TPU-Architektur
Tensor Processing Units (TPUs) sind von Google entwickelte anwendungsspezifische integrierte Schaltkreise (ASICs), die zur Beschleunigung von Machine-Learning-Arbeitslasten verwendet werden. Cloud TPU ist ein Dienst von Google Cloud , der TPUs als skalierbare Ressource zur Verfügung stellt.
TPUs sind für schnelle Matrixoperationen konzipiert und eignen sich daher ideal für Machine-Learning-Arbeitslasten. Sie können Machine-Learning-Arbeitslasten auf TPUs mit Frameworks wie Pytorch und JAX ausführen.
Wie funktionieren TPUs?
Um zu verstehen, wie TPUs funktionieren, ist es hilfreich zu wissen, wie andere Beschleuniger die rechnerischen Herausforderungen beim Trainieren von ML-Modellen bewältigen.
Funktionsweise einer CPU
Die CPU ist ein Prozessor für allgemeine Zwecke, der auf der Von-Neumann-Architektur basiert. Das bedeutet, dass eine CPU mit Software und Speicher folgendermaßen arbeitet:
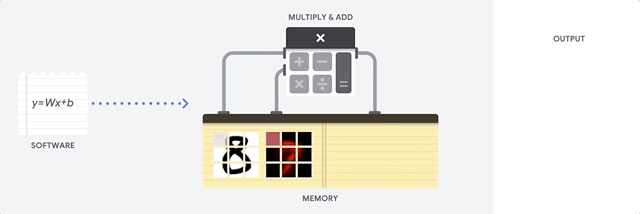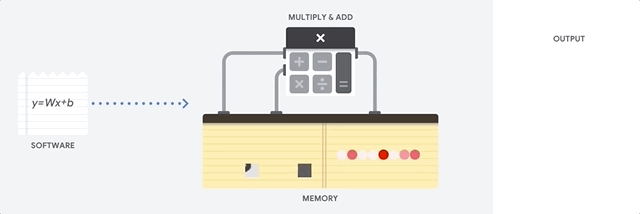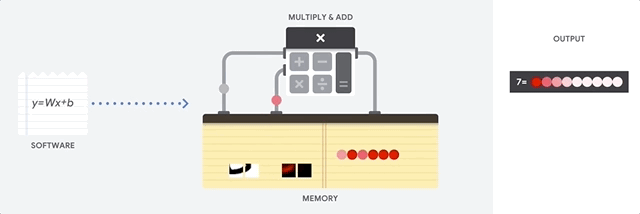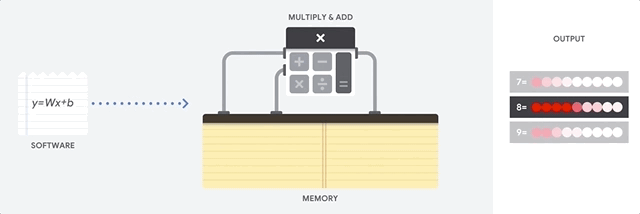
Der größte Vorteil von CPUs ist ihre Flexibilität. Sie können jede Art von Software auf einer CPU für viele verschiedene Arten von Anwendungen laden. Sie können beispielsweise eine CPU zur Textverarbeitung auf einem PC, zur Steuerung von Raketentriebwerken, zur Ausführung von Banktransaktionen oder zur Klassifizierung von Bildern mithilfe eines neuronalen Netzwerks verwenden.
Eine CPU lädt Werte aus dem Arbeitsspeicher, führt eine Berechnung der Werte durch und speichert das Ergebnis jeder Berechnung wieder im Arbeitsspeicher. Der Arbeitsspeicherzugriff ist im Vergleich zur Berechnungsgeschwindigkeit langsam und kann den Gesamtdurchsatz von CPUs einschränken. Dies wird oft als Von-Neumann-Engpass bezeichnet.
Funktionsweise einer GPU
GPUs bieten Tausende arithmetisch-logische Einheiten (ALUs) in einem einzigen Prozessor, um einen höheren Durchsatz zu erzielen. Eine moderne GPU enthält in der Regel zwischen 2.500 und 5.000 ALUs. Diese große Anzahl von Prozessoren ermöglicht es, Tausende von Multiplikationen und Additionen gleichzeitig auszuführen.

Eine GPU-Architektur eignet sich gut für Anwendungen mit massiver Parallelität, z. B. die Matrixmultiplikation in neuronalen Netzen. Im Vergleich zu einer CPU liefert eine GPU für eine typische Deep-Learning-Trainingsarbeitslast einen um Größenordnungen höheren Durchsatz.
Die GPU ist jedoch immer noch ein Prozessor für allgemeine Zwecke, der viele verschiedene Anwendungen und unterschiedliche Software unterstützen muss. Daher haben GPUs das gleiche Problem wie CPUs. Für jede einzelne Berechnung in den Tausenden von ALUs muss eine GPU auf Register oder gemeinsam genutzten Speicher zugreifen, um Operanden zu lesen und die Zwischenergebnisse der Berechnung zu speichern.
Funktionsweise einer TPU
Google hat Cloud TPUs als Matrixprozessoren konzipiert, die auf Arbeitslasten für neuronale Netze spezialisiert sind. TPUs können keine Textverarbeitungsprogramme ausführen, keine Raketentriebwerke steuern und keine Banktransaktionen ausführen. Sie können jedoch mit hoher Geschwindigkeit umfangreiche Matrixvorgänge verarbeiten, die in neuronalen Netzwerken verwendet werden.
Die Hauptaufgabe für TPUs ist die Matrixverarbeitung, bei der es sich um eine Kombination von Multiplikations- und Akkumulationsvorgängen handelt. TPUs enthalten Tausende von Multiplikationsakkumulatoren, die direkt miteinander verbunden sind, um eine große physische Matrix zu bilden. Dies wird als systolische Arrayarchitektur bezeichnet. Cloud TPU v3 enthalten zwei systolische Arrays von 128 × 128 ALUs auf einem einzelnen Prozessor.
Der TPU-Host streamt Daten in eine Einspeisewarteschlange. Die TPU lädt Daten aus der Einspeisewarteschlange und speichert sie im HBM-Arbeitsspeicher. Wenn die Berechnung abgeschlossen ist, lädt die TPU die Ergebnisse in die Ausgabewarteschlange. Der TPU-Host liest dann die Ergebnisse aus der Ausgabewarteschlange und speichert sie im Arbeitsspeicher des Hosts.
Zur Ausführung der Matrixvorgänge lädt die TPU die Parameter aus dem HBM-Arbeitsspeicher in die Matrix Multiplication Unit (MXU).

Dann lädt die TPU die Daten aus dem HBM-Speicher. Wenn eine Multiplikation ausgeführt wird, wird das Ergebnis an den nächsten Multiplikations-Akkumulator weitergeleitet. Die Ausgabe ist die Summe aller Multiplikationsergebnisse zwischen den Daten und Parametern. Während des Prozesses der Matrixmultiplikation ist kein Speicherzugriff erforderlich.
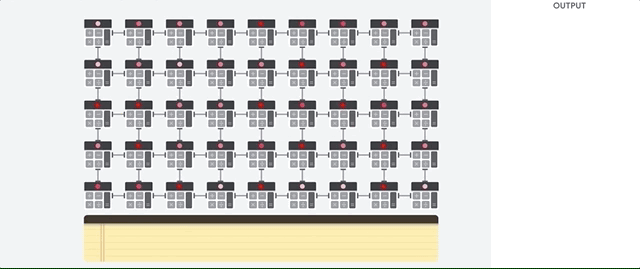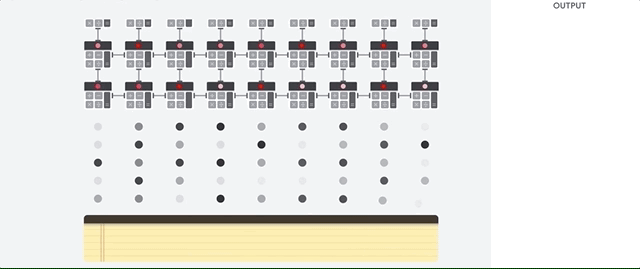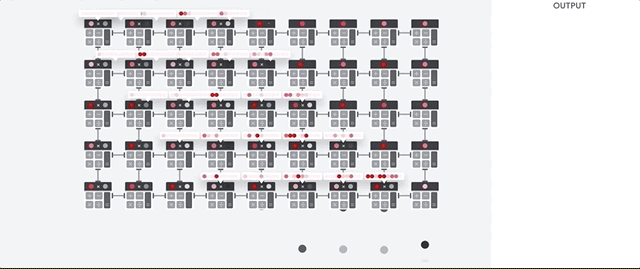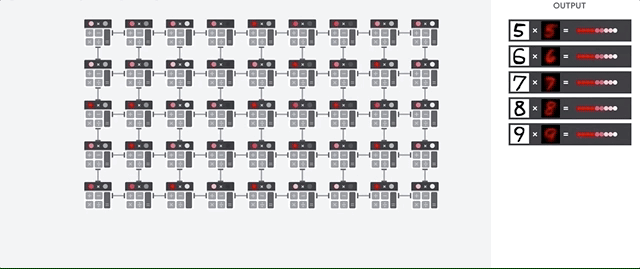
Infolgedessen können TPUs bei Berechnungen in neuronalen Netzen einen hohen rechnerischen Durchsatz erzielen.
TPU-Systemarchitektur
In den folgenden Abschnitten werden die wichtigsten Konzepte eines TPU-Systems beschrieben. Weitere Informationen zu gängigen Begriffen aus dem Bereich des maschinellen Lernens finden Sie im Glossar zum maschinellen Lernen.
Wenn Sie Cloud TPU noch nicht kennen, sehen Sie sich die Startseite der Cloud TPU-Dokumentation an.
TPU-Chip
Ein TPU-Chip enthält einen oder mehrere TensorCores. Die Anzahl der TensorCores hängt von der Version des TPU-Chips ab. Jeder TensorCore besteht aus einer oder mehreren Matrixmultiplikationseinheiten (MXUs), einer Vektoreinheit und einer Skalareinheit. Weitere Informationen zu TensorCores finden Sie im Paper A Domain-Specific Supercomputer for Training Deep Neural Networks.
Eine MXU besteht aus entweder 256 × 256 (TPU v6e) oder 128 × 128 (TPU-Versionen vor v6e) Multiplikatoren/Akkumulatoren in einem systolischen Array. MXUs stellen den Großteil der Rechenleistung in einem TensorCore bereit. Jede MXU kann pro Zyklus 16.000 Multiplikations- bzw. Akkumulationsvorgänge ausführen. Alle Multiplikationen verwenden bfloat16-Eingaben, alle Akkumulationen werden jedoch im FP32-Zahlenformat ausgeführt.
Die Vektoreinheit wird für allgemeine Berechnungen wie Aktivierungen und Softmax verwendet. Die Skalareinheit wird für die Ablaufsteuerung, die Berechnung der Speicheradressen und andere Wartungsvorgänge genutzt.
TPU-Pod
Ein TPU-Pod ist eine zusammenhängende Gruppe von TPUs, die über ein spezielles Netzwerk verbunden sind. Die Anzahl der TPU-Chips in einem TPU-Pod hängt von der TPU-Version ab.
Slice
Ein Slice ist eine Gruppe von Chips, die sich innerhalb desselben TPU-Pods befinden und über Hochgeschwindigkeits-Verbindungen zwischen den Chips (ICI) miteinander verbunden sind. Slices werden je nach TPU-Version in Bezug auf Chips oder TensorCores beschrieben.
Chipform und Chiptopologie beziehen sich ebenfalls auf Slice-Formen.
Multislice im Vergleich zu einem einzelnen Slice
Multislice ist eine Gruppe von Slices, die die TPU-Konnektivität über die Inter-Chip-Verbindungen (ICI) hinaus erweitert und das Rechenzentrumsnetzwerk (Data Center Network, DCN) für die Übertragung von Daten über einen Slice hinaus nutzt. Die Daten in jedem Segment werden weiterhin über ICI übertragen. Durch diese hybride Konnektivität ermöglicht Multislice Parallelisierung über mehrere Slices hinweg und die Verwendung einer größeren Anzahl von TPU-Kernen für einen einzelnen Job, als in einem einzelnen Slice verfügbar wären.
TPUs können verwendet werden, um einen Job entweder auf einem einzelnen oder auf mehreren Slices auszuführen. Weitere Informationen finden Sie unter Einführung in Multislice.
TPU-Cube
Eine 4 × 4 × 4-Topologie miteinander verbundener TPU-Chips. Dies gilt nur für 3D-Topologien (ab TPU v4).
SparseCore
SparseCores sind Dataflow-Prozessoren, die Modelle mit dünnbesetzten Operationen beschleunigen. Ein primärer Anwendungsfall ist die Beschleunigung von Empfehlungsmodellen, die stark auf Einbettungen basieren. v5p umfasst vier SparseCores pro Chip und v6e zwei SparseCores pro Chip. Eine ausführliche Erklärung zur Verwendung von SparseCores finden Sie im Dokumentationsabschnitt A deep dive into SparseCore for Large Embedding Models (LEM). Sie steuern, wie der XLA-Compiler SparseCores verwendet, indem Sie XLA-Flags festlegen. Weitere Informationen finden Sie unter TPU-XLA-Flags.
Cloud TPU-ICI-Ausfallsicherheit
Die ICI-Ausfallsicherheit trägt zur Verbesserung der Fehlertoleranz von optischen Verbindungen und optischen Schaltern (Optical Circuit Switches, OCS) bei, die TPUs zwischen Cubes verbinden. (Für ICI-Verbindungen innerhalb eines Cubes werden Kupferverbindungen verwendet, die nicht betroffen sind.) Die ICI-Ausfallsicherheit ermöglicht es, ICI-Verbindungen um OCS und optische ICI-Fehler herumzuleiten. Dadurch wird die Planungsverfügbarkeit von TPU-Slices verbessert, allerdings auf Kosten einer vorübergehenden Beeinträchtigung der ICI-Leistung.
Bei Cloud TPU v4 und v5p ist die ICI-Ausfallsicherheit standardmäßig für Slices aktiviert, die mindestens einen Cube haben, z. B.:
- v5p‑128 bei Angabe des Beschleunigertyps
- 4 x 4 x 4 bei der Angabe der Beschleunigerkonfiguration
TPU-Versionen
Die genaue Architektur eines TPU-Chips hängt von der verwendeten TPU-Version ab. Jede TPU-Version unterstützt auch unterschiedliche Slice-Größen und -Konfigurationen. Weitere Informationen zur Systemarchitektur und zu unterstützten Konfigurationen finden Sie auf den folgenden Seiten:
TPU-Cloud-Architektur
Google Cloud stellt TPUs als Rechenressourcen über TPU-VMs zur Verfügung. Sie können TPU-VMs direkt für Ihre Arbeitslasten oder über die Google Kubernetes Engine oder Vertex AI verwenden. In den folgenden Abschnitten werden die wichtigsten Komponenten der TPU-Cloud-Architektur beschrieben.
TPU-VM-Architektur
Die TPU-VM-Architektur ermöglicht es Ihnen, über SSH eine direkte Verbindung zur VM herzustellen, die physisch mit dem TPU-Gerät verbunden ist. Eine TPU-VM, auch als Worker bezeichnet, ist eine virtuelle Maschine, auf der Linux ausgeführt wird und die Zugriff auf die zugrunde liegenden TPUs hat. Sie haben Root-Zugriff auf die VM und können so beliebigen Code ausführen. Sie können auf Compiler- und Laufzeit-Debug-Logs sowie auf Fehlermeldungen zugreifen.

Einzelner Host, mehrere Hosts und Subhost
Ein TPU-Host ist eine VM, die auf einem physischen Computer ausgeführt wird, der mit TPU-Hardware verbunden ist. TPU-Arbeitslasten können einen oder mehrere Hosts verwenden.
Eine Arbeitslast mit einem einzelnen Host ist auf eine TPU-VM beschränkt. Bei einer Arbeitslast mit mehreren Hosts wird das Training auf mehrere TPU-VMs verteilt. Bei einer Subhost-Arbeitslast werden nicht alle Chips auf einer TPU-VM verwendet.
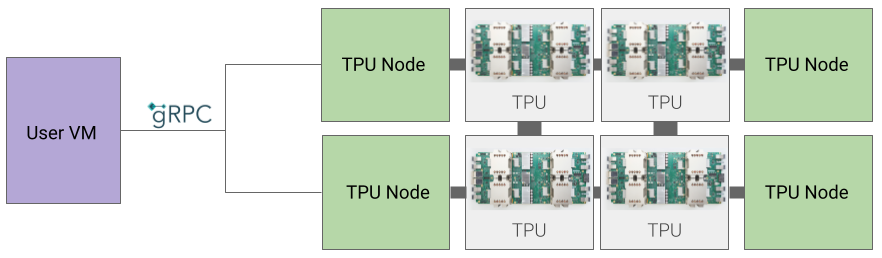
TPU-Knotenarchitektur (nicht mehr unterstützt)
Die TPU-Knotenarchitektur besteht aus einer Nutzer-VM, die über gRPC mit dem TPU-Host kommuniziert. Bei dieser Architektur können Sie nicht direkt auf den TPU-Host zugreifen, was das Debuggen von Trainings- und TPU-Fehlern erschwert.
Von der TPU-Knoten- zur TPU-VM-Architektur wechseln
Wenn Sie TPUs mit der TPU-Knotenarchitektur haben, gehen Sie folgendermaßen vor, um sie zu identifizieren, zu löschen und als TPU-VMs neu bereitzustellen.
Rufen Sie die Seite „TPUs“ auf:
Suchen Sie unter der Überschrift Architektur nach Ihrer TPU und ihrer Architektur. Wenn die Architektur „TPU VM“ ist, müssen Sie nichts weiter tun. Wenn die Architektur „TPU-Knoten“ ist, müssen Sie die TPU löschen und neu bereitstellen.
Löschen Sie die TPU und stellen Sie sie noch einmal bereit.
Eine Anleitung zum Löschen und Neubereitstellen von TPUs finden Sie unter TPUs verwalten.