Mit der Konsole Audioinhalte aus Text erstellen
In dieser Kurzanleitung wird die Cloud Text-to-Speech-Konsole vorgestellt. Sie erstellen hier Audioinhalte aus Text und erfahren, wie Sie diese Audioinhalte für Ihre eigenen Anwendungen wiedergeben, herunterladen und aktualisieren.
Weitere Informationen zu den grundlegenden Konzepten von Text-to-Speech finden Sie unter Grundlagen von Text-to-Speech.
Vorbereitung
Bevor Sie die Text-to-Speech-Konsole verwenden können, müssen Sie die API in der Google Cloud Console aktivieren. Die unten stehenden Schritte führen Sie durch die folgenden Aktionen:
- Text-to-Speech für ein Projekt aktivieren
- Prüfen, ob die Abrechnung für Text-to-Speech aktiviert ist
Google Cloud -Projekt einrichten
Seite zur Projektauswahl aufrufen
Sie können entweder ein vorhandenes Projekt auswählen oder ein neues erstellen. Weitere Informationen zum Erstellen eines Projekts finden Sie in der Google Cloud Platform-Dokumentation.
Wenn Sie ein neues Projekt erstellen, werden Sie aufgefordert, ein Rechnungskonto mit diesem Projekt zu verknüpfen. Wenn Sie ein bereits vorhandenes Projekt verwenden, muss die Abrechnung aktiviert sein.
Informationen dazu, wie Sie prüfen, ob die Abrechnung für Ihr Projekt aktiviert ist
Nachdem Sie ein Projekt ausgewählt und mit einem Rechnungskonto verknüpft haben, können Sie die Text-to-Speech API aktivieren. Öffnen Sie oben auf der Seite die Leiste Produkte und Ressourcen suchen und geben Sie „text-to-speech“ ein.
Wählen Sie aus der Liste der Ergebnisse die Cloud Text-to-Speech API aus.
Wenn Sie Text-to-Speech testen möchten, ohne es mit Ihrem Projekt zu verknüpfen, wählen Sie die Option DIESE API TESTEN aus. Klicken Sie auf AKTIVIEREN, um die Text-to-Speech API für die Verwendung mit Ihrem Projekt zu aktivieren.
Audio aus Text erstellen
Erstellen Sie mit der Google Cloud Console Audioinhalte aus Text:
Text oder SSML eingeben
Öffnen Sie die Text-to-Speech-Seite „Synthetisieren“.
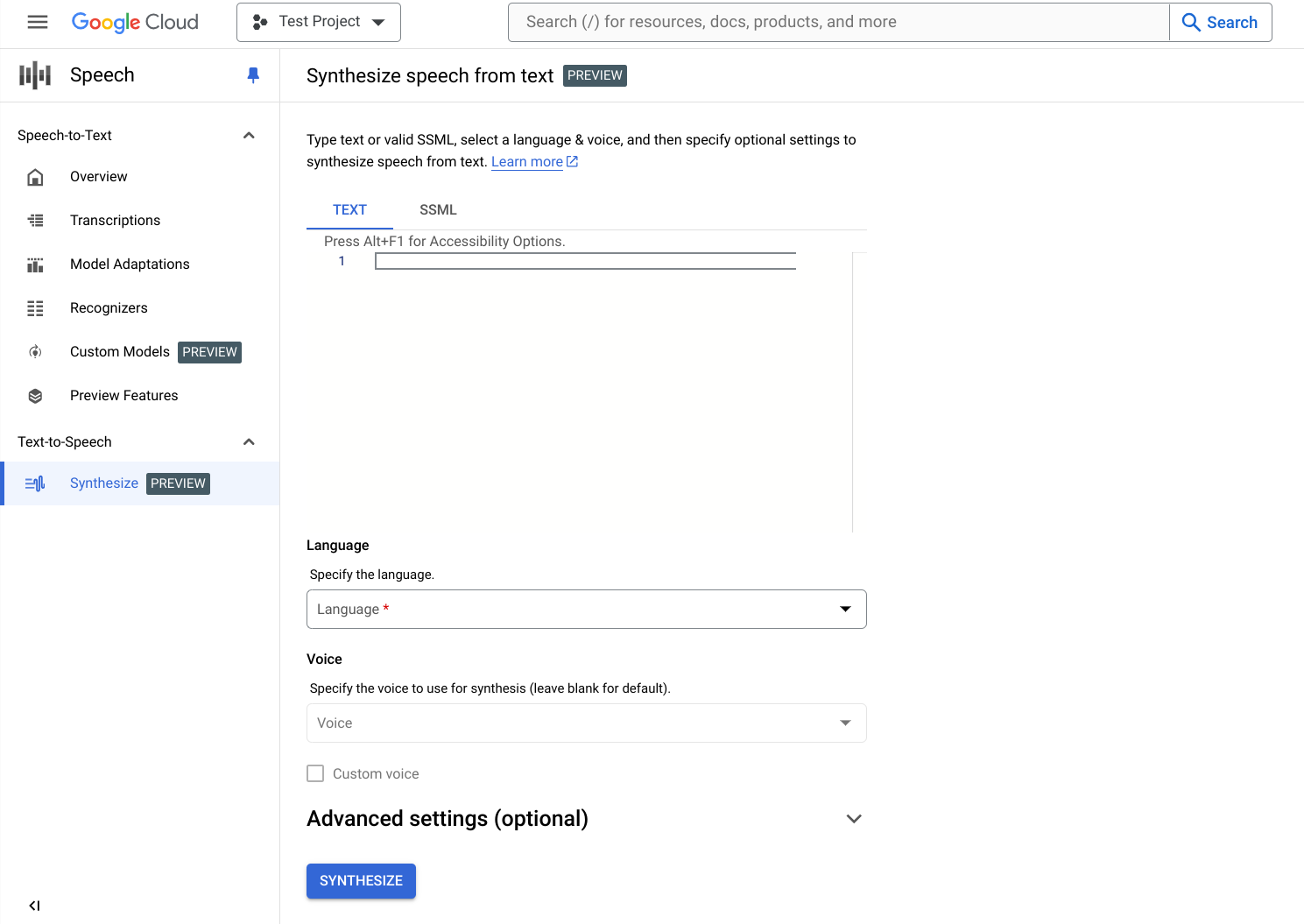
Geben Sie Text oder SSML ein. Sie können entweder Nur-Text-Inhalte synthetisieren oder die Speech Synthesis Markup Language (SSML) verwenden, um noch mehr Anpassungsmöglichkeiten für Ihre Audioantwort zu erhalten.
Wählen Sie die Sprache für Ihren Text oder Ihre SSML aus. Dies ist die Sprache, die für die Synthese verwendet wird.
Wählen Sie die Stimme aus, die für die Synthese verwendet werden soll. Beachten Sie, dass Stimmfunktionen, Merkmale und Kosten variieren können.
Erweiterte Einstellungen (optional)
Optional können Sie den Abschnitt Erweiterte Einstellungen maximieren, um weitere Eigenschaften der Audioinhalte zu konfigurieren, die Sie erstellen werden.
Geben Sie zusätzliche Merkmale der synthetisierten Audioinhalte an, z. B. Geschwindigkeit und Tonhöhe.
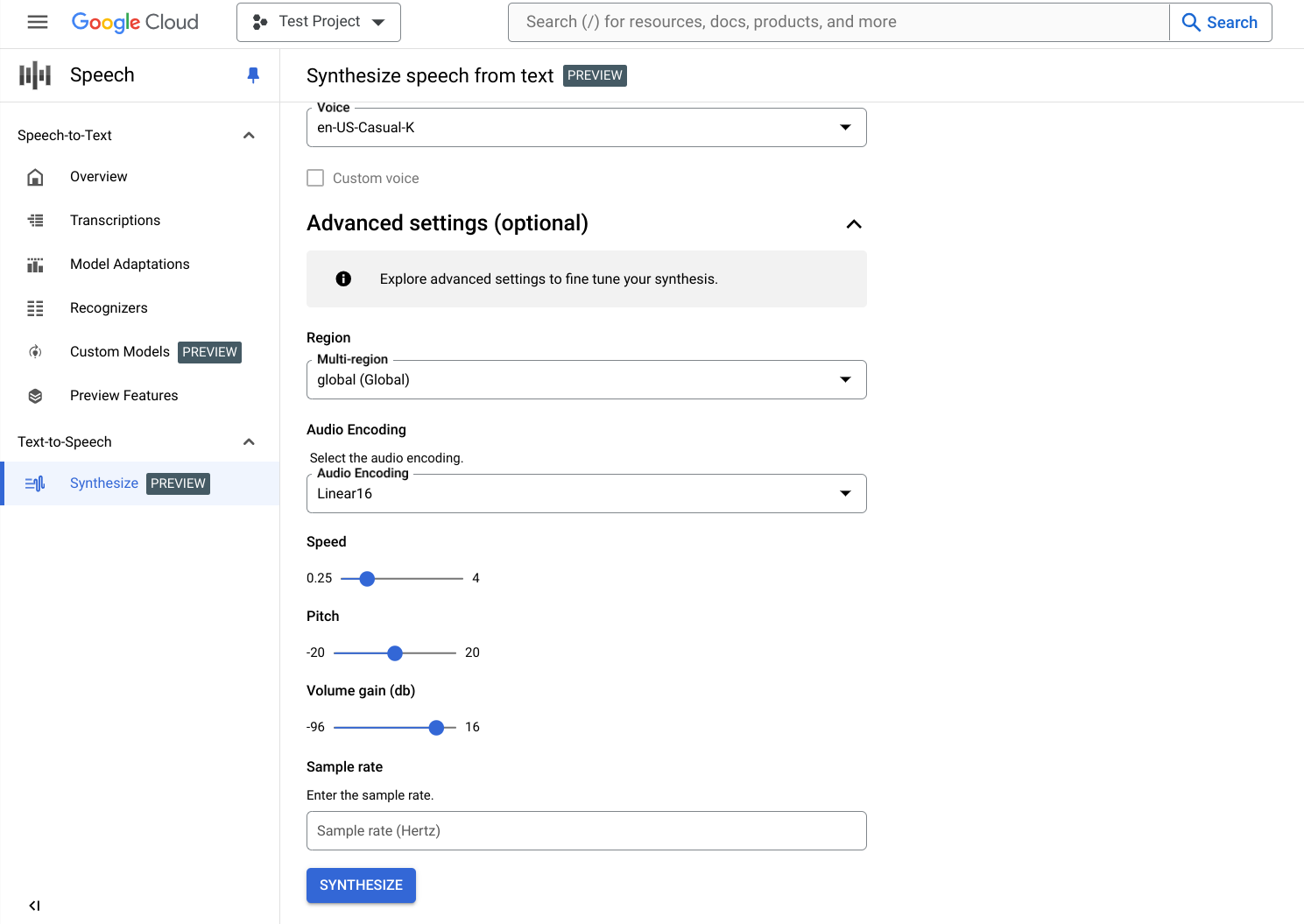
Klicken Sie unten auf Synthetisieren, um die synthetisierten Audioinhalte zu erstellen.
Audioinhalte überprüfen
Je nach Eingabe kann es Sekunden bis Minuten dauern, bis die synthetisierten Audioinhalte erstellt wurden. Nachdem die Audioinhalte erstellt wurden, können sie überprüft werden.
Klicken Sie auf die Steuerelemente des Players, um die Audioinhalte abzuspielen.
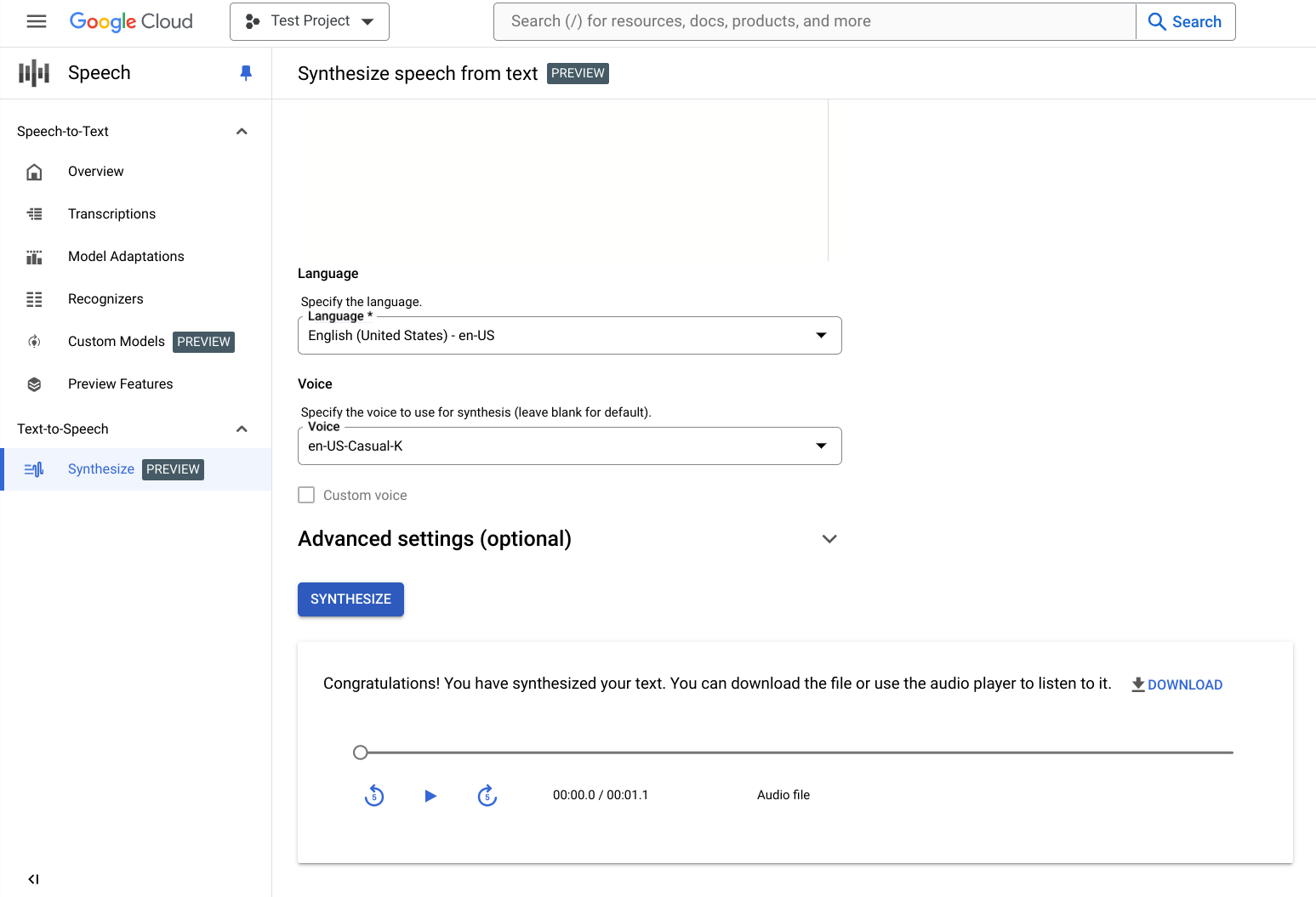
Klicken Sie auf Herunterladen, um die Audiodatei lokal herunterzuladen.
Bereinigen
Wenn Sie das Projekt nicht mehr benötigen, löschen Sie es mit der Google Cloud console , um unnötige Kosten für Google Cloud zu vermeiden.
Weitere Informationen
- Grundlagen der Cloud Text-to-Speech API
- Liste der für synthetische Sprache verfügbaren Stimmen