Cloud TPU v5e 推理转换器简介
简介
Cloud TPU 推理转换器可准备和优化 TensorFlow 2 (TF2) 模型,以便在 TPU 上进行推理。转换器在本地或 TPU 虚拟机 Shell 中运行。建议使用 TPU 虚拟机 Shell,因为它预安装了转换器所需的命令行工具。该工具会接受导出的 SavedModel,并执行以下步骤:
- TPU 转换:它会向模型添加
TPUPartitionedCall和其他 TPU 运算,以便在 TPU 上提供模型。默认情况下,导出以进行推理的模型不包含此类操作,并且无法在 TPU 上提供,即使是在 TPU 上训练的也是如此。 - 批处理:它会向模型添加批处理操作,以实现图内批处理,从而提高吞吐量。
- BFloat16 转换:它会将模型的数据格式从
float32转换为bfloat16,以便在 TPU 上获得更出色的计算性能并降低高带宽内存 (HBM) 用量。 - IO 形状优化:它会优化 CPU 和 TPU 之间传输的数据的张量形状,以提高带宽利用率。
导出模型时,用户可以为要在 TPU 上运行的任何函数创建函数别名。它们会将这些函数传递给转换器,转换器会将它们放置在 TPU 上并对其进行优化。
Cloud TPU 推理转换器以 Docker 映像的形式提供,可在安装了 Docker 的任何环境中执行。
完成上述步骤的预计时间:约 20 分钟到 30 分钟
前提条件
- 模型必须是 TF2 模型,并以 SavedModel 格式导出。
- 模型必须为 TPU 函数提供函数别名。如需了解如何实现这一点,请参阅代码示例。以下示例使用
tpu_func作为 TPU 函数别名。 - 请确保您机器的 CPU 支持 Advanced Vector eXtensions (AVX) 指令,因为 Tensorflow 库(Cloud TPU 推理转换器的依赖项)会编译为使用 AVX 指令。大多数 CPU 都支持 AVX。
- 您可以运行
lscpu | grep avx来检查是否支持 AVX 指令集。
- 您可以运行
准备工作
在开始设置之前,请执行以下操作:
创建新项目:在 Google Cloud 控制台的项目选择器页面上,选择或创建一个 Cloud 项目。
设置 TPU 虚拟机:使用 Google Cloud 控制台或
gcloud创建新的 TPU 虚拟机,或使用现有的 TPU 虚拟机在 TPU 虚拟机上使用转换后的模型运行推理。- 确保 TPU VM 映像基于 TensorFlow。例如
--version=tpu-vm-tf-2.11.0。 - 转换后的模型将在此 TPU 虚拟机上加载和提供。
- 确保 TPU VM 映像基于 TensorFlow。例如
确保您拥有使用 Cloud TPU 推理转换器所需的命令行工具。您可以在本地安装 Google Cloud SDK 和 Docker,也可以使用默认安装了这些软件的 TPU VM。您可以使用这些工具与转换器图片进行交互。
使用以下命令通过 SSH 连接到实例:
gcloud compute tpus tpu-vm ssh ${tpu-name} --zone ${zone} --project ${project-id}
环境设置
通过 TPU VM 或本地 shell 设置环境。
TPU 虚拟机 Shell
在 TPU 虚拟机 shell 中,运行以下命令以允许使用非 root 用户的 docker:
sudo usermod -a -G docker ${USER} newgrp docker
初始化 Docker 凭据帮助程序:
gcloud auth configure-docker \ us-docker.pkg.dev
本地 Shell
在本地 Shell 中,按照以下步骤设置环境:
拉取推理转换器 Docker 映像:
CONVERTER_IMAGE=us-docker.pkg.dev/cloud-tpu-images/inference/tpu-inference-converter-cli:2.13.0 docker pull ${CONVERTER_IMAGE}
转换器图片
该图片用于进行一次性模型转换。设置模型路径并调整转换器选项以满足您的需求。使用示例部分提供了几个常见用例。
docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' tpu_functions { function_alias: "tpu_func" } batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 } '
在 TPU 虚拟机中使用转换后的模型进行推理
# Initialize the TPU resolver = tf.distribute.cluster_resolver.TPUClusterResolver("local") tf.config.experimental_connect_to_cluster(resolver) tf.tpu.experimental.initialize_tpu_system(resolver) # Load the model model = tf.saved_model.load(${CONVERTED_MODEL_PATH}) # Find the signature function for serving serving_signature = 'serving_default' # Change the serving signature if needed serving_fn = model.signatures[serving_signature] # Run the inference using requests. results = serving_fn(**inputs) logging.info("Serving results: %s", str(results))
用法示例
为 TPU 函数添加函数别名
- 在模型中找到或创建一个函数,用于封装您要在 TPU 上运行的所有内容。如果
@tf.function不存在,请添加它。 - 保存模型时,请提供 SaveOptions,如以下代码所示,为
model.tpu_func提供别名func_on_tpu。 - 您可以将此函数别名传递给转换器。
class ToyModel(tf.keras.Model): @tf.function( input_signature=[tf.TensorSpec(shape=[None, 10], dtype=tf.float32)]) def tpu_func(self, x): return x * 1.0 model = ToyModel() save_options = tf.saved_model.SaveOptions(function_aliases={ 'func_on_tpu': model.tpu_func, }) tf.saved_model.save(model, model_dir, options=save_options)
使用多个 TPU 函数转换模型
您可以在 TPU 上放置多个函数。只需创建多个函数别名,并将它们在 converter_options_string 中传递给转换器即可。
tpu_functions { function_alias: "tpu_func_1" } tpu_functions { function_alias: "tpu_func_2" }
量化
量化是一种降低用于表示模型参数的数字精度的技术。这样可以减小模型大小并加快计算速度。量化模型可提高推理吞吐量,并缩减内存用量和存储空间,但代价是精度会略微下降。
TensorFlow 中面向 TPU 的全新训练后量化功能是基于 TensorFlow Lite 中用于面向移动设备和边缘设备的类似现有功能开发的。如需详细了解量化,您可以参阅 TensorFlow Lite 文档。
量化概念
本部分定义了与使用推理转换器进行量化相关的具体概念。
如需了解与其他 TPU 配置相关的概念(例如 slice、主机、芯片和 TensorCore),请参阅 TPU 系统架构页面。
训练后量化 (PTQ):PTQ 是一种技术,可在不显著影响神经网络模型准确性的情况下缩减其大小和计算复杂性。PTQ 的工作原理是将训练好的模型的浮点权重和激活转换为低精度整数,例如 8 位或 16 位整数。这可以显著缩减模型大小和推理延迟时间,同时仅会造成很小的准确率损失。
校准:量化校准步骤是指收集神经网络模型权重和激活值的值范围的统计信息的过程。这些信息用于确定模型的量化参数,这些参数是将浮点权重和激活值转换为整数的值。
代表性数据集:用于量化的代表性数据集是一个小型数据集,代表模型的实际输入数据。它在量化校准步骤期间使用,用于收集有关模型权重和激活值范围的统计信息。代表性数据集应满足以下属性:
- 它应正确表示推理期间模型的实际输入。这意味着,它应涵盖模型在真实世界中可能看到的值范围。
- 它应流经条件(例如
tf.cond)的每个分支(如果有)。这一点很重要,因为量化过程需要能够处理模型的所有可能输入,即使这些输入未在代表性数据集中明确表示也是如此。 - 它应足够大,以收集足够的统计信息并减少错误。一般来说,建议使用超过 200 个代表性样本。
代表性数据集可以是训练数据集的一部分,也可以是专门设计的单独数据集,用于代表模型的真实输入。具体选择使用哪个数据集取决于具体应用。
静态范围量化 (SRQ):SRQ 会在校准步骤期间确定神经网络模型权重和激活函数的值范围一次。这意味着,模型的所有输入都使用相同的值范围。这可能不如动态范围量化准确,尤其是对于输入值范围较大的模型。不过,与动态范围量化相比,静态范围量化在运行时需要的计算量更少。
动态范围量化 (DRQ):DRQ 用于确定神经网络模型的权重和激活值在每个输入中的值范围。这样一来,模型便可适应输入数据的值范围,从而提高准确性。不过,与静态范围量化相比,动态范围量化在运行时需要进行更多的计算。
功能 静态范围量化 动态范围量化 值范围 在校准期间确定一次 为每个输入确定 准确性 准确性可能较低,尤其是对于输入值范围较广的模型 可以提高准确性,尤其是对于输入值范围较广的模型 复杂性 更简单 更复杂 运行时计算 减少计算 更多计算 仅权重量化:仅权重量化是一种量化方法,仅对神经网络模型的权重进行量化,而将激活函数保留为浮点型。对于对准确性敏感的模型,这可能是一个不错的选择,因为它有助于保持模型的准确性。
如何使用量化
您可以通过配置并将 QuantizationOptions 设置为转换器选项来应用量化。值得注意的选项包括:
- 标记:用于标识
SavedModel中要量化的MetaGraphDef的标记集合。如果只有一个MetaGraphDef,则无需指定。 - signature_keys:用于标识包含输入和输出的
SignatureDef的键序列。如果未指定,则使用 ["serving_default"]。 - quantization_method:要应用的量化方法。如果未指定,系统将应用
STATIC_RANGE量化。 - op_set:应保持为 XLA。它目前是默认选项,无需指定。
- representative_datasets:指定用于校准量化参数的数据集。
构建代表性数据集
代表性数据集本质上是样本的可迭代对象。其中,示例是以下内容的映射:{input_key: input_value}。例如:
representative_dataset = [{"x": tf.random.uniform(shape=(3, 3))}
for _ in range(256)]
代表性数据集应使用 tf-nightly pip 软件包中当前提供的 TfRecordRepresentativeDatasetSaver 类另存为 TFRecord 文件。例如:
# Assumed tf-nightly installed.
import tensorflow as tf
representative_dataset = [{"x": tf.random.uniform(shape=(3, 3))}
for _ in range(256)]
tf.quantization.experimental.TfRecordRepresentativeDatasetSaver(
path_map={'serving_default': '/tmp/representative_dataset_path'}
).save({'serving_default': representative_dataset})
示例
以下示例使用 serving_default 的签名键和 tpu_func 的函数别名对模型进行量化:
docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' \ tpu_functions { \ function_alias: "tpu_func" \ } \ external_feature_configs { \ quantization_options { \ signature_keys: "serving_default" \ representative_datasets: { \ key: "serving_default" \ value: { \ tfrecord_file_path: "${TF_RECORD_FILE}" \ } \ } \ } \ } '
添加批处理
转换器可用于向模型添加批处理。如需了解可调整的批处理选项,请参阅批处理选项的定义。
默认情况下,转换器会批处理模型中的所有 TPU 函数。它还可以批量处理用户提供的签名和函数,从而进一步提升性能。任何批处理的 TPU 函数、用户提供的函数或签名都必须满足批处理操作的严格形状要求。
转换器还可以更新现有的批处理选项。以下示例展示了如何向模型添加批处理。如需详细了解批处理,请参阅批处理深入探究。
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 }
停用 bfloat16 和 IO 形状优化
BFloat16 和 IO Shape 优化默认处于启用状态。如果这些功能与您的模型不兼容,可以将其停用。
# Disable both optimizations disable_default_optimizations: true # Or disable them individually io_shape_optimization: DISABLED bfloat16_optimization: DISABLED
转化报告
运行推理转换器后,您可以在日志中找到此转换报告。下面提供了一个示例。
-------- Conversion Report -------- TPU cost of the model: 96.67% (2034/2104) CPU cost of the model: 3.33% (70/2104) Cost breakdown ================================ % Cost Name -------------------------------- 3.33 70 [CPU cost] 48.34 1017 tpu_func_1 48.34 1017 tpu_func_2 --------------------------------
此报告会估算输出模型在 CPU 和 TPU 上的计算开销,并进一步细分每个函数的 TPU 开销,这应该反映了您在转换器选项中选择的 TPU 函数。
如果您想更好地利用 TPU,不妨尝试调整模型结构并调整转换器选项。
常见问题解答
我应该将哪些函数放置在 TPU 上?
最好将模型中的尽可能多操作移至 TPU 上,因为绝大多数操作在 TPU 上执行速度更快。
如果您的模型不包含任何与 TPU 不兼容的运算、字符串或稀疏张量,则将整个模型放置在 TPU 上通常是最佳策略。为此,您可以查找或创建一个封装整个模型的函数,为其创建函数别名,然后将其传递给转换器。
如果您的模型包含无法在 TPU 上运行的部分(例如与 TPU 不兼容的运算、字符串或稀疏张量),则 TPU 函数的选择取决于不兼容部分的位置。
- 如果它位于模型的开头或结尾,您可以重构模型,使其保持在 CPU 上运行。例如字符串预处理和后处理阶段。如需详细了解如何将代码移至 CPU,请参阅“如何将模型的一部分移至 CPU?”它展示了重构模型的典型方法。
- 如果它位于模型中间,最好将模型拆分为三个部分,并将所有不兼容 TPU 的操作包含在中间部分,并使其在 CPU 上运行。
- 如果它是稀疏张量,请考虑在 CPU 上调用
tf.sparse.to_dense,并将生成的密集张量传递给模型的 TPU 部分。
另一个需要考虑的因素是 HBM 用量。嵌入表可能会使用大量 HBM。如果它们超出了 TPU 的硬件限制,则必须将它们与查找操作一起放置在 CPU 上。
应尽可能确保一个签名下只有一个 TPU 函数。如果模型的结构要求在每个传入推理请求中调用多个 TPU 函数,您应注意在 CPU 和 TPU 之间发送张量会增加延迟时间。
评估 TPU 函数选择的好方法是查看转化报告。它会显示放置在 TPU 上的计算百分比,以及每个 TPU 函数的费用明细。
如何将模型的一部分移至 CPU?
如果您的模型包含无法在 TPU 上提供的部分,则需要重构模型以将其移至 CPU。下面是一个玩具示例。该模型是一种包含预处理阶段的语言模型。为简单起见,省略了图层定义和函数的代码。
class LanguageModel(tf.keras.Model): @tf.function def model_func(self, input_string): word_ids = self.preprocess(input_string) return self.bert_layer(word_ids)
此模型无法直接在 TPU 上提供,原因有二。首先,该参数是字符串。其次,preprocess 函数可能包含许多字符串操作。这两种模型都不支持 TPU。
如需重构此模型,您可以创建另一个名为 tpu_func 的函数来托管计算密集型 bert_layer。然后,为 tpu_func 创建一个函数别名,并将其传递给转换器。这样一来,tpu_func 中的所有内容都将在 TPU 上运行,而 model_func 中剩余的所有内容都将在 CPU 上运行。
class LanguageModel(tf.keras.Model): @tf.function def tpu_func(self, word_ids): return self.bert_layer(word_ids) @tf.function def model_func(self, input_string): word_ids = self.preprocess(input_string) return self.tpu_func(word_ids)
如果模型包含与 TPU 不兼容的运算、字符串或稀疏张量,我该怎么办?
TPU 支持大多数标准 TensorFlow 运算,但不支持少数运算,包括稀疏张量和字符串。转换器不会检查是否存在与 TPU 不兼容的操作。因此,包含此类运算的模型可以通过转换。但是,在运行该模型进行推理时,会出现如下错误。
'tf.StringToNumber' op isn't compilable for TPU device.
如果您的模型包含与 TPU 不兼容的运算,则应将其放在 TPU 函数之外。此外,字符串是 TPU 上不受支持的数据格式。因此,不应将字符串类型的变量放入 TPU 函数中。此外,TPU 函数的参数和返回值也不应是字符串类型。同样,请避免在 TPU 函数(包括其参数和返回值)中放置稀疏张量。
通常,重构模型中不兼容的部分并将其移至 CPU 并不难。下面是一个示例。
如何在模型中支持自定义操作?
如果您的模型中使用了自定义运算,转换器可能无法识别它们,并会导致模型转换失败。这是因为自定义运算的运算库(包含运算的完整定义)未与转换器相关联。
由于转换器代码目前尚未开源,因此无法使用自定义运算构建转换器。
如果我有 TensorFlow 1 模型,该怎么办?
转换器不支持 TensorFlow 1 模型。应将 TensorFlow 1 模型迁移到 TensorFlow 2。
在运行模型时,我需要启用 MLIR 桥接吗?
大多数转换后的模型都可以使用较新的 TF2XLA MLIR 桥接或原始 TF2XLA 桥接运行。
如何转换不含函数别名的已导出模型?
如果导出的模型没有函数别名,最简单的方法是再次导出该模型并创建函数别名。如果无法重新导出,您仍然可以通过提供 concrete_function_name 来转换模型。不过,确定正确的 concrete_function_name 确实需要进行一些侦探工作。
函数别名是从用户定义的字符串到具体函数名称的映射。这样可以更轻松地引用模型中的特定函数。转换器同时接受函数别名和原始具体函数名称。
您可以通过检查 saved_model.pb 找到具体函数名称。
以下示例展示了如何将名为 __inference_serve_24 的具体函数放置在 TPU 上。
sudo docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' tpu_functions { concrete_function_name: "__inference_serve_24" }'
如何解决编译时常量约束错误?
对于训练和推理,XLA 要求在 TPU 编译时,某些运算的输入具有已知形状。这意味着,当 XLA 编译程序的 TPU 部分时,这些运算的输入必须具有静态已知的形状。
您可以通过以下两种方式解决此问题。
- 最佳方案是在 XLA 编译 TPU 程序时更新操作的输入,使其具有静态已知形状。此编译会在模型的 TPU 部分运行之前进行。这意味着,在
TpuFunction即将运行时,形状应已静态知晓。 - 另一种方法是修改
TpuFunction,使其不再包含有问题的操作。
为什么我会收到批处理形状错误?
批处理具有严格的形状要求,允许按第 0 个维度(也称为批处理维度)批处理传入请求。这些形状要求来自 TensorFlow 批处理操作,无法放宽。
未能满足这些要求将导致以下错误:
- 批处理输入张量必须至少有一个维度。
- 输入的维度应一致。
- 在给定操作调用中提供的批处理输入张量必须具有相同的第 0 个维度大小。
- 批量输出张量的第 0 个维度不等于输入张量的第 0 个维度大小的总和。
为了满足这些要求,不妨考虑为批处理提供不同的函数或签名。您可能还需要修改现有函数才能满足这些要求。
如果要对某个函数进行批处理,请确保其 @tf.function 的 input_signature 的形状在第 0 个维度中均为 None。如果要批量处理签名,请确保其所有输入的 0 维度均为 -1。
如需详细了解出现这些错误的原因以及如何解决这些错误,请参阅批量处理深入解析。
已知问题
TPU 函数无法间接调用其他 TPU 函数
虽然转换器可以处理跨 CPU-TPU 边界的大多数函数调用场景,但有一个罕见的极端情况会导致其失败。即 TPU 函数间接调用另一个 TPU 函数。
这是因为转换器会将 TPU 函数的直接调用方从调用 TPU 函数本身修改为调用 TPU 调用桩。调用桩包含只能在 CPU 上运行的操作。当 TPU 函数调用最终调用直接调用者的任何函数时,这些 CPU 操作可能会在 TPU 上执行,这会生成缺少内核错误。请注意,这种情况不同于 TPU 函数直接调用另一个 TPU 函数。在这种情况下,转换器不会修改任何函数来调用调用桩,因此它可以正常运行。
在转换器中,我们实现了对此类情况的检测。如果您看到以下错误,则表示您的模型遇到了此极端情况:
Unable to place both "__inference_tpu_func_2_46" and "__inference_tpu_func_4_68" on the TPU because "__inference_tpu_func_2_46" indirectly calls "__inference_tpu_func_4_68". This behavior is unsupported because it can cause invalid graphs to be generated.
常规解决方法是重构模型,以避免出现此类函数调用场景。如果您发现很难做到这一点,请与 Google 支持团队联系,进一步讨论。
参考
采用 protobuf 格式的转换器选项
message ConverterOptions { // TPU conversion options. repeated TpuFunction tpu_functions = 1; // The state of an optimization. enum State { // When state is set to default, the optimization will perform its // default behavior. For some optimizations this is disabled and for others // it is enabled. To check a specific optimization, read the optimization's // description. DEFAULT = 0; // Enabled. ENABLED = 1; // Disabled. DISABLED = 2; } // Batch options to apply to the TPU Subgraph. // // At the moment, only one batch option is supported. This field will be // expanded to support batching on a per function and/or per signature basis. // // // If not specified, no batching will be done. repeated BatchOptions batch_options = 100; // Global flag to disable all optimizations that are enabled by default. // When enabled, all optimizations that run by default are disabled. If a // default optimization is explicitly enabled, this flag will have no affect // on that optimization. // // This flag defaults to false. bool disable_default_optimizations = 202; // If enabled, apply an optimization that reshapes the tensors going into // and out of the TPU. This reshape operation improves performance by reducing // the transfer time to and from the TPU. // // This optimization is incompatible with input_shape_opt which is disabled. // by default. If input_shape_opt is enabled, this option should be // disabled. // // This optimization defaults to enabled. State io_shape_optimization = 200; // If enabled, apply an optimization that updates float variables and float // ops on the TPU to bfloat16. This optimization improves performance and // throughtput by reducing HBM usage and taking advantage of TPU support for // bfloat16. // // This optimization may cause a loss of accuracy for some models. If an // unacceptable loss of accuracy is detected, disable this optimization. // // This optimization defaults to enabled. State bfloat16_optimization = 201; BFloat16OptimizationOptions bfloat16_optimization_options = 203; // The settings for XLA sharding. If set, XLA sharding is enabled. XlaShardingOptions xla_sharding_options = 204; } message TpuFunction { // The function(s) that should be placed on the TPU. Only provide a given // function once. Duplicates will result in errors. For example, if // you provide a specific function using function_alias don't also provide the // same function via concrete_function_name or jit_compile_functions. oneof name { // The name of the function alias associated with the function that // should be placed on the TPU. Function aliases are created during model // export using the tf.saved_model.SaveOptions. // // This is a recommended way to specify which function should be placed // on the TPU. string function_alias = 1; // The name of the concrete function that should be placed on the TPU. This // is the name of the function as it found in the GraphDef and the // FunctionDefLibrary. // // This is NOT the recommended way to specify which function should be // placed on the TPU because concrete function names change every time a // model is exported. string concrete_function_name = 3; // The name of the signature to be placed on the TPU. The user must make // sure there is no TPU-incompatible op under the entire signature. string signature_name = 5; // When jit_compile_functions is set to True, all jit compiled functions // are placed on the TPU. // // To use this option, decorate the relevant function(s) with // @tf.function(jit_compile=True), before exporting. Then set this flag to // True. The converter will find all functions that were tagged with // jit_compile=True and place them on the TPU. // // When using this option, all other settings for the TpuFunction // will apply to all functions tagged with // jit_compile=True. // // This option will place all jit_compile=True functions on the TPU. // If only some jit_compile=True functions should be placed on the TPU, // use function_alias or concrete_function_name. bool jit_compile_functions = 4; } } message BatchOptions { // Number of scheduling threads for processing batches of work. Determines // the number of batches processed in parallel. This should be roughly in line // with the number of TPU cores available. int32 num_batch_threads = 1; // The maximum allowed batch size. int32 max_batch_size = 2; // Maximum number of microseconds to wait before outputting an incomplete // batch. int32 batch_timeout_micros = 3; // Optional list of allowed batch sizes. If left empty, // does nothing. Otherwise, supplies a list of batch sizes, causing the op // to pad batches up to one of those sizes. The entries must increase // monotonically, and the final entry must equal max_batch_size. repeated int32 allowed_batch_sizes = 4; // Maximum number of batches enqueued for processing before requests are // failed fast. int32 max_enqueued_batches = 5; // If set, disables large batch splitting which is an efficiency improvement // on batching to reduce padding inefficiency. bool disable_large_batch_splitting = 6; // Experimental features of batching. Everything inside is subject to change. message Experimental { // The component to be batched. // 1. Unset if it's for all TPU subgraphs. // 2. Set function_alias or concrete_function_name if it's for a function. // 3. Set signature_name if it's for a signature. oneof batch_component { // The function alias associated with the function. Function alias is // created during model export using the tf.saved_model.SaveOptions, and is // the recommended way to specify functions. string function_alias = 1; // The concreate name of the function. This is the name of the function as // it found in the GraphDef and the FunctionDefLibrary. This is NOT the // recommended way to specify functions, because concrete function names // change every time a model is exported. string concrete_function_name = 2; // The name of the signature. string signature_name = 3; } } Experimental experimental = 7; } message BFloat16OptimizationOptions { // Indicates where the BFloat16 optimization should be applied. enum Scope { // The scope currently defaults to TPU. DEFAULT = 0; // Apply the bfloat16 optimization to TPU computation. TPU = 1; // Apply the bfloat16 optimization to the entire model including CPU // computations. ALL = 2; } // This field indicates where the bfloat16 optimization should be applied. // // The scope defaults to TPU. Scope scope = 1; // If set, the normal safety checks are skipped. For example, if the model // already contains bfloat16 ops, the bfloat16 optimization will error because // pre-existing bfloat16 ops can cause issues with the optimization. By // setting this flag, the bfloat16 optimization will skip the check. // // This is an advanced feature and not recommended for almost all models. // // This flag is off by default. bool skip_safety_checks = 2; // Ops that should not be converted to bfloat16. // Inputs into these ops will be cast to float32, and outputs from these ops // will be cast back to bfloat16. repeated string filterlist = 3; } message XlaShardingOptions { // num_cores_per_replica for TPUReplicateMetadata. // // This is the number of cores you wish to split your model into using XLA // SPMD. int32 num_cores_per_replica = 1; // (optional) device_assignment for TPUReplicateMetadata. // // This is in a flattened [x, y, z, core] format (for // example, core 1 of the chip // located in 2,3,0 will be stored as [2,3,0,1]). // // If this is not specified, then the device assignments will utilize the same // topology as specified in the topology attribute. repeated int32 device_assignment = 2; // A serialized string of tensorflow.tpu.TopologyProto objects, used for // the topology attribute in TPUReplicateMetadata. // // You must specify the mesh_shape and device_coordinates attributes in // the topology object. // // This option is required for num_cores_per_replica > 1 cases due to // ambiguity of num_cores_per_replica, for example, // pf_1x2x1 with megacore and df_1x1 // both have num_cores_per_replica = 2, but topology is (1,2,1,1) for pf and // (1,1,1,2) for df. // - For pf_1x2x1, mesh shape and device_coordinates looks like: // mesh_shape = [1,2,1,1] // device_coordinates=flatten([0,0,0,0], [0,1,0,0]) // - For df_1x1, mesh shape and device_coordinates looks like: // mesh_shape = [1,1,1,2] // device_coordinates=flatten([0,0,0,0], [0,0,0,1]) // - For df_2x2, mesh shape and device_coordinates looks like: // mesh_shape = [2,2,1,2] // device_coordinates=flatten( // [0,0,0,0],[0,0,0,1],[0,1,0,0],[0,1,0,1] // [1,0,0,0],[1,0,0,1],[1,1,0,0],[1,1,0,1]) bytes topology = 3; }
批处理深入解析
批处理用于提高吞吐量和 TPU 利用率。它支持同时处理多个请求。在训练期间,可以使用 tf.data 进行批处理。在推理期间,通常通过在图中添加用于批处理传入请求的操作来实现此目的。该操作会等到收到足够的请求或超时,然后再根据各个请求生成一个大批量请求。如需详细了解可调整的不同批处理选项(包括批处理大小和超时),请参阅批处理选项的定义。
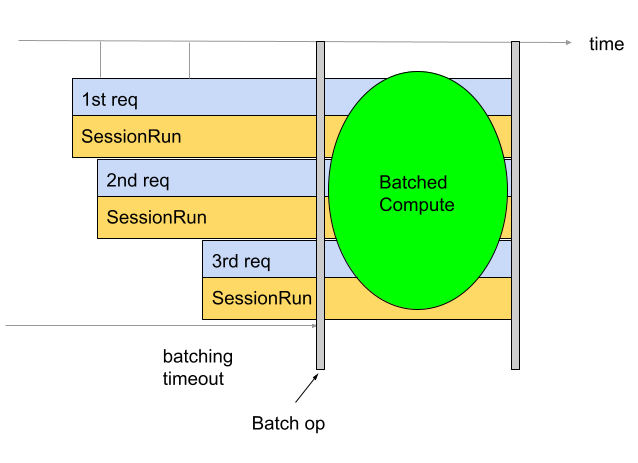
默认情况下,转换器会直接在 TPU 计算之前插入批处理操作。它会使用批处理操作封装用户提供的 TPU 函数和模型中的任何现有 TPU 计算。您可以通过告知转换器应批处理哪些函数和/或签名来替换此默认行为。
以下示例展示了如何添加默认批处理。
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 }
签名批处理
签名批处理会从签名的输入开始,到签名的输出结束,对整个模型进行批处理。与转换器的默认批处理行为不同,签名批处理会同时批处理 TPU 计算和 CPU 计算。这会在某些模型的推理过程中带来 10% 到 20% 的性能提升。
与所有批处理一样,签名批处理确实有严格的形状要求。为确保满足这些形状要求,签名输入的形状应至少具有两个维度。第一个维度是批次大小,应为 -1。例如,(-1, 4)、(-1) 或 (-1,
128, 4, 10) 都是有效的输入形状。如果无法做到这一点,请考虑使用默认批处理行为或函数批处理。
如需使用签名批处理,请使用 BatchOptions 将签名名称作为 signature_name 提供。
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 experimental { signature_name: "serving_default" } }
函数批处理
函数批处理可用于告知转换器应批处理哪些函数。默认情况下,转换器会批处理所有 TPU 函数。函数批处理会替换此默认行为。
函数批处理可用于批处理 CPU 计算。许多模型在其 CPU 计算进行批处理后,性能都会有所提升。批处理 CPU 计算的最佳方式是使用签名批处理,但对于某些模型,此方法可能不适用。在这些情况下,除了 TPU 计算之外,函数批处理还可用于批处理部分 CPU 计算。请注意,批处理操作无法在 TPU 上运行,因此必须在 CPU 上调用提供的任何批处理函数。
函数批处理还可用于满足批处理运算强加的严格形状要求。如果 TPU 函数不符合批处理运算的形状要求,则可以使用函数批处理来指示转换器批处理不同的函数。
如需使用此功能,请为应批处理的函数生成 function_alias。为此,您可以在模型中查找或创建一个用于封装要批处理的所有内容的函数。确保此函数符合批处理操作强加的严格形状要求。如果尚未添加 @tf.function,请添加 @tf.function。请务必向 @tf.function 提供 input_signature。第 0 个维度应为 None,因为它是批处理维度,因此不能是固定大小。例如,[None, 4]、[None] 或 [None, 128, 4, 10] 都是有效的输入形状。保存模型时,请提供类似于下方所示的 SaveOptions,以便为 model.batch_func 提供别名“batch_func”。然后,您可以将此函数别名传递给转换器。
class ToyModel(tf.keras.Model): @tf.function(input_signature=[tf.TensorSpec(shape=[None, 10], dtype=tf.float32)]) def batch_func(self, x): return x * 1.0 ... model = ToyModel() save_options = tf.saved_model.SaveOptions(function_aliases={ 'batch_func': model.batch_func, }) tf.saved_model.save(model, model_dir, options=save_options)
接下来,使用 BatchOptions 传递 function_alias。
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 experimental { function_alias: "batch_func" } }
批处理选项的定义
num_batch_threads:(整数)用于处理批量工作调度线程的数量。确定并行处理的批次数量。这应该与可用的 TPU 核心数大致相符。max_batch_size:(整数)允许的批次大小上限。可以大于allowed_batch_sizes,以便利用大批量拆分。batch_timeout_micros:(整数)在输出不完整的批次之前等待的微秒数上限。allowed_batch_sizes:(整数列表)如果列表不为空,则会将批处理填充到列表中最近的大小。列表必须单调递增,并且最后一个元素必须小于或等于max_batch_size。max_enqueued_batches:(整数)在请求快速失败之前,加入队列以进行处理的批次数量上限。
更新现有批处理选项
您可以通过运行指定 batch_options 的 Docker 映像并使用 --converter_options_string 标志将 disable_default_optimizations 设置为 true 来添加或更新批处理选项。批处理选项将应用于每个 TPU 函数或现有批处理操作。
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 } disable_default_optimizations=True
批处理形状要求
批处理是通过沿批处理(第 0 个)维度串联各个请求的输入张量来创建的。输出张量会沿其第 0 个维度进行拆分。为了执行这些操作,批处理操作对其输入和输出有严格的形状要求。
演示
如需了解这些要求,不妨先了解如何执行批处理。在以下示例中,我们将对一个简单的 tf.matmul 操作进行批处理。
def my_func(A, B) return tf.matmul(A, B)
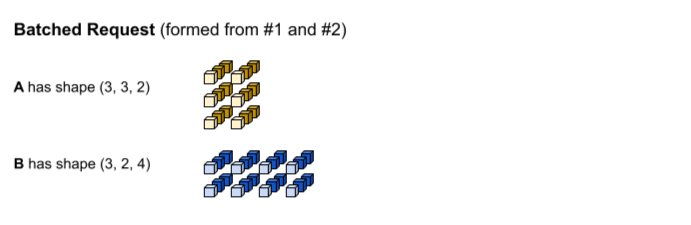
第一个推理请求会生成形状分别为 (1, 3,
2) 和 (1, 2, 4) 的输入 A 和 B。第二个推理请求会生成形状为 (2, 3, 2) 和 (2, 2, 4) 的输入 A 和 B。

达到批处理超时时间。该模型支持批次大小为 3,因此推理请求 1 和 2 会一起批处理,而不会填充任何内容。批处理的张量是通过沿批处理(第 0 个)维度串联请求 1 和请求 2 而形成的。由于 #1 的 A 的形状为 (1, 3, 2),而 #2 的 A 的形状为 (2, 3, 2),因此当它们沿批处理(第 0 个)维度串联时,生成的形状为 (3, 3, 2)。
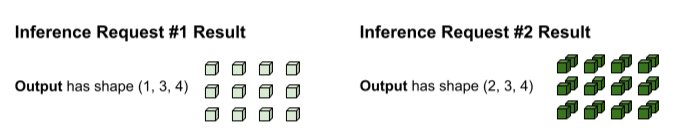
系统会执行 tf.matmul,并生成形状为 (3, 3,
4) 的输出。

tf.matmul 的输出是批处理的,因此需要重新拆分为单独的请求。分批运算符通过沿每个输出张量的批处理(第 0 个)维度进行拆分来实现此目的。它会根据原始输入的形状决定如何拆分第 0 个维度。由于请求 1 的形状的第 0 个维度为 1,因此其输出的形状的第 0 个维度也为 1,即 (1, 3, 4)。由于请求 2 的形状的第 0 个维度为 2,因此其输出的形状的第 0 个维度为 2,即 (2, 3, 4)。
形状要求
为了执行上述输入串联和输出拆分操作,批处理操作必须满足以下形状要求:
批处理的输入不能是标量。为了沿第 0 个维度串联,张量必须至少具有两个维度。
在上述演示中。A 和 B 都不是标量。
如果不满足此要求,将导致以下错误:
Batching input tensors must have at least one dimension。要解决此错误,只需将标量转换为矢量即可。在不同的推理请求(例如,不同的会话运行调用)中,名称相同的输入张量除了第 0 个维度外,每个维度的大小都相同。这样,输入就可以沿着第 0 个维度进行清晰串联。
在上述演示中,请求 1 的 A 的形状为
(1, 3, 2)。这意味着,任何未来请求都必须生成采用(X, 3, 2)模式的形状。请求 2 使用(2, 3, 2)满足此要求。同样,请求 1 的 B 的形状为(1, 2, 4),因此所有后续请求都必须生成形状为(X, 2, 4)的模式。不满足此要求将导致以下错误:
Dimensions of inputs should match。对于给定的推理请求,所有输入都必须具有相同的第 0 个维度大小。如果批处理运算的不同输入张量具有不同的第 0 个维度,则批处理运算不知道如何拆分输出张量。
在上面的演示中,请求 1 的张量都具有 0 维大小为 1。这样,批处理操作便会知道其输出的第 0 个维度大小应为 1。同样,请求 2 的张量第 0 个维度的大小为 2,因此其输出的第 0 个维度的大小也为 2。当批处理操作拆分
(3, 3, 4)的最终形状时,它会为请求 1 生成(1, 3, 4),并为请求 2 生成(2, 3, 4)。未能满足此要求将导致出现以下错误:
Batching input tensors supplied in a given op invocation must have equal 0th-dimension size。每个输出张量形状的第 0 个维度大小必须为所有输入张量第 0 个维度大小的总和(加上批处理运算引入的任何填充,以满足下一个最大的
allowed_batch_size)。这样,批处理运算就可以根据输入张量的第 0 个维度,沿着输出张量的第 0 个维度进行拆分。在上面的演示中,输入张量的第 0 个维度为 1(来自请求 1),为 2(来自请求 2)。因此,每个输出张量必须具有 0 维度为 3,因为 1+2=3。输出张量
(3, 3, 4)满足此要求。如果 3 不是有效的批次大小,但 4 是,则批处理操作必须将输入的 0 维从 3 填充到 4。在这种情况下,每个输出张量的第 0 个维度大小都必须为 4。未能满足此要求将导致以下错误:
Batched output tensor's 0th dimension does not equal the sum of the 0th dimension sizes of the input tensors。
解决形状要求错误
为了满足这些要求,不妨考虑为批处理提供不同的函数或签名。您可能还需要修改现有函数才能满足这些要求。
如果要对函数进行批处理,请确保其 @tf.function 的 input_signature 的形状在第 0 个维度(也称为批处理维度)中均为 None。如果要批量处理签名,请确保其所有输入的 0 维度均为 -1。
BatchFunction 运算不支持将 SparseTensors 用作输入或输出。在内部,每个稀疏张量都表示为三个单独的张量,它们可以具有不同的第 0 个维度大小。