TPU v6e
Dokumen ini menjelaskan arsitektur dan konfigurasi yang didukung oleh Cloud TPU v6e (Trillium).
Trillium adalah akselerator AI generasi terbaru Cloud TPU. Di semua platform teknis, seperti API dan log, serta di seluruh dokumen ini, Trillium akan disebut sebagai v6e.
Dengan footprint 256 chip per Pod, v6e memiliki banyak kesamaan dengan v5e. Sistem ini dioptimalkan untuk menjadi produk bernilai tertinggi untuk pelatihan, penyesuaian, dan penayangan transformer, text-to-image, dan jaringan neural konvolusional (CNN).
Arsitektur sistem
Setiap chip v6e berisi satu TensorCore. Setiap TensorCore memiliki 2 unit perkalian matriks (MXU), unit vektor, dan unit skalar. Tabel berikut menampilkan spesifikasi utama dan nilainya untuk TPU v6e dibandingkan dengan TPU v5e.
| Spesifikasi | v5e | v6e |
|---|---|---|
| Performa/total biaya kepemilikan (TCO) (diharapkan) | 0,65x | 1 |
| Komputasi puncak per chip (bf16) | 197 TFLOP | 918 TFLOP |
| Komputasi puncak per chip (Int8) | 393 TOPS | 1836 TOPS |
| Kapasitas HBM per chip | 16 GB | 32 GB |
| Bandwidth HBM per chip | 800 GBps | 1.600 GBps |
| Bandwidth interkoneksi antar-chip (ICI) | 1.600 Gbps | 3200 Gbps |
| Port ICI per chip | 4 | 4 |
| DRAM per host | 512 GiB | 1536 GiB |
| Chip per host | 8 | 8 |
| Ukuran Pod TPU | 256 chip | 256 chip |
| Topologi Interconnect | Torus 2D | Torus 2D |
| Komputasi puncak BF16 per Pod | 50,63 PFLOP | 234,9 PFLOP |
| Bandwidth all-reduce per Pod | 51,2 TB/dtk | 102,4 TB/dtk |
| Bandwidth biseksi per Pod | 1,6 TB/dtk | 3,2 TB/dtk |
| Konfigurasi NIC per host | NIC 2 x 100 Gbps | NIC 4 x 200 Gbps |
| Bandwidth jaringan pusat data per Pod | 6,4 Tbps | 25,6 Tbps |
| Fitur khusus | - | SparseCore |
Konfigurasi yang didukung
Tabel berikut menunjukkan bentuk irisan 2D yang didukung untuk v6e:
| Topologi | Chip TPU | Host | VM | Jenis akselerator (TPU API) | Jenis mesin (GKE API) | Cakupan |
|---|---|---|---|---|---|---|
| 1x1 | 1 | 1/8 | 1 | v6e-1 |
ct6e-standard-1t |
Sub-host |
| 2x2 | 4 | 1/2 | 1 | v6e-4 |
ct6e-standard-4t |
Sub-host |
| 2x4 | 8 | 1 | 1 | v6e-8 |
ct6e-standard-8t |
Host tunggal |
| 2x4 | 8 | 1 | 2 | - | ct6e-standard-4t |
Host tunggal |
| 4x4 | 16 | 2 | 4 | v6e-16 |
ct6e-standard-4t |
Multi-host |
| 4x8 | 32 | 4 | 8 | v6e-32 |
ct6e-standard-4t |
Multi-host |
| 8x8 | 64 | 8 | 16 | v6e-64 |
ct6e-standard-4t |
Multi-host |
| 8x16 | 128 | 16 | 32 | v6e-128 |
ct6e-standard-4t |
Multi-host |
| 16x16 | 256 | 32 | 64 | v6e-256 |
ct6e-standard-4t |
Multi-host |
Slice dengan 8 chip (v6e-8) yang terpasang ke satu VM dioptimalkan untuk inferensi, sehingga memungkinkan semua 8 chip digunakan dalam satu workload penayangan. Anda dapat
melakukan inferensi multi-host menggunakan Pathways di Cloud. Untuk mengetahui informasi selengkapnya, lihat
Melakukan inferensi multihost menggunakan Pathways.
Untuk mengetahui informasi tentang jumlah VM untuk setiap topologi, lihat Jenis VM.
Jenis VM
Setiap VM v6e TPU dapat berisi 1, 4, atau 8 chip. Slice 4 chip dan yang lebih kecil memiliki node akses memori non-seragam (NUMA) yang sama. Untuk mengetahui informasi selengkapnya tentang node NUMA, lihat Akses memori non-seragam di Wikipedia.
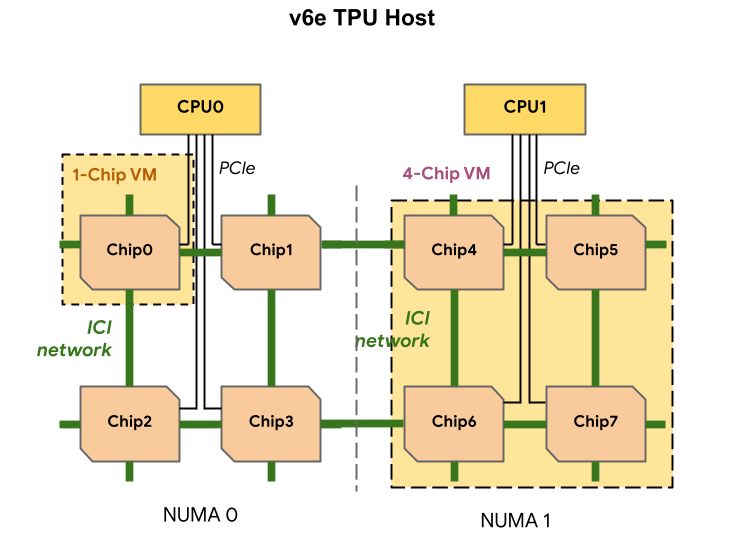
Slice v6e dibuat menggunakan VM setengah host, yang masing-masing memiliki 4 chip TPU. Ada dua pengecualian untuk aturan ini:
v6e-1: VM dengan hanya satu chip, yang terutama ditujukan untuk pengujianv6e-8: VM host penuh yang telah dioptimalkan untuk kasus penggunaan inferensi dengan semua 8 chip terpasang ke satu VM.
Tabel berikut menunjukkan perbandingan jenis VM TPU v6e:
| Jenis VM | Jumlah vCPU per VM | RAM (GB) per VM | Jumlah node NUMA per VM |
|---|---|---|---|
| VM 1 chip | 44 | 176 | 1 |
| VM 4 chip | 180 | 720 | 1 |
| VM 8 chip | 180 | 1440 | 2 |
Menentukan konfigurasi v6e
Saat mengalokasikan slice TPU v6e menggunakan TPU API, Anda menentukan ukuran dan
bentuknya menggunakan parameter AcceleratorType.
Jika Anda menggunakan GKE, gunakan flag --machine-type untuk menentukan
jenis mesin yang mendukung TPU yang ingin Anda gunakan. Untuk mengetahui informasi selengkapnya, lihat
Merencanakan TPU di GKE dalam dokumentasi GKE.
Gunakan AcceleratorType
Saat mengalokasikan resource TPU, Anda menggunakan AcceleratorType untuk menentukan jumlah
TensorCore dalam slice. Nilai yang Anda tentukan untuk
AcceleratorType adalah string dengan format: v$VERSION-$TENSORCORE_COUNT.
Misalnya, v6e-8 menentukan slice TPU v6e dengan 8 TensorCore.
Contoh berikut menunjukkan cara membuat slice TPU v6e dengan 32 TensorCore menggunakan AcceleratorType:
gcloud
$ gcloud compute tpus tpu-vm create tpu-name \ --zone=zone \ --accelerator-type=v6e-32 \ --version=v2-alpha-tpuv6e
Konsol
Di konsol Google Cloud , buka halaman TPU:
Klik Buat TPU.
Di kolom Name, masukkan nama untuk TPU Anda.
Di kotak Zone, pilih zona tempat Anda ingin membuat TPU.
Di kotak TPU type, pilih
v6e-32.Di kotak TPU software version, pilih
v2-alpha-tpuv6e. Saat membuat VM Cloud TPU, versi software TPU menentukan versi runtime TPU yang akan diinstal. Untuk mengetahui informasi selengkapnya, lihat Image VM TPU.Klik tombol Aktifkan antrean.
Di kolom Queued resource name, masukkan nama untuk permintaan resource yang diantrekan.
Klik Buat.
Langkah berikutnya
- Menjalankan pelatihan dan inferensi menggunakan TPU v6e