監控 Cloud TPU VM
本指南說明如何使用 Google Cloud Monitoring 監控 Cloud TPU VM。 Google Cloud Monitoring 會自動從 Cloud TPU 及其主機 Compute Engine 收集指標和記錄。這些資料可用於監控 Cloud TPU 和 Compute Engine 的健康狀態。
指標可讓您追蹤一段時間內的數值,例如 CPU 使用率、網路用量或 TensorCore 閒置時間長度。記錄檔會擷取特定時間點的事件,記錄檔項目是由您自己的程式碼、 Google Cloud服務、第三方應用程式和基礎架構所寫入。 Google Cloud 您也可以建立記錄指標,從記錄項目中的資料產生指標。您也可以根據指標值或記錄項目設定快訊政策。
本指南將討論 Google Cloud 監控功能,並說明如何:
您也可以使用 Capacity Planner (預覽版) 監控 TPU。您可以使用 Capacity Planner,查看專案、資料夾或機構的 TPU 用量和預測資料。這項資料每 24 小時更新一次,可用於分析用量趨勢,並規劃未來的容量需求。詳情請參閱「Capacity Planner 總覽」。
本文假設您具備 Google CloudMonitoring 的基本知識。您必須先建立 Compute Engine VM 和 Cloud TPU 資源,才能開始生成及使用 Google Cloud Monitoring。詳情請參閱 Cloud TPU 快速入門導覽課程。
指標
Google Cloud 指標是由 Compute Engine VM 和 Cloud TPU 執行階段自動產生。Cloud TPU VM 會產生下列指標:
memory/usagenetwork/received_bytes_countnetwork/sent_bytes_countcpu/utilizationtpu/tensorcore/idle_durationaccelerator/tensorcore_utilizationaccelerator/memory_bandwidth_utilizationaccelerator/duty_cycleaccelerator/memory_totalaccelerator/memory_used
指標值產生後,最多可能需要 180 秒才會顯示在指標探索器中。
如需 Cloud TPU 產生的指標完整清單,請參閱 Google Cloud Cloud TPU 指標。
記憶體用量
系統會為 TPU Worker 資源產生 memory/usage 指標,並追蹤 TPU VM 使用的記憶體 (以位元組為單位)。系統每 60 秒就會對這項指標進行一次取樣。
網路接收的位元組數
系統會為 TPU Worker 資源產生 network/received_bytes_count 指標,並追蹤 TPU VM 在特定時間點透過網路接收的累計資料位元組數。
傳送的網路位元組數
系統會為 TPU Worker 資源產生 network/sent_bytes_count 指標,並追蹤 TPU VM 在特定時間點透過網路傳送的累計位元組數。
CPU 使用率
系統會為 TPU Worker 資源產生 cpu/utilization 指標,並追蹤 TPU 工作站目前的 CPU 使用情形 (以百分比表示),每分鐘取樣一次。值通常介於 0.0 至 100.0 之間,但可能超過 100.0。
TensorCore 閒置時間長度
系統會為 TPU Worker 資源產生 tpu/tensorcore/idle_duration 指標,並追蹤每個 TPU 晶片的 TensorCore 閒置秒數。這項指標適用於所有使用中 TPU 的每個晶片。如果使用 TensorCore,閒置時間值會重設為零。TensorCore 不再使用時,閒置時間值就會開始增加。
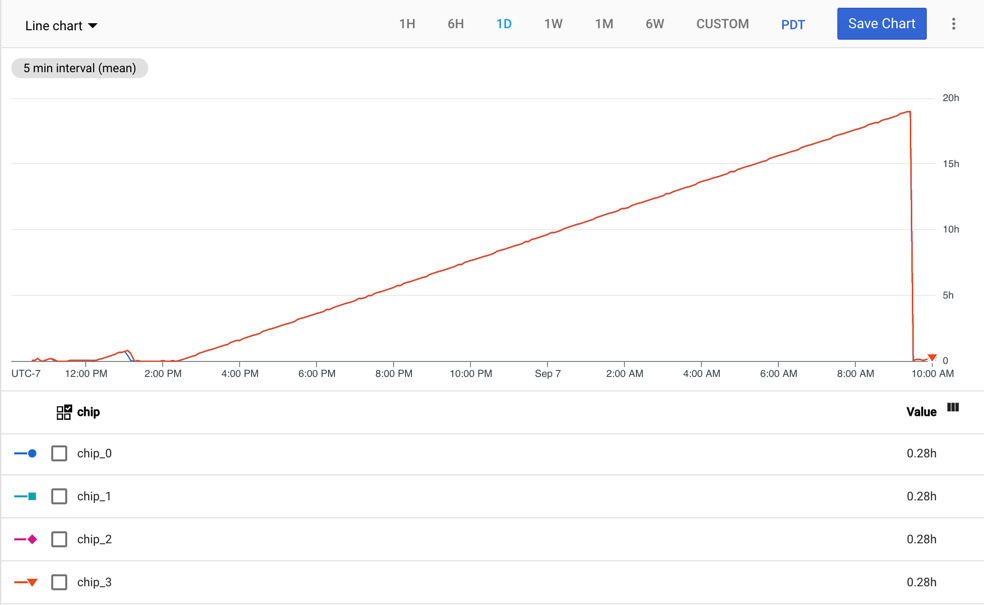
下圖顯示 v2-8 TPU VM 的 tpu/tensorcore/idle_duration 指標,該 VM 有一個工作站。每個工作人員有四個晶片。在本例中,四個晶片都有相同的 tpu/tensorcore/idle_duration 值,因此圖表會彼此重疊。
TensorCore 使用率
系統會為 GCE TPU
Worker 資源產生 accelerator/tensorcore_utilization 指標,並追蹤目前 TensorCore 的用量百分比。這項指標的計算方式是將取樣期間內執行的 TensorCore 作業數量,除以相同取樣期間內可執行的作業數量上限。值越大代表使用率越高。TensorCore 使用率指標支援第 4 代和更新的 TPU。
記憶體頻寬使用率
系統會為 GCE TPU Worker 資源產生 accelerator/memory_bandwidth_utilization 指標,並追蹤目前使用的加速器記憶體頻寬百分比。這項指標的計算方式為:將取樣期間內使用的記憶體頻寬,除以相同期間內支援的最大頻寬。值越大代表使用率越高。v4 以上的 TPU 世代支援「記憶體頻寬使用率」指標。
加速器任務週期
系統會為 GCE TPU Worker
資源產生 accelerator/duty_cycle 指標,並追蹤取樣期間內,加速器 TensorCore 積極處理作業的時間百分比。值介於 0 到 100 之間。值越大表示 TensorCore 使用率越高。在 TPU VM 上執行機器學習工作負載時,系統會回報這項指標。加速器工作週期指標支援 JAX 0.4.14 以上版本、PyTorch 2.1 以上版本,以及
TensorFlow 2.14.0 以上版本。
加速器記憶體總量
accelerator/memory_total 指標是為 GCE TPU Worker 資源產生,並追蹤以位元組為單位的加速器記憶體總量。在 TPU VM 上執行機器學習工作負載時,系統會回報這項指標。「加速器記憶體總計」指標支援 JAX 0.4.14 以上版本、PyTorch 2.1 以上版本,以及
TensorFlow 2.14.0 以上版本。
已使用的加速器記憶體
系統會為 GCE TPU Worker 資源產生 accelerator/memory_used 指標,並追蹤以位元組為單位的加速器記憶體總用量。在 TPU VM 上執行機器學習工作負載時,系統會回報這項指標。「使用的加速器記憶體」指標支援 JAX 0.4.14 以上版本、PyTorch 2.1 以上版本,以及
TensorFlow 2.14.0 以上版本。
查看指標
您可以在 Google Cloud 控制台使用指標探索工具查看指標。
在指標探索工具中,按一下「選取指標」,然後搜尋 TPU Worker 或 GCE TPU Worker,視您感興趣的指標而定。
選取資源,即可顯示該資源的所有可用指標。
如果啟用「使用中」,系統只會列出含有過去 25 小時內時間序列資料的指標。停用「Active」即可列出所有指標。
建立快訊
您可以建立快訊政策,指示 Cloud Monitoring 在符合條件時傳送快訊。
本節的步驟會舉例說明如何為 TensorCore Idle Duration 指標新增快訊政策。每當這項指標超過 24 小時,Cloud Monitoring 就會傳送電子郵件到註冊的電子郵件地址。
- 前往 Monitoring 主控台。
- 在導覽窗格中,按一下「快訊」。
- 按一下「編輯通知管道」。
- 在「電子郵件」下方,按一下「新增」。輸入電子郵件地址和顯示名稱,然後按一下「儲存」。
- 在「快訊」頁面,按一下「建立政策」。
- 按一下「選取指標」,然後選取「Tensorcore 空閒時間長度」,並按一下「套用」。
- 依序點選「下一步」和「門檻」。
- 針對「Alert trigger」(快訊觸發條件),選取「Any time series violates」(任何時間序列違反條件時)。
- 在「Threshold position」(門檻位置) 中選取「Above threshold」(高於門檻)。
- 在「Threshold value」(門檻值) 中,輸入
86400000。 - 點選「下一步」。
- 在「通知管道」下方,選取電子郵件通知管道,然後按一下「確定」。
- 輸入快訊政策名稱。
- 依序點選「下一步」和「建立政策」。
如果 TensorCore 閒置時間超過 24 小時,系統會傳送電子郵件至您指定的電子郵件地址。
記錄
記錄項目是由 Google Cloud 服務、第三方服務、ML 架構或您的程式碼寫入。您可以使用記錄探索工具或記錄 API 查看記錄。如要進一步瞭解 Google Cloud 記錄,請參閱「 Google Cloud 記錄」。
TPU 工作站記錄包含特定區域中特定 Cloud TPU 工作站的相關資訊,例如 Cloud TPU 工作站可用的記憶體量 (system_available_memory_GiB)。
稽核資源記錄包含特定 Cloud TPU API 的呼叫時間和呼叫者資訊。舉例來說,您可以找到對 CreateNode、UpdateNode 和 DeleteNode API 的呼叫相關資訊。
機器學習架構可以產生標準輸出和標準錯誤的記錄檔。這些記錄由環境變數控管,並由訓練指令碼讀取。
您的程式碼可以將記錄檔寫入 Google Cloud Logging。詳情請參閱「寫入標準記錄」和「寫入結構化記錄」。
序列埠記錄
Cloud TPU 會使用序列埠記錄進行疑難排解、監控和偵錯。預設為啟用序列埠記錄功能。 如果未啟用序列埠記錄功能,TPU VM 建立程序就會失敗,並產生下列錯誤訊息。
"Cloud TPU received a bad request. Constraint
`constraints/compute.disableSerialPortLogging` violated. Create TPUs with
serial port logging enabled or remove the Organization Policy Constraint."
這則訊息表示違反了限制條件 constraints/compute.disableSerialPortLogging。如要避免發生這項錯誤,請確保 TPU 專案允許序列埠記錄功能。最佳做法是在專案層級覆寫機構政策。
如要進一步瞭解如何啟用序列埠記錄功能,請參閱「啟用及停用序列埠輸出記錄功能」。
查詢 Google Cloud 記錄
在 Google Cloud 控制台查看記錄時,頁面會執行預設查詢。
選取 Show query 切換開關即可查看查詢。您可以修改預設查詢或建立新的查詢。詳情請參閱「在記錄檔探索工具中建構查詢」。
已稽核的資源記錄
如要查看「已稽核的資源」記錄,請按照下列步驟操作:
- 前往 Google Cloud 記錄檔探索工具。
- 按一下「所有資源」下拉式選單。
- 依序點選「Audited Resource」和「Cloud TPU」。
- 選擇您感興趣的 Cloud TPU API。
- 按一下 [套用]。查詢結果會顯示記錄。
按一下任一記錄項目即可展開。每個記錄項目都有多個欄位,包括:
- logName:記錄名稱
- protoPayload -> @type:記錄類型
- protoPayload -> resourceName:Cloud TPU 的名稱
- protoPayload -> methodName:呼叫的方法名稱 (僅限稽核記錄)
- protoPayload -> request -> @type:要求類型
- protoPayload -> request -> node:Cloud TPU 節點的詳細資料
- protoPayload -> request -> node_id:TPU 的名稱
- severity:記錄的嚴重性
TPU 工作站記錄
如要查看 TPU 工作站記錄,請按照下列步驟操作:
- 前往 Google Cloud 記錄檔探索工具。
- 按一下「所有資源」下拉式選單。
- 按一下「TPU 工作站」。
- 選取區域。
- 選取您感興趣的 Cloud TPU。
- 按一下 [套用]。查詢結果會顯示記錄。
按一下任一記錄項目即可展開。每個記錄項目都有名為 jsonPayload 的欄位。展開 jsonPayload 即可查看多個欄位,包括:
- accelerator_type:加速器類型
- consumer_project:Cloud TPU 所在的專案
- evententry_timestamp:產生記錄的時間
- system_available_memory_GiB:Cloud TPU 工作站的可用記憶體 (0 ~ 350 GiB)
建立記錄指標
本節說明如何建立記錄指標,用於設定監控資訊主頁和快訊。如要瞭解如何以程式輔助方式建立記錄指標,請參閱「使用 Cloud Logging REST API 以程式輔助方式建立記錄指標」。
下列範例使用 system_available_memory_GiB 子欄位,說明如何建立記錄檔式指標,監控 Cloud TPU 工作站可用的記憶體。
- 前往 Google Cloud 記錄檔探索工具。
在查詢方塊中輸入下列查詢,擷取所有為主要 Cloud TPU 工作站定義 system_available_memory_GiB 的記錄項目:
resource.type=tpu_worker resource.labels.project_id=your-project resource.labels.zone=your-tpu-zone resource.labels.node_id=your-tpu-name resource.labels.worker_id=0 logName=projects/your-project/logs/tpu.googleapis.com%2Fruntime_monitor jsonPayload.system_available_memory_GiB:*
按一下「建立指標」,顯示「指標編輯器」。
在「指標類型」下方,選擇「分布」。
輸入指標的名稱、說明 (選填) 和測量單位。 以本例來說,請分別在「名稱」和「說明」欄位中輸入「matrix_unit_utilization_percent」和「MXU utilization」。篩選器會預先填入您在記錄檔探索工具中輸入的指令碼。
點選「建立指標」。
按一下「在 Metrics Explorer 中查看」,即可查看新指標。指標可能需要幾分鐘才會顯示。
使用 Cloud Logging REST API 建立記錄指標
您也可以透過 Cloud Logging API 建立記錄指標。 詳情請參閱建立分佈指標。
使用記錄指標建立資訊主頁和快訊
資訊主頁可協助您以視覺化方式呈現指標 (約有 2 分鐘的延遲);發生錯誤時,快訊則可發送通知。詳情請參閱:
建立資訊主頁
如要在 Cloud Monitoring 中建立 Tensorcore 閒置時間指標的資訊主頁,請按照下列步驟操作:
- 前往 Monitoring 主控台。
- 在導覽窗格中,按一下「資訊主頁」。
- 依序點選「建立資訊主頁」和「新增小工具」。
- 選擇要新增的圖表類型。在本範例中,請選擇「線條」。
- 輸入小工具的標題。
- 按一下「選取指標」下拉式選單,然後在篩選器欄位中輸入「Tensorcore idle duration」。
- 在指標清單中,依序選取「TPU Worker」->「Tpu」->「Tensorcore idle duration」。
- 如要篩選資訊主頁內容,請按一下「篩選器」下拉式選單。
- 在「資源標籤」下方,選取「project_id」。
- 選擇比較器,並在「值」欄位中輸入值。
- 按一下「套用」。