Arquitetura da TPU
As unidades de processamento de tensor (TPUs) são circuitos integrados de aplicação específica (ASICs) projetados pelo Google para acelerar as cargas de trabalho de machine learning. O Cloud TPU é um serviço Google Cloud que disponibiliza TPUs como um recurso escalonável.
As TPUs foram projetadas para realizar operações de matriz rapidamente, o que as torna ideais para cargas de trabalho de machine learning. É possível executar cargas de trabalho de machine learning em TPUs usando frameworks como Pytorch e JAX.
Como as TPUs funcionam?
Para entender como as TPUs funcionam, vale a pena entender como outros aceleradores lidam com os desafios computacionais do treinamento de modelos de ML.
Como funciona uma CPU
Uma CPU é um processador de uso geral baseado na arquitetura de von Neumann. Isso significa que uma CPU trabalha com software e memória, assim:
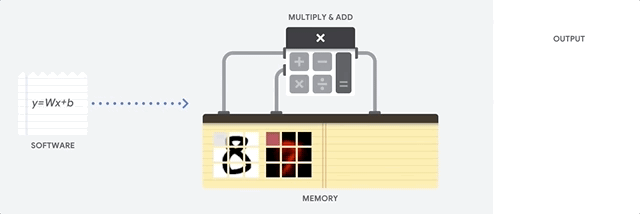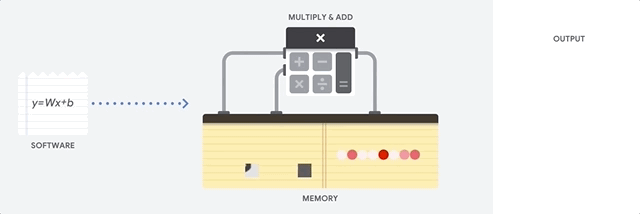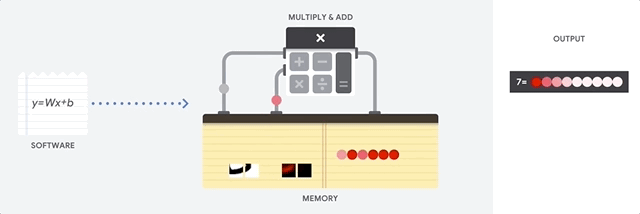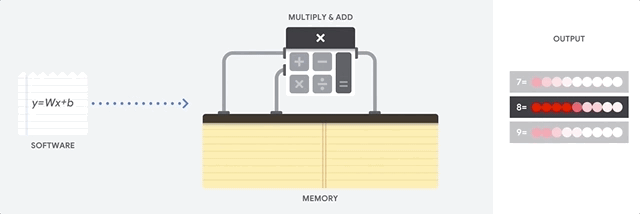
O maior benefício das CPUs é a flexibilidade. É possível carregar qualquer tipo de software em uma CPU para vários tipos diferentes de aplicativos. Por exemplo, é possível usar uma CPU para processar texto em um PC, controlar mecanismos de foguetes, executar transações bancárias ou classificar imagens com uma rede neural.
Uma CPU carrega valores da memória, realiza um cálculo com base nos valores e armazena o resultado de cada cálculo na memória. O acesso à memória é lento quando comparado à velocidade do cálculo, o que limita a capacidade total das CPUs. Isso geralmente é chamado de gargalo de von Neumann.
Como funciona uma GPU
Para aumentar a capacidade de processamento, as GPUs contêm milhares de unidades lógicas aritméticas (ALUs, na sigla em inglês) em um único processador. Uma GPU moderna geralmente contém entre 2.500 e 5.000 ALUs. O grande número de processadores significa que é possível executar milhares de multiplicações e adições simultaneamente.

Essa arquitetura de GPU funciona bem em aplicativos com enorme paralelismo, como a operação de matrizes em uma rede neural. Na verdade, em uma carga de trabalho de treinamento típica para aprendizado profundo, uma GPU fornece uma ordem de grandeza maior do que uma CPU.
No entanto, a GPU ainda é um processador de uso geral que precisa ser compatível com vários aplicativos e softwares diferentes. Portanto, as GPUs têm o mesmo problema que as CPUs. Para cada cálculo nas milhares de ALUs, uma GPU precisa acessar registros ou memória compartilhada para ler e armazenar os resultados de cálculos intermediários.
Como funciona uma TPU
O Google projetou as Cloud TPUs como um processador de matriz especializado em cargas de trabalho de redes neurais. As TPUs não podem executar processadores de texto, controlar mecanismos de foguetes ou executar transações bancárias, mas podem processar operações de matriz em massa usadas em redes neurais em velocidades rápidas.
A principal tarefa das TPUs é o processamento de matrizes, que é uma combinação de operações de multiplicação e acumulação. As TPUs contêm milhares de acumuladores de multiplicação que estão diretamente conectados entre si para formar uma matriz física grande. Isso é chamado de arquitetura de matriz sistólica. O Cloud TPU v3 contém duas matrizes sistólicas de ALUs de 128 x 128 em um único processador.
O host da TPU transmite os dados para uma fila de entrada. A TPU carrega dados da fila de alimentação e os armazena na memória HBM. Quando a computação é concluída, a TPU carrega os resultados na fila de saída. Em seguida, o host da TPU lê os resultados da fila de saída e os armazena na memória do host.
Para executar as operações da matriz, a TPU carrega os parâmetros da memória HBM na unidade de multiplicação de matrizes (MXU).

Em seguida, ela carrega dados da memória HBM. Conforme cada multiplicação é executada, o resultado é transmitido para o próximo acumulador de multiplicação. A saída é a soma de todos os resultados de multiplicação entre os dados e os parâmetros. Não é necessário acessar a memória durante o processo de multiplicação de matrizes.
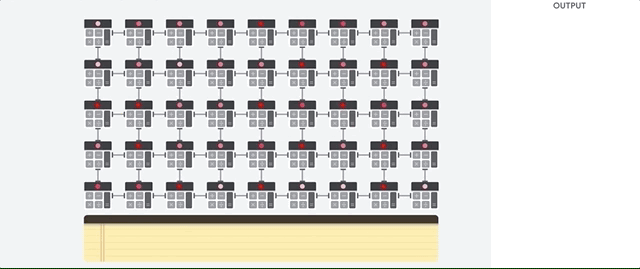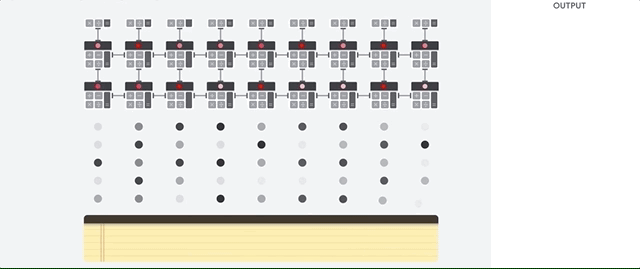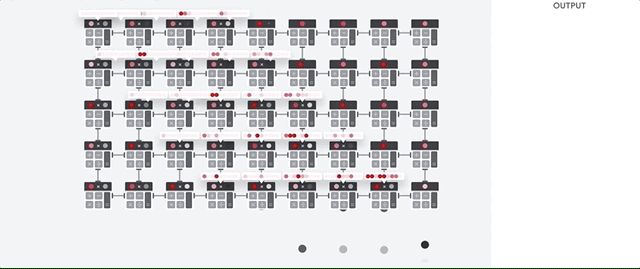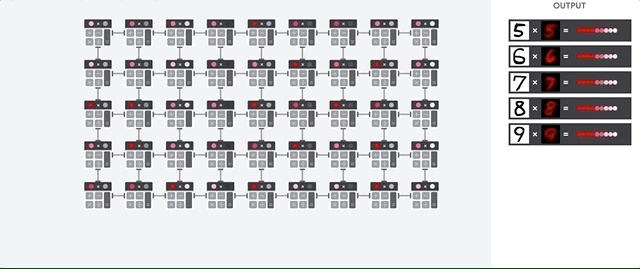
Como resultado, as TPUs podem alcançar uma alta capacidade computacional em cálculos de redes neurais.
Arquitetura do sistema de TPU
As seções a seguir descrevem os principais conceitos de um sistema de TPU. Para mais informações sobre termos comuns de machine learning, consulte o Glossário de machine learning.
Se você não tem experiência com o Cloud TPU, confira a página inicial da documentação da TPU.
Chip de TPU
Um chip de TPU contém um ou mais TensorCores. O número de TensorCores depende da versão do chip de TPU. Cada TensorCore consiste em uma ou mais unidades de multiplicação de matriz (MXUs), uma unidade vetorial e uma unidade escalar. Para mais informações sobre os TensorCores, consulte Um supercomputador específico de domínio para treinamento de redes neurais profundas.
Uma MXU é composta de multiplicadores-acumuladores de 256 x 256 (TPU v6e) ou 128 x 128 (versões da TPU anteriores à v6e) em uma matriz sistólica. As MXUs fornecem a maior parte da capacidade de computação em um TensorCore. Cada MXU é capaz de realizar 16 mil operações de multiplicação seguida de acumulação por ciclo. Todas as multiplicações usam entradas bfloat16, mas todos os acúmulos são realizados no formato de número FP32.
A unidade vetorial é usada para computação geral, como ativações e softmax. A unidade escalar é usada para controlar o fluxo, calcular endereços de memória e outras operações de manutenção.
Pod de TPU
Um pod de TPU é um conjunto contíguo de TPUs agrupadas em uma rede especializada. O número de chips de TPU em um pod de TPU depende da versão da TPU.
Fração
Uma fração é um conjunto de chips localizados no mesmo pod de TPU conectados por interconexões de alta velocidade entre chips (ICI). As frações são descritas em termos de chips ou TensorCores, dependendo da versão da TPU.
Formato do chip e topologia do chip também se referem a formatos de fração.
Multislice x fração única
O Multislice é um grupo de frações que estende a conectividade da TPU além das conexões de interconexão entre chips (ICI) e aproveita a rede de data center (DCN) para transmitir dados além de uma fração. Os dados em cada fração ainda são transmitidos pela ICI. Usando essa conectividade híbrida, o Multislice permite o paralelismo entre as frações e possibilita usar um número maior de núcleos de TPU para um único job do que uma única fração pode acomodar.
As TPUs podem ser usadas para executar um job em uma ou várias frações. Consulte a introdução ao Multislice para mais detalhes.
Cubo de TPU
Uma topologia 4x4x4 de chips de TPU interconectados. Isso só é aplicável a topologias 3D (a partir da TPU v4).
SparseCore
Os SparseCores são processadores de fluxo de dados que aceleram modelos usando operações esparsas. Um caso de uso principal é a aceleração de modelos de recomendação, que dependem muito de embeddings. O v5p inclui quatro SparseCores por chip, e o v6e inclui dois SparseCores por chip. Para uma explicação detalhada sobre como usar o SparseCores, consulte Uma análise detalhada do SparseCore para modelos de embeddings grandes (LEM). Você controla como o compilador XLA usa o SparseCores com flags do XLA. Para mais informações, consulte: Flags do XLA da TPU.
Resiliência da ICI da Cloud TPU
A capacidade de recuperação do ICI ajuda a melhorar a tolerância a falhas de links ópticos e comutadores de circuito óptico (OCS, na sigla em inglês) que conectam as TPUs entre cubos. As conexões ICI em um cubo usam links de cobre que não são afetados. A capacidade de recuperação do ICI permite que as conexões sejam roteadas em torno de falhas do OCS e do ICI óptico. Como resultado, isso melhora a disponibilidade de programação de frações de TPU, com a compensação de uma degradação temporária no desempenho da ICI.
Para Cloud TPU v4 e v5p, a capacidade de recuperação do ICI é ativada por padrão para fatias de um cubo ou maiores, por exemplo:
- v5p-128 ao especificar o tipo de acelerador
- 4x4x4 ao especificar a configuração do acelerador
Versões de TPU
A arquitetura exata de um chip de TPU depende da versão usada. Cada versão de TPU também é compatível com diferentes tamanhos e configurações de fração. Para mais informações sobre a arquitetura do sistema e as configurações compatíveis, consulte as seguintes páginas:
Arquitetura de nuvem da TPU
OGoogle Cloud disponibiliza TPUs como recursos de computação por meio de VMs de TPU. É possível usar diretamente as VMs da TPU para suas cargas de trabalho ou pelo Google Kubernetes Engine ou pela Vertex AI. As seções a seguir descrevem os principais componentes da arquitetura de nuvem da TPU.
Arquitetura da VM da TPU
A arquitetura da VM da TPU permite que você se conecte diretamente à VM fisicamente conectada ao dispositivo de TPU usando SSH. Uma VM de TPU, também conhecida como worker, é uma máquina virtual que executa o Linux e tem acesso às TPUs subjacentes. Você tem acesso raiz à VM, então pode executar código arbitrário. É possível acessar registros de depuração do compilador e do ambiente de execução e mensagens de erro.

Host único, vários hosts e sub-host
Um host de TPU é uma VM executada em um computador físico conectado ao hardware de TPU. As cargas de trabalho de TPU podem usar um ou mais hosts.
Uma carga de trabalho de host único é limitada a uma VM de TPU. Uma carga de trabalho de vários hosts distribui o treinamento em várias VMs de TPU. Uma carga de trabalho de sub-host não usa todos os chips em uma VM de TPU.
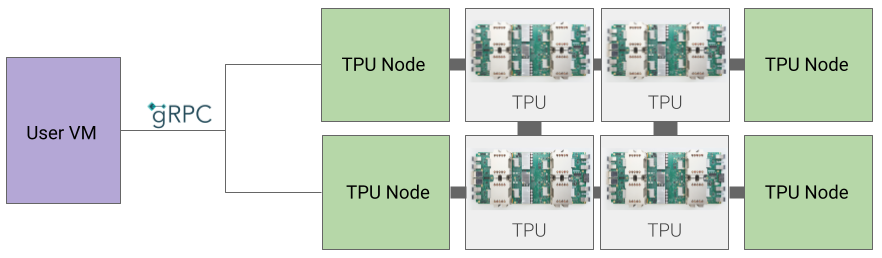
Arquitetura de nó da TPU (descontinuada)
A arquitetura do nó de TPU consiste em uma VM do usuário que se comunica com o host da TPU por gRPC. Ao usar essa arquitetura, não é possível acessar diretamente o host da TPU, o que dificulta a depuração de erros de treinamento e da TPU.
Como migrar da arquitetura de nó da TPU para a de VM da TPU
Se você tiver TPUs usando a arquitetura de nó da TPU, siga estas etapas para identificar, excluir e reaprovisionar como VMs de TPU.
Acesse a página "TPUs":
Localize a TPU e a arquitetura dela no cabeçalho Arquitetura. Se a arquitetura for "VM da TPU", não será necessário fazer nada. Se a arquitetura for "Nó da TPU", exclua e reprovisione a TPU.
Exclua e provisione a TPU novamente.
Consulte Como gerenciar TPUs para instruções sobre como excluir e reprovisionar TPUs.