Introducción al convertidor de inferencia de Cloud TPU v5e
Introducción
El convertidor de inferencia de Cloud TPU prepara y optimiza un modelo de TensorFlow 2 (TF2) para la inferencia de TPU. El convertidor se ejecuta en un shell local o de VM de TPU. Se recomienda la shell de la VM de TPU porque viene preinstalada con las herramientas de línea de comandos necesarias para el convertidor. Toma un SavedModel exportado y realiza los siguientes pasos:
- Conversión de TPU: Agrega
TPUPartitionedCally otras operaciones de TPU al modelo para que se pueda entregar en la TPU. De forma predeterminada, un modelo exportado para la inferencia no tiene esas operaciones y no se puede entregar en la TPU, incluso si se entrenó en ella. - Procesamiento por lotes: Agrega operaciones por lotes al modelo para habilitar el procesamiento por lotes en el grafo y mejorar la capacidad de procesamiento.
- Conversión de BFloat16: Convierte el formato de datos del modelo de
float32abfloat16para mejorar el rendimiento computacional y reducir el uso de la memoria de gran ancho de banda (HBM) en la TPU. - Optimización de la forma de E/S: Optimiza las formas de tensor para los datos que se transfieren entre la CPU y la TPU para mejorar el uso del ancho de banda.
Cuando exportan un modelo, los usuarios crean alias de función para las funciones que desean ejecutar en la TPU. Pasa estas funciones al convertidor, que las coloca en la TPU y las optimiza.
El convertidor de inferencia de Cloud TPU está disponible como una imagen de Docker que se puede ejecutar en cualquier entorno con Docker instalado.
Tiempo estimado para completar los pasos que se muestran más arriba: entre 20 y 30 minutos
Requisitos previos
- El modelo debe ser un modelo de TF2 y exportarse en el formato SavedModel.
- El modelo debe tener un alias de función para la función de TPU. Consulta el ejemplo de código para ver cómo hacerlo. En los siguientes ejemplos, se usa
tpu_funccomo el alias de la función de TPU. - Asegúrate de que la CPU de tu máquina admita instrucciones de extensiones vectoriales avanzadas (AVX), ya que la biblioteca de Tensorflow (la dependencia del convertidor de inferencia de Cloud TPU) se compila para usar instrucciones AVX.
La mayoría de las CPUs admiten AVX.
- Puedes ejecutar
lscpu | grep avxpara verificar si el conjunto de instrucciones AVX es compatible.
- Puedes ejecutar
Antes de comenzar
Antes de comenzar con la configuración, haz lo siguiente:
Crear un proyecto nuevo: En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Cloud.
Configura una VM de TPU: Crea una VM de TPU nueva con la consola de Google Cloud o
gcloud, o usa una VM de TPU existente para ejecutar la inferencia con el modelo convertido en la VM de TPU.- Asegúrate de que la imagen de la VM de TPU esté basada en TensorFlow. Por ejemplo,
--version=tpu-vm-tf-2.11.0. - El modelo convertido se cargará y se entregará en esta VM de TPU.
- Asegúrate de que la imagen de la VM de TPU esté basada en TensorFlow. Por ejemplo,
Asegúrate de tener las herramientas de línea de comandos que necesitas para usar el convertidor de inferencia de Cloud TPU. Puedes instalar el SDK de Google Cloud y Docker de forma local o usar una VM de TPU que tenga este software instalado de forma predeterminada. Usa estas herramientas para interactuar con la imagen del convertidor.
Conéctate a la instancia con SSH mediante el siguiente comando:
gcloud compute tpus tpu-vm ssh ${tpu-name} --zone ${zone} --project ${project-id}
Configuración del entorno
Configura tu entorno desde la shell de la VM de TPU o desde la shell local.
Shell de VM de TPU
En la shell de la VM de TPU, ejecuta los siguientes comandos para permitir el uso de Docker sin permisos de raíz:
sudo usermod -a -G docker ${USER} newgrp docker
Inicializa los auxiliares de credenciales de Docker:
gcloud auth configure-docker \ us-docker.pkg.dev
Shell local
En tu shell local, configura el entorno con los siguientes pasos:
Instala el SDK de Cloud, que incluye la herramienta de línea de comandos de
gcloud.Instala Docker:
Permite el uso de Docker no raíz:
sudo usermod -a -G docker ${USER} newgrp docker
Accede a tu entorno:
gcloud auth login
Inicializa los auxiliares de credenciales de Docker:
gcloud auth configure-docker \ us-docker.pkg.dev
Extrae la imagen de Docker del convertidor de inferencia:
CONVERTER_IMAGE=us-docker.pkg.dev/cloud-tpu-images/inference/tpu-inference-converter-cli:2.13.0 docker pull ${CONVERTER_IMAGE}
Imagen del convertidor
La imagen se usa para realizar conversiones de modelos únicas. Establece las rutas de acceso del modelo y ajusta las opciones del convertidor para que se adapten a tus necesidades. En la sección Ejemplos de uso, se proporcionan varios casos de uso comunes.
docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' tpu_functions { function_alias: "tpu_func" } batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 } '
Inferencia con el modelo convertido en la VM de TPU
# Initialize the TPU resolver = tf.distribute.cluster_resolver.TPUClusterResolver("local") tf.config.experimental_connect_to_cluster(resolver) tf.tpu.experimental.initialize_tpu_system(resolver) # Load the model model = tf.saved_model.load(${CONVERTED_MODEL_PATH}) # Find the signature function for serving serving_signature = 'serving_default' # Change the serving signature if needed serving_fn = model.signatures[serving_signature] # Run the inference using requests. results = serving_fn(**inputs) logging.info("Serving results: %s", str(results))
Ejemplos de uso
Agrega un alias de función para la función de TPU
- Busca o crea una función en tu modelo que una todo lo que deseas ejecutar en la TPU. Si
@tf.functionno existe, agrégalo. - Cuando guardes el modelo, proporciona SaveOptions como se muestra a continuación para asignarle a
model.tpu_funcun aliasfunc_on_tpu. - Puedes pasar este alias de función al convertidor.
class ToyModel(tf.keras.Model): @tf.function( input_signature=[tf.TensorSpec(shape=[None, 10], dtype=tf.float32)]) def tpu_func(self, x): return x * 1.0 model = ToyModel() save_options = tf.saved_model.SaveOptions(function_aliases={ 'func_on_tpu': model.tpu_func, }) tf.saved_model.save(model, model_dir, options=save_options)
Convierte un modelo con varias funciones de TPU
Puedes colocar varias funciones en la TPU. Simplemente crea varios alias de función y pásalos en converter_options_string al convertidor.
tpu_functions { function_alias: "tpu_func_1" } tpu_functions { function_alias: "tpu_func_2" }
Cuantización
La cuantización es una técnica que reduce la precisión de los números que se usan para representar los parámetros de un modelo. Esto da como resultado un tamaño de modelo más pequeño y un procesamiento más rápido. Un modelo cuantificado proporciona mejoras en la capacidad de procesamiento de inferencia, así como un uso de memoria y un tamaño de almacenamiento más pequeños, a costa de pequeñas disminuciones en la precisión.
La nueva función de cuantificación posterior al entrenamiento en TensorFlow que se orienta a la TPU se desarrolló a partir de la función existente similar en TensorFlow Lite que se usa para segmentar dispositivos móviles y perimetrales. Para obtener más información sobre la cuantificación en general, puedes consultar el documento de TensorFlow Lite.
Conceptos de cuantización
En esta sección, se definen conceptos relacionados específicamente con la cuantificación con el convertidor de inferencia.
Los conceptos relacionados con otras configuraciones de TPU (por ejemplo, fragmentos, hosts, chips y TensorCores) se describen en la página Arquitectura del sistema de TPU.
Cuantización posterior al entrenamiento (PTQ): La PTQ es una técnica que reduce el tamaño y la complejidad computacional de un modelo de red neuronal sin afectar significativamente su precisión. La PTQ funciona convirtiendo los pesos y las activaciones de punto flotante de un modelo entrenado en números enteros de menor precisión, como números enteros de 8 o 16 bits. Esto puede provocar una reducción significativa en el tamaño del modelo y la latencia de inferencia, a la vez que solo se incurre en una pequeña pérdida de precisión.
Calibración: El paso de calibración para la cuantización es el proceso de recopilar estadísticas sobre el rango de valores que toman los pesos y las activaciones de un modelo de red neuronal. Esta información se usa para determinar los parámetros de cuantificación del modelo, que son los valores que se usarán para convertir las activaciones y los pesos de punto flotante en números enteros.
Conjunto de datos representativo: Un conjunto de datos representativo para la cuantificación es un conjunto de datos pequeño que representa los datos de entrada reales del modelo. Se usa durante el paso de calibración de la cuantificación para recopilar estadísticas sobre el rango de valores que tomarán las ponderaciones y activaciones del modelo. El conjunto de datos representativo debe cumplir con las siguientes propiedades:
- Debe representar correctamente las entradas reales del modelo durante la inferencia. Esto significa que debe abarcar el rango de valores que es probable que el modelo vea en el mundo real.
- Debe fluir de forma colectiva a través de cada rama de condiciones (como
tf.cond), si las hay. Esto es importante porque el proceso de cuantificación debe poder controlar todas las entradas posibles del modelo, incluso si no están representadas explícitamente en el conjunto de datos representativo. - Debe ser lo suficientemente grande como para recopilar suficientes estadísticas y reducir los errores. Como regla general, se recomienda usar más de 200 muestras representativas.
El conjunto de datos representativo puede ser un subconjunto del conjunto de datos de entrenamiento o un conjunto de datos independiente diseñado específicamente para representar las entradas del mundo real en el modelo. La elección del conjunto de datos que se usará depende de la aplicación específica.
Cuantización de rango estático (SRQ): La SRQ determina el rango de valores para los pesos y las activaciones de un modelo de red neuronal una vez, durante el paso de calibración. Esto significa que se usa el mismo rango de valores para todas las entradas del modelo. Esto puede ser menos preciso que la cuantificación del rango dinámico, especialmente para los modelos con un amplio rango de valores de entrada. Sin embargo, la cuantificación de rango estático requiere menos procesamiento en el tiempo de ejecución que la cuantificación de rango dinámico.
Cuantización de rango dinámico (DRQ): La DRQ determina el rango de valores para los pesos y las activaciones de un modelo de red neuronal para cada entrada. Esto permite que el modelo se adapte al rango de valores de los datos de entrada, lo que puede mejorar la precisión. Sin embargo, la cuantificación del rango dinámico requiere más procesamiento en el tiempo de ejecución que la cuantificación del rango estático.
Función Cuantización de rango estático Cuantización del rango dinámico Rango de valores Se determina una vez, durante la calibración Se determina para cada entrada. Exactitud Pueden ser menos precisos, especialmente para los modelos con un amplio rango de valores de entrada. Pueden ser más precisos, en especial para los modelos con un amplio rango de valores de entrada. Complejidad Es más simple Es más complejo Cálculo en el tiempo de ejecución Menos procesamiento Más procesamiento Cuantización de solo pesos: La cuantización de solo pesos es un tipo de cuantización que solo cuantiza los pesos de un modelo de red neuronal y deja las activaciones en punto flotante. Esta puede ser una buena opción para los modelos sensibles a la precisión, ya que puede ayudar a preservarla.
Cómo usar la cuantización
Para aplicar la cuantificación, configura QuantizationOptions en las opciones del convertidor. Las opciones destacadas son las siguientes:
- tags: Es una colección de etiquetas que identifican el
MetaGraphDefdentro deSavedModelpara cuantificar. No es necesario especificarlo si solo tienes unMetaGraphDef. - signature_keys: Es una secuencia de claves que identifican
SignatureDefque contiene entradas y salidas. Si no se especifica, se usa ["serving_default"]. - quantization_method: Es el método de cuantificación que se aplicará. Si no se especifica, se aplicará la cuantificación
STATIC_RANGE. - op_set: Debe mantenerse como XLA. Actualmente, es la opción predeterminada, no es necesario especificarla.
- representative_datasets: Especifica el conjunto de datos que se usa para calibrar los parámetros de cuantificación.
Cómo crear el conjunto de datos representativo
Un conjunto de datos representativo es, en esencia, un iterador de muestras.
Donde un ejemplo es un mapa de: {input_key: input_value}. Por ejemplo:
representative_dataset = [{"x": tf.random.uniform(shape=(3, 3))}
for _ in range(256)]
Los conjuntos de datos representativos se deben guardar como archivos TFRecord con la clase TfRecordRepresentativeDatasetSaver disponible actualmente en el paquete pip tf-nightly. Por ejemplo:
# Assumed tf-nightly installed.
import tensorflow as tf
representative_dataset = [{"x": tf.random.uniform(shape=(3, 3))}
for _ in range(256)]
tf.quantization.experimental.TfRecordRepresentativeDatasetSaver(
path_map={'serving_default': '/tmp/representative_dataset_path'}
).save({'serving_default': representative_dataset})
Ejemplos
En el siguiente ejemplo, se cuantifica el modelo con la clave de firma de serving_default y el alias de función de tpu_func:
docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' \ tpu_functions { \ function_alias: "tpu_func" \ } \ external_feature_configs { \ quantization_options { \ signature_keys: "serving_default" \ representative_datasets: { \ key: "serving_default" \ value: { \ tfrecord_file_path: "${TF_RECORD_FILE}" \ } \ } \ } \ } '
Agrega el procesamiento por lotes
El convertidor se puede usar para agregar procesamiento por lotes a un modelo. Para obtener una descripción de las opciones de procesamiento por lotes que se pueden ajustar, consulta Definición de las opciones de procesamiento por lotes.
De forma predeterminada, el convertidor procesará por lotes todas las funciones de TPU del modelo. También puede procesar por lotes las firmas y las funciones proporcionadas por el usuario, lo que puede mejorar aún más el rendimiento. Cualquier función de TPU, función proporcionada por el usuario o firma que se agrupe debe cumplir con los requisitos estrictos de forma de la operación de procesamiento por lotes.
El convertidor también puede actualizar las opciones de procesamiento por lotes existentes. El siguiente es un ejemplo de cómo agregar el procesamiento por lotes a un modelo. Para obtener más información sobre los lotes, consulta Análisis detallado de los lotes.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 }
Inhabilita las optimizaciones de bfloat16 y de forma de E/S
BFloat16 y las optimizaciones de forma de E/S están habilitadas de forma predeterminada. Si no funcionan bien con tu modelo, puedes inhabilitarlos.
# Disable both optimizations disable_default_optimizations: true # Or disable them individually io_shape_optimization: DISABLED bfloat16_optimization: DISABLED
Informe de conversiones
Puedes encontrar este informe de conversiones en el registro después de ejecutar el convertidor de inferencia. Aquí tienen un ejemplo.
-------- Conversion Report -------- TPU cost of the model: 96.67% (2034/2104) CPU cost of the model: 3.33% (70/2104) Cost breakdown ================================ % Cost Name -------------------------------- 3.33 70 [CPU cost] 48.34 1017 tpu_func_1 48.34 1017 tpu_func_2 --------------------------------
Este informe estima el costo computacional del modelo de salida en la CPU y la TPU, y desglosa el costo de la TPU en cada función, lo que debería reflejar tu selección de las funciones de TPU en las opciones del convertidor.
Si deseas aprovechar mejor la TPU, te recomendamos que experimentes con la estructura del modelo y que ajustes las opciones del convertidor.
Preguntas frecuentes
¿Qué funciones debo colocar en la TPU?
Lo mejor es colocar la mayor parte posible de tu modelo en la TPU, ya que la gran mayoría de las operaciones se ejecutan más rápido en la TPU.
Si tu modelo no contiene ninguna operación, cadena ni tensor disperso incompatible con la TPU, la mejor estrategia suele ser colocar todo el modelo en la TPU. Y puedes hacerlo encontrando o creando una función que una todo el modelo, creando un alias de función para él y pasándolo al convertidor.
Si tu modelo contiene partes que no pueden funcionar en la TPU (p.ej.,operaciones, cadenas o tensores dispersos incompatibles con la TPU), la elección de las funciones de TPU depende de dónde se encuentre la parte incompatible.
- Si está al principio o al final del modelo, puedes refactorizarlo para mantenerlo en la CPU. Los ejemplos son las etapas de procesamiento previo y posterior de cadenas. Para obtener más información sobre cómo mover código a la CPU, consulta "¿Cómo puedo mover una parte del modelo a la CPU?". Muestra una forma típica de refactorizar el modelo.
- Si está en el medio del modelo, es mejor dividirlo en tres partes, contener todas las operaciones incompatibles con TPU en la parte central y hacer que se ejecute en la CPU.
- Si es un tensor disperso, considera llamar a
tf.sparse.to_denseen la CPU y pasar el tensor denso resultante a la parte de TPU del modelo.
Otro factor que debes tener en cuenta es el uso de HBM. Las tablas de incorporación pueden usar mucha HBM. Si crecen más allá de la limitación de hardware de la TPU, se deben colocar en la CPU, junto con las operaciones de búsqueda.
Siempre que sea posible, debe existir una sola función de TPU con una firma. Si la estructura de tu modelo requiere llamar a varias funciones de TPU por solicitud de inferencia entrante, debes tener en cuenta la latencia adicional de enviar tensores entre la CPU y la TPU.
Una buena manera de evaluar la selección de funciones de TPU es consultar el Informe de conversiones. Muestra el porcentaje de procesamiento que se colocó en la TPU y un desglose del costo de cada función de TPU.
¿Cómo puedo mover una parte del modelo a la CPU?
Si tu modelo contiene partes que no se pueden entregar en la TPU, debes refactorizarlo para moverlas a la CPU. Este es un ejemplo de juguete. El modelo es un modelo de lenguaje con una etapa de procesamiento previo. Por motivos de simplicidad, se omite el código de las definiciones y las funciones de las capas.
class LanguageModel(tf.keras.Model): @tf.function def model_func(self, input_string): word_ids = self.preprocess(input_string) return self.bert_layer(word_ids)
Este modelo no se puede entregar directamente en la TPU por dos motivos. Primero, el parámetro es una cadena. En segundo lugar, la función preprocess puede contener muchas operaciones de cadenas. Ninguno de ellos es compatible con TPU.
Para refactorizar este modelo, puedes crear otra función llamada tpu_func para alojar el bert_layer intensivo en procesamiento. Luego, crea un alias de función para tpu_func y pásalo al convertidor. De esta manera, todo lo que esté dentro de tpu_func se ejecutará en la TPU, y todo lo que quede en model_func se ejecutará en la CPU.
class LanguageModel(tf.keras.Model): @tf.function def tpu_func(self, word_ids): return self.bert_layer(word_ids) @tf.function def model_func(self, input_string): word_ids = self.preprocess(input_string) return self.tpu_func(word_ids)
¿Qué debo hacer si el modelo tiene operaciones, cadenas o tensores dispersos incompatibles con TPU?
La mayoría de las operaciones estándar de TensorFlow son compatibles con la TPU, pero algunas, como las cadenas y los tensores dispersos, no lo son. El convertidor no verifica las operaciones incompatibles con TPU. Por lo tanto, un modelo que contenga esas operaciones puede pasar la conversión. Sin embargo, cuando lo ejecutes para la inferencia, se producirán errores como los que se muestran a continuación.
'tf.StringToNumber' op isn't compilable for TPU device.
Si tu modelo tiene operaciones incompatibles con TPU, deben colocarse fuera de la función de TPU. Además, la cadena es un formato de datos no admitido en la TPU. Por lo tanto, las variables de tipo de cadena no deben colocarse en la función de TPU. Además, los parámetros y los valores que se muestran de la función de TPU tampoco deben tener un tipo de cadena. Del mismo modo, evita colocar tensores dispersos en la función de TPU, incluidos en sus parámetros y valores que se muestran.
Por lo general, no es difícil refactorizar la parte incompatible del modelo y moverla a la CPU. Este es un ejemplo.
¿Cómo admitir operaciones personalizadas en el modelo?
Si se usan operaciones personalizadas en tu modelo, es posible que el convertidor no las reconozca y no logre convertirlo. Esto se debe a que la biblioteca de la operación personalizada, que contiene la definición completa de la operación, no está vinculada al convertidor.
Como, en la actualidad, el código del convertidor aún no es de código abierto, no se puede compilar con una operación personalizada.
¿Qué debo hacer si tengo un modelo de TensorFlow 1?
El convertidor no admite modelos de TensorFlow 1. Los modelos de TensorFlow 1 deben migrar a TensorFlow 2.
¿Debo habilitar el puente de MLIR cuando ejecuto mi modelo?
La mayoría de los modelos convertidos se pueden ejecutar con el puente MLIR TF2XLA más reciente o con el puente TF2XLA original.
¿Cómo convierto un modelo que ya se exportó sin un alias de función?
Si un modelo se exportó sin un alias de función, la forma más fácil es volver a exportarlo y crear un alias de función.
Si la reexportación no es una opción, aún es posible convertir el modelo si se proporciona un concrete_function_name. Sin embargo, identificar el concrete_function_name correcto requiere un poco de trabajo de investigación.
Los alias de función son una asignación de una cadena definida por el usuario a un nombre de función concreta. Facilitan la referencia a una función específica en el modelo. El conversor acepta alias de funciones y nombres de funciones concretas sin procesar.
Para encontrar nombres de funciones concretos, examina saved_model.pb.
En el siguiente ejemplo, se muestra cómo colocar una función concreta llamada __inference_serve_24 en la TPU.
sudo docker run \ --mount type=bind,source=${MODEL_PATH},target=/tmp/input,readonly \ --mount type=bind,source=${CONVERTED_MODEL_PATH},target=/tmp/output \ ${CONVERTER_IMAGE} \ --input_model_dir=/tmp/input \ --output_model_dir=/tmp/output \ --converter_options_string=' tpu_functions { concrete_function_name: "__inference_serve_24" }'
¿Cómo resuelvo un error de restricción constante de tiempo de compilación?
Para el entrenamiento y la inferencia, XLA requiere que las entradas de ciertas operaciones tengan una forma conocida en el tiempo de compilación de TPU. Esto significa que, cuando XLA compila la parte de TPU del programa, las entradas de estas operaciones deben tener una forma conocida de forma estática.
Existen dos formas de resolver este problema.
- La mejor opción es actualizar las entradas de la operación para que tengan una forma conocida de forma estática cuando XLA compile el programa de TPU. Esta compilación se realiza justo antes de que se ejecute la parte de TPU del modelo. Esto significa que la forma debería conocerse de forma estática cuando
TpuFunctionesté a punto de ejecutarse. - Otra opción es modificar
TpuFunctionpara que ya no incluya la operación problemática.
¿Por qué recibo un error de forma de procesamiento por lotes?
La agrupación en lotes tiene requisitos de forma estrictos que permiten que las solicitudes entrantes se agrupen en lotes a lo largo de su dimensión 0 (también conocida como dimensión de agrupación). Estos requisitos de forma provienen de la operación de procesamiento por lotes de TensorFlow y no se pueden relajar.
Si no cumples con estos requisitos, se producirán errores como los siguientes:
- Los tensores de entrada por lotes deben tener al menos una dimensión.
- Las dimensiones de las entradas deben coincidir.
- Los tensores de entrada por lotes proporcionados en una invocación de operación determinada deben tener el mismo tamaño de dimensión 0.
- La dimensión 0 del tensor de salida por lotes no es igual a la suma de los tamaños de la dimensión 0 de los tensores de entrada.
Para cumplir con estos requisitos, considera proporcionar una función o una firma diferente al lote. También es posible que debas modificar las funciones existentes para cumplir con estos requisitos.
Si se está procesando una función en lotes, asegúrate de que todas las formas de input_signature de @tf.function tengan None en la dimensión 0. Si se agrupa una firma, asegúrate de que todas sus entradas tengan -1 en la dimensión 0.
Para obtener una explicación completa sobre por qué ocurren estos errores y cómo resolverlos, consulta Análisis detallado de los lotes.
Problemas conocidos
La función de TPU no puede llamar indirectamente a otra función de TPU.
Si bien el convertidor puede controlar la mayoría de las situaciones de llamadas a funciones en el límite entre CPU y TPU, hay un caso extremo poco frecuente en el que fallaría. Ocurre cuando una función de TPU llama indirectamente a otra función de TPU.
Esto se debe a que el convertidor modifica el llamador directo de una función de TPU de llamar a la función de TPU en sí a llamar a un stub de llamada de TPU. El stub de llamada contiene operaciones que solo pueden funcionar en la CPU. Cuando una función de TPU llama a cualquier función que, en última instancia, llama al llamador directo, esas operaciones de CPU se pueden llevar a la TPU para que se ejecuten, lo que generará errores de kernel faltantes. Ten en cuenta que este caso es diferente de una función de TPU que llama directamente a otra función de TPU. En este caso, el convertidor no modifica ninguna función para llamar al stub de llamada, por lo que puede funcionar.
En el convertidor, implementamos la detección de esta situación. Si ves el siguiente error, significa que tu modelo alcanzó este caso extremo:
Unable to place both "__inference_tpu_func_2_46" and "__inference_tpu_func_4_68" on the TPU because "__inference_tpu_func_2_46" indirectly calls "__inference_tpu_func_4_68". This behavior is unsupported because it can cause invalid graphs to be generated.
La solución general es refactorizar el modelo para evitar una situación de llamada a función de este tipo. Si te resulta difícil, comunícate con el equipo de asistencia al cliente de Google para obtener más información.
Reference
Opciones del convertidor en formato Protobuf
message ConverterOptions { // TPU conversion options. repeated TpuFunction tpu_functions = 1; // The state of an optimization. enum State { // When state is set to default, the optimization will perform its // default behavior. For some optimizations this is disabled and for others // it is enabled. To check a specific optimization, read the optimization's // description. DEFAULT = 0; // Enabled. ENABLED = 1; // Disabled. DISABLED = 2; } // Batch options to apply to the TPU Subgraph. // // At the moment, only one batch option is supported. This field will be // expanded to support batching on a per function and/or per signature basis. // // // If not specified, no batching will be done. repeated BatchOptions batch_options = 100; // Global flag to disable all optimizations that are enabled by default. // When enabled, all optimizations that run by default are disabled. If a // default optimization is explicitly enabled, this flag will have no affect // on that optimization. // // This flag defaults to false. bool disable_default_optimizations = 202; // If enabled, apply an optimization that reshapes the tensors going into // and out of the TPU. This reshape operation improves performance by reducing // the transfer time to and from the TPU. // // This optimization is incompatible with input_shape_opt which is disabled. // by default. If input_shape_opt is enabled, this option should be // disabled. // // This optimization defaults to enabled. State io_shape_optimization = 200; // If enabled, apply an optimization that updates float variables and float // ops on the TPU to bfloat16. This optimization improves performance and // throughtput by reducing HBM usage and taking advantage of TPU support for // bfloat16. // // This optimization may cause a loss of accuracy for some models. If an // unacceptable loss of accuracy is detected, disable this optimization. // // This optimization defaults to enabled. State bfloat16_optimization = 201; BFloat16OptimizationOptions bfloat16_optimization_options = 203; // The settings for XLA sharding. If set, XLA sharding is enabled. XlaShardingOptions xla_sharding_options = 204; } message TpuFunction { // The function(s) that should be placed on the TPU. Only provide a given // function once. Duplicates will result in errors. For example, if // you provide a specific function using function_alias don't also provide the // same function via concrete_function_name or jit_compile_functions. oneof name { // The name of the function alias associated with the function that // should be placed on the TPU. Function aliases are created during model // export using the tf.saved_model.SaveOptions. // // This is a recommended way to specify which function should be placed // on the TPU. string function_alias = 1; // The name of the concrete function that should be placed on the TPU. This // is the name of the function as it found in the GraphDef and the // FunctionDefLibrary. // // This is NOT the recommended way to specify which function should be // placed on the TPU because concrete function names change every time a // model is exported. string concrete_function_name = 3; // The name of the signature to be placed on the TPU. The user must make // sure there is no TPU-incompatible op under the entire signature. string signature_name = 5; // When jit_compile_functions is set to True, all jit compiled functions // are placed on the TPU. // // To use this option, decorate the relevant function(s) with // @tf.function(jit_compile=True), before exporting. Then set this flag to // True. The converter will find all functions that were tagged with // jit_compile=True and place them on the TPU. // // When using this option, all other settings for the TpuFunction // will apply to all functions tagged with // jit_compile=True. // // This option will place all jit_compile=True functions on the TPU. // If only some jit_compile=True functions should be placed on the TPU, // use function_alias or concrete_function_name. bool jit_compile_functions = 4; } } message BatchOptions { // Number of scheduling threads for processing batches of work. Determines // the number of batches processed in parallel. This should be roughly in line // with the number of TPU cores available. int32 num_batch_threads = 1; // The maximum allowed batch size. int32 max_batch_size = 2; // Maximum number of microseconds to wait before outputting an incomplete // batch. int32 batch_timeout_micros = 3; // Optional list of allowed batch sizes. If left empty, // does nothing. Otherwise, supplies a list of batch sizes, causing the op // to pad batches up to one of those sizes. The entries must increase // monotonically, and the final entry must equal max_batch_size. repeated int32 allowed_batch_sizes = 4; // Maximum number of batches enqueued for processing before requests are // failed fast. int32 max_enqueued_batches = 5; // If set, disables large batch splitting which is an efficiency improvement // on batching to reduce padding inefficiency. bool disable_large_batch_splitting = 6; // Experimental features of batching. Everything inside is subject to change. message Experimental { // The component to be batched. // 1. Unset if it's for all TPU subgraphs. // 2. Set function_alias or concrete_function_name if it's for a function. // 3. Set signature_name if it's for a signature. oneof batch_component { // The function alias associated with the function. Function alias is // created during model export using the tf.saved_model.SaveOptions, and is // the recommended way to specify functions. string function_alias = 1; // The concreate name of the function. This is the name of the function as // it found in the GraphDef and the FunctionDefLibrary. This is NOT the // recommended way to specify functions, because concrete function names // change every time a model is exported. string concrete_function_name = 2; // The name of the signature. string signature_name = 3; } } Experimental experimental = 7; } message BFloat16OptimizationOptions { // Indicates where the BFloat16 optimization should be applied. enum Scope { // The scope currently defaults to TPU. DEFAULT = 0; // Apply the bfloat16 optimization to TPU computation. TPU = 1; // Apply the bfloat16 optimization to the entire model including CPU // computations. ALL = 2; } // This field indicates where the bfloat16 optimization should be applied. // // The scope defaults to TPU. Scope scope = 1; // If set, the normal safety checks are skipped. For example, if the model // already contains bfloat16 ops, the bfloat16 optimization will error because // pre-existing bfloat16 ops can cause issues with the optimization. By // setting this flag, the bfloat16 optimization will skip the check. // // This is an advanced feature and not recommended for almost all models. // // This flag is off by default. bool skip_safety_checks = 2; // Ops that should not be converted to bfloat16. // Inputs into these ops will be cast to float32, and outputs from these ops // will be cast back to bfloat16. repeated string filterlist = 3; } message XlaShardingOptions { // num_cores_per_replica for TPUReplicateMetadata. // // This is the number of cores you wish to split your model into using XLA // SPMD. int32 num_cores_per_replica = 1; // (optional) device_assignment for TPUReplicateMetadata. // // This is in a flattened [x, y, z, core] format (for // example, core 1 of the chip // located in 2,3,0 will be stored as [2,3,0,1]). // // If this is not specified, then the device assignments will utilize the same // topology as specified in the topology attribute. repeated int32 device_assignment = 2; // A serialized string of tensorflow.tpu.TopologyProto objects, used for // the topology attribute in TPUReplicateMetadata. // // You must specify the mesh_shape and device_coordinates attributes in // the topology object. // // This option is required for num_cores_per_replica > 1 cases due to // ambiguity of num_cores_per_replica, for example, // pf_1x2x1 with megacore and df_1x1 // both have num_cores_per_replica = 2, but topology is (1,2,1,1) for pf and // (1,1,1,2) for df. // - For pf_1x2x1, mesh shape and device_coordinates looks like: // mesh_shape = [1,2,1,1] // device_coordinates=flatten([0,0,0,0], [0,1,0,0]) // - For df_1x1, mesh shape and device_coordinates looks like: // mesh_shape = [1,1,1,2] // device_coordinates=flatten([0,0,0,0], [0,0,0,1]) // - For df_2x2, mesh shape and device_coordinates looks like: // mesh_shape = [2,2,1,2] // device_coordinates=flatten( // [0,0,0,0],[0,0,0,1],[0,1,0,0],[0,1,0,1] // [1,0,0,0],[1,0,0,1],[1,1,0,0],[1,1,0,1]) bytes topology = 3; }
Análisis detallado de los lotes
La agrupación en lotes se usa para mejorar la capacidad de procesamiento y el uso de TPU. Permite que se procesen varias solicitudes al mismo tiempo. Durante el entrenamiento, el procesamiento por lotes se puede realizar con tf.data. Durante la inferencia, por lo general, se agrega una operación en el grafo que agrupa las solicitudes entrantes. La operación espera hasta tener suficientes solicitudes o hasta que se agote el tiempo de espera antes de generar un lote grande a partir de las solicitudes individuales. Consulta Definición de las opciones de procesamiento por lotes para obtener más información sobre las diferentes opciones de procesamiento por lotes que se pueden ajustar, incluidos los tamaños de lotes y los tiempos de espera.
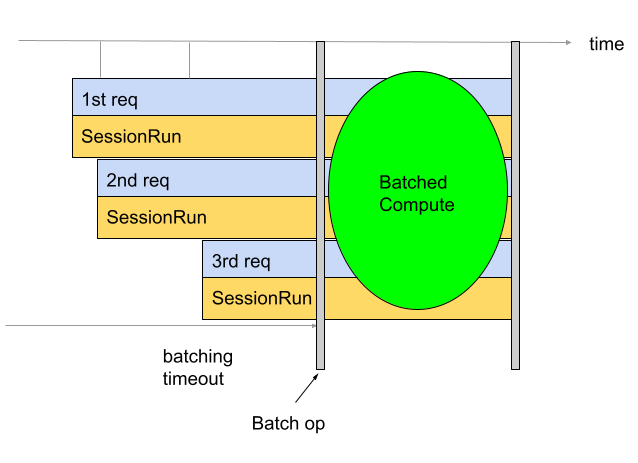
De forma predeterminada, el convertidor inserta la operación de procesamiento por lotes directamente antes del procesamiento de la TPU. Une las funciones de TPU proporcionadas por el usuario y cualquier cálculo de TPU preexistente en el modelo con operaciones por lotes. Para anular este comportamiento predeterminado, debes indicarle al convertidor qué funciones o firmas deben agruparse.
En el siguiente ejemplo, se muestra cómo agregar el procesamiento por lotes predeterminado.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 }
Agrupación en lotes de firmas
El procesamiento por lotes de firmas agrupa todo el modelo, desde las entradas de la firma hasta sus salidas. A diferencia del comportamiento por lotes predeterminado del convertidor, el procesamiento por lotes de firmas agrupa el procesamiento de TPU y el procesamiento de CPU. Esto proporciona un aumento de rendimiento del 10% al 20% durante la inferencia en algunos modelos.
Al igual que todos los lotes, el lote de firmas tiene requisitos de forma estrictos.
Para garantizar que se cumplan estos requisitos de forma, las entradas de firma deben tener formas que tengan al menos dos dimensiones. La primera dimensión es el tamaño del lote y debe tener un tamaño de -1. Por ejemplo, (-1, 4), (-1) o (-1,
128, 4, 10) son formas de entrada válidas. Si no es posible, considera usar
el comportamiento por lotes predeterminado o
por lotes de funciones.
Para usar el procesamiento por lotes de firmas, proporciona los nombres de las firmas como signature_name con BatchOptions.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 experimental { signature_name: "serving_default" } }
Agrupación en lotes de funciones
El procesamiento por lotes de funciones se puede usar para indicarle al convertidor qué funciones se deben procesar por lotes. De forma predeterminada, el convertidor procesará por lotes todas las funciones de TPU. El procesamiento por lotes de funciones anula este comportamiento predeterminado.
El procesamiento por lotes de funciones se puede usar para procesar por lotes la CPU. Muchos modelos observan una mejora en el rendimiento cuando su procesamiento de CPU se realiza por lotes. La mejor manera de realizar el procesamiento por lotes de la CPU es usar el procesamiento por lotes de firmas, pero es posible que no funcione para algunos modelos. En esos casos, se puede usar el procesamiento por lotes de funciones para procesar por lotes parte del procesamiento de la CPU además del procesamiento de la TPU. Ten en cuenta que la operación por lotes no se puede ejecutar en la TPU, por lo que se debe llamar a cualquier función por lotes que se proporcione en la CPU.
El procesamiento por lotes de funciones también se puede usar para satisfacer los requisitos estrictos de forma que impone la operación por lotes. En los casos en que las funciones de TPU no cumplan con los requisitos de forma de la operación por lotes, se puede usar el procesamiento por lotes de funciones para indicarle al Conversor que procese por lotes diferentes funciones.
Para usarlo, genera un function_alias para la función que se debe procesar en lotes. Para ello, busca o crea una función en tu modelo
que una todo lo que deseas procesar por lotes. Asegúrate de que esta función cumpla con los requisitos de forma estrictos que impone la operación por lotes. Agrega @tf.function si aún no lo tienes.
Es importante proporcionar el input_signature a @tf.function. La dimensión 0 debe ser None porque es la dimensión del lote, por lo que no puede tener un tamaño fijo. Por ejemplo, [None, 4], [None] o [None, 128, 4, 10] son
formas de entrada válidas. Cuando guardes el modelo, proporciona SaveOptions como los que se muestran a continuación para darle a model.batch_func un alias "batch_func". Luego, puedes pasar este alias de función al convertidor.
class ToyModel(tf.keras.Model): @tf.function(input_signature=[tf.TensorSpec(shape=[None, 10], dtype=tf.float32)]) def batch_func(self, x): return x * 1.0 ... model = ToyModel() save_options = tf.saved_model.SaveOptions(function_aliases={ 'batch_func': model.batch_func, }) tf.saved_model.save(model, model_dir, options=save_options)
A continuación, pasa los function_alias con BatchOptions.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 experimental { function_alias: "batch_func" } }
Definición de las opciones de procesamiento por lotes
num_batch_threads: (entero) Cantidad de subprocesos de programación para procesar lotes de trabajo. Determina la cantidad de lotes que se procesan en paralelo. Esto debería coincidir aproximadamente con la cantidad de núcleos de TPU disponibles.max_batch_size: (entero) Es el tamaño máximo de lote permitido. Puede ser mayor queallowed_batch_sizespara usar la división de lotes grandes.batch_timeout_micros: (entero) Es la cantidad máxima de microsegundos que se deben esperar antes de generar un lote incompleto.allowed_batch_sizes: (lista de números enteros). Si la lista no está vacía, rellenará los lotes hasta el tamaño más cercano en la lista. La lista debe ser monótonamente creciente y el elemento final debe ser menor o igual quemax_batch_size.max_enqueued_batches: (entero) Es la cantidad máxima de lotes en fila para su procesamiento antes de que las solicitudes fallen rápidamente.
Actualiza las opciones de procesamiento por lotes existentes
Para agregar o actualizar opciones de procesamiento por lotes, ejecuta la imagen de Docker que especifique
batch_options y establece disable_default_optimizations como verdadero con la
marca --converter_options_string. Las opciones por lotes se aplicarán a cada función de TPU o operación por lotes preexistente.
batch_options { num_batch_threads: 2 max_batch_size: 8 batch_timeout_micros: 5000 allowed_batch_sizes: 2 allowed_batch_sizes: 4 allowed_batch_sizes: 8 max_enqueued_batches: 10 } disable_default_optimizations=True
Requisitos de forma de lotes
Para crear lotes, se concatenan los tensores de entrada en todas las solicitudes a lo largo de su dimensión de lote (0). Los tensores de salida se dividen en su dimensión 0. Para realizar estas operaciones, la operación por lotes tiene requisitos de forma estrictos para sus entradas y salidas.
Explicación
Para comprender estos requisitos, es útil comprender primero cómo se realiza el procesamiento por lotes. En el siguiente ejemplo, agrupamos una operación tf.matmul simple.
def my_func(A, B) return tf.matmul(A, B)
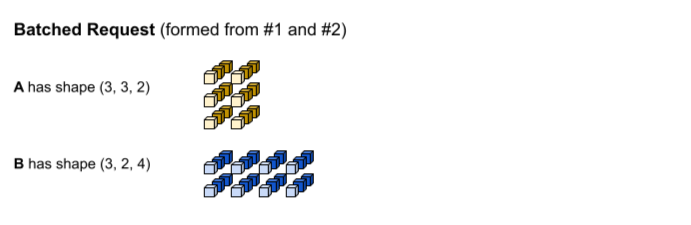
La primera solicitud de inferencia produce las entradas A y B con las formas (1, 3,
2) y (1, 2, 4), respectivamente. La segunda solicitud de inferencia produce las entradas A y B con las formas (2, 3, 2) y (2, 2, 4).

Se alcanzó el tiempo de espera de procesamiento por lotes. El modelo admite un tamaño del lote de 3, por lo que las solicitudes de inferencia 1 y 2 se agrupan en lotes sin ningún relleno. Los tensores por lotes se forman concatenando las solicitudes n° 1 y n° 2 a lo largo de la dimensión del lote (0). Dado que A del n° 1 tiene una forma de (1, 3, 2) y A del n° 2 tiene una forma de (2, 3, 2), cuando se concatenan a lo largo de la dimensión del lote (0), la forma resultante es (3, 3, 2).
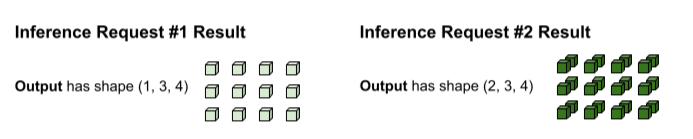
Se ejecuta tf.matmul y se produce un resultado con la forma (3, 3,
4).

El resultado de tf.matmul se agrupa, por lo que se debe volver a dividir en solicitudes separadas. Para ello, la operación de procesamiento por lotes se divide en la dimensión del lote (0) de cada tensor de salida. Decide cómo dividir la dimensión 0 según la forma de las entradas originales. Dado que las formas de la solicitud n° 1 tienen una dimensión 0 de 1, su salida tiene una dimensión 0 de 1 para una forma de (1, 3, 4).
Dado que las formas de la solicitud 2 tienen una dimensión 0 de 2, su salida tiene una dimensión 0 de 2 para una forma de (2, 3, 4).
Requisitos de forma
Para realizar la concatenación de entradas y la división de salidas descritas anteriormente, la operación por lotes tiene los siguientes requisitos de forma:
Las entradas para el procesamiento por lotes no pueden ser escalares. Para concatenar a lo largo de la dimensión 0, los tensores deben tener al menos dos dimensiones.
En la explicación anterior. Ni A ni B son escalares.
Si no cumples con este requisito, se producirá un error como
Batching input tensors must have at least one dimension. Una solución simple para este error es hacer que el escalar sea un vector.En diferentes solicitudes de inferencia (por ejemplo, diferentes invocaciones de ejecución de sesión), los tensores de entrada con el mismo nombre tienen el mismo tamaño para cada dimensión, excepto la dimensión 0. Esto permite que las entradas se concatenan de forma ordenada a lo largo de su dimensión 0.
En la explicación anterior, la A de la solicitud n° 1 tiene la forma de
(1, 3, 2). Esto significa que cualquier solicitud futura debe producir una forma con el patrón(X, 3, 2). La solicitud 2 cumple con este requisito con(2, 3, 2). Del mismo modo, la B de la solicitud n° 1 tiene la forma de(1, 2, 4), por lo que todas las solicitudes futuras deben producir una forma con el patrón(X, 2, 4).Si no cumples con este requisito, se producirá un error como
Dimensions of inputs should match.Para una solicitud de inferencia determinada, todas las entradas deben tener el mismo tamaño de dimensión 0. Si diferentes tensores de entrada a la operación de procesamiento por lotes tienen diferentes dimensiones de orden 0, la operación de procesamiento por lotes no sabe cómo dividir los tensores de salida.
En la explicación anterior, los tensores de la solicitud n° 1 tienen un tamaño de dimensión 0 de 1. Esto le permite a la operación de lotes saber que su salida debe tener un tamaño de dimensión 0 de 1. Del mismo modo, los tensores de la solicitud n° 2 tienen un tamaño de dimensión 0 de 2, por lo que su salida tendrá un tamaño de dimensión 0 de 2. Cuando la operación de lote divide la forma final de
(3, 3, 4), produce(1, 3, 4)para la solicitud n° 1 y(2, 3, 4)para la solicitud n° 2.Si no cumples con este requisito, se producirán errores como
Batching input tensors supplied in a given op invocation must have equal 0th-dimension size.El tamaño de la dimensión 0 de la forma de cada tensor de salida debe ser la suma de todos los tamaños de la dimensión 0 de los tensores de entrada (más cualquier padding que introduzca la operación de procesamiento por lotes para cumplir con el siguiente
allowed_batch_sizemás grande). Esto permite que la operación de procesamiento por lotes divida los tensores de salida a lo largo de su dimensión 0 según la dimensión 0 de los tensores de entrada.En la explicación anterior, los tensores de entrada tienen una dimensión 0 de 1 de la solicitud n° 1 y 2 de la solicitud n° 2. Por lo tanto, cada tensor de salida debe tener una dimensión 0 de 3 porque 1+2=3. El tensor de salida
(3, 3, 4)cumple con este requisito. Si 3 no hubiera sido un tamaño de lote válido, pero 4 sí, la operación de lote habría tenido que rellenar la dimensión 0 de las entradas de 3 a 4. En este caso, cada tensor de salida tendría que tener un tamaño de dimensión 0 de 4.Si no cumples con este requisito, se producirá un error como el siguiente:
Batched output tensor's 0th dimension does not equal the sum of the 0th dimension sizes of the input tensors.
Cómo resolver errores de requisitos de forma
Para cumplir con estos requisitos, considera proporcionar una función o una firma diferente al lote. También es posible que debas modificar las funciones existentes para cumplir con estos requisitos.
Si se está procesando por lotes una función, asegúrate de que las formas de input_signature de @tf.function tengan None en la dimensión 0 (también conocida como dimensión por lotes). Si se agrupa una firma, asegúrate de que todas sus entradas tengan -1 en la dimensión 0.
La operación BatchFunction no admite SparseTensors como entradas ni salidas.
De forma interna, cada tensor disperso se representa como tres tensores separados que pueden tener diferentes tamaños de dimensión 0.