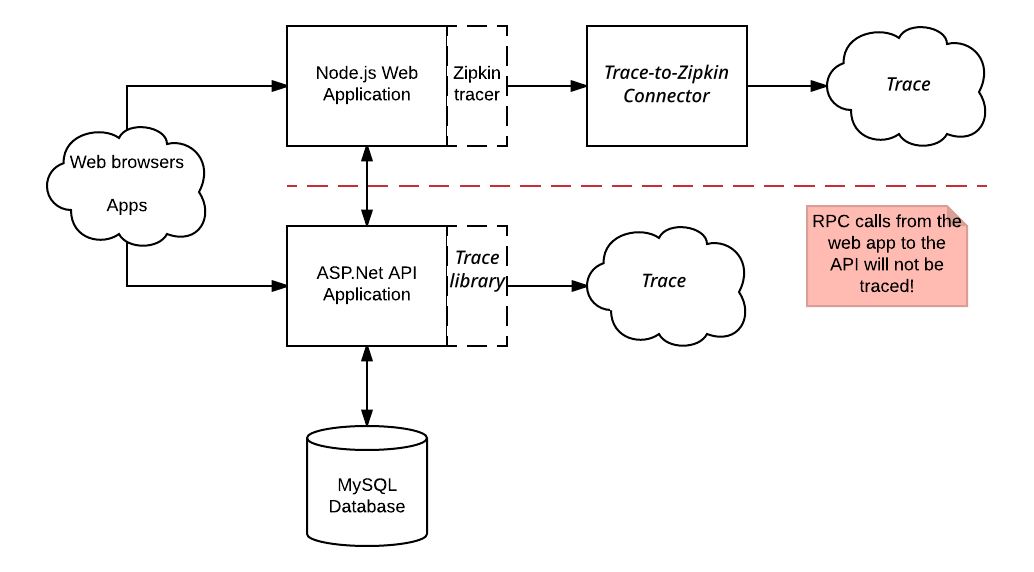
Las solicitudes realizadas a la aplicación web de Node.js se rastrean con la biblioteca Zipkin y se envían a Cloud Trace. Sin embargo, estos seguimientos no contienen intervalos generados por la aplicación de la API de ASP.NET. Los seguimientos que captura la biblioteca Zipkin tampoco contienen intervalos para las llamadas RPC que la aplicación de API de APS.NET realiza a su base de datos de MySQL.
P: ¿Esta característica funciona como un servidor Zipkin completo?
No, esta característica solo escribe datos en Cloud Trace.