Architettura di sistema
Le TPU (Tensor Processing Unit) sono circuiti integrati per applicazioni specifiche (ASIC) progettati da Google per accelerare i carichi di lavoro di machine learning. Cloud TPU è un servizio Google Cloud che rende disponibili le TPU come risorse scalabili.
Le TPU sono progettate per eseguire rapidamente operazioni sulle matrici, il che le rende ideali per i carichi di lavoro di machine learning. Puoi eseguire carichi di lavoro di machine learning su TPU utilizzando framework come TensorFlow, Pytorch e JAX.
Termini di Cloud TPU
Se non hai mai utilizzato le Cloud TPU, consulta la home page della documentazione delle TPU. Le sezioni seguenti spiegano i termini e i concetti correlati utilizzati in questo documento.
Inferenza batch
L'inferenza batch o offline si riferisce all'esecuzione dell'inferenza al di fuori della produzione pipeline in genere su una grande quantità di input. L'inferenza batch viene utilizzata per la modalità offline come l'etichettatura dei dati e la valutazione del modello addestrato. Gli SLO di latenza non sono una priorità per l'inferenza batch.
Chip TPU
Un chip TPU contiene uno o più TensorCore. Il numero di TensorCore dipende dalla versione del chip TPU. Ogni TensorCore è composto da uno o più matriciale (MXU), un'unità vettoriale e un'unità scalare.
Un'unità MXU è composta da accumulatori di moltiplicazione 128 x 128 in un array sistolica. Gli MXU forniscono la maggior parte della potenza di calcolo di un TensorCore. Ogni MXU è in grado di eseguire 16.000 operazioni di moltiplicazione per ciclo. Tutte le moltiplicazioni accettano input bfloat16, ma tutte le accumulazioni vengono eseguite in formato numerico FP32.
L'unità di vettore viene utilizzata per calcoli generali come attivazioni e softmax. L'unità scalare viene utilizzata per il flusso di controllo, il calcolo degli indirizzi di memoria e altre le operazioni di manutenzione.
Cubo TPU
Una topologia 4x4x4. Questo vale solo per le topologie 3D (a partire dalla versione TPU v4).
Inferenza
L'inferenza è il processo di utilizzo di un modello addestrato per fare previsioni su nuovi dati. Viene utilizzato dal processo di pubblicazione.
Multislice e singolo slice
Multislice è un gruppo di sezioni che estende la connettività delle TPU oltre le connessioni inter-chip (ICI) e sfrutta la rete del data center (DCN) per trasmettere i dati oltre una sezione. I dati all'interno di ogni segmento vengono comunque trasmessi dall'ICI. Grazie a questa connettività ibrida, Multislice consente il parallelismo tra le slice e ti permette di utilizzare un numero maggiore di core TPU per un singolo job rispetto a quanto può supportare una singola slice.
Le TPU possono essere utilizzate per eseguire un job su un singolo slice o su più slice. Per ulteriori dettagli, consulta la Introduzione a Multislice.
Resilienza ICI di Cloud TPU
La resilienza dell'ICI contribuisce a migliorare la tolleranza agli errori dei link ottici e degli interruttori di circuiti ottici (OCS) che collegano le TPU tra i cubetti. (Le connessioni ICI all'interno di un cubo utilizzano maglie in rame che non sono interessate). La resilienza dell'ICI consente di instradare le connessioni ICI attorno ai guasti dell'OCS e dell'ICI ottico. Di conseguenza, migliora la disponibilità della pianificazione delle TPU sezioni, con il compromesso di un peggioramento temporaneo delle prestazioni di ICI.
Come per Cloud TPU v4, la resilienza ICI è abilitata per impostazione predefinita per le sezioni v5p di almeno un cubo:
- v5p-128 quando si specifica il tipo di acceleratore
- 4x4x4 quando specifichi la configurazione dell'acceleratore
Risorsa in coda
Una rappresentazione delle risorse TPU, utilizzata per mettere in coda e gestire una richiesta per un ambiente TPU a un solo o più slice. Per ulteriori informazioni, consulta la Guida dell'utente per le risorse in coda.
Pubblicazione
La pubblicazione è il processo di implementazione di un modello di machine learning addestrato in un ambiente di produzione in cui può essere utilizzato per fare previsioni o prendere decisioni. La latenza e la disponibilità a livello di servizio sono importanti per la distribuzione.
Host singolo e multi host
Un host TPU è una VM in esecuzione su un computer fisico connesso all'hardware TPU. I carichi di lavoro TPU possono utilizzare uno o più host.
Un carico di lavoro a singolo host è limitato a una VM TPU. Un carico di lavoro multi-host distribuisce l'addestramento su più VM TPU.
Sezioni
Una sezione di pod è una raccolta di chip tutti all'interno dello stesso pod TPU connessi da interconnessioni inter-chip (ICI) ad alta velocità. Le sezioni vengono descritte in termini di chip o TensorCore, a seconda della versione della TPU.
Forma del chip e topologia del chip si riferiscono anche alle forme delle sezioni.
SparseCore
La versione v5p include quattro SparseCore per chip, ovvero processori Dataflow che accelerano i modelli basati sugli incorporamenti trovati nei modelli di consigli.
pod di TPU
Un pod di TPU è un insieme contiguo di TPU raggruppate in una rete specializzata. Il numero di chip TPU in un pod TPU dipende dalla versione della TPU.
VM o worker TPU
Una macchina virtuale con sistema operativo Linux che ha accesso alle TPU sottostanti. Una VM TPU è anche noto come lavoratore.
Tensor Core
I chip TPU hanno uno o due TensorCore per eseguire la moltiplicazione di matrici. Per ulteriori informazioni su TensorCores, consulta questo articolo ACM .
Worker
Vedi VM TPU.
Versioni TPU
L'architettura esatta di un chip TPU dipende dalla versione della TPU utilizzata. Ogni versione di TPU supporta anche dimensioni e configurazioni delle sezioni diverse. Per ulteriori informazioni sull'architettura di sistema e sulle configurazioni supportate, vedi le pagine seguenti:
Architetture TPU
Esistono due architetture TPU che descrivono come una VM sia fisicamente connesso al dispositivo TPU: nodo TPU e VM TPU. Il nodo TPU era l'originale Architettura TPU per le versioni TPU v2 e v3. Con la versione 4, la VM TPU è diventata l'architettura predefinita, ma entrambe le architetture erano supportate. L'architettura dei nodi TPU è deprecata e viene supportata solo la VM TPU. Se utilizzando i nodi TPU, consulta la sezione Spostamento dal nodo TPU all'architettura VM TPU per eseguire la conversione dal nodo TPU all'architettura delle VM TPU.
Architettura VM TPU
L'architettura delle VM TPU ti consente di connetterti direttamente alla VM connessa fisicamente al dispositivo TPU tramite SSH. Hai accesso come utente root alla VM, quindi puoi eseguire codice arbitrario. Puoi accedere ai log di debug e ai messaggi di errore del compilatore e del runtime.

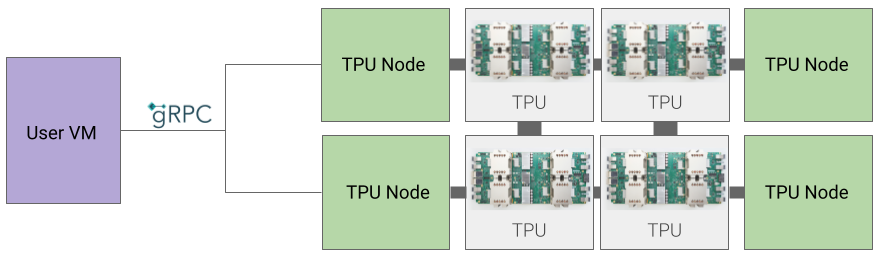
Architettura del nodo TPU
L'architettura del nodo TPU è costituita da una VM utente che comunica con l'host TPU tramite gRPC. Quando utilizzi questa architettura, non puoi accedere direttamente all'host TPU, il che rende difficile il debug dell'addestramento e degli errori TPU.
Spostamento dal nodo TPU all'architettura delle VM TPU
Se hai TPU che utilizzano l'architettura dei nodi TPU, segui questi passaggi per identificarle, eliminarle e eseguirne il nuovo provisioning come VM TPU.
Vai alla pagina TPU:
- Individua la tua TPU e la sua architettura sotto l'intestazione Architecture. Se l'architettura è "VM TPU", non devi fare nulla. Se l'architettura è "Nodo TPU", devi eliminare e eseguire nuovamente il provisioning della TPU.
Elimina ed esegui nuovamente il provisioning della TPU.
Consulta la sezione Gestione delle TPU per Istruzioni sull'eliminazione e le TPU di reprovisioning.