O Chirp 2 é a geração mais recente dos modelos multilingues específicos de RFA da Google, concebidos para satisfazer as necessidades dos utilizadores com base no feedback e na experiência. Melhora o modelo Chirp original em termos de precisão e velocidade, além de expandir-se para novas funcionalidades importantes, como indicações de tempo ao nível da palavra, adaptação do modelo e tradução de voz.
|
|
 Ver bloco de notas no GitHub Ver bloco de notas no GitHub
|
Detalhes do modelo
O Chirp 2 está disponível exclusivamente na API Speech-to-Text V2.
Identificadores do modelo
Pode usar o Chirp 2 tal como qualquer outro modelo, especificando o identificador do modelo adequado no seu pedido de reconhecimento quando usar a API ou o nome do modelo na Google Cloud consola.
| Modelo | Identificador do modelo |
|---|---|
| Chirp 2 | chirp_2 |
Métodos da API
Como o Chirp 2 está disponível exclusivamente na API Speech-to-Text V2, suporta os seguintes métodos de reconhecimento:
| Modelo | Identificador do modelo | Suporte de idiomas |
|---|---|---|
V2 |
Speech.StreamingRecognize (bom para streaming e áudio em tempo real) |
Limitado* |
V2 |
Speech.Recognize (ideal para áudio curto com menos de 1 minuto) |
À altura do Chirp |
V2 |
Speech.BatchRecognize (bom para áudio longo de 1 min a 8 horas) |
À altura do Chirp |
*Pode sempre encontrar a lista mais recente de idiomas e funcionalidades suportados para cada modelo de transcrição através da API locations.
Disponibilidade regional
O Chirp 2 é compatível nas seguintes regiões:
| Google Cloud Zona | Disposição para o lançamento |
|---|---|
us-central1 |
DG |
europe-west4 |
DG |
asia-southeast1 |
DG |
Pode sempre encontrar a lista mais recente de Google Cloud regiões, idiomas e funcionalidades suportados para cada modelo de transcrição através da API Locations, conforme explicado aqui.
Idiomas disponíveis para a transcrição
O Chirp 2 suporta a transcrição nos métodos de reconhecimento StreamingRecognize, Recognize e BatchRecognize. No entanto, o suporte de idiomas difere consoante o método usado. Especificamente, a BatchRecognize oferece a compatibilidade com idiomas mais abrangente. O StreamingRecognize suporta os seguintes idiomas:
| Idioma | Código BCP-47 |
|---|---|
| Chinês (simplificado, China) | cmn-Hans-CN |
| Chinês (tradicional, Taiwan) | cmn-Hant-TW |
| Chinês, cantonês (Hong Kong tradicional) | yue-Hant-HK |
| Inglês (Austrália) | en-AU |
| Inglês (Índia) | en-IN |
| Inglês (Reino Unido) | en-GB |
| Inglês (Estados Unidos) | en-US |
| Francês (Canadá) | fr-CA |
| Francês (França) | fr-FR |
| Alemão (Alemanha) | de-DE |
| Italiano (Itália) | it-IT |
| Japonês (Japão) | ja-JP |
| Coreano (Coreia do Sul) | ko-KR |
| Português (Brasil) | pt-BR |
| Espanhol (Espanha) | es-ES |
| Espanhol (Estados Unidos) | es-US |
Idiomas disponíveis para tradução
Estes são os idiomas suportados para a tradução de voz. Tenha em atenção que o suporte de idiomas do Chirp 2 para tradução não é simétrico. Isto significa que, embora possamos traduzir do idioma A para o idioma B, a tradução do idioma B para o idioma A pode não estar disponível. Os seguintes pares de idiomas são suportados para a tradução de voz.
Para tradução para inglês:
| Idioma de origem -> Idioma de destino | Código do idioma de origem -> Código do idioma de destino |
|---|---|
| Árabe (Egito) -> inglês | ar-EG -> en-US |
| Árabe (Golfo) -> Inglês | ar-x-gulf -> en-US |
| Árabe (Levante) -> Inglês | ar-x-levant -> en-US |
| Árabe (Magrebe) -> Inglês | ar-x-maghrebi -> en-US |
| Catalão (Espanha) -> Inglês | ca-ES -> en-US |
| Galês (Reino Unido) -> inglês | cy-GB -> en-US |
| Alemão (Alemanha) -> Inglês | de-DE -> en-US |
| Espanhol (América Latina) -> Inglês | es-419 -> en-US |
| Espanhol (Espanha) -> Inglês | es-ES -> en-US |
| Espanhol (Estados Unidos) -> inglês | es-US -> en-US |
| Estónio (Estónia) -> Inglês | et-EE -> en-US |
| Francês (Canadá) -> Inglês | fr-CA -> en-US |
| Francês (França) -> Inglês | fr-FR -> en-US |
| Persa (Irão) -> Inglês | fa-IR -> en-US |
| Indonésio (Indonésia) -> Inglês | id-ID -> en-US |
| Italiano (Itália) -> Inglês | it-IT -> en-US |
| Japonês (Japão) -> Inglês | ja-JP -> en-US |
| Letão (Letónia) -> Inglês | lv-LV -> en-US |
| Mongol (Mongólia) -> Inglês | mn-MN -> en-US |
| Neerlandês (Países Baixos) -> inglês | nl-NL -> en-US |
| Português (Brasil) -> Inglês | pt-BR -> en-US |
| Russo (Rússia) -> Inglês | ru-RU -> en-US |
| Esloveno (Eslovénia) -> Inglês | sl-SI -> en-US |
| Sueco (Suécia) -> Inglês | sv-SE -> en-US |
| Tâmil (Índia) -> inglês | ta-IN -> en-US |
| Turco (Turquia) -> Inglês | tr-TR -> en-US |
| Chinês (simplificado, China) -> Inglês | cmn-Hans-CN -> en-US |
Para tradução de inglês:
| Idioma de origem -> Idioma de destino | Código do idioma de origem -> Código do idioma de destino |
|---|---|
| Inglês -> árabe (Egito) | en-US -> ar-EG |
| Inglês -> Árabe (Golfo) | en-US -> ar-x-gulf |
| Inglês -> Árabe (Levante) | en-US -> ar-x-levant |
| Inglês -> Árabe (Magrebe) | en-US -> ar-x-maghrebi |
| Inglês -> catalão (Espanha) | en-US -> ca-ES |
| Inglês -> galês (Reino Unido) | en-US -> cy-GB |
| Inglês -> alemão (Alemanha) | en-US -> de-DE |
| Inglês -> estónio (Estónia) | en-US -> et-EE |
| Inglês -> persa (Irão) | en-US -> fa-IR |
| Inglês -> indonésio (Indonésia) | en-US -> id-ID |
| Inglês -> japonês (Japão) | en-US -> ja-JP |
| Inglês -> letão (Letónia) | en-US -> lv-LV |
| Inglês -> Mongol (Mongólia) | en-US -> mn-MN |
| Inglês -> esloveno (Eslovénia) | en-US -> sl-SI |
| Inglês -> sueco (Suécia) | en-US -> sv-SE |
| Inglês -> tâmil (Índia) | en-US -> ta-IN |
| Inglês -> turco (Turquia) | en-US -> tr-TR |
| Inglês -> chinês (simplificado, China) | en-US -> cmn-Hans-CN |
Suporte de funcionalidades e limitações
O Chirp 2 suporta as seguintes funcionalidades:
| Funcionalidade | Descrição |
|---|---|
| Pontuação automática | Geradas automaticamente pelo modelo e podem ser desativadas opcionalmente. |
| Letras maiúsculas automáticas | Geradas automaticamente pelo modelo e podem ser desativadas opcionalmente. |
| Adaptação da voz (tendência) | Forneça sugestões ao modelo sob a forma de palavras ou expressões simples para melhorar a precisão do reconhecimento de termos específicos ou nomes próprios. Os tokens de classe ou as classes personalizadas não são suportados. |
| Indicações de tempo das palavras (datas/horas) | Geradas automaticamente pelo modelo e podem ser ativadas opcionalmente. É possível que a qualidade e a velocidade da transcrição se degradem ligeiramente. |
| Filtro de linguagem obscena | Detetar palavras obscenas e devolver apenas a primeira letra seguida de asteriscos na transcrição (por exemplo, f***). |
| Transcrição de áudio independente do idioma | O modelo infere automaticamente o idioma falado no seu ficheiro de áudio e transcreve-o no idioma mais predominante. |
| Tradução específica do idioma | O modelo traduz automaticamente do idioma falado para o idioma de destino. |
| Normalização forçada | Se estiverem definidas no corpo do pedido, a API faz substituições de strings em termos ou expressões específicos, garantindo a consistência na transcrição. |
| Pontuações de confiança ao nível da palavra | A API devolve um valor, mas não é verdadeiramente uma pontuação de confiança. No caso da tradução, as classificações de confiança não são devolvidas. |
| Cancelamento de ruído e filtragem de SNR | Remova o ruído do áudio antes de o enviar para o modelo. Filtre segmentos de áudio se a SNR for inferior ao limite especificado. |
O Chirp 2 não suporta as seguintes funcionalidades:
| Funcionalidade | Descrição |
|---|---|
| Diarização | Não suportado |
| Deteção de idioma | Não suportado |
Transcreva com o Chirp 2
Descubra como usar o Chirp 2 para as suas necessidades de transcrição e tradução.
Realize o reconhecimento de voz em streaming
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_streaming_chirp2(
audio_file: str
) -> cloud_speech.StreamingRecognizeResponse:
"""Transcribes audio from audio file stream using the Chirp 2 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API V2 containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
content = f.read()
# In practice, stream should be a generator yielding chunks of audio data
chunk_length = len(content) // 5
stream = [
content[start : start + chunk_length]
for start in range(0, len(content), chunk_length)
]
audio_requests = (
cloud_speech.StreamingRecognizeRequest(audio=audio) for audio in stream
)
recognition_config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
)
streaming_config = cloud_speech.StreamingRecognitionConfig(
config=recognition_config
)
config_request = cloud_speech.StreamingRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
streaming_config=streaming_config,
)
def requests(config: cloud_speech.RecognitionConfig, audio: list) -> list:
yield config
yield from audio
# Transcribes the audio into text
responses_iterator = client.streaming_recognize(
requests=requests(config_request, audio_requests)
)
responses = []
for response in responses_iterator:
responses.append(response)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return responses
Realize o reconhecimento de voz síncrono
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_sync_chirp2(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 2 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Realize o reconhecimento de voz em lote
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_batch_chirp2(
audio_uri: str,
) -> cloud_speech.BatchRecognizeResults:
"""Transcribes an audio file from a Google Cloud Storage URI using the Chirp 2 model of Google Cloud Speech-to-Text V2 API.
Args:
audio_uri (str): The Google Cloud Storage URI of the input audio file.
E.g., gs://[BUCKET]/[FILE]
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
)
file_metadata = cloud_speech.BatchRecognizeFileMetadata(uri=audio_uri)
request = cloud_speech.BatchRecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
files=[file_metadata],
recognition_output_config=cloud_speech.RecognitionOutputConfig(
inline_response_config=cloud_speech.InlineOutputConfig(),
),
)
# Transcribes the audio into text
operation = client.batch_recognize(request=request)
print("Waiting for operation to complete...")
response = operation.result(timeout=120)
for result in response.results[audio_uri].transcript.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response.results[audio_uri].transcript
Use as funcionalidades do Chirp 2
Explore como pode usar as funcionalidades mais recentes com exemplos de código:
Faça uma transcrição sem diálogo
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_sync_chirp2_auto_detect_language(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file and auto-detect spoken language using Chirp 2.
Please see https://cloud.google.com/speech-to-text/v2/docs/encoding for more
information on which audio encodings are supported.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["auto"], # Set language code to auto to detect language.
model="chirp_2",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
print(f"Detected Language: {result.language_code}")
return response
Realize a tradução de voz
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def translate_sync_chirp2(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Translates an audio file using Chirp 2.
Args:
audio_file (str): Path to the local audio file to be translated.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the translated results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["fr-FR"], # Set language code to targeted to detect language.
translation_config=cloud_speech.TranslationConfig(target_language="fr-FR"), # Set target language code.
model="chirp_2",
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Translated transcript: {result.alternatives[0].transcript}")
return response
Ative as indicações de tempo ao nível das palavras
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_sync_chirp2_with_timestamps(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 2 model of Google Cloud Speech-to-Text V2 API, providing word-level timestamps for each transcribed word.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
features=cloud_speech.RecognitionFeatures(
enable_word_time_offsets=True, # Enabling word-level timestamps
)
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Melhore a precisão com a adaptação do modelo
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_sync_chirp2_model_adaptation(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 2 model with adaptation, improving accuracy for specific audio characteristics or vocabulary.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
# Use model adaptation
adaptation=cloud_speech.SpeechAdaptation(
phrase_sets=[
cloud_speech.SpeechAdaptation.AdaptationPhraseSet(
inline_phrase_set=cloud_speech.PhraseSet(phrases=[
{
"value": "alphabet",
},
{
"value": "cell phone service",
}
])
)
]
)
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Detalhes do redutor de ruído e da filtragem de SNR
denoiser_audio=true pode ajudar a reduzir eficazmente a música de fundo ou os ruídos, como a chuva e o trânsito na rua. Tenha em atenção que um redutor de ruído não pode remover vozes humanas de fundo.
Pode definir snr_threshold=X para controlar o volume mínimo da voz necessário para a transcrição. Isto ajuda a filtrar o áudio sem voz ou o ruído de fundo, evitando texto indesejado nos seus resultados. Um valor snr_threshold mais elevado significa que o utilizador tem de falar mais alto para que o modelo transcreva as expressões.
A filtragem de SNR pode ser usada em exemplos de utilização de streaming em tempo real para evitar o envio de sons desnecessários para um modelo para transcrição. Um valor mais elevado para esta definição significa que o volume da sua voz tem de ser mais alto em relação ao ruído de fundo para ser enviado para o modelo de transcrição.
A configuração de snr_threshold interage com o facto de denoise_audio ser true ou false. Quando denoise_audio=true,
o ruído de fundo é removido e a voz torna-se relativamente mais clara. A relação sinal/ruído geral do áudio aumenta.
Se o seu exemplo de utilização envolver apenas a voz do utilizador sem outras pessoas a falar, defina denoise_audio=true para aumentar a sensibilidade da filtragem de SNR, que pode filtrar o ruído que não seja de voz. Se o seu exemplo de utilização envolver pessoas a falar em segundo plano e quiser evitar a transcrição da fala em segundo plano, considere definir denoise_audio=false e baixar o limite de SNR.
Seguem-se os valores de limite de SNR recomendados. Pode definir um valor snr_threshold
razoável entre 0 e 1000. Um valor de 0 significa que não filtra nada e 1000
significa que filtra tudo. Ajuste o valor se a definição recomendada não
funcionar para si.
| Remova o ruído do áudio | Limite de SNR | Sensibilidade da voz |
|---|---|---|
| verdadeiro | 10,0 | alta |
| verdadeiro | 20,0 | média |
| verdadeiro | 40,0 | baixos |
| verdadeiro | 100,0 | muito baixa |
| falso | 0,5 | alta |
| falso | 1,0 | média |
| falso | 2,0 | baixos |
| falso | 5.0 | muito baixa |
Ative o cancelamento de ruído e a filtragem de SNR
import os
from google.cloud.speech_v2 import SpeechClient
from google.cloud.speech_v2.types import cloud_speech
from google.api_core.client_options import ClientOptions
PROJECT_ID = os.getenv("GOOGLE_CLOUD_PROJECT")
def transcribe_sync_chirp2_with_timestamps(
audio_file: str
) -> cloud_speech.RecognizeResponse:
"""Transcribes an audio file using the Chirp 2 model of Google Cloud Speech-to-Text V2 API, providing word-level timestamps for each transcribed word.
Args:
audio_file (str): Path to the local audio file to be transcribed.
Example: "resources/audio.wav"
Returns:
cloud_speech.RecognizeResponse: The response from the Speech-to-Text API containing
the transcription results.
"""
# Instantiates a client
client = SpeechClient(
client_options=ClientOptions(
api_endpoint="us-central1-speech.googleapis.com",
)
)
# Reads a file as bytes
with open(audio_file, "rb") as f:
audio_content = f.read()
config = cloud_speech.RecognitionConfig(
auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(),
language_codes=["en-US"],
model="chirp_2",
denoiser_config={
denoise_audio: True,
# Medium snr threshold
snr_threshold: 20.0,
}
)
request = cloud_speech.RecognizeRequest(
recognizer=f"projects/{PROJECT_ID}/locations/us-central1/recognizers/_",
config=config,
content=audio_content,
)
# Transcribes the audio into text
response = client.recognize(request=request)
for result in response.results:
print(f"Transcript: {result.alternatives[0].transcript}")
return response
Use o Chirp 2 na Google Cloud consola
- Certifique-se de que se inscreveu numa conta do Google Cloud e criou um projeto.
- Aceda a Speech na Google Cloud consola.
- Ative a API, caso ainda não esteja ativada.
Certifique-se de que tem uma consola STT do Workspace. Se ainda não tiver um, tem de criar um espaço de trabalho.
Aceda à página de transcrições e clique em Nova transcrição.
Abra o menu pendente Espaço de trabalho e clique em Novo espaço de trabalho para criar um espaço de trabalho para a transcrição.
Na barra lateral de navegação Criar um novo espaço de trabalho, clique em Procurar.
Clique para criar um novo contentor.
Introduza um nome para o seu contentor e clique em Continuar.
Clique em Criar para criar o seu contentor do Cloud Storage.
Depois de criar o contentor, clique em Selecionar para selecionar o contentor para utilização.
Clique em Criar para concluir a criação do seu espaço de trabalho para a consola da API Speech-to-Text V2.
Fazer uma transcrição do seu áudio real.
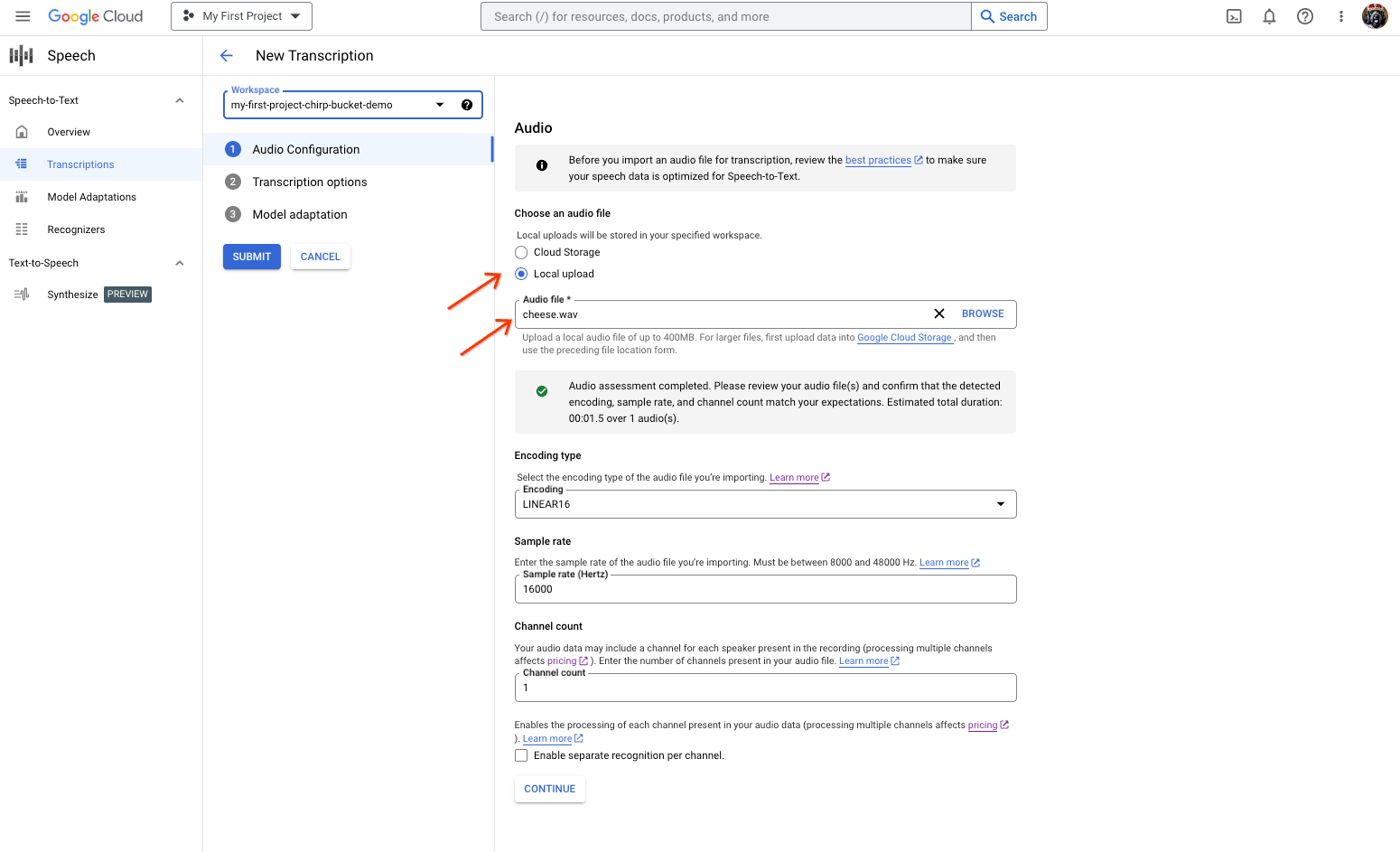
Na página Nova transcrição, selecione o ficheiro de áudio carregando-o (Carregamento local) ou especificando um ficheiro do Cloud Storage existente (Armazenamento na nuvem).
Clique em Continuar para aceder às Opções de transcrição.
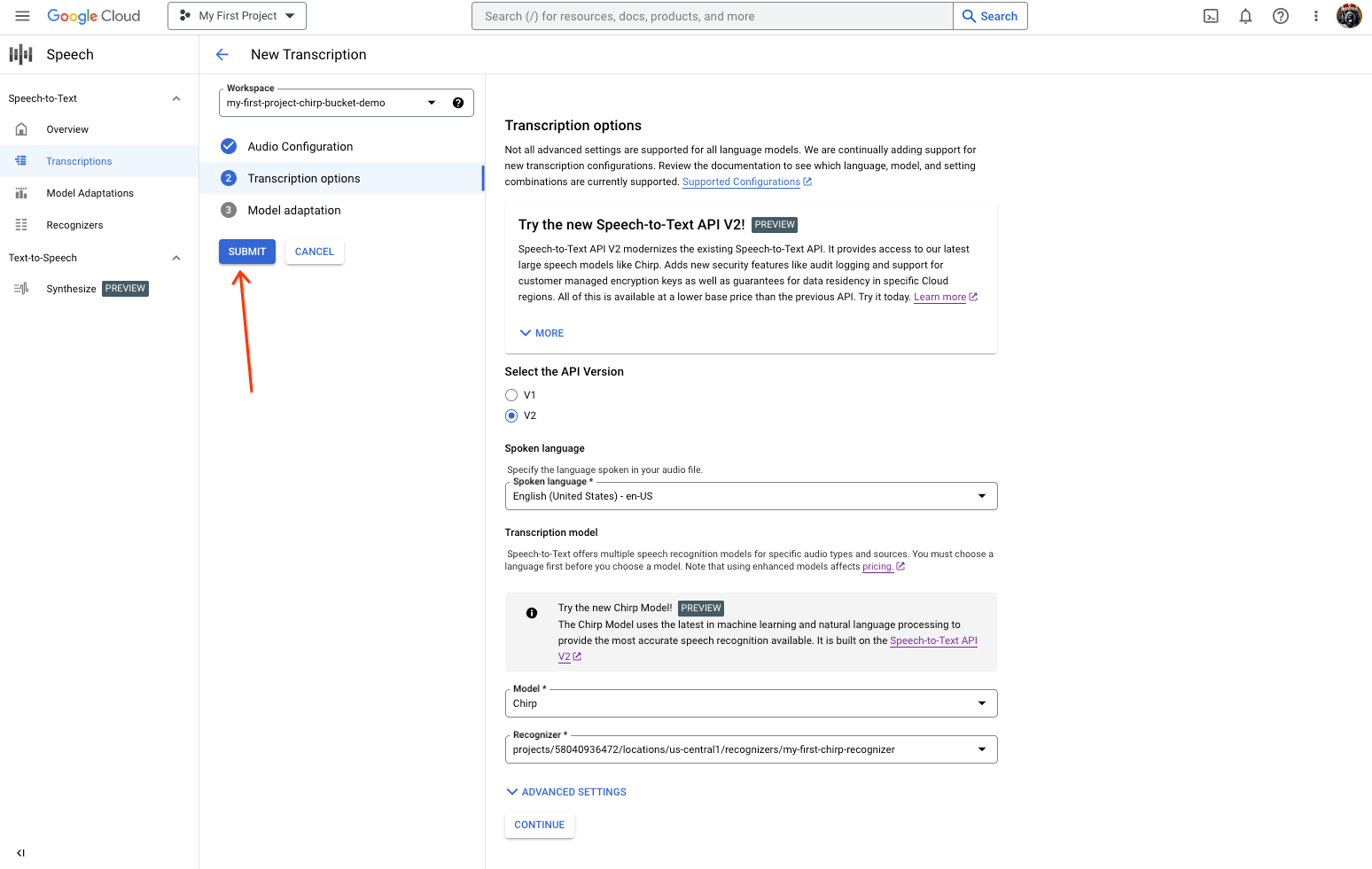
Selecione o idioma falado que planeia usar para o reconhecimento com o Chirp a partir do reconhecedor criado anteriormente.
No menu pendente do modelo, selecione Chirp – Modelo de voz universal.
No menu pendente Reconhecedor, selecione o reconhecedor que acabou de criar.
Clique em Enviar para executar o seu primeiro pedido de reconhecimento através do Chirp.
Veja o resultado da transcrição do Chirp 2.
Na página Transcrição, clique no nome da transcrição para ver o respetivo resultado.
Na página Detalhes da transcrição, veja o resultado da transcrição e, opcionalmente, ouça o áudio no navegador.
Limpar
Para evitar incorrer em cobranças na sua Google Cloud conta pelos recursos usados nesta página, siga estes passos.
-
Optional: Revoke the authentication credentials that you created, and delete the local credential file.
gcloud auth application-default revoke
-
Optional: Revoke credentials from the gcloud CLI.
gcloud auth revoke
Consola
gcloud
O que se segue?
- Pratique a transcrição de ficheiros de áudio curtos.
- Saiba como transcrever áudio em streaming.
- Saiba como transcrever ficheiros de áudio longos.
- Para o melhor desempenho, precisão e outras sugestões, consulte a documentação de práticas recomendadas.