Arsitektur TPU
Tensor Processing Unit (TPU) adalah sirkuit terintegrasi khusus aplikasi (ASIC) yang dirancang oleh Google untuk mempercepat workload machine learning. Cloud TPU adalah Google Cloud layanan yang menyediakan TPU sebagai resource yang dapat diskalakan.
TPU dirancang untuk melakukan operasi matriks dengan cepat sehingga ideal untuk beban kerja machine learning. Anda dapat menjalankan beban kerja machine learning di TPU menggunakan framework seperti Pytorch dan JAX.
Bagaimana cara kerja TPU?
Untuk memahami cara kerja TPU, Anda perlu memahami cara akselerator lain mengatasi tantangan komputasi dalam melatih model ML.
Cara kerja CPU
CPU adalah prosesor tujuan umum berdasarkan arsitektur von Neumann. Artinya, CPU bekerja dengan software dan memori seperti ini:

Manfaat terbesar CPU adalah fleksibilitasnya. Anda dapat memuat semua jenis software di CPU untuk berbagai jenis aplikasi. Misalnya, Anda dapat menggunakan CPU untuk pemrosesan kata di PC, mengontrol mesin roket, mengeksekusi transaksi bank, atau mengklasifikasikan gambar dengan jaringan saraf tiruan.
CPU memuat nilai dari memori, melakukan perhitungan pada nilai, dan menyimpan hasilnya kembali ke memori untuk setiap perhitungan. Akses memori lambat jika dibandingkan dengan kecepatan penghitungan dan dapat membatasi total throughput CPU. Hal ini sering disebut sebagai hambatan von Neumann.
Cara kerja GPU
Untuk mendapatkan throughput yang lebih tinggi, GPU berisi ribuan Unit Logika Aritmatika (ALU) dalam satu prosesor. GPU modern biasanya berisi antara 2.500–5.000 ALU. Banyaknya prosesor berarti Anda dapat menjalankan ribuan perkalian dan penjumlahan secara bersamaan.

Arsitektur GPU ini berfungsi dengan baik pada aplikasi dengan paralelisme besar, seperti operasi matriks dalam jaringan neural. Faktanya, pada beban kerja pelatihan umum untuk deep learning, GPU dapat memberikan throughput yang lebih tinggi daripada CPU.
Namun, GPU tetap merupakan prosesor serbaguna yang harus mendukung banyak aplikasi dan software yang berbeda. Oleh karena itu, GPU memiliki masalah yang sama dengan CPU. Untuk setiap perhitungan dalam ribuan ALU, GPU harus mengakses register atau memori bersama untuk membaca operand dan menyimpan hasil perhitungan sementara.
Cara kerja TPU
Google mendesain Cloud TPU sebagai prosesor matriks yang dikhususkan untuk beban kerja jaringan neural. TPU tidak dapat menjalankan pemroses kata, mengontrol mesin roket, atau mengeksekusi transaksi bank, tetapi dapat menangani operasi matriks besar yang digunakan dalam jaringan neural dengan kecepatan tinggi.
Tugas utama untuk TPU adalah pemrosesan matriks, yang merupakan kombinasi operasi perkalian dan akumulasi. TPU berisi ribuan multiply-accumulator yang terhubung langsung satu sama lain untuk membentuk matriks fisik yang besar. Hal ini disebut arsitektur systolic array. Cloud TPU v3 berisi dua array sistolik dari 128 x 128 ALU, pada satu prosesor.
Host TPU melakukan streaming data ke dalam antrean infeed. TPU memuat data dari antrean feed dan menyimpannya dalam memori HBM. Setelah komputasi selesai, TPU akan memuat hasil ke dalam antrean outfeed. Host TPU kemudian membaca hasil dari antrean outfeed dan menyimpannya dalam memori host.
Untuk melakukan operasi matriks, TPU memuat parameter dari memori HBM ke dalam Unit Perkalian Matriks (MXU).

Kemudian, TPU memuat data dari memori HBM. Saat setiap perkalian dijalankan, hasilnya diteruskan ke multiply-accumulator berikutnya. Outputnya adalah penjumlahan semua hasil perkalian antara data dan parameter. Tidak ada akses memori yang diperlukan selama proses perkalian matriks.

Oleh karena itu, TPU dapat mencapai throughput komputasi yang tinggi pada perhitungan jaringan neural.
Arsitektur sistem TPU
Bagian berikut menjelaskan konsep utama sistem TPU. Untuk mengetahui informasi selengkapnya tentang istilah machine learning umum, lihat Glosarium Machine Learning.
Jika Anda baru menggunakan Cloud TPU, lihat halaman beranda dokumentasi TPU.
Chip TPU
Chip TPU berisi satu atau beberapa TensorCore. Jumlah TensorCore bergantung pada versi chip TPU. Setiap TensorCore terdiri dari satu atau beberapa unit perkalian matriks (MXU), unit vektor, dan unit skalar. Untuk mengetahui informasi selengkapnya tentang TensorCore, lihat Superkomputer Khusus Domain untuk Melatih Jaringan Neural Dalam.
MXU terdiri dari multiply-accumulator 256 x 256 (TPU v6e) atau 128 x 128 (TPU versi sebelum v6e) dalam array sistolik. MXU menyediakan sebagian besar daya komputasi di TensorCore. Setiap MXU mampu melakukan 16.000 operasi multiply-accumulate per siklus. Semua operasi perkalian menggunakan input bfloat16, tetapi semua akumulasi dilakukan dalam format angka FP32.
Unit vektor digunakan untuk komputasi umum seperti aktivasi dan softmax. Unit skalar digunakan untuk alur kontrol, menghitung alamat memori, dan operasi pemeliharaan lainnya.
Pod TPU
Pod TPU adalah sekumpulan TPU yang berdekatan dan dikelompokkan bersama melalui jaringan khusus. Jumlah TPU chip dalam Pod TPU bergantung pada versi TPU.
Slice
Slice adalah kumpulan chip yang semuanya berada di dalam Pod TPU yang sama dan terhubung oleh interkoneksi antar-chip (ICI) berkecepatan tinggi. Slice dijelaskan dalam bentuk chip atau TensorCore, bergantung pada versi TPU.
Bentuk chip dan topologi chip juga merujuk pada bentuk irisan.
Multislice versus slice tunggal
Multislice adalah grup slice, yang memperluas konektivitas TPU di luar koneksi interkoneksi antar-chip (ICI) dan memanfaatkan jaringan pusat data (DCN) untuk mengirimkan data di luar slice. Data dalam setiap irisan masih ditransmisikan oleh ICI. Dengan konektivitas hibrida ini, Multislice memungkinkan paralelisme di seluruh slice dan memungkinkan Anda menggunakan lebih banyak core TPU untuk satu tugas daripada yang dapat ditampung oleh satu slice.
TPU dapat digunakan untuk menjalankan tugas pada satu slice atau beberapa slice. Lihat Pengantar multirisir untuk mengetahui detail selengkapnya.
Kubus TPU
Topologi 4x4x4 dari chip TPU yang saling terhubung. Hal ini hanya berlaku untuk topologi 3D (dimulai dengan TPU v4).
SparseCore
SparseCore adalah pemroses dataflow yang mempercepat model menggunakan operasi sparse. Kasus penggunaan utamanya adalah mempercepat model rekomendasi, yang sangat mengandalkan embedding. v5p mencakup empat SparseCore per chip, dan v6e mencakup dua SparseCore per chip. Untuk penjelasan mendalam tentang cara penggunaan SparseCores, lihat Penjelasan mendalam tentang SparseCore untuk Model Embedding Besar (LEM). Anda mengontrol cara compiler XLA menggunakan SparseCores menggunakan flag XLA. Untuk mengetahui informasi selengkapnya, lihat: Flag XLA TPU.
Ketahanan ICI Cloud TPU
Ketahanan ICI membantu meningkatkan fault tolerance link optik dan switch sirkuit optik (OCS) yang menghubungkan TPU antar-kubus. (Koneksi ICI dalam kubus menggunakan link tembaga yang tidak terpengaruh). Ketahanan ICI memungkinkan koneksi ICI dirutekan di sekitar OCS dan kesalahan ICI optik. Akibatnya, ketersediaan penjadwalan slice TPU meningkat, dengan penurunan sementara performa ICI sebagai imbasnya.
Untuk Cloud TPU v4 dan v5p, ketahanan ICI diaktifkan secara default untuk slice yang berukuran satu kubus atau lebih besar, misalnya:
- v5p-128 saat menentukan jenis akselerator
- 4x4x4 saat menentukan konfigurasi akselerator
Versi TPU
Arsitektur yang tepat dari chip TPU bergantung pada versi TPU yang Anda gunakan. Setiap versi TPU juga mendukung ukuran dan konfigurasi slice yang berbeda. Untuk mengetahui informasi selengkapnya tentang arsitektur sistem dan konfigurasi yang didukung, lihat halaman berikut:
Arsitektur cloud TPU
Google Cloud membuat TPU tersedia sebagai resource komputasi melalui VM TPU. Anda dapat menggunakan VM TPU secara langsung untuk workload atau menggunakannya melalui Google Kubernetes Engine atau Vertex AI. Bagian berikut menjelaskan komponen utama arsitektur cloud TPU.
Arsitektur VM TPU
Arsitektur VM TPU memungkinkan Anda terhubung langsung ke VM yang terhubung secara fisik ke perangkat TPU menggunakan SSH. VM TPU, yang juga dikenal sebagai pekerja, adalah mesin virtual yang menjalankan Linux dan memiliki akses ke TPU yang mendasarinya. Anda memiliki akses root ke VM, sehingga Anda dapat menjalankan kode arbitrer. Anda dapat mengakses log debug dan pesan error compiler dan runtime.

Host tunggal, multi-host, dan sub-host
Host TPU adalah VM yang berjalan di komputer fisik yang terhubung ke hardware TPU. Workload TPU dapat menggunakan satu atau beberapa host.
Workload host tunggal dibatasi untuk satu VM TPU. Workload multi-host mendistribusikan pelatihan di beberapa VM TPU. Workload sub-host tidak menggunakan semua chip di VM TPU.
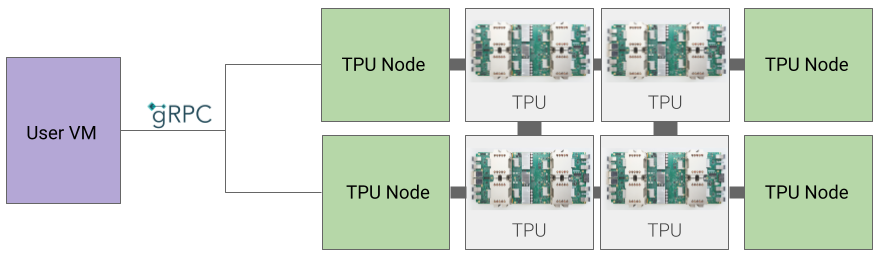
Arsitektur TPU Node (tidak digunakan lagi)
Arsitektur TPU Node terdiri dari VM pengguna yang berkomunikasi dengan host TPU melalui gRPC. Saat menggunakan arsitektur ini, Anda tidak dapat langsung mengakses Host TPU, sehingga sulit untuk men-debug pelatihan dan error TPU.
Beralih dari arsitektur TPU Node ke TPU VM
Jika Anda memiliki TPU yang menggunakan arsitektur TPU Node, gunakan langkah-langkah berikut untuk mengidentifikasi, menghapus, dan menyediakan ulang TPU tersebut sebagai VM TPU.
Buka halaman TPU:
Temukan TPU dan arsitekturnya di bagian judul Arsitektur. Jika arsitekturnya adalah "TPU VM", Anda tidak perlu melakukan tindakan apa pun. Jika arsitekturnya adalah "TPU Node", Anda harus menghapus dan menyediakan ulang TPU.
Hapus dan sediakan ulang TPU.
Lihat Mengelola TPU untuk mendapatkan petunjuk tentang cara menghapus dan membuat ulang TPU.