Cloud TPU 멀티슬라이스 개요
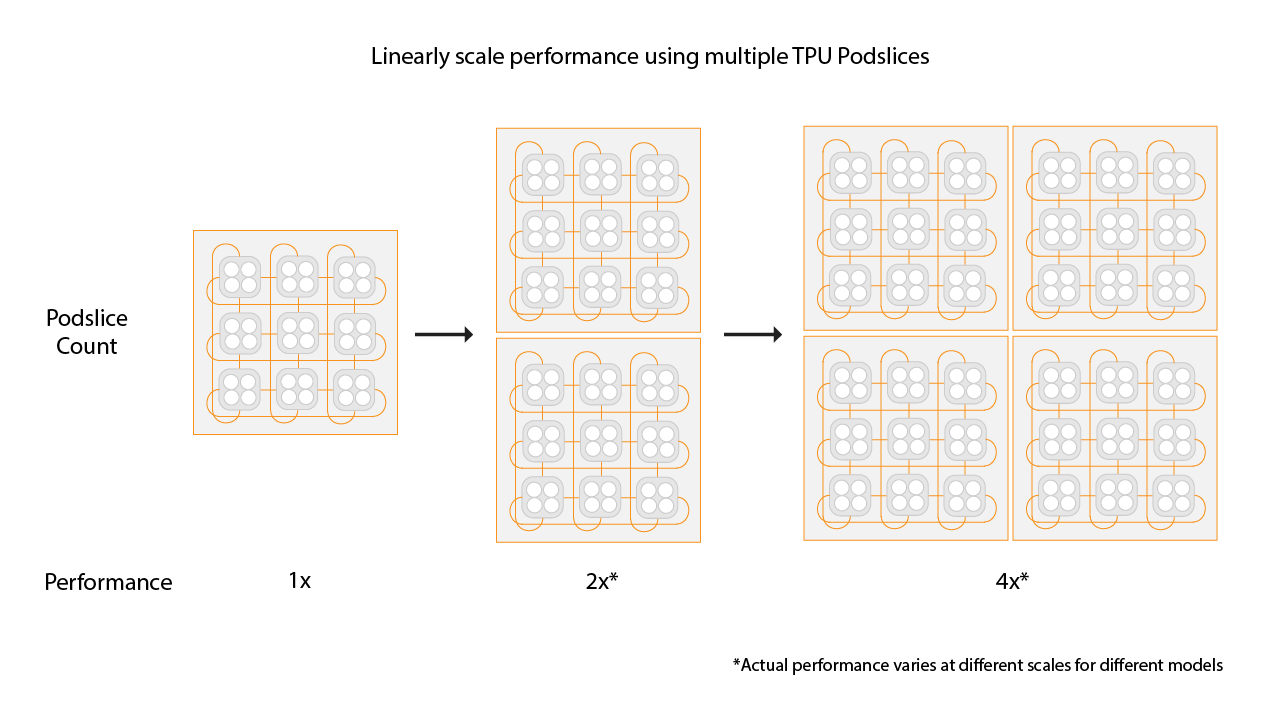
Cloud TPU 멀티슬라이스는 학습 작업이 단일 슬라이스 내에서 또는 표준 데이터 동시 로드를 사용하는 여러 포드의 슬라이스에서 여러 TPU 슬라이스를 사용할 수 있도록 하는 풀 스택 성능 확장 기술입니다. TPU v4 칩을 사용하면 학습 작업에서 단일 실행에 4,096개가 넘는 칩을 사용할 수 있습니다. 4,096개보다 적은 칩이 필요한 학습 작업의 경우 단일 슬라이스가 최상의 성능을 제공합니다. 그러나 작은 슬라이스 여러 개가 있는 경우 더 신속하게 사용할 수 있으므로 멀티슬라이스를 작은 슬라이스로 사용하면 시작 시간이 빨라집니다.
멀티 슬라이스 구성에 배포된 경우 각 슬라이스의 TPU 칩은 칩-상호 연결(ICI)을 통해 통신합니다. 서로 다른 슬라이스의 TPU 칩은 CPU(호스트)로 데이터를 전송하여 통신한 후 데이터 센터 네트워크(DCN)를 통해 데이터를 전송합니다. 멀티슬라이스를 사용한 확장에 관한 자세한 내용은 멀티슬라이스를 사용하여 AI 학습을 최대 수만 개의 Cloud TPU 칩으로 확장하는 방법을 참조하세요.
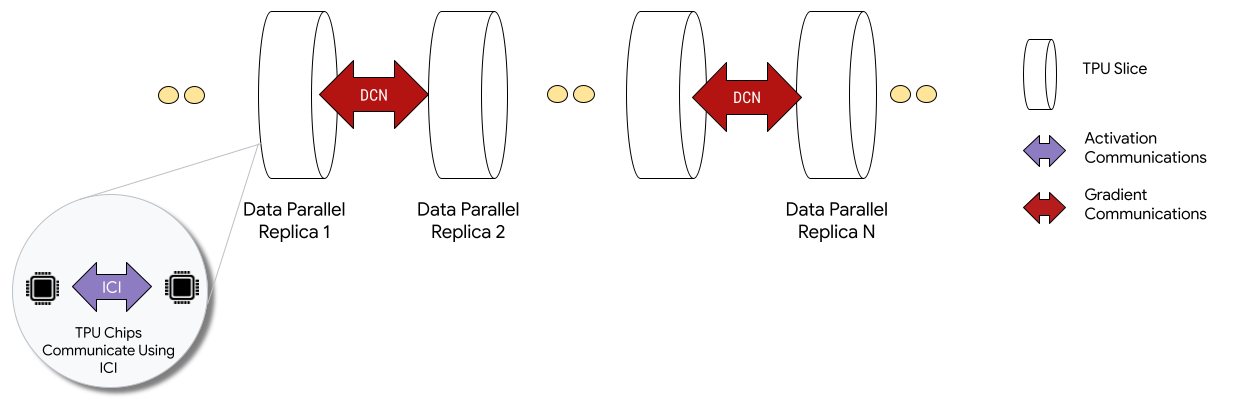
개발자는 슬라이스 간 DCN 통신을 구현하기 위해 코드를 작성할 필요가 없습니다. XLA 컴파일러는 해당 코드를 생성하고 최대 성능을 위해 계산을 통신과 겹칩니다.
개념
- 가속기 유형
- 멀티슬라이스로 구성된 각 TPU 슬라이스의 형태입니다. 멀티슬라이스 요청의 각 슬라이스는 동일한 가속기 유형입니다. 가속기 유형은 TPU 유형(v4 이상)과 TensorCore 수로 구성됩니다.
예를 들어
v5litepod-128은 TensorCore 128개가 있는 TPU v5e를 지정합니다. - 자동 복구
- 슬라이스에서 유지보수 이벤트, 선점 또는 하드웨어 고장이 발생하면 Cloud TPU가 새 슬라이스를 만듭니다. 새 슬라이스를 만들기 위한 리소스가 부족하면 하드웨어를 사용할 수 있을 때까지 생성이 완료되지 않습니다. 새 슬라이스가 생성되면 멀티슬라이스 환경의 다른 모든 슬라이스가 다시 시작되므로 학습이 계속됩니다. 시작 스크립트를 올바르게 구성하면 사용자 개입 없이 최신 체크포인트에서 로드 및 재개하여 학습 스크립트를 자동으로 다시 실행할 수 있습니다.
- 데이터 센터 네트워킹(DCN)
- 멀티슬라이스 구성에서 TPU 슬라이스를 연결하는(ICI와 비교할 때) 지연 시간이 길고 처리량이 낮은 네트워크입니다.
- 갱(Gang) 예약
- 모든 TPU 슬라이스가 동시에 프로비저닝되면 슬라이스가 모두 성공적으로 프로비저닝되거나 하나도 프로비저닝되지 않도록 보장합니다.
- 칩 간 상호 연결(ICI)
- TPU Pod 내에서 TPU를 연결하는 속도가 빠르고 지연 시간이 짧은 내부 링크입니다.
- 멀티슬라이스
- DCN을 통해 통신할 수 있는 2개 이상의 TPU 칩 슬라이스입니다.
- 노드
- 멀티슬라이스 컨텍스트에서 노드는 단일 TPU 슬라이스를 나타냅니다. 멀티슬라이스의 각 TPU 슬라이스에는 노드 ID가 할당됩니다.
- 시작 스크립트
- VM이 부팅되거나 재부팅될 때마다 실행되는 표준 Compute Engine 시작 스크립트입니다. 멀티슬라이스의 경우 QR 생성 요청에 지정됩니다. Cloud TPU 시작 스크립트에 대한 자세한 내용은 TPU 리소스 관리를 참조하세요.
- Tensor
- 머신러닝 모델에서 다차원 데이터를 나타내는 데 사용되는 데이터 구조입니다.
- Cloud TPU 용량 유형
TPU는 다양한 유형의 용량으로 만들 수 있습니다(TPU 가격 책정 방식의 사용 옵션 참조).
예약: 예약을 사용하려면 Google과 예약 계약이 있어야 합니다. 리소스를 만들 때
--reserved플래그를 사용합니다.스팟: 스팟 VM을 사용해서 선점형 할당량을 대상으로 합니다. 우선순위가 더 높은 작업을 요청하기 위한 공간을 확보하기 위해 리소스가 선점될 수도 있습니다. 리소스를 만들 때
--spot플래그를 사용합니다.주문형: 예약이 필요하지 않고 선점되지 않는 주문형 할당량을 대상으로 합니다. TPU 요청은 Cloud TPU에서 제공하는 주문형 할당량 큐에 추가되며 리소스의 가용성은 보장되지 않습니다. 기본적으로 선택되어 있으며 플래그는 필요하지 않습니다.
시작하기
-
-
In the API Console, activate Cloud Shell.
At the bottom of the API Console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
ici_data_parallelismici_fsdp_parallelismici_tensor_parallelism환경 설정:
$ gcloud auth login $ export QR_ID=your-queued-resource-id $ export TPU_NAME=your-tpu-name $ export PROJECT=your-project-name $ export ZONE=us-central1-a $ export NETWORK_NAME=your-network-name $ export SUBNETWORK_NAME=your-subnetwork-name $ export RUNTIME_VERSION=v2-alpha-tpuv5-lite $ export ACCELERATOR_TYPE=v5litepod-16 $ export EXAMPLE_TAG_1=your-tag-1 $ export EXAMPLE_TAG_2=your-tag-2 $ export SLICE_COUNT=4 $ export STARTUP_SCRIPT='#!/bin/bash\n'
변수 설명
입력 설명 QR_ID 큐에 추가된 리소스 요청의 사용자 할당 ID입니다. TPU_NAME TPU의 사용자 할당 이름입니다. 프로젝트 Google Cloud 프로젝트 이름 ZONE 리소스를 만들 영역을 지정합니다. NETWORK_NAME VPC 네트워크 이름 SUBNETWORK_NAME VPC 네트워크의 서브넷 이름 RUNTIME_VERSION Cloud TPU 소프트웨어 버전입니다. ACCELERATOR_TYPE v4-16 EXAMPLE_TAG_1, EXAMPLE_TAG_2 … 태그는 네트워크 방화벽의 유효한 소스 또는 대상을 식별하는 데 사용됩니다. SLICE_COUNT 슬라이스 수입니다. 최대 256개의 슬라이스로 제한됩니다. STARTUP_SCRIPT 시작 스크립트를 지정하면 TPU 슬라이스가 프로비저닝되거나 다시 시작될 때 스크립트가 실행됩니다. gcloud의 SSH 키를 만듭니다. 빈 비밀번호를 그대로 두는 것이 좋습니다(다음 명령어를 실행한 후 Enter 키를 두 번 누릅니다).google_compute_engine파일이 이미 있다는 메시지가 표시되면 기존 버전을 바꿉니다.$ ssh-keygen -f ~/.ssh/google_compute_engine
TPU를 프로비저닝합니다.
gcloud
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-id=${TPU_NAME} \ --zone=${ZONE} \ [--reserved |--spot]
Google Cloud CLI에서는 태그와 같은 모든 QR 만들기 옵션이 지원되지 않습니다. 자세한 내용은 QR 만들기를 참조하세요.
콘솔
Google API 콘솔에서 TPU 페이지로 이동합니다.
TPU 만들기를 클릭합니다.
이름 필드에 TPU의 이름을 입력합니다.
영역 상자에서 TPU를 만들 영역을 선택합니다.
TPU 유형 상자에서 가속기 유형을 선택합니다. 가속기 유형은 만들려는 Cloud TPU의 버전과 크기를 지정합니다. 각 TPU 버전에서 지원되는 가속기 유형에 대한 자세한 내용은 TPU 버전을 참조하세요.
TPU 소프트웨어 버전 상자에서 소프트웨어 버전을 선택합니다. Cloud TPU VM을 만들 때 TPU 소프트웨어 버전은 설치할 TPU 런타임 버전을 지정합니다. 자세한 내용은 TPU 소프트웨어 버전을 참조하세요.
큐 사용 설정 전환 버튼을 클릭합니다.
큐에 추가된 리소스 이름 필드에 큐에 추가된 리소스 요청의 이름을 입력합니다.
만들기를 클릭하여 큐에 추가된 리소스 요청을 만듭니다.
큐에 추가된 리소스(QR)가
ACTIVE상태가 될 때까지 기다린 후 워커 노드가READY상태가 될 때까지 기다립니다. 큐에 추가된 리소스 프로비저닝이 시작되면 큐에 추가된 리소스의 크기에 따라 완료하는 데 1~5분 정도 걸릴 수 있습니다. gcloud CLI 또는 Google API 콘솔을 사용하여 큐에 추가된 리소스 요청의 상태를 확인할 수 있습니다.gcloud
$ gcloud compute tpus queued-resources \ list --filter=${QR_ID} --zone=${ZONE}
콘솔
Google API 콘솔에서 TPU 페이지로 이동합니다.
큐에 추가된 리소스 탭을 클릭합니다.
큐에 추가된 리소스 요청의 이름을 클릭합니다.
SSH를 사용하여 TPU VM에 연결:
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} --zone=${ZONE}
MaxText(
shardings.py포함)를 TPU VM에 클론합니다.$ git clone https://github.com/AI-Hypercomputer/maxtext && cd maxtext
Python 3.10 설치:
$ sudo apt-get update $ sudo apt install python3.10 $ sudo apt install python3.10-venv
가상 환경을 만들고 활성화합니다.
$ python3 -m venv your-venv-name $ source your-venv-name/bin/activate
MaxText 저장소 디렉터리 내에서 설정 스크립트를 실행하여 TPU 슬라이스에 JAX 및 기타 종속 항목을 설치합니다. 설정 스크립트를 실행하는 데 몇 분 정도 걸립니다.
$ bash setup.sh
다음 명령어를 실행하여 TPU 슬라이스에서
shardings.py를 실행합니다.$ python3 -m pedagogical_examples.shardings \ --ici_fsdp_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
로그에서 결과를 확인할 수 있습니다. TPU는 초당 약 260 TFLOP 또는 90%이상의 놀라운 FLOP 사용률을 달성해야 합니다! 이 경우 TPU의 고대역폭 메모리(HBM)에 맞는 최대 배치를 선택했습니다.
ICI를 통한 다른 샤딩 전략을 살펴보세요. 예를 들어 다음과 같은 조합을 사용할 수 있습니다.
$ python3 -m pedagogical_examples.shardings \ --ici_tensor_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
완료되면 큐에 추가된 리소스와 TPU 슬라이스를 삭제합니다. 슬라이스를 설정한 환경에서 삭제 단계를 실행해야 합니다. 먼저
exit를 실행하여 SSH 세션을 종료합니다. 삭제를 완료하는 데 2~5분 정도 걸립니다. gcloud CLI를 사용하는 경우 선택사항인--async플래그를 사용하여 백그라운드에서 이 명령어를 실행할 수 있습니다.gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --force (--async)
콘솔
Google API 콘솔에서 TPU 페이지로 이동합니다.
큐에 추가된 리소스 탭을 클릭합니다.
큐에 추가된 리소스 요청 옆에 있는 체크박스를 선택합니다.
삭제를 클릭합니다.
- dcn_data_parallelism
- dcn_fsdp_parallelism
- dcn_tensor_parallelism
실행기 머신에서 MaxText를 클론합니다.
$ git clone https://github.com/AI-Hypercomputer/maxtext
저장소 디렉터리로 이동합니다.
$ cd maxtext
gcloud의 SSH 키를 만들려면 빈 비밀번호를 그대로 두는 것이 좋습니다(다음 명령어를 실행한 후 Enter 키를 두 번 누릅니다).google_compute_engine파일이 이미 있다는 메시지가 표시되면 기존 버전을 유지하지 않도록 선택합니다.$ ssh-keygen -f ~/.ssh/google_compute_engine
환경 변수를 추가하여 TPU 슬라이스 수를
2로 설정합니다.$ export SLICE_COUNT=2
queued-resources create명령어나 Google API 콘솔을 사용하여 멀티슬라이스 환경을 만듭니다.gcloud
다음 명령어는 v5e 멀티슬라이스 TPU를 만드는 방법을 보여줍니다. 다른 TPU 버전을 사용하려면 다른
accelerator-type및runtime-version을 지정합니다.$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-count=${SLICE_COUNT} \ --node-prefix=${TPU_NAME} \ --zone=${ZONE} \ [--reserved|--spot]
콘솔
Google API 콘솔에서 TPU 페이지로 이동합니다.
TPU 만들기를 클릭합니다.
이름 필드에 TPU의 이름을 입력합니다.
영역 상자에서 TPU를 만들 영역을 선택합니다.
TPU 유형 상자에서 가속기 유형을 선택합니다. 가속기 유형은 만들려는 Cloud TPU의 버전과 크기를 지정합니다. 멀티슬라이스는 Cloud TPU v4 이상 TPU 버전에서만 지원됩니다. TPU 버전에 관한 자세한 내용은 TPU 버전을 참조하세요.
TPU 소프트웨어 버전 상자에서 소프트웨어 버전을 선택합니다. Cloud TPU VM을 만들 때 TPU 소프트웨어 버전은 TPU VM에 설치할 TPU 런타임 버전을 지정합니다. 자세한 내용은 TPU 소프트웨어 버전을 참조하세요.
큐 사용 설정 전환 버튼을 클릭합니다.
큐에 추가된 리소스 이름 필드에 큐에 추가된 리소스 요청의 이름을 입력합니다.
멀티슬라이스 TPU로 만들기 체크박스를 클릭합니다.
슬라이스 수 필드에 만들려는 슬라이스 수를 입력합니다.
만들기를 클릭하여 큐에 추가된 리소스 요청을 만듭니다.
큐에 추가된 리소스 프로비저닝이 시작되면 큐에 추가된 리소스의 크기에 따라 완료하는 데 최대 5분이 걸릴 수 있습니다. 큐에 추가된 리소스가
ACTIVE상태가 될 때까지 기다립니다. gcloud CLI 또는 Google API 콘솔을 사용하여 큐에 추가된 리소스 요청의 상태를 확인할 수 있습니다.gcloud
$ gcloud compute tpus queued-resources list \ --filter=${QR_ID} --zone=${ZONE} --project=${PROJECT}
다음과 같은 출력이 생성되어야 합니다.
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central2-b 4 v5litepod-16 ACTIVE ...
콘솔
Google API 콘솔에서 TPU 페이지로 이동합니다.
큐에 추가된 리소스 탭을 클릭합니다.
큐에 추가된 리소스 요청의 이름을 클릭합니다.
QR 상태가 15분 넘게
WAITING_FOR_RESOURCES또는PROVISIONING상태이면 Google Cloud 계정 담당자에게 문의하세요.종속 항목을 설치합니다.
$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="bash setup.sh"
multihost_runner.py를 사용하여 각 작업자에서shardings.py를 실행합니다.$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="python3 -m pedagogical_examples.shardings \ --dcn_data_parallelism ${SLICE_COUNT} \ --ici_fsdp_parallelism 16 \ --batch_size 131072 \ --embedding_dimension 2048"
로그 파일에 초당 약 230개의 TFLOPS 성능이 표시됩니다.
동시 로드 구성에 관한 자세한 내용은 DCN 동시 로드를 사용한 멀티슬라이스 샤딩 및
shardings.py를 참조하세요.완료되면 TPU와 큐에 추가된 리소스를 삭제합니다. 삭제가 완료되는 데 2~5분 정도 걸립니다. gcloud CLI를 사용하는 경우 선택사항인
--async플래그를 사용하여 백그라운드에서 이 명령어를 실행할 수 있습니다.- 메시를 만들 때 jax.experimental.mesh_utils.create_device_mesh대신 jax.experimental.mesh_utils.create_hybrid_device_mesh를 사용합니다.
- 실험 실행기 스크립트
multihost_runner.py사용 - 프로덕션 실행기 스크립트
multihost_job.py사용 - 수동 방식 사용
다음 명령어를 사용하여 큐에 추가된 리소스 요청을 만듭니다.
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --project=${PROJECT} \ --zone=${ZONE} \ --node-count=${SLICE_COUNT} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --network=${NETWORK_NAME} \ --subnetwork=${SUBNETWORK_NAME} \ --tags=${EXAMPLE_TAG_1},${EXAMPLE_TAG_2} \ --metadata=startup-script="${STARTUP_SCRIPT}" \ [--reserved|--spot]
queued-resource-req.json파일을 만들고 이 파일에 다음 JSON을 복사합니다.{ "guaranteed": { "reserved": true }, "tpu": { "node_spec": [ { "parent": "projects/your-project-number/locations/your-zone", "node": { "accelerator_type": "accelerator-type", "runtime_version": "tpu-vm-runtime-version", "network_config": { "network": "your-network-name", "subnetwork": "your-subnetwork-name", "enable_external_ips": true }, "tags" : ["example-tag-1"] "metadata": { "startup-script": "your-startup-script" } }, "multi_node_params": { "node_count": slice-count, "node_id_prefix": "your-queued-resource-id" } } ] } }
다음 값을 바꿉니다.
- your-project-number: Google Cloud 프로젝트 번호.
- your-zone - 큐에 추가된 리소스를 만들려는 영역입니다.
- accelerator-type - 단일 슬라이스의 버전 및 크기입니다. 멀티슬라이스는 Cloud TPU v4 이상 TPU 버전에서만 지원됩니다.
- tpu-vm-runtime-version - 사용할 TPU VM 런타임 버전입니다.
- your-network-name - 큐에 추가된 리소스가 연결될 네트워크입니다(선택사항).
- your-subnetwork-name - 큐에 추가된 리소스가 연결될 서브네트워크입니다(선택사항).
- example-tag-1 - 임의 태그 문자열입니다(선택사항).
- your-startup-script - 큐에 추가된 리소스가 할당될 때 실행되는 시작 스크립트입니다.
- slice-count - 멀티슬라이스 환경의 TPU 슬라이스 개수입니다.
- your-queued-resource-id - 사용자가 제공한 큐에 추가된 리소스의 ID입니다.
자세한 내용은 REST Queued Resource API 문서에서 사용 가능한 모든 옵션을 참조하세요.
스팟 용량을 사용하려면 다음을 바꿉니다.
"guaranteed": { "reserved": true }("spot": {}포함)기본 주문형 용량을 사용하려면 줄을 삭제합니다.
JSON 페이로드로 대기열에 추가된 리소스 만들기 요청을 제출합니다.
$ curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d @queuedresourcereq.json \ https://tpu.googleapis.com/v2alpha1/projects/your-project-id/locations/your-zone/queuedResources\?queued_resource_id\=your-queued-resource-id
다음 값을 바꿉니다.
- your-project-id: Google Cloud 프로젝트 ID입니다.
- your-zone - 큐에 추가된 리소스를 만들려는 영역입니다.
- your-queued-resource-id - 사용자가 제공한 큐에 추가된 리소스의 ID입니다.
Google API 콘솔에서 TPU 페이지로 이동합니다.
TPU 만들기를 클릭합니다.
이름 필드에 TPU의 이름을 입력합니다.
영역 상자에서 TPU를 만들 영역을 선택합니다.
TPU 유형 상자에서 가속기 유형을 선택합니다. 가속기 유형은 만들려는 Cloud TPU의 버전과 크기를 지정합니다. 멀티슬라이스는 Cloud TPU v4 이상 TPU 버전에서만 지원됩니다. 각 TPU 버전에서 지원되는 가속기 유형에 대한 자세한 내용은 TPU 버전을 참조하세요.
TPU 소프트웨어 버전 상자에서 소프트웨어 버전을 선택합니다. Cloud TPU VM을 만들 때 TPU 소프트웨어 버전은 설치할 TPU 런타임 버전을 지정합니다. 자세한 내용은 TPU 소프트웨어 버전을 참조하세요.
큐 사용 설정 전환 버튼을 클릭합니다.
큐에 추가된 리소스 이름 필드에 큐에 추가된 리소스 요청의 이름을 입력합니다.
멀티슬라이스 TPU로 만들기 체크박스를 클릭합니다.
슬라이스 수 필드에 만들려는 슬라이스 수를 입력합니다.
만들기를 클릭하여 큐에 추가된 리소스 요청을 만듭니다.
Google API 콘솔에서 TPU 페이지로 이동합니다.
큐에 추가된 리소스 탭을 클릭합니다.
큐에 추가된 리소스 요청의 이름을 클릭합니다.
Google API 콘솔에서 TPU 페이지로 이동합니다.
큐에 추가된 리소스 탭을 클릭합니다.
Google API 콘솔에서 TPU 페이지로 이동합니다.
큐에 추가된 리소스 탭을 클릭합니다.
큐에 추가된 리소스 요청 옆에 있는 체크박스를 선택합니다.
삭제를 클릭합니다.
- B는 토큰의 배치 크기입니다.
- P는 매개변수의 수입니다.
- 칩이 데이터를 대기 중이므로 유휴 상태인 '파이프라인 버블'이 발생합니다.
- 마이크로 배치가 필요하며, 이로 인해 유효 배치 크기, 산술 강도, 궁극적으로 모델 FLOP 사용률이 감소합니다.
멀티슬라이스를 사용하려면 TPU 리소스를 큐에 추가된 리소스로 관리해야 합니다.
소개 예시
이 튜토리얼에서는 MaxText GitHub 저장소의 코드를 사용합니다. MaxText는 Python 및 Jax로 작성된 고성능의 임의 확장 가능한 오픈소스이자 잘 테스트된 기본 LLM입니다. MaxText는 Cloud TPU에서 효율적으로 학습하도록 설계되었습니다.
shardings.py의 코드는 다양한 동시 로드 옵션을 실험해 볼 수 있도록 설계되었습니다. 예를 들어 데이터 동시 로드, 완전히 샤딩된 데이터 동시 로드(FSDP), 텐서 동시 로드가 있습니다. 코드는 단일 슬라이스에서 멀티 슬라이스 환경으로 확장됩니다.
ICI 동시 로드
ICI는 단일 슬라이스에서 TPU를 연결하는 고속 상호 연결을 의미합니다. ICI 샤딩은 슬라이스 내 샤딩에 해당합니다. shardings.py는 세 가지 ICI 동시 로드 매개변수를 제공합니다.
이러한 매개변수에 지정하는 값은 각 동시 로드 메서드의 샤드 수를 결정합니다.
ici_data_parallelism * ici_fsdp_parallelism * ici_tensor_parallelism이 슬라이스의 칩 수와 같도록 이러한 입력을 제한해야 합니다.
다음 표에서는 v4-8에서 사용 가능한 4개 칩의 ICI 동시 로드에 대한 사용자 입력 예시를 보여줍니다.
| ici_data_parallelism | ici_fsdp_parallelism | ici_tensor_parallelism | |
| 4방향 FSDP | 1 | 4 | 1 |
| 4방향 텐서 동시 로드 | 1 | 1 | 4 |
| 2방향 FSDP + 2방향 텐서 동시 로드 | 1 | 2 | 2 |
ICI 네트워크는 거의 항상 데이터 동시 로드보다 FSDP를 선호할 만큼 빠르므로 ici_data_parallelism은 1로 둡니다.
이 예시에서는 JAX를 사용하여 Cloud TPU VM에서 계산 실행과 같은 단일 TPU 슬라이스의 코드 실행에 익숙하다고 가정합니다.
이 예시에서는 단일 슬라이스에서 shardings.py를 실행하는 방법을 보여줍니다.
DCN 동시 로드를 사용한 멀티슬라이스 샤딩
shardings.py 각 데이터 동시 로드 유형의 샤드 수에 해당하는 DCN 동시 로드를 지정하는 세 가지 매개변수를 사용합니다.
이러한 매개변수의 값은 dcn_data_parallelism * dcn_fsdp_parallelism * dcn_tensor_parallelism이 슬라이스 수와 같도록 제한해야 합니다.
두 개의 슬라이스를 예로 들면 --dcn_data_parallelism = 2를 사용합니다.
| dcn_data_parallelism | dcn_fsdp_parallelism | dcn_tensor_parallelism | 슬라이스 수 | |
| 양방향 데이터 동시 로드 | 2 | 1 | 1 | 2 |
DCN은 이러한 샤딩에 적합하지 않으므로 dcn_tensor_parallelism은 항상 1로 설정해야 합니다. v4 칩의 일반적인 LLM 워크로드의 경우 dcn_fsdp_parallelism도 1로 설정해야 하므로 dcn_data_parallelism은 슬라이스 수로 설정해야 하지만 애플리케이션에 따라 다릅니다.
슬라이스 수를 늘리면(슬라이스 크기 및 슬라이스당 배치는 일정하게 유지한다고 가정) 데이터 동시 로드 양이 증가합니다.
멀티슬라이스 환경에서 shardings.py 실행
multihost_runner.py를 사용하거나 각 TPU VM에서 shardings.py를 실행하여 멀티슬라이스 환경에서 shardings.py를 실행할 수 있습니다. 여기서는 multihost_runner.py를 사용합니다. 다음 단계는 train.py의 더 복잡한 LLM 대신 shardings.py를 실행한다는 점을 제외하고 MaxText 저장소의 시작하기: 여러 슬라이스에 빠른 실험의 단계와 매우 유사합니다.
multihost_runner.py 도구는 동일한 TPU를 반복적으로 재사용하는 빠른 실험에 최적화되어 있습니다. multihost_runner.py 스크립트는 장기 SSH 연결에 따라 달라지므로 장기 실행 작업에는 사용하지 않는 것이 좋습니다.
몇 시간 또는 며칠이 걸리는 더 긴 작업을 실행하려면 multihost_job.py를 사용하는 것이 좋습니다.
이 튜토리얼에서는 실행기라는 용어를 사용하여 multihost_runner.py 스크립트를 실행하는 머신을 나타냅니다. 슬라이스를 구성하는 TPU VM을 나타내는 용어로 작업자를 사용합니다. 로컬 머신 또는 슬라이스와 동일한 프로젝트에 있는 모든 Compute Engine VM에서 multihost_runner.py를 실행할 수 있습니다. multihost_runner.py를 작업자에서 실행하는 것은 지원되지 않습니다.
multihost_runner.py는 SSH를 통해 TPU 작업자에 자동으로 연결합니다.
이 예시에서는 2개의 v5e-16 슬라이스, 총 4개의 VM과 16개의 TPU 칩에 대해 shardings.py를 실행합니다. 더 많은 TPU에서 실행되도록 예시를 수정할 수 있습니다.
환경 설정
멀티슬라이스로 워크로드 확장
멀티슬라이스 환경에서 모델을 실행하기 전에 다음 코드를 변경합니다.
멀티슬라이스로 이동할 때 다음 코드 변경만 필요합니다. 높은 성능을 달성하려면 DCN을 데이터 동시 로드, 완전 샤딩된 데이터 동시 로드 또는 파이프라인 동시 로드 축에 매핑해야 합니다. 성능 고려사항과 샤딩 전략은 최고의 성능을 위해 멀티슬라이스로 샤딩에 자세히 설명되어 있습니다.
코드가 모든 기기에 액세스할 수 있는지 검사하려면 len(jax.devices())이 멀티슬라이스 환경의 칩 수와 동일하다고 어설션하면 됩니다. 예를 들어 v4-16의 슬라이스 4개를 사용하는 경우 슬라이스당 8개의 칩*이 있고 슬라이스가 4개 있으므로 len(jax.devices())은 32를 반환해야 합니다.
멀티슬라이스 환경의 슬라이스 크기 선택
선형 속도를 높이려면 기존 슬라이스와 동일한 크기의 새 슬라이스를 추가합니다. 예를 들어 v4-512 슬라이스를 사용하는 경우 멀티슬라이스는 두 번째 v4-512 슬라이스를 추가하고 전역 배치 크기를 두 배로 늘려 약 두 배의 성능을 달성합니다. 자세한 내용은 최고의 성능을 위해 멀티슬라이스로 샤딩을 참조하세요.
여러 슬라이스에서 작업 실행
멀티슬라이스 환경에서 커스텀 워크로드를 실행하는 방법에는 다음 세 가지가 있습니다.
실험 실행기 스크립트
multihost_runner.py 스크립트는 기존 멀티슬라이스 환경에 코드를 배포하고 각 호스트에서 명령어를 실행하고 로그를 다시 복사하고 각 명령어의 오류 상태를 추적합니다. multihost_runner.py 스크립트는 MaxText 리드미에 설명되어 있습니다.
multihost_runner.py는 영구 SSH 연결을 유지하므로 적당한 규모의 비교적 짧은 실험에만 적합합니다. multihost_runner.py 튜토리얼의 단계를 워크로드 및 하드웨어 구성에 적용할 수 있습니다.
프로덕션 실행기 스크립트
하드웨어 오류 및 기타 선점에 대한 복원력이 필요한 프로덕션 작업의 경우 Create Queued Resource API와 직접 통합하는 것이 가장 좋습니다. 적절한 시작 스크립트로 Queued Resource API 호출을 트리거하여 학습을 실행하고 선점 시 재개하는 multihost_job.py를 작업 예시로 사용하세요. multihost_job.py 스크립트는 MaxText 리드미에 설명되어 있습니다.
multihost_job.py는 실행할 때마다 리소스를 프로비저닝해야 하므로 multihost_runner.py만큼 빠른 반복 주기를 제공하지 않습니다.
수동 방식
multihost_runner.py 또는 multihost_job.py를 사용하거나 조정하여 멀티슬라이스 구성에서 커스텀 워크로드를 실행하는 것이 좋습니다. 그러나 QR 명령어를 사용하여 환경을 직접 프로비저닝하고 관리하려면 멀티슬라이스 환경 관리를 참조하세요.
멀티슬라이스 환경 관리
MaxText 저장소에서 제공되는 도구를 사용하지 않고 QR을 수동으로 프로비저닝하고 관리하려면 다음 섹션을 참조하세요.
큐에 추가된 리소스 만들기
gcloud
--reserved, --spot 또는 기본 주문형 할당량을 선택하기 전에 해당 할당량이 있는지 확인하세요. 할당량 유형에 대한 자세한 내용은 할당량 정책을 참조하세요.
curl
다음과 같은 응답이 표시됩니다.
{ "name": "projects/<your-project-id>/locations/<your-zone>/operations/operation-<your-qr-guid>", "metadata": { "@type": "type.googleapis.com/google.cloud.common.OperationMetadata", "createTime": "2023-11-01T00:17:05.742546311Z", "target": "projects/<your-project-id>/locations/<your-zone>/queuedResources/<your-qa-id>", "verb": "create", "cancelRequested": false, "apiVersion": "v2alpha1" }, "done": false }
쿠에 추가된 리소스 요청에 대한 정보를 가져오려면 name 속성의 문자열 값 끝에 있는 GUID 값을 사용합니다.
콘솔
큐에 추가된 리소스의 상태 가져오기
gcloud
$ gcloud compute tpus queued-resources describe ${QR_ID} --zone=${ZONE}
ACTIVE 상태인 큐에 추가된 리소스의 출력은 다음과 같습니다.
...
state:
state: ACTIVE
...
curl
$ curl -X GET -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://tpu.googleapis.com/v2/projects/your-project-id/locations/your-zone/queuedResources/${YOUR_QR_ID}
ACTIVE 상태인 큐에 추가된 리소스의 출력은 다음과 같습니다.
{
"name": your-queued-res,
"tpu": {
"nodeSpec": [
{
... // node 1
},
{
... // node 2
},
...
]
},
...
"state": "ACTIVE"
}
콘솔
TPU가 프로비저닝된 후에는 TPU 페이지로 이동하여 TPU를 찾고 해당하는 큐에 추가된 리소스 요청의 이름을 클릭하여 큐에 추가된 리소스 요청에 관한 세부정보를 볼 수도 있습니다.
드문 경우지만, 일부 슬라이스가 ACTIVE일 때 큐에 추가된 리소스의 상태가 FAILED일 수 있습니다. 이 경우 생성된 리소스를 삭제하고 몇 분 후에 다시 시도하거나 Google Cloud 지원팀에 문의하세요.
SSH 및 설치 종속 항목
TPU 슬라이스에서 JAX 코드 실행에서는 SSH를 사용하여 단일 슬라이스에서 TPU VM에 연결하는 방법을 설명합니다. SSH를 통해 멀티슬라이스 환경의 모든 TPU VM에 연결하고 종속 항목을 설치하려면 다음 gcloud 명령어를 사용하세요.
$ gcloud compute tpus queued-resources ssh ${QR_ID} \ --zone=${ZONE} \ --node=all \ --worker=all \ --command="command-to-run" \ --batch-size=4
이 gcloud 명령어는 SSH를 사용하여 QR의 모든 작업자 및 노드에 지정된 명령어를 전송합니다. 명령어는 4개 그룹으로 일괄 처리되어 동시에 전송됩니다. 현재 배치가 실행을 완료하면 다음 명령어 배치가 전송됩니다. 명령어 중 하나에 오류가 발생하면 처리가 중지되고 추가 배치가 전송되지 않습니다. 자세한 내용은 큐에 추가된 리소스 API 참조를 확인하세요.
사용 중인 슬라이스 수가 로컬 컴퓨터의 스레딩 한도(일괄 처리 한도라고도 함)를 초과하면 교착 상태가 발생합니다. 예를 들어 로컬 머신의 일괄 처리 한도가 64라고 가정해봅니다. 64개가 넘는 슬라이스(예: 100개)에서 학습 스크립트를 실행하려고 하면 SSH 명령어가 슬라이스를 배치로 나눕니다. 이 스크립트는 64개의 슬라이스의 첫 번째 배치에서 학습 스크립트를 실행하고 나머지 36개 슬라이스 배치에서 스크립트를 실행하기 전에 스크립트가 완료될 때까지 기다립니다. 하지만 나머지 36개의 슬라이스가 스크립트 실행을 시작할 때까지 64개 슬라이스의 첫 번째 배치를 완료할 수가 없어서 교착 상태가 발생합니다.
이를 방지하려면 --command 플래그로 지정한 스크립트 명령어에 앰퍼샌드(&)를 추가하여 각 VM에서 백그라운드에서 학습 스크립트를 실행하면 됩니다. 이렇게 하면 슬라이스의 첫 번째 배치에서 학습 스크립트를 시작한 후 제어가 SSH 명령어로 즉시 돌아갑니다. 그런 다음 SSH 명령어는 나머지 36개의 슬라이스 배치에 대한 학습 스크립트 실행을 시작할 수 있습니다. 백그라운드에서 명령어를 실행할 때 stdout 및 stderr 스트림을 적절하게 파이핑해야 합니다. 동일한 QR 내에서 동시 로드를 늘리려면 --node 매개변수를 사용하여 특정 슬라이스를 선택하면 됩니다.
네트워크 설정
다음 단계를 실행하여 TPU 슬라이스가 서로 통신할 수 있는지 확인합니다.
각 슬라이스에 JAX를 설치합니다. 자세한 내용은 TPU 슬라이스에서 JAX 코드 실행을 참조하세요. len(jax.devices())이 멀티슬라이스 환경의 칩 수와 동일한지 확인합니다. 이렇게 하려면 각 슬라이스에서 다음을 실행합니다.
$ python3 -c 'import jax; print(jax.devices())'
v4-16의 슬라이스 4개로 이 코드를 실행하면 슬라이스당 8개의 칩과 4개의 슬라이스가 있으므로 jax.devices()는 총 32개의 칩(기기)을 반환해야 합니다.
큐에 추가된 리소스 나열
gcloud
queued-resources list 명령어를 사용하여 큐에 추가된 리소스의 상태를 볼 수 있습니다.
$ gcloud compute tpus queued-resources list --zone=${ZONE}
결과는 다음과 유사합니다.
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central1-a 4 v5litepod-16 ACTIVE ...
콘솔
프로비저닝된 환경에서 작업 시작
SSH를 통해 각 슬라이스의 모든 호스트에 연결하고 모든 호스트에서 다음 명령어를 실행하여 워크로드를 수동으로 실행할 수 있습니다.
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} \ --zone=${ZONE} \ --worker=all \ --command="command-to-run"
QR 재설정
ResetQueuedResource API를 사용하여 ACTIVE QR에서 모든 VM을 재설정할 수 있습니다. VM을 재설정하면 머신의 메모리가 강제로 삭제되고 VM이 초기 상태로 재설정됩니다. 로컬에 저장된 모든 데이터는 그대로 유지되며 초기화 후 시작 스크립트가 호출됩니다. ResetQueuedResource API는 모든 TPU를 다시 시작하려는 경우에 유용할 수 있습니다. 예를 들어 학습이 중단되고 모든 VM을 재설정하는 것이 디버깅보다 쉽습니다.
모든 VM 재설정은 동시 로드로 수행되며 ResetQueuedResource 작업이 완료되는 데 1~2분 정도 걸립니다. API를 호출하려면 다음 명령어를 사용합니다.
$ gcloud compute tpus queued-resources reset ${QR_ID} --zone=${ZONE}
큐에 추가된 리소스 삭제
학습 세션이 끝날 때 리소스를 해제하려면 큐에 추가된 리소스를 삭제합니다. 삭제가 완료되는 데 2~5분 정도 걸립니다. gcloud CLI를 사용하는 경우 선택사항인 --async 플래그를 사용하여 백그라운드에서 이 명령어를 실행할 수 있습니다.
gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --zone=${ZONE} --force [--async]
콘솔
장애 발생 시 자동 복구
서비스 중단이 발생하면 멀티슬라이스가 영향을 받는 슬라이스에 대한 개입 없이 복구하고 나중에 모든 슬라이스를 재설정합니다. 영향을 받는 슬라이스가 새 슬라이스로 바뀌고 나머지 정상 슬라이스는 재설정됩니다. 대체 슬라이스를 할당할 수 있는 용량이 없으면 학습이 중지됩니다.
중단 후 학습을 자동으로 재개하려면 마지막으로 저장된 체크포인트를 확인하고 로드하는 시작 스크립트를 지정해야 합니다. 시작 스크립트는 슬라이스가 재할당되거나 VM이 재설정될 때마다 자동으로 실행됩니다. QR 요청 API 만들기로 보내는 JSON 페이로드에 시작 스크립트를 지정합니다.
다음 시작 스크립트(QR 만들기에서 사용)를 사용하면 MaxText 학습 중에 장애를 자동으로 복구하고 Cloud Storage 버킷에 저장된 체크포인트에서 학습을 재개할 수 있습니다.
{
"tpu": {
"node_spec": [
{
...
"metadata": {
"startup-script": "#! /bin/bash \n pwd \n runuser -l user1 -c 'cd /home/user1/MaxText && python3 -m MaxText.train MaxText/configs/base.yml run_name=run_test_failure_recovery dcn_data_parallelism=4 ici_fsdp_parallelism=8 steps=10000 save_period=10 base_output_directory='gs://user1-us-central2'' EOF"
}
...
}
]
}
}
사용해 보기 전에 MaxText 저장소를 클론합니다.
프로파일링 및 디버깅
단일 슬라이스 및 멀티슬라이스 환경에서는 프로파일링이 동일합니다. 자세한 내용은 JAX 프로그램 프로파일링을 참조하세요
학습 최적화
다음 섹션에서는 멀티슬라이스 학습을 최적화하는 방법을 설명합니다.
최고의 성능을 위해 멀티슬라이스로 샤딩
멀티슬라이스 환경에서 최대 성능을 얻기 위해서는 여러 슬라이스를 샤딩하는 방법을 고려해야 합니다. 일반적으로 데이터 동시 로드, 완전히 샤딩된 데이터 동시 로드, 파이프라인 동시 로드와 같은 3가지 옵션이 있습니다. 슬라이스 간 대역폭이 너무 많이 필요하므로 모델 차원(텐서 동시 로드라고도 함)에 활성화를 샤딩하지 않는 것이 좋습니다. 이러한 모든 전략에서 이전에 효과가 있었던 슬라이스 내에 동일한 샤딩 전략을 유지할 수 있습니다.
순수한 데이터 동시 로드로 시작하는 것이 좋습니다. 완전 샤딩된 데이터 동시 로드를 사용하면 메모리 사용량을 확보하는 데 유용합니다. 슬라이스 간의 통신에 DCN 네트워크가 사용되어 워크로드 속도가 느려진다는 단점이 있습니다. 배치 크기를 기준으로 필요한 경우에만 파이프라인 동시 로드를 사용합니다(아래 분석 참조).
데이터 동시 로드를 사용해야 하는 경우
순수 데이터 동시 로드는 잘 실행되고 있는 워크로드가 있지만 여러 슬라이스에 걸쳐 확장하여 성능을 개선하려는 경우에 적합합니다.
여러 슬라이스에서 강력한 확장을 달성하려면 DCN에서 all-reduce를 실행하는 데 필요한 시간이 역방향 패스를 실행하는 데 필요한 시간보다 짧아야 합니다. DCN은 슬라이스 간 통신에 사용되며 워크로드 처리량을 제한하는 요소입니다.
각 v4 TPU 칩은 최대 275 * 1012FLOPS/초로 작동합니다.
TPU 호스트당 4개의 칩이 있으며 각 호스트의 최대 네트워크 대역폭은 50Gbps입니다.
즉, 산술 강도는 4 * 275 * 1012FLOPS/50Gbps = 22000FLOPS/비트입니다.
모델은 단계마다 각 매개변수에 32~64비트의 DCN 대역폭을 사용합니다. 2개의 슬라이스를 사용하면 모델은 32비트의 DCN 대역폭을 사용합니다. 3개 이상의 슬라이스를 사용하는 경우 컴파일러는 전체 셔플 전체 축소 작업을 수행합니다. 그러면 단계마다 각 매개변수에 최대 64비트의 DCN 대역폭을 사용합니다. 각 매개변수에 필요한 FLOPS의 양은 모델에 따라 다릅니다. 특히 Transformer 기반 언어 모델의 경우 정방향 및 역방향 전달에 필요한 FLOPS 수는 대략 6 * B * P입니다. 각 항목의 의미는 다음과 같습니다.
매개변수별 FLOPS 수는 6 * B이고 역방향 전달 중에 매개변수별 FLOPS 수는 4 * B입니다.
여러 슬라이스에서 강력하게 확장하려면 운영 강도가 TPU 하드웨어의 산술 강도를 초과해야 합니다. 작동 강도를 계산하려면 역방향 전달 중에 매개변수별 FLOPS 수를 단계별 매개변수당 네트워크 대역폭(비트)으로 나눕니다.Operational Intensity = FLOPSbackwards_pass / DCN bandwidth
따라서 Transformer 기반 언어 모델의 경우, 두 개의 슬라이스를 사용하는 경우 다음과 같습니다.Operational intensity = 4 * B / 32
슬라이스를 3개 이상 사용하는 경우에는 다음과 같습니다.Operational intensity = 4 * B/64
이는 Transformer 기반 언어 모델의 최소 배치 크기를 176,000에서 352,000 사이로 제안합니다. DCN 네트워크는 패킷을 간단하게 삭제할 수 있기 때문에 포드당 배치 크기가 350,000(포드 2개)에서 700,000개(여러 포드) 이상인 경우에만 데이터 동시 로드를 배포하여 상당한 오차 범위를 유지하는 것이 좋습니다.
다른 모델 아키텍처의 경우 프로파일러를 사용하여 타이밍을 지정하거나 FLOPS를 계산하여 슬라이스 당 역방향 전달의 런타임을 예측해야 합니다. 그런 다음 이를 예상 실행 시간과 비교하여 DCN을 통해 모두 줄이고 데이터 동시 로드가 적합한지 여부를 추정할 수 있습니다.
완전 샤딩된 데이터 동시 로드(FSDP)를 사용해야 하는 경우
완전 샤딩된 데이터 동시 로드(FSDP)는 데이터 동시 로드(노드 간 데이터 샤딩)와 노드 간 가중치 샤딩을 결합합니다. 정방향 전달과 역방향 전달의 각 작업에 대해 가중치가 모두 수집되어 각 슬라이스가 필요한 가중치를 갖도록 합니다. 전체 축소를 사용하여 경사를 동기화하는 대신 경사가 생성되는 대로 축소 분산됩니다. 이렇게 하면 각 슬라이스는 해당하는 가중치의 경사만 가져옵니다.
데이터 동시 로드와 마찬가지로 FSDP에서는 전역 배치 크기를 슬라이스 수에 따라 선형으로 조정해야 합니다. 슬라이스 수를 늘리면 FSDP에서 메모리 압력을 줄입니다. 이는 슬라이스당 가중치와 최적화 도구 상태가 감소하지만 이로 인해 네트워크 트래픽이 늘어나고 지연된 수집으로 인해 차단 가능성이 커지기 때문입니다.
실제로 슬라이스당 배치를 늘리거나, 역방향 전달 중에 재구체화를 최소화하기 위해 더 많은 활성화를 저장하거나, 신경망의 매개변수 수를 늘리는 경우 슬라이스 전체에 걸친 FSDP를 사용하는 것이 좋습니다.
FSDP의 전체 수집 및 전체 감소 작업은 DP의 작업과 유사하게 작동하므로 이전 섹션에서 설명한 것과 동일한 방법으로 FSDP 워크로드가 DCN 성능에 의해 제한되는지 확인할 수 있습니다.
파이프라인 동시 로드를 사용해야 하는 경우
파이프라인 동시 로드는 원하는 최대 배치 크기보다 큰 전역 배치 크기가 필요한 다른 병렬 처리 전략으로 고성능을 달성할 때 적합합니다. 파이프라인 동시 로드를 사용하면 파이프라인을 구성하는 슬라이스가 배치를 '공유'할 수 있습니다. 그러나 파이프라인 동시 로드에는 두 가지 중요한 단점이 있습니다.
파이프라인 동시 로드는 다른 동시 로드 전략에 너무 큰 전역 배치 크기가 필요한 경우에만 사용해야 합니다. 파이프라인 동시 로드를 시도하기 전에 고성능 FSDP를 달성하는 데 필요한 배치 크기에서 샘플별 수렴이 느려지는지 경험해 보는 것이 좋습니다. FSDP는 모델 FLOP 사용률이 높은 경향이 있지만 배치 크기가 커짐에 따라 샘플당 수렴이 느려지는 경우 파이프라인 동시 로드가 더 나은 선택일 수 있습니다. 대부분의 워크로드는 파이프라인 동시 로드의 이점을 얻지 못할 정도로 충분히 큰 배치 크기를 허용할 수 있지만 그렇지 않은 워크로드도 있을 수 있습니다.
파이프라인 동시 로드가 필요한 경우 데이터 동시 로드 또는 FSDP와 결합하는 것이 좋습니다. 이렇게 하면 DCN 지연 시간이 처리량에 미치는 영향이 줄어들 때까지 파이프라인별 일괄 처리 크기를 늘리면서 파이프라인 깊이를 최소화할 수 있습니다. 구체적으로, N개의 슬라이스가 있는 경우 깊이 2의 파이프라인과 데이터 동시 로드의 N/2 복제본, 깊이 4의 파이프라인과 데이터 동시 로드의 N/4 복제본을 고려하고, 파이프라인당 일괄 처리가 역방향 패스의 산술 뒤에 DCN 집합체를 숨길 수 있을 만큼 커질 때까지 같은 방식으로 계속 진행합니다. 이렇게 하면 파이프라인 동시 로드로 인해 발생하는 속도 저하를 최소화하면서 글로벌 배치 크기 제한을 초과하여 확장할 수 있습니다.
멀티슬라이스 권장사항
다음 섹션에서는 멀티슬라이스 학습 권장사항을 설명합니다.
데이터 로드 중
학습 중에 데이터 세트에서 배치를 반복적으로 로드하여 모델에 입력합니다. TPU의 작업량이 고갈되는 것을 방지하려면 호스트 간에 배치를 샤딩하는 효율적인 비동기 데이터 로더가 필요합니다. MaxText의 현재 데이터 로더는 각 호스트가 예시의 동일한 하위 집합을 로드하도록 합니다. 이 솔루션은 텍스트에 적합하지만 모델 내에서 다시 샤딩해야 합니다. 또한 MaxText는 아직 데이터 반복기가 선점 전후에 동일한 데이터를 로드할 수 있는 결정론적 스냅샷을 제공하지 않습니다.
체크포인트
Orbax 체크포인트 라이브러리는 JAX PyTrees를 로컬 스토리지 또는 Google Cloud 스토리지로 체크포인트하기 위한 기본 요소를 제공합니다.
checkpointing.py의 MaxText에 동기식 체크포인트를 사용하는 참조 통합을 제공합니다.
지원되는 구성
다음 섹션에서는 멀티슬라이스에 지원되는 슬라이스 도형, 오케스트레이션, 프레임워크, 동시 실행을 설명합니다.
도형
모든 슬라이스는 동일한 형태여야 합니다(예: 동일한 AcceleratorType). 이기종 슬라이스 형태는 지원되지 않습니다.
조정
GKE에서 조정이 지원됩니다. 자세한 내용은 GKE의 TPU를 참조하세요.
프레임워크
멀티슬라이스는 JAX 및 PyTorch 워크로드만 지원합니다.
동시 로드
사용자는 데이터 동시 로드로 멀티슬라이스를 테스트하는 것이 좋습니다. 멀티슬라이스로 파이프라인 동시 로드를 구현하는 방법에 대한 자세한 내용은Google Cloud 계정 담당자에게 문의하세요.
지원 및 의견
여러분의 모든 의견을 환영합니다. 의견을 공유하거나 지원을 요청하려면 Cloud TPU 지원 또는 의견 제출 양식을 사용하여 Google에 문의하세요.