Este tutorial vai ajudá-lo a:
- Criar uma VM do Cloud TPU para implantar a família de modelos de linguagem grandes (LLMs) Llama 2, disponível em diferentes tamanhos (7B, 13B ou 70B)
- Preparando checkpoints para os modelos e implantando-os no SAX
- Interagir com o modelo usando um endpoint HTTP
A disponibilização para experimentos de AGI (SAX, na sigla em inglês) é um sistema experimental que exibe modelos Paxml, JAX e PyTorch para inferência. Código e documentação para SAX estão no repositório Git do Saxml. A versão estável atual compatível com a TPU v5e é a v1.1.0.
Sobre as células SAX
Uma célula SAX (ou cluster) é a unidade principal para veicular seus modelos. Ele consiste em duas partes principais:
- Servidor de administrador: monitora os servidores de modelos, atribui modelos a esses servidores e ajuda os clientes a encontrar o servidor de modelos certo para interagir.
- Servidores de modelo: esses servidores executam seu modelo. Eles são responsáveis pela processar solicitações recebidas e gerar respostas.
Veja no diagrama a seguir uma célula SAX:
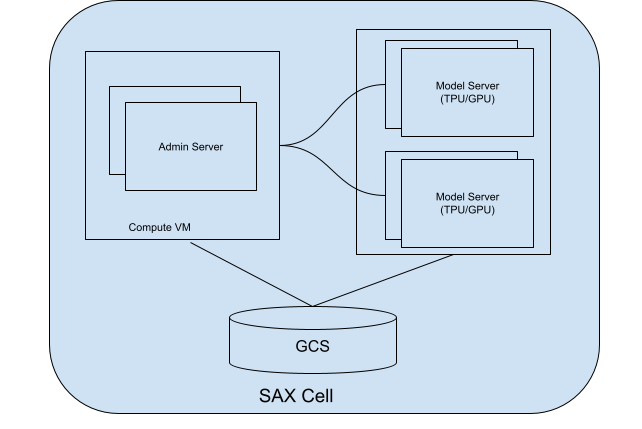
Figura 1. Célula SAX com servidor administrador e servidor modelo.
Você pode interagir com uma célula SAX usando clientes escritos em Python, C++ ou Go, ou diretamente por um servidor HTTP. O diagrama a seguir mostra como um servidor cliente pode interagir com uma célula SAX:

Figura 2. Arquitetura do ambiente de execução de um cliente externo interagindo com um SAX célula
Objetivos
- Configurar recursos de TPU para veiculação
- Criar um cluster SAX
- Publicar o modelo Llama 2
- Interagir com o modelo
Custos
Neste documento, você usará os seguintes componentes faturáveis do Google Cloud:
- Cloud TPU
- Compute Engine
- Cloud Storage
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Antes de começar
Configure seu projeto do Google Cloud, ative a API Cloud TPU e crie um conta de serviço seguindo as instruções em Configurar o Cloud TPU de código aberto.
Criar TPU
As etapas a seguir mostram como criar uma VM de TPU, que vai atender seu modelo.
Crie variáveis de ambiente:
export PROJECT_ID=PROJECT_ID export ACCELERATOR_TYPE=ACCELERATOR_TYPE export ZONE=ZONE export RUNTIME_VERSION=v2-alpha-tpuv5-lite export SERVICE_ACCOUNT=SERVICE_ACCOUNT export TPU_NAME=TPU_NAME export QUEUED_RESOURCE_ID=QUEUED_RESOURCE_ID
Descrições das variáveis de ambiente
PROJECT_ID- O ID do seu projeto do Google Cloud.
ACCELERATOR_TYPE- O tipo de acelerador especifica a versão e o tamanho do
o Cloud TPU que você quer criar. Diferentes tamanhos de modelos do Llama 2 têm
diferentes requisitos de tamanho de TPU:
- 7B:
v5litepod-4ou maior - 13B:
v5litepod-8ou mais recente - 70B:
v5litepod-16ou maior
- 7B:
ZONE- A zona em que você quer criar o Cloud TPU.
SERVICE_ACCOUNT- A conta de serviço que você quer anexar ao Cloud TPU.
TPU_NAME- O nome do Cloud TPU.
QUEUED_RESOURCE_ID- Um identificador para sua solicitação de recurso na fila.
Defina o ID do projeto e a zona na configuração ativa da Google Cloud CLI:
gcloud config set project $PROJECT_ID && gcloud config set compute/zone $ZONECrie a VM da TPU:
gcloud compute tpus queued-resources create ${QUEUED_RESOURCE_ID} \ --node-id ${TPU_NAME} \ --project ${PROJECT_ID} \ --zone ${ZONE} \ --accelerator-type ${ACCELERATOR_TYPE} \ --runtime-version ${RUNTIME_VERSION} \ --service-account ${SERVICE_ACCOUNT}Verifique se a TPU está ativa:
gcloud compute tpus queued-resources list --project $PROJECT_ID --zone $ZONE
Configurar o nó de conversão do checkpoint
Para executar os modelos Llama em um cluster SAX, é necessário converter os pontos de verificação originais do Llama em um formato compatível com SAX.
A conversão requer recursos de memória significativos, dependendo do tamanho do modelo:
| Modelo | Tipo de máquina |
|---|---|
| 7B | 50-60 GB de memória |
| 13B | 120 GB de memória |
| 70 bi | Memória de 500 a 600 GB (tipo de máquina N2 ou M1) |
Para os modelos 7B e 13B, é possível executar a conversão na VM de TPU. Para o modelo 70B, é necessário criar uma instância do Compute Engine com aproximadamente 1 TB de espaço em disco:
gcloud compute instances create INSTANCE_NAME --project=$PROJECT_ID --zone=$ZONE \ --machine-type=n2-highmem-128 \ --network-interface=network-tier=PREMIUM,stack-type=IPV4_ONLY,subnet=default \ --maintenance-policy=MIGRATE --provisioning-model=STANDARD \ --service-account=$SERVICE_ACCOUNT \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --tags=http-server,https-server \ --create-disk=auto-delete=yes,boot=yes,device-name=bk-workday-dlvm,image=projects/ml-images/global/images/c0-deeplearning-common-cpu-v20230925-debian-10,mode=rw,size=500,type=projects/$PROJECT_ID/zones/$ZONE/diskTypes/pd-balanced \ --no-shielded-secure-boot \ --shielded-vtpm \ --shielded-integrity-monitoring \ --labels=goog-ec-src=vm_add-gcloud \ --reservation-affinity=any
Não importa se você usa uma instância de TPU ou do Compute Engine como servidor de conversão: configure o servidor para converter os checkpoints do Llama 2:
Para os modelos 7B e 13B, defina a variável de ambiente de nome do servidor como o nome da TPU:
export CONV_SERVER_NAME=$TPU_NAMEPara o modelo 70B, defina a variável de ambiente do nome do servidor como o nome da sua instância do Compute Engine:
export CONV_SERVER_NAME=INSTANCE_NAME
Conecte-se ao nó de conversão usando SSH.
Se o nó de conversão for uma TPU, conecte-se a ela:
gcloud compute tpus tpu-vm ssh $CONV_SERVER_NAME --project=$PROJECT_ID --zone=$ZONESe o nó de conversão for uma instância do Compute Engine, conecte-se à VM do Compute Engine:
gcloud compute ssh $CONV_SERVER_NAME --project=$PROJECT_ID --zone=$ZONEInstale os pacotes necessários no nó de conversão:
sudo apt update sudo apt-get install python3-pip sudo apt-get install git-all pip3 install paxml==1.1.0 pip3 install torch pip3 install jaxlib==0.4.14Faça o download do script de conversão de checkpoint do Llama:
gcloud storage cp gs://cloud-tpu-inference-public/sax-tokenizers/llama/convert_llama_ckpt.py .
Fazer o download dos pesos do Llama 2
Antes de converter o modelo, você precisa fazer o download dos pesos da Llama 2. Para isso é preciso usar os pesos originais do Llama 2 (por exemplo, meta-llama/Llama-2-7b) e não os pesos que foram convertidos para o formato Hugging Face Transformers (por exemplo, meta-llama/Llama-2-7b-hf).
Se você já tiver os pesos do Llama 2, avance para a seção Converter o pesos específicos.
Para fazer o download dos pesos do hub Hugging Face, é necessário definir configure um token de acesso do usuário e solicitar acesso aos modelos Llama 2. Para solicitar acesso, siga as instruções na página do Hugging Face para o modelo que quer usar, por exemplo, meta-llama/Llama-2-7b.
Crie um diretório para os pesos:
sudo mkdir WEIGHTS_DIRECTORY
Pegue os pesos Llama2 no hub Hugging Face:
Instale a CLI do hub do Hugging Face:
pip install -U "huggingface_hub[cli]"Mude para o diretório de pesos:
cd WEIGHTS_DIRECTORY
Faça o download dos arquivos do Llama 2:
python3 from huggingface_hub import login login() from huggingface_hub import hf_hub_download, snapshot_download import os PATH=os.getcwd() snapshot_download(repo_id="meta-llama/LLAMA2_REPO", local_dir_use_symlinks=False, local_dir=PATH)
Substitua LLAMA2_REPO pelo nome do repositório do Hugging Face de onde você quer fazer o download:
Llama-2-7b,Llama-2-13bouLlama-2-70b.
Converter os pesos
Edite o script de conversão e execute-o para converter os pesos do modelo.
Crie um diretório para armazenar os pesos convertidos:
sudo mkdir CONVERTED_WEIGHTS
Clone o repositório Saxml do GitHub em um diretório onde você possa ler, gravar e as permissões de execução:
git clone https://github.com/google/saxml.git -b r1.1.0Altere para o diretório
saxml:cd saxmlAbra o arquivo
saxml/tools/convert_llama_ckpt.py.No arquivo
saxml/tools/convert_llama_ckpt.py, altere a linha 169 de:'scale': pytorch_vars[0]['layers.%d.attention_norm.weight' % (layer_idx)].type(torch.float16).numpy()Para:
'scale': pytorch_vars[0]['norm.weight'].type(torch.float16).numpy()Execute o script
saxml/tools/init_cloud_vm.sh:saxml/tools/init_cloud_vm.shSomente para 70 bilhões: desative o modo de teste:
- Abra o
saxml/server/pax/lm/params/lm_cloud.py. Na
saxml/server/pax/lm/params/lm_cloud.pyaltere a linha 344 de:return TruePara:
return False
- Abra o
Converta os pesos:
python3 saxml/tools/convert_llama_ckpt.py --base-model-path WEIGHTS_DIRECTORY \ --pax-model-path CONVERTED_WEIGHTS \ --model-size MODEL_SIZE
Substitua:
- WEIGHTS_DIRECTORY: diretório dos pesos originais.
- CONVERTED_WEIGHTS: caminho de destino das ponderações convertidas.
- MODEL_SIZE:
7b,13bou70b.
Preparar o diretório de pontos de verificação
Depois de converter os pontos de verificação, o diretório de pontos de verificação terá a seguinte estrutura:
checkpoint_00000000
metadata/
metadata
state/
mdl_vars.params.lm*/
...
...
step/
Crie um arquivo vazio chamado commit_success.txt e coloque uma cópia dele nos diretórios
checkpoint_00000000, metadata e state. Isso permite que o SAX saiba
se o checkpoint está totalmente convertido e pronto para ser carregado:
Mude para o diretório de verificação:
cd CONVERTED_WEIGHTS/checkpoint_00000000
Crie um arquivo vazio chamado
commit_success.txt:touch commit_success.txtMude para o diretório de metadados e crie um arquivo vazio chamado
commit_success.txt:cd metadata && touch commit_success.txtMude para o diretório de estado e crie um arquivo vazio chamado
commit_success.txt:cd .. && cd state && touch commit_success.txt
O diretório de checkpoint agora terá a seguinte estrutura:
checkpoint_00000000
commit_success.txt
metadata/
commit_success.txt
metadata
state/
commit_success.txt
mdl_vars.params.lm*/
...
...
step/
Criar um bucket do Cloud Storage
Você precisa armazenar os arquivos checkpoints em um bucket do Cloud Storage para que eles sejam disponíveis ao publicar o modelo.
Defina uma variável de ambiente para o nome do bucket do Cloud Storage:
export GSBUCKET=BUCKET_NAME
Crie um bucket:
gcloud storage buckets create gs://${GSBUCKET}Copie os arquivos de ponto de verificação convertidos para o bucket:
gcloud storage cp -r CONVERTED_WEIGHTS/checkpoint_00000000 gs://$GSBUCKET/sax_models/llama2/SAX_LLAMA2_DIR/
Substitua SAX_LLAMA2_DIR pelo valor apropriado:
- 7 bi:
saxml_llama27b - 13 bi:
saxml_llama213b - 70B:
saxml_llama270b
- 7 bi:
Criar cluster SAX
Para criar um cluster SAX, você precisa:
- Criar um servidor de administrador
- Crie um servidor de modelo
- Implante o modelo no servidor de modelos
Em uma implantação típica, você executa o servidor de administrador em uma instância do Compute Engine e o servidor de modelo em uma TPU ou GPU. Para este você vai implantar o servidor administrador e o servidor de modelo na mesma TPU v5e do Compute Engine.
Criar servidor de administrador
Crie o contêiner do Docker do servidor de administrador:
No servidor de conversão, instale o Docker:
sudo apt-get update sudo apt-get install docker.ioInicie o contêiner do Docker do servidor de administrador:
sudo docker run --name sax-admin-server \ -it \ -d \ --rm \ --network host \ --env GSBUCKET=${GSBUCKET} us-docker.pkg.dev/cloud-tpu-images/inference/sax-admin-server:v1.1.0
É possível executar o comando docker run sem a opção -d para visualizar os registros e
garantir que o servidor de administração seja iniciado corretamente.
Criar servidor de modelo
As seções a seguir mostram como criar um servidor de modelo.
Modelo 7b
Inicie o contêiner do Docker do servidor de modelo:
sudo docker run --privileged \
-it \
-d \
--rm \
--network host \
--name "sax-model-server" \
--env SAX_ROOT=gs://${GSBUCKET}/sax-root us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0 \
--sax_cell="/sax/test" \
--port=10001 \
--platform_chip=tpuv5e \
--platform_topology='4'
Modelo 13b
A configuração de LLaMA13BFP16TPUv5e não está presente em lm_cloud.py. O
as etapas a seguir mostram como atualizar lm_cloud.py e confirmar uma nova imagem Docker.
Inicie o servidor de modelo:
sudo docker run --privileged \ -it \ -d \ --rm \ --network host \ --name "sax-model-server" \ --env SAX_ROOT=gs://${GSBUCKET}/sax-root \ us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0 \ --sax_cell="/sax/test" \ --port=10001 \ --platform_chip=tpuv5e \ --platform_topology='8'Conecte-se ao contêiner do Docker usando SSH:
sudo docker exec -it sax-model-server bashInstale o Vim na imagem do Docker:
$ apt update $ apt install vimAbra o arquivo
saxml/server/pax/lm/params/lm_cloud.py. PesquiseLLaMA13B. O seguinte código vai aparecer:@servable_model_registry.register @quantization.for_transformer(quantize_on_the_fly=False) class LLaMA13B(BaseLLaMA): """13B model on a A100-40GB. April 12, 2023 Latency = 5.06s with 128 decoded tokens. 38ms per output token. """ NUM_LAYERS = 40 VOCAB_SIZE = 32000 DIMS_PER_HEAD = 128 NUM_HEADS = 40 MODEL_DIMS = 5120 HIDDEN_DIMS = 13824 ICI_MESH_SHAPE = [1, 1, 1] @property def test_mode(self) -> bool: return TrueComente ou exclua a linha que começa com
@quantization. Depois disso mudar, o arquivo será semelhante ao seguinte:@servable_model_registry.register class LLaMA13B(BaseLLaMA): """13B model on a A100-40GB. April 12, 2023 Latency = 5.06s with 128 decoded tokens. 38ms per output token. """ NUM_LAYERS = 40 VOCAB_SIZE = 32000 DIMS_PER_HEAD = 128 NUM_HEADS = 40 MODEL_DIMS = 5120 HIDDEN_DIMS = 13824 ICI_MESH_SHAPE = [1, 1, 1] @property def test_mode(self) -> bool: return TrueAdicione o código a seguir para oferecer suporte à configuração da TPU.
@servable_model_registry.register class LLaMA13BFP16TPUv5e(LLaMA13B): """13B model on TPU v5e-8. """ BATCH_SIZE = [1] BUCKET_KEYS = [128] MAX_DECODE_STEPS = [32] ENABLE_GENERATE_STREAM = False ICI_MESH_SHAPE = [1, 1, 8] @property def test_mode(self) -> bool: return FalseSaia da sessão SSH do contêiner do Docker:
exitConfirme as alterações em uma nova imagem do Docker:
sudo docker commit sax-model-server sax-model-server:v1.1.0-modVerifique se a nova imagem Docker foi criada:
sudo docker imagesÉ possível publicar a imagem Docker no Artifact Registry do projeto, mas vai continuar com a imagem local.
Pare o servidor de modelo. O restante do tutorial usará o modelo atualizado servidor.
sudo docker stop sax-model-serverInicie o servidor do modelo usando a imagem do Docker atualizada. Certifique-se de especificar o nome da imagem atualizado,
sax-model-server:v1.1.0-mod:sudo docker run --privileged \ -it \ -d \ --rm \ --network host \ --name "sax-model-server" \ --env SAX_ROOT=gs://${GSBUCKET}/sax-root \ sax-model-server:v1.1.0-mod \ --sax_cell="/sax/test" \ --port=10001 \ --platform_chip=tpuv5e \ --platform_topology='8'
Modelo 70B
Conecte-se à TPU usando SSH e inicie o servidor de modelo:
gcloud compute tpus tpu-vm ssh ${TPU_NAME} \
--project ${PROJECT_ID} \
--zone ${ZONE} \
--worker=all \
--command="
gcloud auth configure-docker \
us-docker.pkg.dev
# Pull SAX model server image
sudo docker pull us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0
# Run model server
sudo docker run \
--privileged \
-it \
-d \
--rm \
--network host \
--name "sax-model-server" \
--env SAX_ROOT=gs://${GSBUCKET}/sax-root \
us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0 \
--sax_cell="/sax/test" \
--port=10001 \
--platform_chip=tpuv5e \
--platform_topology='16'
"
Verifique os registros
Verifique os registros do servidor de modelo para garantir que ele foi iniciado corretamente:
docker logs -f sax-model-server
Se o servidor de modelo não tiver sido iniciado, consulte a seção Solução de problemas para mais informações.
Para o modelo de 70 bilhões, repita estas etapas para cada VM de TPU:
Conecte-se à TPU usando SSH:
gcloud compute tpus tpu-vm ssh ${TPU_NAME} \ --project ${PROJECT_ID} \ --zone ${ZONE} \ --worker=WORKER_NUMBER
WORKER_NUMBER é um índice baseado em 0, indicando a VM de TPU à qual você quer se conectar.
Verificar os registros:
sudo docker logs -f sax-model-serverTrês VMs de TPU precisam mostrar que se conectaram às outras instâncias:
I1117 00:16:07.196594 140613973207936 multi_host_sync.py:152] Received SPMD peer address 10.182.0.3:10001 I1117 00:16:07.197484 140613973207936 multi_host_sync.py:152] Received SPMD peer address 10.182.0.87:10001 I1117 00:16:07.199437 140613973207936 multi_host_sync.py:152] Received SPMD peer address 10.182.0.13:10001Uma das VMs da TPU precisa ter registros que mostrem o início do servidor do modelo:
I1115 04:01:29.479170 139974275995200 model_service_base.py:867] Started joining SAX cell /sax/test ERROR: logging before flag.Parse: I1115 04:01:31.479794 1 location.go:141] Calling Join due to address update ERROR: logging before flag.Parse: I1115 04:01:31.814721 1 location.go:155] Joined 10.182.0.44:10000
Publicar o modelo
O SAX vem com uma ferramenta de linha de comando chamada saxutil, que simplifica
a interação com os servidores de modelo do SAX. Neste tutorial, você vai usar
saxutil para publicar o modelo. Para conferir a lista completa de comandos saxutil, consulte
o arquivo README do Saxml
.
Mude para o diretório em que você clonou o repositório do GitHub do Saxml:
cd saxmlPara o modelo 70B, conecte-se ao seu servidor de conversão:
gcloud compute ssh ${CONV_SERVER_NAME} \ --project ${PROJECT_ID} \ --zone ${ZONE}Instale o Bazel:
sudo apt-get install bazelDefina um alias para executar
saxutilcom seu bucket do Cloud Storage:alias saxutil='bazel run saxml/bin:saxutil -- --sax_root=gs://${GSBUCKET}/sax-root'Publique o modelo usando
saxutil. Isso leva cerca de 10 minutos em uma TPU v5litepod-8.saxutil --sax_root=gs://${GSBUCKET}/sax-root publish '/sax/test/MODEL' \ saxml.server.pax.lm.params.lm_cloud.PARAMETERS \ gs://${GSBUCKET}/sax_models/llama2/SAX_LLAMA2_DIR/checkpoint_00000000/ \ 1
Substitua as seguintes variáveis:
Tamanho do modelo Valores 7B MODEL: llama27b
PARAMETERS: saxml.server.pax.lm.params.lm_cloud.LLaMA7BFP16TPUv5e
SAX_LLAMA2_DIR: saxml_llama27b
13B MODEL: llama213b
PARAMETERS: saxml.server.pax.lm.params.lm_cloud.LLaMA13BFP16TPUv5e
SAX_LLAMA2_DIR: saxml_llama213b
70 bi MODEL: lhama270b
PARAMETERS: saxml.server.pax.lm.params.lm_cloud.LLaMA70BFP16TPUv5e
SAX_LLAMA2_DIR: saxml_llama270b
Testar implantação
Para verificar se a implantação foi bem-sucedida, use o comando saxutil ls:
saxutil ls /sax/test/MODEL
Uma implantação bem-sucedida precisa ter um número de réplicas maior que zero e parecer com o seguinte:
INFO: Running command line: bazel-bin/saxml/bin/saxutil_/saxutil '--sax_rootmgs://sax-admin2/sax-root is /sax/test/1lama27b
+----------+-------------------------------------------------------+-----------------------------------------------------------------------+---------------+---------------------------+
| MODEL | MODEL PATH | CHECKPOINT PATH | # OF REPLICAS | (SELECTED) REPLICAADDRESS |
+----------+-------------------------------------------------------+-----------------------------------------------------------------------+---------------+---------------------------+
| llama27b | saxml.server.pax.lm.params.lm_cloud.LLaMA7BFP16TPUv5e | gs://${MODEL_BUCKET}/sax_models/llama2/7b/pax_7B/checkpoint_00000000/ | 1 | 10.182.0.28:10001 |
+----------+-------------------------------------------------------+-----------------------------------------------------------------------+---------------+---------------------------+
Os logs do Docker para o servidor de modelos serão semelhantes a este:
I1114 17:31:03.586631 140003787142720 model_service_base.py:532] Successfully loaded model for key: /sax/test/llama27b
INFO: Running command line: bazel-bin/saxml/bin/saxutil_/saxutil '--sax_rootmgs://sax-admin2/sax-root is /sax/test/1lama27b
Resolver problemas
Se a implantação falhar, verifique os registros do servidor de modelo:
sudo docker logs -f sax-model-server
Para uma implantação bem-sucedida, você vai ver a seguinte saída:
Successfully loaded model for key: /sax/test/llama27b
Se os registros não mostrarem que o modelo foi implantado, verifique a configuração do modelo e o caminho para o ponto de verificação do modelo.
Gerar respostas
Use a ferramenta saxutil para gerar respostas a comandos.
Gerar respostas para uma pergunta:
saxutil lm.generate -extra="temperature:0.2" /sax/test/MODEL "Q: Who is Harry Potter's mother? A:"
A saída será semelhante a esta:
INFO: Running command line: bazel-bin/saxml/bin/saxutil_/saxutil '--sax_rootmgs://sax-admin2/sax-root' lm.generate /sax/test/llama27b 'Q: Who is Harry Potter's mother? A: `
+-------------------------------+------------+
| GENERATE | SCORE |
+-------------------------------+------------+
| 1. Harry Potter's mother is | -20.214787 |
| Lily Evans. 2. Harry Potter's | |
| mother is Petunia Evans | |
| (Dursley). | |
+-------------------------------+------------+
Interagir com o modelo de um cliente
O repositório SAX inclui clientes que podem ser usados para interagir com uma célula SAX. Os clientes estão disponíveis em C++, Python e Go. O exemplo a seguir mostra como criar um cliente Python.
Crie o cliente Python:
bazel build saxml/client/python:sax.cc --compile_one_dependencyAdicione o cliente a
PYTHONPATH. Neste exemplo, supomos que você tenhasaxmlno diretório principal:export PYTHONPATH=${PYTHONPATH}:$HOME/saxml/bazel-bin/saxml/client/python/Interaja com o SAX no shell do Python:
$ python3 Python 3.10.12 (main, Jun 11 2023, 05:26:28) [GCC 11.4.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import sax >>>
Interagir com o modelo em um endpoint HTTP
Para interagir com o modelo em um endpoint HTTP, crie um cliente HTTP:
Crie uma VM do Compute Engine:
export PROJECT_ID=PROJECT_ID export ZONE=ZONE export HTTP_SERVER_NAME=HTTP_SERVER_NAME export SERVICE_ACCOUNT=SERVICE_ACCOUNT export MACHINE_TYPE=e2-standard-8 gcloud compute instances create $HTTP_SERVER_NAME --project=$PROJECT_ID --zone=$ZONE \ --machine-type=$MACHINE_TYPE \ --network-interface=network-tier=PREMIUM,stack-type=IPV4_ONLY,subnet=default \ --maintenance-policy=MIGRATE --provisioning-model=STANDARD \ --service-account=$SERVICE_ACCOUNT \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --tags=http-server,https-server \ --create-disk=auto-delete=yes,boot=yes,device-name=$HTTP_SERVER_NAME,image=projects/ml-images/global/images/c0-deeplearning-common-cpu-v20230925-debian-10,mode=rw,size=500,type=projects/$PROJECT_ID/zones/$ZONE/diskTypes/pd-balanced \ --no-shielded-secure-boot \ --shielded-vtpm \ --shielded-integrity-monitoring \ --labels=goog-ec-src=vm_add-gcloud \ --reservation-affinity=any
Conecte-se à VM do Compute Engine usando SSH:
gcloud compute ssh $HTTP_SERVER_NAME --project=$PROJECT_ID --zone=$ZONEClone a IA no repositório do GKE no GitHub:
git clone https://github.com/GoogleCloudPlatform/ai-on-gke.gitMude para o diretório do servidor HTTP:
cd ai-on-gke/tools/saxml-on-gke/httpserverCrie o arquivo Docker:
docker build -f Dockerfile -t sax-http .Execute o servidor HTTP:
docker run -e SAX_ROOT=gs://${GSBUCKET}/sax-root -p 8888:8888 -it sax-http
Teste o endpoint na máquina local ou em outro servidor com acesso à porta 8888 usando os seguintes comandos:
Exporte as variáveis de ambiente para o endereço IP e a porta do servidor:
export LB_IP=HTTP_SERVER_EXTERNAL_IP export PORT=8888
Defina o payload JSON, que contém o modelo e a consulta:
json_payload=$(cat << EOF { "model": "/sax/test/MODEL", "query": "Example query" } EOF )
Envie a solicitação:
curl --request POST --header "Content-type: application/json" -s $LB_IP:$PORT/generate --data "$json_payload"
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
Quando terminar este tutorial, siga estas etapas para limpar seu do Google Cloud.
Exclua o Cloud TPU.
$ gcloud compute tpus tpu-vm delete $TPU_NAME --zone $ZONE
Exclua a instância do Compute Engine, caso tenha criado uma.
gcloud compute instances delete INSTANCE_NAME
Exclua o bucket do Cloud Storage e o conteúdo dele.
gcloud storage rm --recursive gs://BUCKET_NAME
A seguir
- Todos os tutoriais de TPU
- Modelos de referência compatíveis
- Inferência usando a v5e
- Converter um modelo para inferência usando a v5e