Introducción a Cloud TPU
Las unidades de procesamiento tensorial (TPU) son circuitos integrados personalizados específicos de aplicaciones (ASIC) de Google que se utilizan para acelerar las cargas de trabajo de aprendizaje automático. Para obtener información más detallada sobre el hardware de TPU, consulta Arquitectura del sistema. Cloud TPU es un servicio web que pone las TPU a disposición como recursos de procesamiento escalables en Google Cloud.
Las TPU entrenan tus modelos de manera más eficiente con hardware diseñado para realizar operaciones de matrices grandes que suelen encontrarse en los algoritmos de aprendizaje automático. Las TPU tienen memoria de gran ancho de banda (HBM) en el chip, lo que te permite usar modelos y tamaños de lotes más grandes. Las TPU se pueden conectar en grupos llamados Pods que escalan verticalmente tus cargas de trabajo. con pocos cambios en el código o ninguno.
¿Cómo funciona?
Para entender cómo funcionan las TPU, es útil entender cómo otros aceleradores abordar los desafíos computacionales del entrenamiento de modelos de AA.
Cómo funciona una CPU
Una CPU es un procesador de uso general basado en la arquitectura de von Neumann. Eso significa que una CPU funciona con software y memoria, de la siguiente manera:
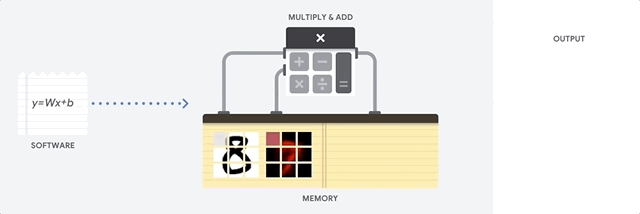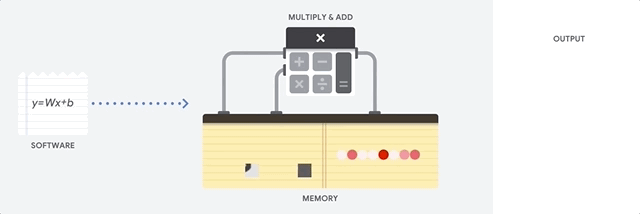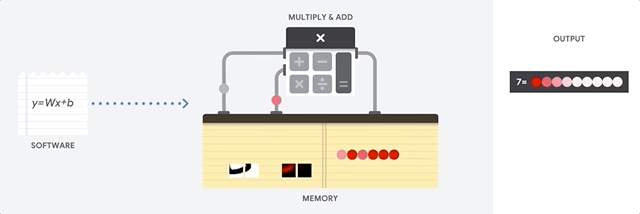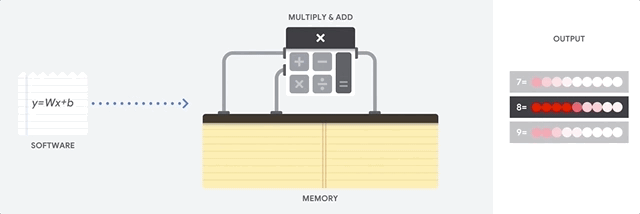
El mayor beneficio de las CPU es su flexibilidad. Puedes cargar cualquier tipo de software en una CPU para muchos tipos de aplicaciones diferentes. Por ejemplo, puedes usar una CPU para procesar textos en una PC, controlar motores de cohetes, ejecutar transacciones bancarias o clasificar imágenes con una red neuronal.
Una CPU carga valores de la memoria, realiza un cálculo en ellos y vuelve a almacenar el resultado en la memoria para cada cálculo. El acceso a la memoria es lento en comparación con la velocidad de cálculo y puede limitar la capacidad de procesamiento total de las CPU. Esto suele denominarse cuello de botella de von Neumann.
Cómo funciona una GPU
Para aumentar la capacidad de procesamiento, las GPUs contienen miles de unidades lógicas aritméticas (ALU) en un solo procesador. Una GPU moderna suele contener entre 2,500 y 5,000 ALU. La gran cantidad de procesadores permite ejecutar miles de multiplicaciones y sumas de manera simultánea.

Esta arquitectura de GPU funciona bien en aplicaciones con paralelismo masivo, como las operaciones de matrices en una red neuronal. De hecho, en una carga de trabajo de entrenamiento típica para el aprendizaje profundo, una GPU puede proporcionar un pedido de capacidad de procesamiento de magnitud mayor que una CPU.
Sin embargo, la GPU sigue siendo un procesador de propósito general que tiene que admitir muchas aplicaciones y software diferentes. Por lo tanto, las GPU tienen el mismo problema que y CPU virtuales. Para cada cálculo en miles de ALU, una GPU debe acceder registros o memoria compartida para leer operandos y almacenar el intermedio los resultados del cálculo.
Cómo funciona una TPU
Google diseñó Cloud TPU como un procesador matricial especializado para cargas de trabajo de redes neuronales. Las TPU no pueden ejecutar procesadores de texto, controlar motores de cohetes ni ejecutar de transacciones bancarias, pero pueden manejar operaciones matriciales masivas que se usan en redes a velocidades rápidas.
La tarea principal de las TPU es el procesamiento matricial, que es una combinación de operaciones de multiplicación y acumulación. Las TPU contienen miles de varios acumuladores que están directamente conectados entre sí para formar un gran matriz física. Esto se conoce como arquitectura de arreglo sistólico. Cloud TPU v3 contiene dos arreglos sistólicos de 128 x 128 ALU en un solo procesador.
El host de TPU transmite datos a una cola de entrada. La TPU carga datos del y los almacena en la memoria HBM. Cuando se completa el cálculo, la TPU carga los resultados en la cola de salida. Luego, el host de TPU lee el los resultados de la cola de salida y los almacena en la memoria del host.
Para realizar las operaciones matriciales, la TPU carga los parámetros de la memoria HBM en la unidad de multiplicación de matrices (MXU).

Luego, la TPU carga datos de la memoria HBM. A medida que se ejecuta cada multiplicación, el resultado se pasa al siguiente acumulador de multiplicación. La salida es la la suma de todos los resultados de multiplicación entre los datos y los parámetros. No se requiere acceso a la memoria durante el proceso de multiplicación de matrices.
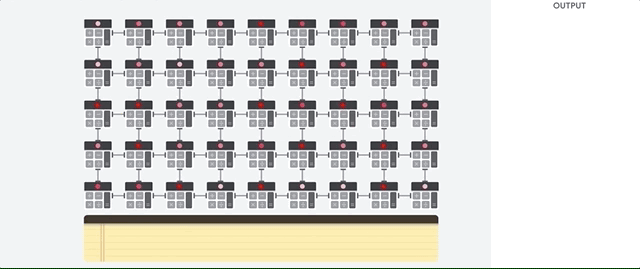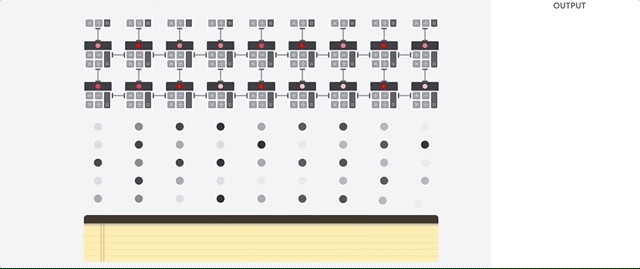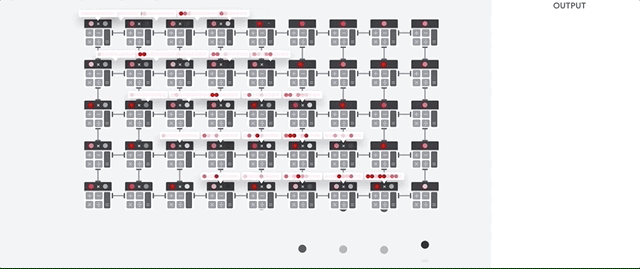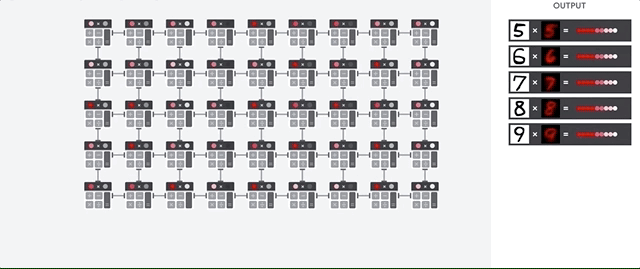
Como resultado, las TPU pueden lograr una alta capacidad de procesamiento computacional en la red neuronal realizar cálculos.
Compilador XLA
El compilador de álgebra lineal acelerada (XLA) debe compilar el código que se ejecuta en las TPU. XLA es un compilador justo a tiempo que toma el grafo emitido por una aplicación de framework de AA y compila los componentes de álgebra lineal, pérdida y gradiente del grafo en código máquina de TPU. El resto del programa se ejecuta en la máquina host de la TPU. XLA el compilador es parte de la imagen de VM de TPU que se ejecuta en una máquina anfitrión de TPU.
Cuándo conviene usar las TPU
Las Cloud TPU están optimizadas para ciertas cargas de trabajo en particular. En algunas situaciones, es posible usar GPU o CPU en instancias de Compute Engine para ejecutar de las cargas de trabajo de aprendizaje automático. En general, puedes decidir qué hardware se ajusta mejor a tu carga de trabajo según los siguientes lineamientos:
CPU
- Prototipado rápido que requiere máxima flexibilidad
- Modelos simples que no tardan mucho en entrenarse
- Modelos pequeños con tamaños de lotes efectivos pequeños
- Modelos que contienen muchas operaciones de TensorFlow personalizadas escritas en C++
- Modelos que están limitados por las E/S disponibles o el ancho de banda de red del sistema host
GPU
- Modelos con una cantidad significativa de operaciones personalizadas de TensorFlow/PyTorch/JAX que debe ejecutarse al menos parcialmente en CPU
- Modelos con operaciones de TensorFlow que no están disponibles en Cloud TPU (consulta la lista de operaciones de TensorFlow disponibles)
- Modelos medianos a grandes con tamaños de lotes efectivos más grandes
TPU
- Modelos dominados por cálculos de matrices
- Modelos sin operaciones personalizadas de TensorFlow/PyTorch/JAX dentro de la instancia principal bucle de entrenamiento
- Modelos que se entrenan por semanas o meses
- Modelos grandes con tamaños de lotes efectivos grandes
Las Cloud TPU no son apropiadas para las siguientes cargas de trabajo:
- Programas de álgebra lineal que requieren ramificaciones frecuentes o contienen muchas operaciones de álgebra a nivel de los elementos
- Cargas de trabajo que acceden a la memoria de manera dispersa
- Cargas de trabajo que requieren aritmética de alta precisión
- Cargas de trabajo de redes neuronales que contienen operaciones personalizadas en el ciclo de entrenamiento principal
Recomendaciones para el desarrollo del modelo
En cambio, es probable que un programa cuyos cálculos están dominados por operaciones no matriciales, como suma, cambio de forma o concatenación, no logre un uso alto de las MXU. Los siguientes son algunos lineamientos que te ayudarán a elegir y crear que son adecuados para Cloud TPU.
Diseño
El compilador de XLA realiza transformaciones de código, incluso dividir una multiplicación de matriz en bloques más pequeños a fin de ejecutar cálculos en la unidad matriz (MXU) de manera eficiente. Para garantizar la eficiencia de la división, el compilador de XLA emplea la estructura del hardware de las MXU, un arreglo sistólico de 128 x 128, y el diseño del subsistema de memoria de las TPU, que prefiere dimensiones que sean múltiplos de 8. En consecuencia, algunos diseños son más propicios para la división, mientras que otros requieren que se realicen cambios de forma antes de que puedan dividirse. Las operaciones de cambio de forma suelen depender de la memoria en Cloud TPU.
Formas
El compilador de XLA compila un grafo de AA justo a tiempo antes del primer lote. Si los lotes subsiguientes tienen formas diferentes, el modelo no funciona. (Se vuelve a compilar el gráfico cada vez que la forma cambia es demasiado lenta). Por lo tanto, cualquier modelo que tenga tensores con formas dinámicas no es adecuado para las TPU.
Relleno
Un programa de Cloud TPU de alto rendimiento es aquel en el que el procesamiento denso se puede dividir en mosaicos en fragmentos de 128 x 128. Cuando un cálculo de matriz no puede ocupar una MXU entera, el compilador rellena los tensores con ceros. El relleno presenta dos desventajas:
- Los tensores rellenos con ceros no usan el núcleo TPU lo suficiente.
- El relleno aumenta el tamaño del almacenamiento en la memoria del chip que necesita un tensor y puede llevar a un error de falta de memoria en casos extremos.
Aunque el compilador de XLA ejecuta operaciones de relleno automáticamente cuando es necesario, se puede determinar la cantidad de operaciones de relleno que se realizan mediante la herramienta op_profile. Puedes evitar el relleno si eliges dimensiones de tensor que se ajusten bien a las TPU.
Dimensiones
La elección de dimensiones de tensor adecuadas contribuye de manera considerable a extraer el máximo rendimiento del hardware de TPU, en particular las MXU. El compilador de XLA trata de usar el tamaño del lote o una dimensión de los atributos para usar las MXU al máximo. Por lo tanto, uno de estos debe ser un múltiplo de 128. Si no es así, el compilador rellenará uno de estos hasta que llegue a 128. Idealmente, tanto el tamaño del lote como la dimensión de los atributos deberían ser múltiplos de 8, lo que posibilita lograr un alto rendimiento en el subsistema de la memoria.
Integración de los Controles del servicio de VPC
Los Controles del servicio de VPC de Cloud TPU te permiten definir perímetros de seguridad alrededor de los recursos de Cloud TPU y controlar el movimiento de datos en el límite perimetral. Para obtener más información sobre los Controles del servicio de VPC, consulta la Descripción general de los Controles del servicio de VPC. Para conocer las limitaciones en el uso de Cloud TPU con los controles del servicio de VPC, consulta la página sobre los productos admitidos y las limitaciones.
Edge TPU
Los modelos de aprendizaje automático entrenados en la nube necesitan cada vez más ejecutar inferencias “en el perímetro”, es decir, en dispositivos que operan en el perímetro de la Internet de las cosas (IoT). Estos dispositivos incluyen sensores y otros dispositivos inteligentes que recopilan datos en tiempo real, toman decisiones inteligentes y, luego, toman medidas o comunican su información a otros dispositivos o a la nube.
Debido a que estos dispositivos deben funcionar con energía limitada (incluida la batería), Google diseñó el coprocesador Edge TPU para acelerar la inferencia del AA en dispositivos de bajo consumo. Una Edge TPU individual puede realizar 4 billones de operaciones por segundo (4 TOPS) con solo 2 vatios de potencia. En otras palabras, obtienes 2 TOPS por vatio. Por ejemplo, la Edge TPU puede ejecutar modelos de visión móvil de vanguardia, como MobileNet V2, a casi 400 fotogramas por segundo y de manera eficiente.
Este acelerador del AA de bajo consumo aumenta Cloud TPU y Cloud IoT para proporcionar una infraestructura de extremo a extremo (de hardware y software, de la nube al perímetro) que facilite las soluciones basadas en la IA.
Edge TPU está disponible para tus propios dispositivos de producción y prototipos en varios factores de forma, incluidas una computadora de una sola placa, un módulo en un módulo, una tarjeta PCIe/M.2 y un módulo activado en la superficie. Para obtener más información sobre Edge TPU y todos los productos disponibles, visita coral.ai.
Primeros pasos con Cloud TPU
- Configura una cuenta de Google Cloud
- Activa la API de Cloud TPU
- Otorga a Cloud TPU acceso a tus buckets de Cloud Storage
- Cómo ejecutar un cálculo básico en una TPU
- Entrena un modelo de referencia en una TPU
- Cómo analizar tu modelo
Cómo solicitar ayuda
Comunícate con el equipo de asistencia de Cloud TPU. Si tienes un proyecto activo de Google Cloud, prepárate para proporcionar la siguiente información:
- El ID del proyecto de Google Cloud
- El nombre de tu TPU, si existe
- Otra información que deseas proporcionar
Próximos pasos
¿Deseas aprender más sobre Cloud TPU? Los siguientes recursos pueden ayudarte: