TPU v3
In diesem Dokument werden die Architektur und die unterstützten Konfigurationen von Cloud TPU v3 beschrieben.
Systemarchitektur
Jeder TPU-Chip der Version 3 enthält zwei TensorCores. Jeder TensorCore hat zwei Matrixmultiplikationseinheiten (MXUs), eine Vektoreinheit und eine Skalareinheit. Die folgende Tabelle enthält die wichtigsten Spezifikationen und ihre Werte für einen TPU-Pod der Version 3.
| Wichtige Spezifikationen | Werte für v3-Pods |
|---|---|
| Spitzenleistung pro Chip | 123 Teraflops (bf16) |
| HBM2-Kapazität und ‑Bandbreite | 32 GiB, 900 GB/s |
| Gemessene minimale/durchschnittliche/maximale Leistung | 123/220/262 W |
| TPU-Pod-Größe | 1.024 Chips |
| Interconnect-Topologie | 2D-Torus |
| Spitzenberechnung pro Pod | 126 PetaFLOPS (bf16) |
| All-Reduce-Bandbreite pro Pod | 340 TB/s |
| Geteilte Bandbreite pro Pod | 6,4 TB/s |
Das folgende Diagramm zeigt einen TPU v3-Chip.
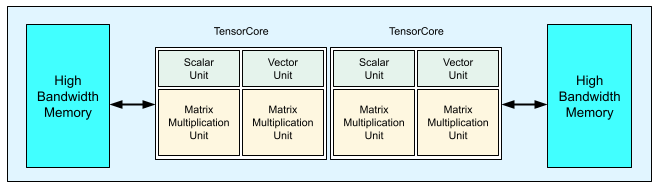
Details zur Architektur und zu den Leistungsmerkmalen von TPU v3 sind unter Domainspezifischer Supercomputer zum Trainieren neuronaler Deep-Learning-Netzwerke verfügbar.
Leistungsvorteile von TPU v3 im Vergleich zu v2
Die größere Anzahl von FLOPS pro TensorCore und größere Speicherkapazität bei TPU v3-Konfigurationen können die Leistung von Modellen auf folgende Weise verbessern:
TPU v3-Konfigurationen bieten für rechenintensive Modelle erhebliche Leistungsvorteile pro Tensor Core. Für speichergebundene Modelle kann im Vergleich zu TPU v2-Konfigurationen möglicherweise nicht dieselbe Leistungsverbesserung erzielt werden, wenn sie auch bei TPU v3-Konfigurationen speichergebunden sind.
Wenn Daten in TPU v2-Konfigurationen den Speicherplatz überschreiten, ist mit TPU v3 eine bessere Leistung möglich und es müssen weniger Zwischenwerte neu berechnet werden (Neuberechnen von Schreibergebnissen).
Mit TPU v3-Konfigurationen können neue Modelle mit Stapelgrößen ausgeführt werden, für die TPU v2-Konfigurationen nicht ausgereicht haben. Zum Beispiel lässt TPU v3 tiefere ResNet-Modelle und größere Bilder mit RetinaNet zu.
Modelle, die auf TPU v2-Hardware nahezu eingabegebunden arbeiten ("Infeed"), da Trainingsschritte auf Eingaben warten müssen, arbeiten unter Umständen auch auf Cloud TPU v3-Hardware eingabegebunden. Mit dem Leitfaden zur Leistung von Pipelines können Sie Einspeisungsprobleme beheben.
Konfigurationen
Ein TPU v3-Pod besteht aus 1.024 Chips, die über Hochgeschwindigkeitsverbindungen miteinander verbunden sind. Wenn Sie ein TPU v3-Gerät oder ‑Speicherebenensegment erstellen möchten, verwenden Sie das Flag --accelerator-type im Befehl zum Erstellen von TPUs (gcloud compute tpus tpu-vm). Sie geben den Beschleunigertyp an, indem Sie die TPU-Version und die Anzahl der TPU-Kerne angeben. Verwenden Sie beispielsweise --accelerator-type=v3-8 für eine einzelne v3-TPU. Verwenden Sie für einen v3-Speicherbereich mit 128 TensorCores --accelerator-type=v3-128.
In der folgenden Tabelle sind die unterstützten TPU-Typen der Version 3 aufgeführt:
| TPU-Version | Support-Ende |
|---|---|
| v3-8 | (Enddatum wurde noch nicht festgelegt) |
| v3-32 | (Enddatum wurde noch nicht festgelegt) |
| v3-128 | (Enddatum wurde noch nicht festgelegt) |
| v3-256 | (Enddatum wurde noch nicht festgelegt) |
| v3-512 | (Enddatum wurde noch nicht festgelegt) |
| v3-1024 | (Enddatum wurde noch nicht festgelegt) |
| v3-2048 | (Enddatum wurde noch nicht festgelegt) |
Der folgende Befehl zeigt, wie Sie ein TPU-Stück der Version 3 mit 128 TensorCores erstellen:
$ gcloud compute tpus tpu-vm create tpu-name \ --zone=europe-west4-a \ --accelerator-type=v3-128 \ --version=tpu-ubuntu2204-base
Weitere Informationen zum Verwalten von TPUs finden Sie unter TPUs verwalten. Weitere Informationen zur Systemarchitektur von Cloud TPU finden Sie unter Systemarchitektur.