Pengantar Cloud TPU
Tensor Processing Unit (TPU) adalah sirkuit terintegrasi khusus aplikasi (ASIC) yang dikembangkan khusus dari Google yang digunakan untuk mempercepat workload machine learning. Untuk informasi selengkapnya tentang hardware TPU, lihat Arsitektur Sistem. Cloud TPU adalah layanan web yang menjadikan TPU tersedia sebagai resource komputasi yang skalabel di Google Cloud.
TPU melatih model Anda secara lebih efisien menggunakan hardware yang dirancang untuk menjalankan operasi matriks besar yang sering ditemukan dalam algoritma machine learning. TPU memiliki memori bandwidth tinggi (HBM) on-chip, sehingga Anda dapat menggunakan model dan ukuran batch yang lebih besar. TPU dapat dihubungkan dalam grup yang disebut Pod yang meningkatkan skala workload Anda dengan sedikit atau tanpa perubahan kode.
Bagaimana cara kerjanya?
Untuk memahami cara kerja TPU, sebaiknya pahami cara akselerator lainnya mengatasi tantangan komputasi dalam melatih model ML.
Cara kerja CPU
CPU adalah prosesor serbaguna berdasarkan arsitektur von Neumann. Itu berarti CPU bekerja dengan software dan memori seperti ini:
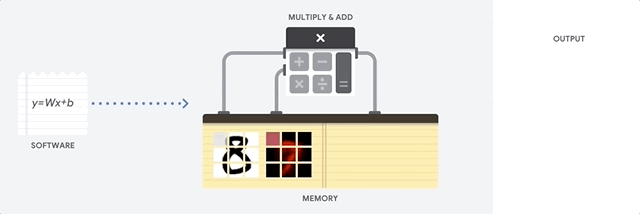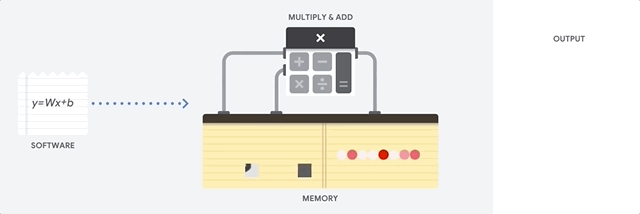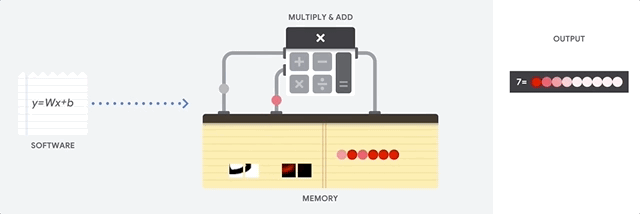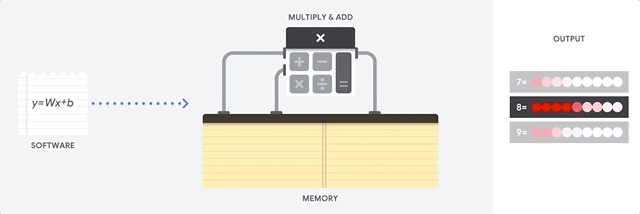
Manfaat terbesar dari CPU adalah fleksibilitasnya. Anda dapat memuat jenis perangkat lunak apa pun ke CPU untuk berbagai jenis aplikasi. Misalnya, Anda dapat menggunakan CPU untuk pemrosesan kata di PC, mengontrol mesin roket, menjalankan transaksi bank, atau mengklasifikasikan gambar dengan jaringan neural.
CPU memuat nilai dari memori, melakukan penghitungan nilai, dan menyimpan hasilnya kembali dalam memori untuk setiap penghitungan. Akses memori lambat jika dibandingkan dengan kecepatan penghitungan dan dapat membatasi total throughput CPU. Hal ini sering disebut sebagai bottleneck von Neumann.
Cara kerja GPU
Untuk mendapatkan throughput yang lebih tinggi, GPU berisi ribuan Arithmetic Logic Unit (ALU) dalam satu prosesor. GPU modern biasanya mengandung antara 2.500–5.000 ALU. Dengan banyaknya jumlah prosesor, Anda dapat menjalankan ribuan perkalian dan penambahan secara bersamaan.

Arsitektur GPU ini berfungsi dengan baik pada aplikasi dengan paralelisme masif, seperti operasi matriks di jaringan neural. Bahkan, pada workload pelatihan standar untuk deep learning, GPU dapat memberikan throughput yang jauh lebih tinggi daripada CPU.
Namun, GPU masih merupakan prosesor serbaguna yang harus mendukung banyak aplikasi dan software yang berbeda. Oleh karena itu, GPU memiliki masalah yang sama dengan CPU. Untuk setiap penghitungan dalam ribuan ALU, GPU harus mengakses register atau memori bersama untuk membaca operand dan menyimpan hasil penghitungan perantara.
Cara kerja TPU
Google merancang Cloud TPU sebagai pemroses matriks yang dikhususkan untuk workload jaringan neural. TPU tidak dapat menjalankan pengolah kata, mengontrol mesin roket, atau menjalankan transaksi bank, tetapi dapat menangani operasi matriks besar yang digunakan di jaringan neural dengan kecepatan tinggi.
Tugas utama TPU adalah pemrosesan matriks, yang merupakan kombinasi dari operasi pengali dan akumulasi. TPU berisi ribuan multi-akumulator yang terhubung langsung satu sama lain untuk membentuk matriks fisik yang besar. Ini disebut arsitektur array sistolik. Cloud TPU v3, berisi dua array sistolik ALU 128 x 128, pada satu prosesor.
Host TPU mengalirkan data ke antrean dalam feed. TPU memuat data dari antrean dalam feed dan menyimpannya dalam memori HBM. Setelah komputasi selesai, TPU akan memuat hasilnya ke antrean outfeed. Host TPU kemudian membaca hasil dari antrean outfeed dan menyimpannya dalam memori host.
Untuk melakukan operasi matriks, TPU memuat parameter dari memori HBM ke dalam Matrix Multiplication Unit (MXU).

Kemudian, TPU akan memuat data dari memori HBM. Saat setiap perkalian dieksekusi, hasilnya diteruskan ke akumulator pengali berikutnya. Output-nya adalah penjumlahan dari semua hasil perkalian antara data dan parameter. Tidak ada akses memori yang diperlukan selama proses perkalian matriks.
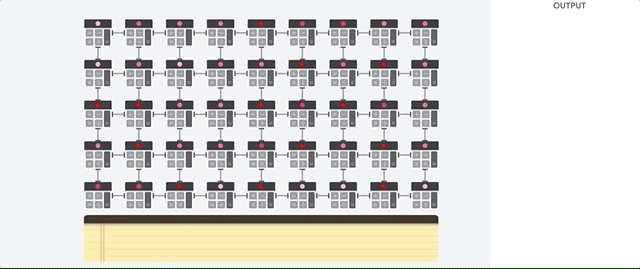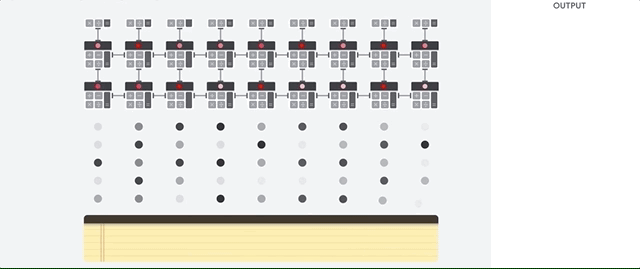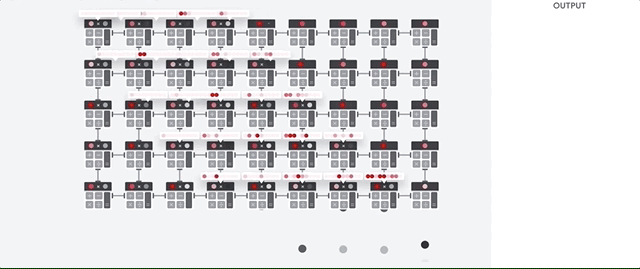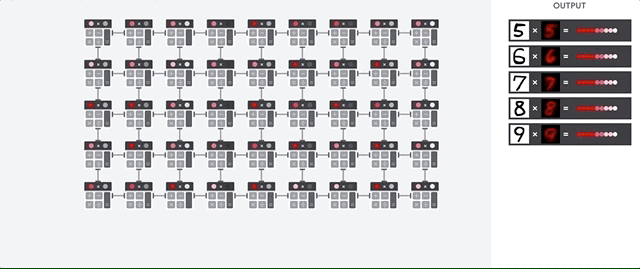
Hasilnya, TPU dapat mencapai throughput komputasi yang tinggi pada penghitungan jaringan neural.
Compiler XLA
Kode yang berjalan di TPU harus dikompilasi oleh compiler aljabar linear akselerator (XLA). XLA adalah compiler tepat waktu yang mengambil grafik yang dikeluarkan oleh aplikasi framework ML dan mengompilasi komponen aljabar, kerugian, dan gradien linear dari grafik ke dalam kode mesin TPU. Program lainnya berjalan di mesin host TPU. Compiler XLA adalah bagian dari runtime TPU yang berjalan pada mesin host TPU.
Kapan harus menggunakan TPU
Cloud TPU dioptimalkan untuk workload tertentu. Dalam beberapa situasi, Anda mungkin ingin menggunakan GPU atau CPU di instance Compute Engine untuk menjalankan workload machine learning. Secara umum, Anda dapat menentukan hardware yang paling cocok untuk beban kerja Anda berdasarkan panduan berikut:
CPU
- Pembuatan prototipe cepat yang membutuhkan fleksibilitas maksimum
- Model sederhana yang tidak membutuhkan waktu lama untuk dilatih
- Model kecil dengan ukuran tumpukan yang kecil dan efektif
- Model yang berisi banyak operasi TensorFlow kustom yang ditulis dalam C++
- Model yang dibatasi oleh I/O yang tersedia atau bandwidth jaringan sistem host
GPU
- Model dengan operasi TensorFlow/PyTorch/JAX kustom dalam jumlah besar yang harus berjalan setidaknya sebagian di CPU
- Model dengan operasi TensorFlow yang tidak tersedia di Cloud TPU (lihat daftar operasi TensorFlow yang tersedia)
- Model sedang hingga besar dengan ukuran tumpukan efektif yang lebih besar
TPU
- Model yang didominasi oleh komputasi matriks
- Model tanpa operasi TensorFlow/PyTorch/JAX kustom di dalam loop pelatihan utama
- Model yang dilatih selama berminggu-minggu atau berbulan-bulan
- Model besar dengan ukuran tumpukan efektif yang besar
Cloud TPU tidak cocok untuk workload berikut:
- Program aljabar linear yang memerlukan percabangan sering atau berisi banyak operasi aljabar berbasis elemen
- Beban kerja yang mengakses memori secara renggang
- Beban kerja yang memerlukan aritmetika presisi tinggi
- Workload jaringan neural yang berisi operasi kustom di loop pelatihan utama
Praktik terbaik untuk pengembangan model
Program yang komputasinya didominasi oleh operasi non-matriks seperti menambah, membentuk ulang, atau menyambungkan, kemungkinan tidak akan mencapai pemanfaatan MXU yang tinggi. Berikut ini adalah beberapa panduan untuk membantu Anda memilih dan mem-build model yang cocok untuk Cloud TPU.
Tata Letak
Compiler XLA melakukan transformasi kode, termasuk menggabungkan matriks dengan perkalian menjadi blok yang lebih kecil, untuk menjalankan komputasi secara efisien pada unit matriks (MXU). Struktur hardware MXU, array sistolik 128x128, dan desain subsistem memori TPU, yang lebih memilih dimensi kelipatan 8, digunakan oleh compiler XLA untuk efisiensi penyusunan ubin. Karenanya, tata letak tertentu lebih kondusif untuk penyusunan ubin, sementara tata letak lain memerlukan pembentukan ulang agar dilakukan sebelum dapat di-tiler. Operasi pembentukan ulang sering kali terikat pada memori di Cloud TPU.
Bentuk
Compiler XLA mengompilasi grafik ML tepat pada waktunya untuk batch pertama. Jika ada batch berikutnya yang memiliki bentuk yang berbeda, model tidak akan berfungsi. (Mengompilasi ulang grafik setiap kali perubahan bentuk terlalu lambat.) Oleh karena itu, model apa pun yang memiliki TensorFlow dengan bentuk dinamis yang berubah saat runtime tidak cocok untuk TPU.
Padding
Program Cloud TPU berperforma tinggi adalah program tempat komputasi padat dapat dengan mudah digabungkan menjadi potongan 128x128. Jika komputasi matriks tidak dapat menempati seluruh MXU, compiler pad akan memberikan nilai pada TensorFlow dengan nol. Ada dua kelemahan untuk padding:
- Tensor dilengkapi dengan angka nol yang kurang memanfaatkan inti TPU.
- Padding meningkatkan jumlah penyimpanan memori pada chip yang diperlukan untuk tensor dan dapat menyebabkan error kehabisan memori dalam kasus yang ekstrem.
Meskipun padding otomatis dilakukan oleh compiler XLA saat diperlukan, seseorang dapat menentukan jumlah padding yang dilakukan dengan menggunakan alat op_profile. Anda dapat menghindari padding dengan memilih dimensi TensorFlow yang cocok untuk TPU.
Dimensi
Memilih dimensi TensorFlow yang sesuai sangat membantu dalam mengekstrak performa maksimum dari hardware TPU, terutama MXU. Compiler XLA mencoba menggunakan ukuran batch atau dimensi fitur untuk memanfaatkan MXU secara maksimal. Oleh karena itu, salah satu dari jumlah tersebut harus kelipatan 128. Jika tidak, compiler akan menambahkan kode 128 ke salah satunya. Idealnya, ukuran batch serta dimensi fitur harus kelipatan 8, yang memungkinkan ekstraksi performa tinggi dari subsistem memori.
Integrasi Kontrol Layanan VPC
Dengan Kontrol Layanan VPC Cloud TPU, Anda dapat menentukan perimeter keamanan di sekitar resource Cloud TPU dan mengontrol pergerakan data di seluruh batas perimeter. Untuk mempelajari lebih lanjut Kontrol Layanan VPC, lihat ringkasan Kontrol Layanan VPC. Untuk mempelajari batasan penggunaan Cloud TPU dengan Kontrol Layanan VPC, lihat produk dan batasan yang didukung.
Edge TPU
Model machine learning yang dilatih di cloud semakin perlu menjalankan inferensi "di edge"—yaitu, di perangkat yang beroperasi di edge Internet of Things (IoT). Perangkat ini mencakup sensor dan perangkat smart lainnya yang mengumpulkan data real-time, membuat keputusan cerdas, lalu mengambil tindakan atau menyampaikan informasinya ke perangkat lain atau cloud.
Karena perangkat tersebut harus beroperasi dengan daya terbatas (termasuk daya baterai), Google mendesain koprosesor Edge TPU untuk mempercepat inferensi ML pada perangkat berdaya rendah. Setiap Edge TPU dapat melakukan 4 triliun operasi per detik (4 TOPS), hanya menggunakan daya 2 watt. Dengan kata lain, Anda mendapatkan 2 TOPS per watt. Misalnya, Edge TPU dapat menjalankan model mobile vision canggih seperti MobileNet V2 dengan hampir 400 frame per detik, dan dengan cara yang hemat daya.
Akselerator ML berdaya rendah ini mendukung Cloud TPU dan Cloud IoT untuk menyediakan infrastruktur menyeluruh (cloud-to-edge, hardware + software) yang memfasilitasi solusi berbasis AI.
Edge TPU tersedia untuk perangkat pembuatan prototipe dan produksi Anda sendiri dalam beberapa faktor bentuk, termasuk komputer single-board, sistem di modul, kartu PCIe/M.2, dan modul yang dipasang di platform. Untuk mengetahui informasi selengkapnya tentang Edge TPU dan semua produk yang tersedia, kunjungi karang.ai.
Memulai Cloud TPU
- Menyiapkan akun Google Cloud
- Mengaktifkan Cloud TPU API
- Memberi Cloud TPU akses ke bucket Cloud Storage
- Menjalankan penghitungan dasar di TPU
- Melatih model referensi di TPU
- Menganalisis model
Meminta bantuan
Hubungi dukungan Cloud TPU. Jika Anda memiliki project Google Cloud yang aktif, bersiaplah untuk memberikan informasi berikut:
- ID project Google Cloud Anda
- Nama node TPU Anda, jika ada
- Informasi lain yang ingin Anda berikan
Apa langkah selanjutnya?
Ingin mempelajari Cloud TPU lebih lanjut? Referensi berikut dapat membantu: