Chirp 3 は、フィードバックと経験に基づいてユーザーのニーズを満たすように設計された、Google の最新世代の多言語 ASR 専用生成モデルです。初代の Chirp モデルと Chirp 2 モデルと比べて精度と速度が向上し、ダイアライゼーション(発言者の識別・分離)などの重要な新機能が追加されています。
モデルの詳細
Chirp_3 の詳細
モデル ID
Chirp 3 は Speech-to-Text API V2 でのみ使用可能で、他のモデルと同様に使用できます。API を使用する場合は認識リクエストで適切な ID を指定します。 Google Cloud コンソールを使用する場合はモデル名を指定します。
| モデル | モデル ID |
| Chirp 3 | chirp_3 |
API メソッド
認識メソッドによってサポートされている対応言語セットは異なります。Chirp 3 は Speech-to-Text API V2 で使用できるため、次の認識メソッドがサポートされています。
| API | API メソッドのサポート | サポート |
| v2 | Speech.BatchRecognize(1 分~1 時間の長い音声に最適) | サポート対象 |
| v2 | Speech.Recognize(1 分未満の音声に最適) | サポート対象外 |
| v2 | Speech.StreamingRecognize(ストリーミングとリアルタイム音声に最適) | サポート対象外 |
ご利用いただけるリージョン
Chirp 3 は、次の Google Cloud リージョンで利用できます。今後さらに追加される予定です。
| Google Cloud ゾーン | 提供状況 |
| us-west1 | 限定公開プレビュー |
ここで説明されているように、Location API を使用して、各音声文字変換モデルでサポートされている最新の Google Cloud のリージョン、言語とロケール、機能の一覧を確認できます。
音声文字変換の対応言語
Chirp 3 は、BatchRecognize で次の言語の音声文字変換のみをサポートしています。
| 言語 | BCP-47 コード |
| アラビア語(エジプト) | ar-EG |
| アラビア語(サウジアラビア) | ar-SA |
| ベンガル語(バングラデシュ) | bn-BD |
| ベンガル語(インド) | bn-IN |
| チェコ語(チェコ共和国) | cs-CZ |
| デンマーク語(デンマーク) | da-DK |
| ギリシャ語(ギリシャ) | el-GR |
| スペイン語(メキシコ) | es-MX |
| エストニア語(エストニア) | et-EE |
| ペルシャ語(イラン) | fa-IR |
| フィンランド語(フィンランド) | fi-FI |
| フィリピン語(フィリピン) | fil-PH |
| フランス語(カナダ) | fr-CA |
| グジャラト語(インド) | gu-IN |
| クロアチア語(クロアチア) | hr-HR |
| ハンガリー語(ハンガリー) | hu-HU |
| インドネシア語(インドネシア) | id-ID |
| ヘブライ語(イスラエル) | iw-IL |
| カンナダ語(インド) | kn-IN |
| リトアニア語(リトアニア) | lt-LT |
| ラトビア語(ラトビア) | lv-LV |
| マラヤーラム語(インド) | ml-IN |
| マラーティー語(インド) | mr-IN |
| オランダ語(オランダ) | nl-NL |
| ノルウェー語(ノルウェー) | no-NO |
| パンジャブ語(インド) | pa-IN |
| ポーランド語(ポーランド) | pl-PL |
| ポルトガル語(ポルトガル) | pt-PT |
| ルーマニア語(ルーマニア) | ro-RO |
| ロシア語(ロシア) | ru-RU |
| スロバキア語(スロバキア) | sk-SK |
| スロベニア語(スロベニア) | sl-SI |
| セルビア語(セルビア) | sr-RS |
| スウェーデン語(スウェーデン) | sv-SE |
| タミル語(インド) | ta-IN |
| テルグ語(インド) | te-IN |
| タイ語(タイ) | th-TH |
| トルコ語(トルコ) | tr-TR |
| ウクライナ語(ウクライナ) | uk-UA |
| ウルドゥー語(パキスタン) | ur-PK |
| ベトナム語(ベトナム) | vi-VN |
| 中国語(中国) | zh-CN |
| 中国語(台湾) | zh-TW |
| ズールー語(南アフリカ) | zu-SA |
ダイアライゼーションの対応言語
| 言語 | BCP-47 コード |
| 中国語(簡体字、中国) | cmn-Hans-CN |
| ドイツ語(ドイツ) | de-DE |
| 英語(オーストラリア) | en-AU |
| 英語(英国) | en-GB |
| 英語(インド) | en-IN |
| 英語(米国) | en-US |
| スペイン語(スペイン) | es-ES |
| スペイン語(米国) | es-US |
| フランス語(フランス) | fr-FR |
| ヒンディー語(インド) | hi-IN |
| イタリア語(イタリア) | it-IT |
| 日本語(日本) | ja-JP |
| 韓国語(韓国) | ko-KR |
| ポルトガル語(ブラジル) | pt-BR |
機能のサポートと制限事項
Chirp 3 は、次の機能をサポートしています。
| 機能 | 説明 | リリース ステージ |
| 句読点の自動入力 | モデルによって自動的に生成され、必要に応じて無効にできます。 | プレビュー |
| 大文字の自動入力 | モデルによって自動的に生成され、必要に応じて無効にできます。 | プレビュー |
| 話者ダイアライゼーション | シングル チャンネルの音声サンプル内の複数の話者を自動的に識別します。 | プレビュー |
| 言語に依存しない音声文字変換 | モデルが音声ファイルの音声言語を自動的に推論し、最も多く使用されている言語で文字起こしします。 | プレビュー |
Chirp 3 は、次の機能をサポートしていません。
| 機能 | 説明 |
| 単語のタイミング(タイムスタンプ) | モデルによって自動的に生成され、必要に応じて無効にできます。 |
| 単語レベルの信頼スコア | API は値を返しますが、正確な信頼スコアではありません。 |
| 音声適応(バイアス) | フレーズや単語の形式でモデルにヒントを提供することで、特定の用語や固有名詞の認識精度を高めることができます。 |
Chirp 3 の使用
音声文字変換とダイアライゼーションのタスクに Chirp 3 を使用します。
Chirp 3 バッチ リクエストでダイアライゼーションを使用して文字起こしする
音声文字変換のニーズに Chirp 3 で対応する方法を学びます。
一括音声認識を実行する
Cloud Speech サービスが Cloud Storage ストレージ バケットを読み取れるようにします(これは限定公開プレビュー中に一時的に必要になります)。これには、コマンドラインで Google Cloud CLI コマンドを使用します。
gcloud storage buckets add-iam-policy-binding gs://<YOUR_BUCKET_NAME_HERE> --member=serviceAccount:service-727103546492@gcp-sa-aiplatform.iam.gserviceaccount.com --role=roles/storage.objectViewer
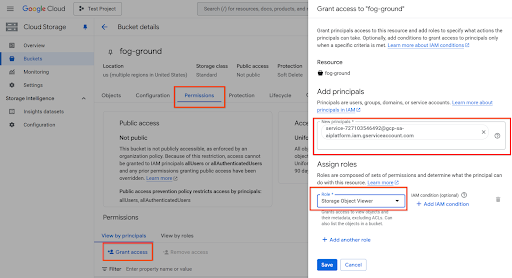
または、次のように Cloud コンソール(http://console.cloud.google.com/storage/browser に移動)を使用して、バケットを選択し、[権限] > [アクセス権を付与] をクリックして、サービス アカウントを追加します。
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_batch_chirp3(
audio_uri: str,
) -> cloud_speech.BatchRecognizeResults:
"""Transcribes an audio file from a Google Cloud Storage URI using the Chirp 3 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_uri (str): The Google Cloud Storage URI of the input
audio file. E.g., gs://[BUCKET]/[FILE]
Returns:
cloud_speech.RecognizeResponse: The response from the
Speech-to-Text API containing the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-west1-speech.googleapis.com",
)
)
speaker_diarization_config = cloud_speech.SpeakerDiarizationConfig(
min_speaker_count=1, # minimum number of speakers
max_speaker_count=6, # maximum expected number of speakers
)
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"], # Use "auto" to detect language
model="chirp_3",
features=cloud_speech.RecognitionFeatures(
diarization_config=speaker_diarization_config,
),
)
file_metadata = cloud_speech.BatchRecognizeFileMetadata(uri=audio_uri)
request = cloud_speech.BatchRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-west1/recognizers/_",
config=config,
files=[file_metadata],
recognition_output_config=cloud_speech.RecognitionOutputConfig(
inline_response_config=cloud_speech.InlineOutputConfig(),
),
)
# Transcribes the audio into text
operation = client.batch_recognize(request=request)
print("Waiting for operation to complete...")
response = operation.result(timeout=120)
for result in response.results[audio_uri].transcript.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
print(f"Speakers per word: {result.alternatives[0].words}")
return response.results[audio_uri].transcript