Cloud TPU Multislice 總覽
Cloud TPU Multislice 是一項全堆疊效能擴充技術,可讓訓練工作在單一配量內或多個 Pod 的配量上,使用多個 TPU 配量,並採用標準資料平行處理方式。使用 TPU v4 晶片時,這表示訓練工作在單次執行中可使用超過 4096 個晶片。如果訓練工作需要的晶片少於 4096 個,單一切片就能提供最佳效能。不過,多個較小的切片更容易取得,因此搭配較小的切片使用 Multislice 時,啟動時間會更快。
以多配量設定部署時,每個配量中的 TPU 晶片會透過晶片間互連 (ICI) 通訊。不同切片中的 TPU 晶片會將資料傳輸至 CPU (主機),再由 CPU 透過資料中心網路 (DCN) 傳輸資料,藉此進行通訊。如要進一步瞭解如何使用 Multislice 擴大訓練規模,請參閱如何使用 Multislice,將 AI 訓練作業的規模擴充至高達數萬個 Cloud TPU 晶片。
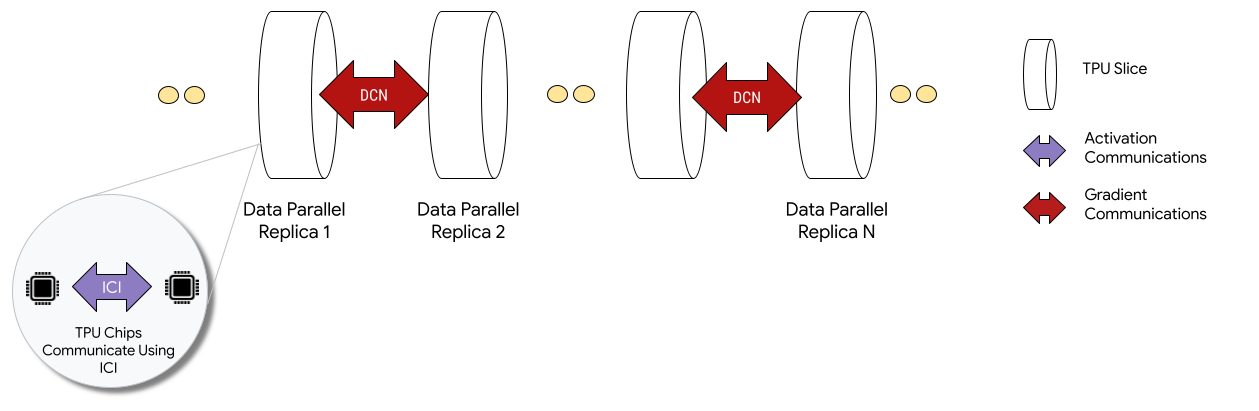
開發人員不必編寫程式碼,即可實作 DCN 跨切片通訊。XLA 編譯器會為您產生該程式碼,並將通訊與運算重疊,以發揮最大效能。
概念
- 加速器類型
- 構成 Multislice 的每個 TPU 配量形狀。多切片要求中的每個切片都屬於相同的加速器類型。加速器類型由 TPU 類型 (v4 以上) 和 TensorCore 數量組成。舉例來說,
v5litepod-128指定具有 128 個 TensorCore 的 TPU v5e。 - 自動修復
- 如果節點發生維護事件、遭到搶占或硬體故障,Cloud TPU 會建立新的節點。如果資源不足,無法建立新切片,則必須等到硬體可用時,才能完成建立作業。建立新切片後, 多切片環境中的所有其他切片都會重新啟動,以便繼續訓練。只要開機指令碼設定正確,訓練指令碼就能自動重新啟動,不必使用者介入,並從最新的檢查點載入及繼續執行。
- 資料中心網路 (DCN)
- 與 ICI 相比,延遲時間較長、處理量較低的網路,可連結 Multislice 設定中的 TPU 配量。
- 幫派排程
- 當所有 TPU 切片一起佈建時,可確保所有切片都能成功佈建,或全數佈建失敗。
- 晶片間互連網路 (ICI)
- 高速、低延遲的內部連結,可連結 TPU Pod 內的 TPU。
- Multislice
- 兩個以上的 TPU 晶片配量,可透過 DCN 通訊。
- 節點
- 在「多配量」環境中,節點是指單一 TPU 配量。Multislice 中的每個 TPU 節點都會獲得節點 ID。
- 啟動指令碼
- 標準 Compute Engine 開機指令碼,每次啟動或重新啟動 VM 時都會執行。如果是「多重切片」,則是在 QR code 建立要求中指定。如要進一步瞭解 Cloud TPU 啟動指令碼,請參閱「管理 TPU 資源」。
- Tensor
- 用於在機器學習模型中表示多維度資料的資料結構。
- Cloud TPU 容量類型
您可以從不同類型的容量建立 TPU (請參閱「TPU 計價方式」一文中的「使用選項」):
預訂:如要使用預訂,您必須與 Google 簽訂預訂協議。建立資源時,請使用
--reserved旗標。Spot:使用 Spot VM 做為先占配額的目標。系統可能會搶占資源,以利處理優先順序較高的工作要求。建立資源時,請使用
--spot旗標。隨需:以隨需配額為目標,不需要預留,也不會遭到搶占。TPU 要求會排入 Cloud TPU 提供的隨選配額佇列,但我們無法保證資源可用性。預設為選取狀態,不需要任何旗標。
開始使用
-
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
ici_data_parallelismici_fsdp_parallelismici_tensor_parallelism設定環境:
$ gcloud auth login $ export QR_ID=your-queued-resource-id $ export TPU_NAME=your-tpu-name $ export PROJECT=your-project-name $ export ZONE=us-central1-a $ export NETWORK_NAME=your-network-name $ export SUBNETWORK_NAME=your-subnetwork-name $ export RUNTIME_VERSION=v2-alpha-tpuv5-lite $ export ACCELERATOR_TYPE=v5litepod-16 $ export EXAMPLE_TAG_1=your-tag-1 $ export EXAMPLE_TAG_2=your-tag-2 $ export SLICE_COUNT=4 $ export STARTUP_SCRIPT='#!/bin/bash\n'
變數說明
輸入 說明 QR_ID 佇列資源的使用者指派 ID。 TPU_NAME TPU 的使用者指派名稱。 專案 Google Cloud 專案名稱 ZONE 指定要建立資源的區域。 NETWORK_NAME 虛擬私有雲網路的名稱。 SUBNETWORK_NAME 虛擬私有雲網路中的子網路名稱 RUNTIME_VERSION Cloud TPU 軟體版本。 ACCELERATOR_TYPE v4-16 EXAMPLE_TAG_1、EXAMPLE_TAG_2 等。 標記可用於識別網路防火牆的有效來源或目標 SLICE_COUNT 切片數量。最多只能有 256 個切片。 STARTUP_SCRIPT 如果您指定開機指令碼,系統會在佈建或重新啟動 TPU 節點時執行該指令碼。 為
gcloud建立 SSH 金鑰。建議您留空密碼 (執行下列指令後按兩次 Enter 鍵)。如果系統提示google_compute_engine檔案已存在,請取代現有版本。$ ssh-keygen -f ~/.ssh/google_compute_engine
佈建 TPU:
gcloud
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-id=${TPU_NAME} \ --zone=${ZONE} \ [--reserved |--spot]
Google Cloud CLI 不支援所有建立 QR code 的選項,例如標記。詳情請參閱「建立 QR 碼」。
控制台
前往 Google Cloud 控制台的「TPUs」頁面:
按一下「建立 TPU」。
在「Name」(名稱) 欄位中,輸入 TPU 的名稱。
在「Zone」(可用區) 方塊中,選取要建立 TPU 的可用區。
在「TPU type」(TPU 類型) 方塊中,選取加速器類型。加速器類型會指定要建立的 Cloud TPU 版本和大小。如要進一步瞭解各個 TPU 版本支援的加速器類型,請參閱「TPU 版本」。
在「TPU 軟體版本」方塊中,選取軟體版本。建立 Cloud TPU VM 時,TPU 軟體版本會指定要安裝的 TPU 執行階段版本。詳情請參閱「TPU 軟體版本」。
按一下「啟用佇列」切換鈕。
在「Queued resource name」(已加入佇列的資源名稱) 欄位中,輸入已加入佇列的資源要求名稱。
按一下「建立」,建立已加入佇列的資源要求。
等待佇列資源處於
ACTIVE狀態,這表示工作站節點處於READY狀態。排入佇列的資源開始佈建後,可能需要 1 到 5 分鐘才能完成,視排入佇列的資源大小而定。您可以使用 gcloud CLI 或 Google Cloud 主控台,檢查已加入佇列的資源要求狀態:gcloud
$ gcloud compute tpus queued-resources \ list --filter=${QR_ID} --zone=${ZONE}
控制台
前往 Google Cloud 控制台的「TPUs」頁面:
按一下「已加入佇列的資源」分頁標籤。
按一下已加入佇列的資源要求名稱。
使用 SSH 連線至 TPU VM:
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} --zone=${ZONE}
將 MaxText (包括
shardings.py) 複製到 TPU VM:$ git clone https://github.com/AI-Hypercomputer/maxtext && cd maxtext
安裝 Python 3.10:
$ sudo apt-get update $ sudo apt install python3.10 $ sudo apt install python3.10-venv
建立並啟用虛擬環境:
$ python3 -m venv your-venv-name $ source your-venv-name/bin/activate
在 MaxText 存放區目錄中,執行設定指令碼,在 TPU 節點上安裝 JAX 和其他依附元件。設定指令碼需要幾分鐘才能執行完畢。
$ bash setup.sh
執行下列指令,在 TPU 節點上執行
shardings.py。$ python3 -m pedagogical_examples.shardings \ --ici_fsdp_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
您可以在記錄中查看結果。TPU 的速度應可達到每秒 260 TFLOP,或令人驚豔的 90%以上 FLOP 使用率!在本例中,我們選取的大約是可放入 TPU 高頻寬記憶體 (HBM) 的最大批次。
歡迎探索 ICI 的其他分片策略,例如嘗試下列組合:
$ python3 -m pedagogical_examples.shardings \ --ici_tensor_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
完成後,請刪除排入佇列的資源和 TPU 節點。您應從設定切片的環境執行這些清理步驟 (先執行
exit結束 SSH 工作階段)。刪除作業需要 2 到 5 分鐘才能完成。如果您使用 gcloud CLI,可以執行這個指令並加上選用的--async旗標,在背景執行指令。gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --force (--async)
控制台
前往 Google Cloud 控制台的「TPUs」頁面:
按一下「已加入佇列的資源」分頁標籤。
選取佇列中的資源要求旁邊的核取方塊。
按一下「刪除」圖示 。
- dcn_data_parallelism
- dcn_fsdp_parallelism
- dcn_tensor_parallelism
在執行器電腦上複製 MaxText:
$ git clone https://github.com/AI-Hypercomputer/maxtext
前往存放區目錄。
$ cd maxtext
為
gcloud建立 SSH 金鑰,建議您將密碼留空 (執行下列指令後按兩次 Enter 鍵)。如果系統提示google_compute_engine檔案已存在,請選取不要保留現有版本。$ ssh-keygen -f ~/.ssh/google_compute_engine
新增環境變數,將 TPU 節點數設為
2。$ export SLICE_COUNT=2
使用
queued-resources create指令或 Google Cloud 控制台建立 Multislice 環境。gcloud
以下指令示範如何建立 v5e Multislice TPU。如要使用其他 TPU 版本,請指定其他
accelerator-type和runtime-version。$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-count=${SLICE_COUNT} \ --node-prefix=${TPU_NAME} \ --zone=${ZONE} \ [--reserved|--spot]
控制台
前往 Google Cloud 控制台的「TPUs」頁面:
按一下「建立 TPU」。
在「Name」(名稱) 欄位中,輸入 TPU 的名稱。
在「Zone」(可用區) 方塊中,選取要建立 TPU 的可用區。
在「TPU type」(TPU 類型) 方塊中,選取加速器類型。加速器類型會指定要建立的 Cloud TPU 版本和大小。Multislice 僅支援 Cloud TPU v4 和更新版本的 TPU。如要進一步瞭解 TPU 版本,請參閱「TPU 版本」。
在「TPU 軟體版本」方塊中,選取軟體版本。建立 Cloud TPU VM 時,TPU 軟體版本會指定要安裝在 TPU VM 上的 TPU 執行階段版本。詳情請參閱「TPU 軟體版本」。
按一下「啟用佇列」切換鈕。
在「Queued resource name」(已加入佇列的資源名稱) 欄位中,輸入已加入佇列的資源要求名稱。
按一下「將此設為多配量 TPU」核取方塊。
在「切片數量」欄位中,輸入要建立的切片數量。
按一下「建立」,建立已加入佇列的資源要求。
排入佇列的資源開始佈建後,最多可能需要五分鐘才能完成,視排入佇列的資源大小而定。等待佇列資源處於
ACTIVE狀態。您可以使用 gcloud CLI 或 Google Cloud console,查看已加入佇列的資源要求狀態:gcloud
$ gcloud compute tpus queued-resources list \ --filter=${QR_ID} --zone=${ZONE} --project=${PROJECT}
這會產生類似以下的輸出內容:
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central2-b 4 v5litepod-16 ACTIVE ...
控制台
前往 Google Cloud 控制台的「TPUs」頁面:
按一下「已加入佇列的資源」分頁標籤。
按一下已加入佇列的資源要求名稱。
如果 QR code 狀態處於 Google Cloud 或
WAITING_FOR_RESOURCES狀態超過 15 分鐘,請與帳戶代表聯絡。PROVISIONING安裝依附元件:
$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="bash setup.sh"
在每個工作站上使用
multihost_runner.py執行shardings.py。$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="python3 -m pedagogical_examples.shardings \ --dcn_data_parallelism ${SLICE_COUNT} \ --ici_fsdp_parallelism 16 \ --batch_size 131072 \ --embedding_dimension 2048"
記錄檔中會顯示每秒約 230 TFLOP 的效能。
如要進一步瞭解如何設定平行處理,請參閱「使用 DCN 平行處理的多切片分片」和
shardings.py。完成後,請清除 TPU 和排入佇列的資源。刪除作業需要 2 到 5 分鐘才能完成。如果您使用 gcloud CLI,可以執行這個指令並加上選用的
--async旗標,在背景執行指令。- 建立網格時,請使用 jax.experimental.mesh_utils.create_hybrid_device_mesh,而不是 jax.experimental.mesh_utils.create_device_mesh。
- 使用實驗執行器指令碼,
multihost_runner.py - 使用正式版執行器指令碼
multihost_job.py。 - 使用手動做法
使用下列指令建立已加入佇列的資源要求:
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --project=${PROJECT} \ --zone=${ZONE} \ --node-count=${SLICE_COUNT} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --network=${NETWORK_NAME} \ --subnetwork=${SUBNETWORK_NAME} \ --tags=${EXAMPLE_TAG_1},${EXAMPLE_TAG_2} \ --metadata=startup-script="${STARTUP_SCRIPT}" \ [--reserved|--spot]
建立名為
queued-resource-req.json的檔案,然後將下列 JSON 複製到檔案中。{ "guaranteed": { "reserved": true }, "tpu": { "node_spec": [ { "parent": "projects/your-project-number/locations/your-zone", "node": { "accelerator_type": "accelerator-type", "runtime_version": "tpu-vm-runtime-version", "network_config": { "network": "your-network-name", "subnetwork": "your-subnetwork-name", "enable_external_ips": true }, "tags" : ["example-tag-1"] "metadata": { "startup-script": "your-startup-script" } }, "multi_node_params": { "node_count": slice-count, "node_id_prefix": "your-queued-resource-id" } } ] } }
替換下列值:
- your-project-number - 您的 Google Cloud 專案編號
- your-zone:您要在其中建立排入佇列資源的區域
- accelerator-type - 單一切片的版本和大小。 Multislice 僅支援 Cloud TPU v4 和更新版本的 TPU。
- tpu-vm-runtime-version - 要使用的 TPU VM 執行階段版本。
- your-network-name - 選用,排隊資源要連結的網路
- your-subnetwork-name - 選用,排隊資源要附加的子網路
- example-tag-1 - 選用,任意標記字串
- your-startup-script:在分配佇列資源時執行的開機指令碼
- slice-count - Multislice 環境中的 TPU 配量數量
- your-queued-resource-id - 佇列資源的使用者提供 ID
如要進一步瞭解所有可用選項,請參閱 REST Queued Resource API 說明文件。
如要使用 Spot 容量,請替換下列項目:
"guaranteed": { "reserved": true }"spot": {}移除該行,即可使用預設的隨選容量。
使用 JSON 酬載提交已加入佇列的資源建立要求:
$ curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d @queuedresourcereq.json \ https://tpu.googleapis.com/v2alpha1/projects/your-project-id/locations/your-zone/queuedResources\?queued_resource_id\=your-queued-resource-id
替換下列值:
- your-project-id:您的 Google Cloud 專案 ID
- your-zone:您要在其中建立排入佇列資源的區域
- your-queued-resource-id - 佇列資源的使用者提供 ID
前往 Google Cloud 控制台的「TPUs」頁面:
按一下「建立 TPU」。
在「Name」(名稱) 欄位中,輸入 TPU 的名稱。
在「Zone」(可用區) 方塊中,選取要建立 TPU 的可用區。
在「TPU type」(TPU 類型) 方塊中,選取加速器類型。加速器類型會指定要建立的 Cloud TPU 版本和大小。Multislice 僅支援 Cloud TPU v4 和後續 TPU 版本。如要進一步瞭解各個 TPU 版本支援的加速器類型,請參閱「TPU 版本」。
在「TPU 軟體版本」方塊中,選取軟體版本。建立 Cloud TPU VM 時,TPU 軟體版本會指定要安裝的 TPU 執行階段版本。詳情請參閱「TPU 軟體版本」。
按一下「啟用佇列」切換鈕。
在「Queued resource name」(已加入佇列的資源名稱) 欄位中,輸入已加入佇列的資源要求名稱。
按一下「將此設為多配量 TPU」核取方塊。
在「切片數量」欄位中,輸入要建立的切片數量。
按一下「建立」,建立已加入佇列的資源要求。
前往 Google Cloud 控制台的「TPUs」頁面:
按一下「已加入佇列的資源」分頁標籤。
按一下已加入佇列的資源要求名稱。
前往 Google Cloud 控制台的「TPUs」頁面:
按一下「已加入佇列的資源」分頁標籤。
前往 Google Cloud 控制台的「TPUs」頁面:
按一下「已加入佇列的資源」分頁標籤。
選取佇列中的資源要求旁邊的核取方塊。
按一下「刪除」圖示 。
- B 是以權杖為單位的批次大小
- P 是參數數量
- 這會導致「管道泡泡」,因為晶片閒置等待資料。
- 這需要微批次處理,會降低有效批量大小、算術強度,以及最終的模型 FLOP 利用率。
如要使用多配量,必須將 TPU 資源管理為排入佇列的資源。
入門範例
本教學課程使用 MaxText GitHub 存放區中的程式碼。 MaxText 是以 Python 和 Jax 編寫的基礎 LLM,具備高效能、任意擴充性、開放原始碼,且經過完善測試。MaxText 的設計宗旨是在 Cloud TPU 上有效率地訓練模型。
shardings.py 中的程式碼旨在協助您開始實驗不同的平行處理選項。例如資料平行處理、完全分割資料平行處理 (FSDP) 和張量平行處理。程式碼可從單一 Slice 擴充至 Multislice 環境。
ICI 平行處理
ICI 是指連結單一配量中 TPU 的高速互連網路。ICI 分片對應於切片內的分片。shardings.py
提供三個 ICI 平行處理參數:
您為這些參數指定的值,會決定每個平行處理方法的分片數量。
這些輸入內容必須受到限制,因此 ici_data_parallelism * ici_fsdp_parallelism * ici_tensor_parallelism 等於切片中的晶片數量。
下表顯示 v4-8 中四個可用晶片的 ICI 平行處理範例使用者輸入內容:
| ici_data_parallelism | ici_fsdp_parallelism | ici_tensor_parallelism | |
| 四向 FSDP | 1 | 4 | 1 |
| 4 向張量平行處理 | 1 | 1 | 4 |
| 雙向 FSDP + 雙向張量平行處理 | 1 | 2 | 2 |
請注意,在大多數情況下,ici_data_parallelism 應保留為 1,因為 ICI 網路速度夠快,幾乎一律會優先使用 FSDP,而非資料平行處理。
本範例假設您熟悉在單一 TPU 配量上執行程式碼,例如「使用 JAX 在 Cloud TPU VM 上執行計算」一文所述。這個範例說明如何在單一切片上執行 shardings.py。
使用 DCN 平行處理的多切片分割
shardings.py 指令碼會採用三個參數,指定 DCN 平行處理,對應於每種資料平行處理的分片數量:
這些參數的值必須受到限制,因此 dcn_data_parallelism * dcn_fsdp_parallelism * dcn_tensor_parallelism 等於切片數量。
以兩個切片為例,請使用 --dcn_data_parallelism = 2。
| dcn_data_parallelism | dcn_fsdp_parallelism | dcn_tensor_parallelism | 切片數量 | |
| 雙向資料平行處理 | 2 | 1 | 1 | 2 |
dcn_tensor_parallelism 應一律設為 1,因為 DCN 不適合這類分片。對於 v4 晶片上的典型 LLM 工作負載,dcn_fsdp_parallelism 也應設為 1,因此 dcn_data_parallelism 應設為切片數量,但這取決於應用程式。
增加切片數量時 (假設切片大小和每個切片的批次保持不變),資料平行處理量也會增加。
在 Multislice 環境中執行 shardings.py
您可以使用 multihost_runner.py,或在每個 TPU VM 上執行 shardings.py,在多配量環境中執行 shardings.py。這裡我們使用
multihost_runner.py。下列步驟與 MaxText 存放區的「開始使用:多個切片的快速實驗」中的步驟非常相似,但這裡我們執行的是 shardings.py,而不是 train.py 中較複雜的 LLM。
multihost_runner.py 工具經過最佳化,可快速進行實驗,並重複使用相同的 TPU。由於 multihost_runner.py 指令碼依賴長時間的 SSH 連線,因此不建議用於任何長時間執行的工作。如要執行較長時間的工作 (例如數小時或數天),建議使用 multihost_job.py。
在本教學課程中,我們使用「執行器」一詞,表示您執行 multihost_runner.py 指令碼的機器。我們使用「工作站」一詞來表示構成切片的 TPU VM。您可以在本機電腦或與切片位於相同專案的任何 Compute Engine VM 上執行 multihost_runner.py。不支援在工作者上執行 multihost_runner.py。
multihost_runner.py 會使用 SSH 自動連線至 TPU 工作站。
在本例中,您會在兩個 v5e-16 配量上執行 shardings.py,共四部 VM 和 16 個 TPU 晶片。您可以修改範例,在更多 TPU 上執行。
設定環境
將工作負載擴充至 Multislice
在 Multislice 環境中執行模型前,請先進行下列程式碼變更:
改用 Multislice 時,您只需要進行這些程式碼變更。如要達到高效能,DCN 必須對應至資料平行、完全分片資料平行或管道平行軸。如要進一步瞭解效能注意事項和分片策略,請參閱「使用多切片分片,盡量提升效能」。
如要驗證程式碼是否可存取所有裝置,可以確認 len(jax.devices()) 等於 Multislice 環境中的晶片數量。舉例來說,如果您使用四個 v4-16 切片,每個切片有八個晶片,因此 len(jax.devices()) 應傳回 32。
為 Multislice 環境選擇切片大小
如要線性加速,請新增與現有切片大小相同的切片。舉例來說,如果您使用 v4-512 切片,Multislice 會新增第二個 v4-512 切片,並將全域批次大小加倍,藉此將效能提升約一倍。詳情請參閱「Sharding With Multislice for Maximum Performance」。
在多個切片上執行工作
在 Multislice 環境中執行自訂工作負載的方法有三種:
實驗執行器指令碼
multihost_runner.py 指令碼會將程式碼分配至現有的 Multislice 環境,並在每個主機上執行指令、將記錄檔複製回來,以及追蹤每個指令的錯誤狀態。multihost_runner.py 指令碼的說明文件位於 MaxText README。
由於 multihost_runner.py 會維護持續性 SSH 連線,因此只適合規模適中、執行時間相對較短的實驗。您可以根據工作負載和硬體設定,調整multihost_runner.py教學課程中的步驟。
正式版執行器指令碼
如要讓正式版作業在硬體故障和其他搶占情況下仍能正常運作,建議直接整合 Create Queued Resource API。請使用 multihost_job.py 做為工作範例,觸發「已建立佇列資源」API 呼叫,並搭配適當的啟動指令碼來執行訓練,以及在搶占後繼續執行。multihost_job.py 指令碼的說明文件位於 MaxText README。
由於 multihost_job.py 必須為每次執行佈建資源,因此疊代週期不如 multihost_runner.py 快速。
手動方法
建議您使用或調整 multihost_runner.py 或 multihost_job.py,在 Multislice 設定中執行自訂工作負載。不過,如果您偏好直接使用 QR 指令佈建及管理環境,請參閱「管理多重切片環境」。
管理 Multislice 環境
如要手動佈建及管理 QR code,而不使用 MaxText 存放區提供的工具,請參閱下列章節。
建立排入佇列的資源
gcloud
請確認您有相應配額,再選取 --reserved、--spot 或預設隨選配額。如要瞭解配額類型,請參閱配額政策。
curl
回應內容應如下所示:
{ "name": "projects/<your-project-id>/locations/<your-zone>/operations/operation-<your-qr-guid>", "metadata": { "@type": "type.googleapis.com/google.cloud.common.OperationMetadata", "createTime": "2023-11-01T00:17:05.742546311Z", "target": "projects/<your-project-id>/locations/<your-zone>/queuedResources/<your-qa-id>", "verb": "create", "cancelRequested": false, "apiVersion": "v2alpha1" }, "done": false }
在 name 屬性的字串值結尾使用 GUID 值,即可取得已加入佇列的資源要求相關資訊。
控制台
擷取排入佇列的資源狀態
gcloud
$ gcloud compute tpus queued-resources describe ${QR_ID} --zone=${ZONE}
如果佇列資源處於 ACTIVE 狀態,輸出內容會如下所示:
...
state:
state: ACTIVE
...
curl
$ curl -X GET -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://tpu.googleapis.com/v2/projects/your-project-id/locations/your-zone/queuedResources/${YOUR_QR_ID}
如果佇列資源處於 ACTIVE 狀態,輸出內容會如下所示:
{
"name": your-queued-res,
"tpu": {
"nodeSpec": [
{
... // node 1
},
{
... // node 2
},
...
]
},
...
"state": "ACTIVE"
}
控制台
佈建 TPU 後,您也可以前往「TPU」頁面,找出 TPU 並點選相應的佇列資源要求名稱,查看佇列資源要求的詳細資料。
在極少數情況下,您可能會發現佇列中的資源處於 FAILED 狀態,而某些切片則處於 ACTIVE 狀態。如果發生這種情況,請刪除已建立的資源,幾分鐘後再試一次,或聯絡Google Cloud 支援團隊。
透過 SSH 連線並安裝依附元件
在 TPU 配量上執行 JAX 程式碼:說明如何使用 SSH 連線至單一配量中的 TPU VM。如要透過 SSH 連線至 Multislice 環境中的所有 TPU VM,並安裝依附元件,請使用下列 gcloud 指令:
$ gcloud compute tpus queued-resources ssh ${QR_ID} \ --zone=${ZONE} \ --node=all \ --worker=all \ --command="command-to-run" \ --batch-size=4
這項 gcloud 指令會透過 SSH 將指定指令傳送至 QR 中的所有工作站和節點。這項指令會分批傳送,每批四個,並同時傳送。目前批次執行完畢後,系統就會傳送下一批指令。如果其中一個指令失敗,系統會停止處理,且不會再傳送任何批次。詳情請參閱「已加入佇列的資源 API 參考資料」。如果使用的切片數量超過本機電腦的執行緒限制 (也稱為批次處理限制),就會發生死結。舉例來說,假設本機電腦的批次處理限制為 64。如果您嘗試在超過 64 個切片上執行訓練指令碼 (例如 100 個),SSH 指令會將切片分成批次。系統會對第一批 64 個切片執行訓練指令碼,並等待指令碼完成,再對其餘 36 個切片執行指令碼。不過,前 64 個切片必須等待其餘 36 個切片開始執行指令碼,才能完成作業,因此會造成死結。
如要避免這種情況,請在每個 VM 上執行訓練指令時,在指令後方加上連字號 (&),並使用 --command 標記指定指令,即可在背景執行訓練指令。這麼做之後,在第一批切片上啟動訓練指令碼後,控制權會立即返回 SSH 指令。接著,SSH 指令就能開始在剩餘的 36 個切片批次上執行訓練指令碼。在背景執行指令時,您需要適當管道傳送 stdout 和 stderr 串流。如要提高同一 QR 內的平行處理程度,可以使用 --node 參數選取特定切片。
網路設定
請執行下列步驟,確保 TPU 配量可以互相通訊。在每個切片上安裝 JAX。詳情請參閱「在 TPU 配量上執行 JAX 程式碼」。確認 len(jax.devices()) 等於 Multislice 環境中的晶片數量。如要這麼做,請在每個切片上執行下列指令:
$ python3 -c 'import jax; print(jax.devices())'
如果您在四個 v4-16 的切片上執行這段程式碼,每個切片有八個晶片,四個切片總共會有 32 個晶片 (裝置),應由 jax.devices() 傳回。
列出排入佇列的資源
gcloud
您可以使用 queued-resources list 指令查看已加入佇列的資源狀態:
$ gcloud compute tpus queued-resources list --zone=${ZONE}
輸出看起來類似以下內容:
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central1-a 4 v5litepod-16 ACTIVE ...
控制台
在已佈建的環境中啟動工作
您可以透過 SSH 連線至每個切片中的所有主機,並在所有主機上執行下列指令,手動執行工作負載。
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} \ --zone=${ZONE} \ --worker=all \ --command="command-to-run"
重設應答短訊
您可以使用 ResetQueuedResource API 重設 ACTIVE QR 中的所有 VM。強制重設 VM 會清除機器的記憶體,並將 VM 重設為初始狀態。本機儲存的資料不會受到影響,且系統會在重設後叫用啟動指令碼。如果您想重新啟動所有 TPU,可以運用 ResetQueuedResource API。舉例來說,當訓練停滯不前,且重設所有 VM 比偵錯更簡單時。
所有 VM 的重設作業會平行執行,ResetQueuedResource作業需要一到兩分鐘才能完成。如要叫用 API,請使用下列指令:
$ gcloud compute tpus queued-resources reset ${QR_ID} --zone=${ZONE}
刪除排入佇列的資源
如要在訓練工作階段結束時釋出資源,請刪除已加入佇列的資源。刪除作業需要 2 到 5 分鐘才能完成。如果您使用 gcloud CLI,可以搭配選用的 --async 標記,在背景執行這項指令。
gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --zone=${ZONE} --force [--async]
控制台
自動故障復原
如果發生中斷情形,Multislice 會自動修復受影響的切片,並在之後重設所有切片。受影響的切片會由新切片取代,其餘正常切片則會重設。如果沒有可用的容量來分配替代切片,訓練就會停止。
如要在中斷後自動繼續訓練,您必須指定啟動指令碼,檢查並載入上次儲存的檢查點。每次重新配置配量或重設 VM 時,系統都會自動執行開機指令碼。您可以在傳送至建立 QR code 要求 API 的 JSON 酬載中,指定啟動指令碼。
下列開機指令碼 (用於「建立 QR 碼」) 可讓您在 MaxText 訓練期間,從儲存在 Cloud Storage 值區的檢查點自動復原失敗狀態,並繼續訓練:
{
"tpu": {
"node_spec": [
{
...
"metadata": {
"startup-script": "#! /bin/bash \n pwd \n runuser -l user1 -c 'cd /home/user1/MaxText && python3 -m MaxText.train MaxText/configs/base.yml run_name=run_test_failure_recovery dcn_data_parallelism=4 ici_fsdp_parallelism=8 steps=10000 save_period=10 base_output_directory='gs://user1-us-central2'' EOF"
}
...
}
]
}
}
請先複製 MaxText 存放區,再試試這項功能。
剖析和偵錯
單一切片和多切片環境中的剖析作業相同。詳情請參閱「剖析 JAX 程式」。
取得最佳培訓成效
下列各節說明如何最佳化 Multislice 訓練。
使用 Multislice 進行分片,以獲得最高效能
如要在 Multislice 環境中達到最高效能,必須考慮如何在多個 Slice 之間分片。通常有三種選擇 (資料平行處理、完全分片資料平行處理和 pipeline 平行處理)。我們不建議在模型維度之間分片啟用 (有時稱為張量平行處理),因為這需要過多的切片間頻寬。對於所有這些策略,您可以在過去適用於您的切片中,保留相同的分片策略。
建議您先從純資料平行化著手。使用完全分片的資料平行處理,有助於釋放記憶體用量。缺點是切片之間的通訊會使用 DCN 網路,導致工作負載速度變慢。只有在必要時,才根據批次大小使用管道平行處理 (如下方分析)。
何時該使用資料平行化
如果工作負載執行順暢,但您想透過跨多個切片擴展來提升效能,純資料平行處理就很適合。
如要在多個切片中實現強大的縮放功能,透過 DCN 執行 all-reduce 作業所需的時間,必須少於執行反向傳遞作業所需的時間。DCN 用於切片之間的通訊,是工作負載輸送量的限制因素。
每個 v4 TPU 晶片的尖峰效能為每秒 275 * 1012 FLOPS。
每個 TPU 主機有四個晶片,且每個主機的網路頻寬上限為 50 Gbps。
也就是說,算術強度為 4 * 275 * 1012 FLOPS / 50 Gbps = 22000 FLOPS / bit。
模型會為每個步驟的每個參數使用 32 到 64 位元的 DCN 頻寬。如果使用兩個切片,模型會使用 32 位元的 DCN 頻寬。如果您使用超過兩個切片,編譯器會執行完整的隨機全歸約作業,且每個步驟的每個參數最多會使用 64 位元的 DCN 頻寬。每個參數所需的 FLOPS 數量會因模型而異。具體來說,對於以 Transformer 為基礎的語言模型,正向和反向傳遞所需的 FLOPS 數量約為 6 * B * P,其中:
每個參數的 FLOPS 數量為 6 * B,反向傳遞期間每個參數的 FLOPS 數量為 4 * B。
如要確保多個切片都能有效擴充,請確認運算強度超過 TPU 硬體的算術強度。如要計算運算強度,請將反向傳遞期間每個參數的 FLOPS 數,除以每個步驟中每個參數的網路頻寬 (以位元為單位):
Operational Intensity = FLOPSbackwards_pass / DCN bandwidth
因此,如果是以 Transformer 為基礎的語言模型,使用兩個切片時:
Operational intensity = 4 * B / 32
如果使用超過兩個切片:Operational intensity = 4 * B/64
這表示 Transformer 語言模型的最小批次大小應介於 176k 到 352k 之間。由於 DCN 網路可能會短暫捨棄封包,因此最好保留大量錯誤空間,只有在每個 Pod 的批次大小至少為 35 萬 (兩個 Pod) 到 70 萬 (多個 Pod) 時,才部署資料平行處理。
如果是其他模型架構,您需要估算每個切片的向後傳遞執行時間 (可使用剖析器計時,或計算 FLOPS)。接著,您可以將該時間與預期執行時間進行比較,以減少 DCN 溢出,並準確估算資料平行處理是否適合您。
何時該使用完全分片資料平行處理 (FSDP)
全分割資料平行處理 (FSDP) 會結合資料平行處理 (在節點間分割資料) 和在節點間分割權重。在正向和反向傳遞的每個作業中,權重都會全部收集,讓每個切片都有所需的權重。梯度不會使用 all-reduce 進行同步處理,而是會在產生時進行 reduce-scatter。這樣一來,每個切片只會取得其負責權重的梯度。
與資料平行處理類似,FSDP 也會要求全域批次大小隨著切片數量線性擴展。隨著切片數量增加,FSDP 會降低記憶體壓力。這是因為每個切片的權重和最佳化工具狀態數量會減少,但代價是網路流量增加,且集體作業延遲而導致封鎖的可能性更高。
在實務上,如果您要增加每個切片的批次大小、儲存更多啟用項目,以盡量減少反向傳遞期間的重新實現作業,或是增加神經網路中的參數數量,最好使用切片 FSDP。
FSDP 中的全收集和全縮減作業與 DP 中的作業類似,因此您可以按照上一節所述的方式,判斷 FSDP 工作負載是否受 DCN 效能限制。
何時使用管道平行處理
如果使用其他平行處理策略時,需要大於偏好最大批次大小的全球批次大小,才能達到高成效,這時管道平行處理就顯得相當重要。管道平行處理可讓管道的切片「共用」批次。不過,管道平行處理有兩項重大缺點:
只有在其他平行處理策略需要過大的全域批次大小時,才應使用管道平行處理。嘗試管線平行處理前,建議先進行實驗,根據經驗判斷在達到高效能 FSDP 時,每個樣本的收斂速度是否會因批次大小而變慢。FSDP 往往能提高模型 FLOP 使用率,但如果每個樣本的收斂速度隨著批次大小增加而變慢,管道平行化可能仍是較好的選擇。大多數工作負載可容許足夠大的批次大小,因此不會受益於管道平行處理,但您的工作負載可能不同。
如有必要,建議您將管道平行處理與資料平行處理或 FSDP 結合使用。這樣一來,您就能盡量減少管道深度,同時增加每個管道的批次大小,直到 DCN 延遲不再是輸送量的影響因素為止。具體來說,如果您有 N 個切片,請考慮深度為 2 的管道和 N/2 個資料平行處理複本,然後是深度為 4 的管道和 N/4 個資料平行處理複本,依此類推,直到每個管道的批次夠大,DCN 集體作業可隱藏在反向傳遞的算術中為止。這樣可盡量減少管線平行處理造成的效能降低,同時允許您擴充超過全域批次大小限制。
多切片最佳做法
下列各節將說明 Multislice 訓練的最佳做法。
載入資料
訓練期間,我們會從資料集重複載入批次資料,並提供給模型。為了避免 TPU 閒置,請務必使用有效率的非同步資料載入器,將批次資料分散到各主機。MaxText 中的現有資料載入器會讓每個主機載入相同數量的範例子集。這個解決方案適用於文字,但需要在模型中重新分片。此外,MaxText 目前尚未提供確定性快照,因此資料迭代器無法在搶占前後載入相同資料。
檢查點
Orbax 檢查點程式庫提供基本元素,可將 JAX PyTree 檢查點儲存至本機儲存空間或 Google Cloud 儲存空間。我們在 checkpointing.py 中提供參考整合,將同步檢查點納入 MaxText。
支援的設定
以下各節說明 Multislice 支援的切片形狀、協調、架構和平行處理。
形狀
所有切片必須為相同形狀 (例如相同的 AcceleratorType)。系統不支援形狀不同的切片。
自動化調度管理
GKE 支援自動化調度管理。詳情請參閱「GKE 中的 TPU」。
架構
Multislice 僅支援 JAX 和 PyTorch 工作負載。
平行處理工作數量
建議使用者透過資料平行處理測試 Multislice。如要進一步瞭解如何透過 Multislice 實作管道平行處理,請與Google Cloud 帳戶代表聯絡。
支援和意見回饋
歡迎提供任何意見!如要分享意見回饋或要求支援,請使用 Cloud TPU 支援或意見回饋表單與我們聯絡。