This page describes how to use a Zipkin server to receive traces from Zipkin clients and forward those traces to Cloud Trace for analysis.
You might want to use a Zipkin server if your application is instrumented with Zipkin and either you don't want to run your own trace backend or you want access to Cloud Trace's advanced analysis tools.
This page describes several ways to set up your Zipkin server:
Using a container image to set up your server
A container image of the Cloud Trace Zipkin Collector is available on GitHub. This repository contains the Docker build definition and layers Google Cloud support on the base Zipkin Docker image, in addition to detailed setup steps.
You can run this image on your container host of choice, including Google Kubernetes Engine.
To run the image:
$ docker run -d -p 9411:9411 \
-e STORAGE_TYPE=stackdriver \
-e GOOGLE_APPLICATION_CREDENTIALS=/root/.gcp/credentials.json \
-e STACKDRIVER_PROJECT_ID=your_project \
-v $HOME/.gcp:/root/.gcp:ro \
openzipkin/zipkin-gcp
If you are running this container within the Google Cloud, such as on a Compute Engine instance or Google Kubernetes Engine cluster, the environment's default credentials are automatically captured and traces are automatically sent to Cloud Trace.
For the full setup process, go to the GitHub repository for the Zipkin Docker image.
As described on this page, you must also configure your Zipkin tracers.
Running your server outside of Google Cloud
If you would like to build and run the collector outside of Google Cloud, such as on a physical server running on-premises, complete the following steps:
Create or select a project
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
A billing account isn't required because the collector isn't running on Google Cloud.
Create a service account
To allow your service to authenticate to the Cloud Trace API:
- Create a service account.
- Ensure that the new service account has been granted a project editor role so that it can write data to the Trace API.
- Select Furnish a new private key and choose JSON.
- Save the JSON credentials file to a directory on the machine that will be running the collector service.
Configure your firewall
Configure your network configuration to allow TCP traffic on port 9411 to pass to the machine running the Zipkin collector.
If your applications are hosted outside of the firewall, note that Zipkin tracer-to-collector traffic is not encrypted or authenticated. Connections between the Cloud Trace Zipkin collector and the Cloud Trace API are encrypted and authenticated, as are connections sourced from the Cloud Trace instrumentation libraries.
Set up your server with the container image
For more information, see Using a container image.
Configure Zipkin tracers
Follow the instructions in the common Configure Zipkin tracers section on this page.
Modifying an existing Zipkin server
The Zipkin project maintains instructions on how to use Cloud Trace as a storage destination for an existing Zipkin server. These instructions are available on the GitHub repository for the Zipkin Docker image.
How to Configure Zipkin tracers
No matter how you host the Cloud Trace Zipkin Collector, you need to configure your Zipkin tracers to send data to it.
To reference the collector, use its internal IP address, external IP address (if it is receiving traces from applications hosted outside of Google Cloud), or hostname. Each Zipkin tracer is configured differently - for example, to point a Brave tracer at a collector with the IP address 1.2.3.4, the following lines must be added to your Java codebase:
Reporter reporter = AsyncReporter.builder(OkHttpSender.create("1.2.3.4:9411/api/v1/spans")).build();
Brave brave = Brave.Builder("example").reporter(reporter).build()
Frequently asked questions
Q: What are the limitations?
This release has two known limitations:
Zipkin tracers must support the correct Zipkin time and duration semantics. For more information, go to Instrumenting a library and scroll down to the section on Timestamps and duration.
Zipkin tracers and the Cloud Trace instrumentation libraries can't append spans to the same traces because they use different formats for propagating the trace context between services. The result is that traces that are captured by one library don't contain spans for services instrumented by the other library.
For this reason, we recommend that projects wanting to use Cloud Trace either exclusively use Zipkin-compatible tracers along with the Zipkin Collector, or use instrumentation libraries that work with Cloud Trace. For more information on the Cloud Trace libraries, see Node.js, Java, and Go.
For example:
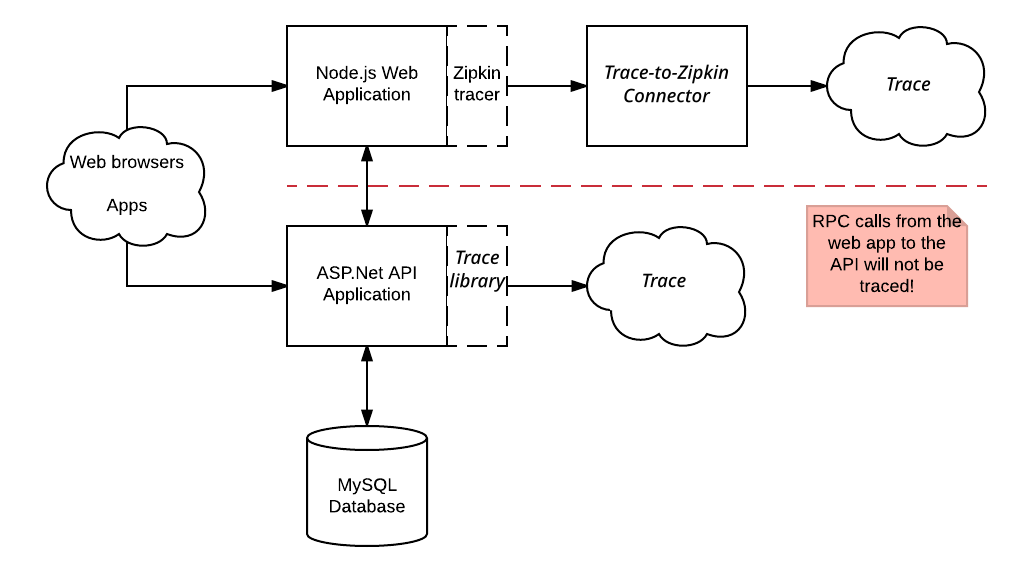
Requests made to the Node.js web application are traced with the Zipkin library and sent to Cloud Trace. However, these traces don't contain spans generated by the ASP.NET API application. The traces captured by the Zipkin library also don't contain spans for the RPC calls the APS.NET API application makes to its MySQL Database.
Q: Will this work as a full Zipkin server?
No, this feature only writes data to Cloud Trace.