Nesta página, descrevemos as cotas e os limites de produção do Spanner. Cota e limite podem ser usados alternadamente no console Google Cloud .
Esses valores estão sujeitos a alterações.
Permissões para verificar e editar cotas
Para visualizar as cotas, você precisa ter a permissão
serviceusage.quotas.get
do Identity and Access Management (IAM).
Para mudar as cotas, você precisa ter a permissão
serviceusage.quotas.update
do IAM. Por padrão, ela está incluída nos seguintes
papéis predefinidos: proprietário, editor e
administrador de cotas.
Por padrão, elas estão incluídas nos papéis básicos do IAM Proprietário e Editor, assim como no papel predefinido Administrador de cotas.
Verificar suas cotas
Para verificar as cotas atuais para os recursos do seu projeto, use o consoleGoogle Cloud :
Aumentar suas cotas
À medida que você usa mais o Spanner, as cotas também podem aumentar proporcionalmente. Se você espera um aumento significativo no uso, faça uma solicitação com alguns dias de antecedência para garantir que as cotas tenham o limite necessário.
Talvez também seja necessário aumentar a substituição da cota de consumidor. Para mais informações, consulte Como criar uma modificação de cota do consumidor.
É possível aumentar o limite atual de nós de configuração da instância do Spanner usando o console Google Cloud .
Acesse a página Cotas.
Selecione API Spanner na lista suspensa Serviço.
Se você não encontrar a opção API Spanner, é porque ela não foi ativada. Para mais informações, consulte Como ativar APIs.
Selecione as cotas que você quer alterar.
Clique em Editar cotas.
No painel Mudanças de cota, insira o novo limite de cota.
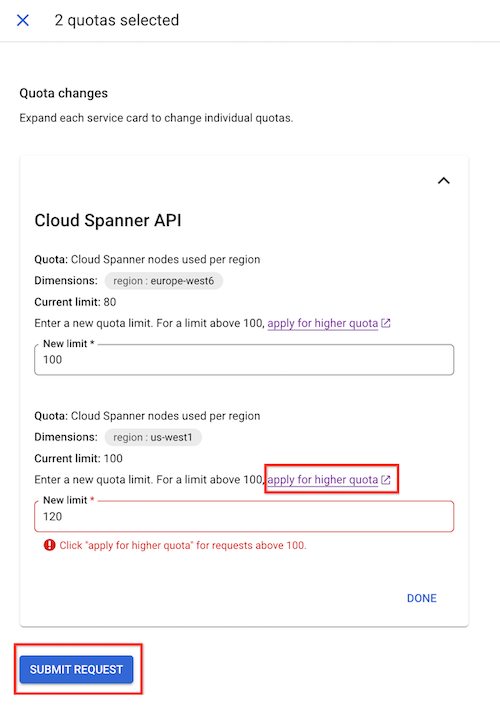
Clique em Concluído e em Enviar solicitação.
Se não for possível aumentar o limite de nós manualmente para o valor desejado, clique em Solicitar uma cota maior. Preencha o formulário para enviar uma solicitação à equipe do Spanner. Você vai receber uma resposta em até 48 horas após o envio da solicitação.
Aumentar a cota para uma configuração de instância personalizada
É possível aumentar a cota de nós para sua configuração de instância personalizada.
Verifique o limite de nós de uma configuração de instância personalizada verificando o limite de nós da configuração de instância básica.
Use o comando show instance configurations detail se você não souber ou não se lembrar da configuração básica da sua configuração de instância personalizada.
Se o limite de nós necessário para sua configuração de instância personalizada for menor que 85, siga as instruções na seção anterior Aumentar suas cotas. Use o console Google Cloud para aumentar o limite de nós da configuração de instância de base associada à sua configuração de instância personalizada.
Se o limite de nós necessário para sua configuração de instância personalizada for maior que 85, preencha o formulário Solicitar um aumento de cota para seus nós do Spanner. Especifique o ID da configuração personalizada da instância no formulário.
Limites de nós
| Valor | Limite |
|---|---|
| Nós por configuração de instância |
Os limites padrão variam de acordo com o projeto e a configuração da instância. Para mudar os limites de cota do projeto ou pedir um aumento, consulte Aumentar suas cotas. |
Limites de instância
| Valor | Limite |
|---|---|
| Comprimento do ID da instância | 2 a 64 caracteres |
Limites de instâncias de teste gratuito
Uma instância de teste gratuito do Spanner tem os seguintes limites adicionais: Para aumentar ou remover esses limites, faça upgrade da instância de avaliação gratuita para uma instância paga.
| Valor | Limite |
|---|---|
| Capacidade de armazenamento | 10 GiB |
| Limite de banco de dados | Criar até cinco bancos de dados |
| Recursos não suportados | Backup e restauração |
| SLA | Sem SLA |
| Período de teste | Período de teste gratuito de 90 dias |
Limites do particionamento geográfico
| Valor | Limite |
|---|---|
| Número máximo de partições por instância | 20 |
| Número máximo de linhas de posicionamento por nó na sua partição | 100 milhões |
Limites de consultas salvas
| Valor | Limite |
|---|---|
| Número máximo de consultas salvas por projeto (incluindo consultas salvas para outros produtos do Google Cloud ) | 10.000 |
| Tamanho máximo para cada consulta | 1 MiB |
Limites de configuração de instâncias
| Valor | Limite |
|---|---|
| Número máximo de configurações de instâncias personalizadas por projeto | 100 |
| Tamanho do ID da configuração de instância personalizada | 8 a 64 caracteres Um ID de configuração de instância personalizada precisa começar com |
Limites de bancos de dados
| Valor | Limite |
|---|---|
| Bancos de dados por instância |
|
| Funções por banco de dados | 100 |
| Comprimento do ID do banco de dados | 2 a 30 caracteres |
| Tamanho do armazenamento1 |
O aumento da capacidade de armazenamento de 10 TiB por nó está disponível na maioria das configurações de instâncias regionais, birregionais e multirregionais do Spanner. Para mais informações, consulte Melhorias de desempenho e armazenamento. Se você usa armazenamento em camadas, é possível usar um armazenamento combinado (SSD e HDD) de até 10 TiB por nó. Os backups são armazenados separadamente e não entram na conta do limite. Para mais informações, consulte Métricas de utilização do Storage. O Spanner cobra pelo armazenamento real utilizado em uma instância, e não pelo armazenamento total disponível. |
Limites de backup e restauração
| Valor | Limite |
|---|---|
| Número de operações de criação de backup em andamento por banco de dados | 1 |
| Número de operações de restauração de banco de dados em andamento por instância (na instância do banco de dados restaurado, não no backup) | 10 |
| Tempo de retenção máximo do backup | Um ano (incluindo o dia extra em anos bissextos) |
Limites de esquemas
Objetos de esquema
| Valor | Limite |
|---|---|
| O número total de objetos de esquema em todos os bancos de dados na mesma instância | Os limites padrão variam de acordo com a configuração da instância.2 |
Instruções DDL
| Valor | Limite |
|---|---|
| Tamanho da instrução DDL para uma única mudança de esquema | 10 MiB |
Tamanho da instrução DDL para todo o esquema de um banco de dados, conforme retornado por GetDatabaseDdl |
10 MiB |
Gráficos
| Valor | Limite |
|---|---|
| Gráficos de propriedades por banco de dados | 16 |
| Comprimento do nome do gráfico de propriedades | 1 a 128 caracteres |
Tabelas
| Valor | Limite |
|---|---|
| Tabelas por banco de dados | 5,000 |
| Comprimento do nome da tabela | 1 a 128 caracteres |
| Colunas por tabela | 1.024 |
| Comprimento do nome da coluna | 1 a 128 caracteres |
| Tamanho máximo dos dados por célula | 10 MiB |
Tamanho de uma célula STRING |
2.621.440 caracteres Unicode |
| Número de colunas em uma chave de tabela | 16 Inclui colunas de uma chave compartilhadas com qualquer tabela pai |
| Profundidade de intercalação da tabela | 7 Uma tabela de nível superior com tabelas filhas tem profundidade 1. Uma tabela de nível superior com tabelas netas tem profundidade 2, e as tabelas aninhadas subsequentes aumentam a profundidade de acordo. |
| Tamanho máximo de uma chave primária ou de índice por linha | 8 KiB Inclui o tamanho de todas as colunas que compõem a chave |
| Tamanho total das colunas não principais por linha | 1.600 MiB Inclui o tamanho de todas as colunas não principais por linha de uma tabela |
Índices
| Valor | Limite |
|---|---|
| Índices por banco de dados | 10.000 |
| Índices por tabela | 128 |
| Comprimento do nome do índice | 1 a 128 caracteres |
| Número de colunas em uma chave de índice | 16 O número de colunas indexadas (exceto as colunas de STORING) mais o número de colunas da chave primária na tabela base |
Visualizações
| Valor | Limite |
|---|---|
| Visualizações por banco de dados | 5,000 |
| Ver tamanho do nome | 1 a 128 caracteres |
| Profundidade de aninhamento | 10 Uma visualização que se refere a outra tem profundidade de aninhamento 1. Uma visualização que se refere a outra visualização que ainda se refere a outra visualização tem profundidade de aninhamento 2 e assim por diante. |
Grupos de localidades
| Valor | Limite |
|---|---|
| Número máximo de grupos de localidades por banco de dados | 16 (1 grupo de localidades padrão e 15 grupos de localidades adicionais opcionais) |
Tempo mínimo necessário na opção ssd_to_hdd_spill_timespan |
1 hora |
Tempo máximo permitido na opção ssd_to_hdd_spill_timespan |
365 dias |
Limites de consulta
| Valor | Limite |
|---|---|
Colunas em uma cláusula GROUP BY |
1.000 |
Valores em um operador IN |
10.000 |
| Chamadas de funções | 1.000 |
| Mesclagens | 20 |
| Chamadas de funções aninhadas | 75 |
Cláusulas GROUP BY aninhadas |
35 |
| Expressões de subconsulta aninhadas | 25 |
| Instruções de subseleção aninhadas | 60 |
| Junções produzidas por uma consulta de gráfico | 100 |
| Parâmetros | 950 |
| Comprimento da instrução de consulta | 1 milhão de caracteres |
STRUCT campos |
1.000 |
| Filhos da expressão de subconsulta | 50 |
| Uniões em uma consulta | 200 |
| Profundidade da travessia do caminho quantificado do gráfico | 100 |
Limites para criar, ler, atualizar e excluir dados
| Valor | Limite |
|---|---|
| Tamanho da confirmação (incluindo índices e fluxos de mudanças) | 100 MiB |
| Leituras simultâneas por sessão | 100 |
| Mutações por confirmação (incluindo índices)3 | 80.000 |
| Mutações por grupo de mutação em uma solicitação de gravação em lote | 80.000 |
| Instruções DML particionadas simultâneas por banco de dados | 20.000 |
Limites administrativos
| Valor | Limite |
|---|---|
| Tamanho da solicitação de ações administrativas4 | 1 MiB |
| Limitação de taxa para ações administrativas5 | Cinco por segundo, por projeto e por usuário (média de mais de 100 segundos) |
Limites de solicitações
| Valor | Limite |
|---|---|
| Tamanho da solicitação, que não o tamanho das confirmações6 | 10 MiB |
Limites de fluxo de alterações
| Valor | Limite |
|---|---|
| Fluxos de alterações por banco de dados | 10 |
| Transmissões de mudança que monitoram qualquer coluna não chave7 | 3 |
| Leitores simultâneos por partição de dados de fluxo de alterações8 | 20 |
Limites do Data Boost
| Valor | Limite |
|---|---|
| Solicitações simultâneas do Data Boost por projeto em us-central1 | 1000 9 |
| Solicitações simultâneas de Data Boost por projeto e região em outras regiões | 400 9 |
Limites da API de pré-divisão
| Valor | Limite |
|---|---|
| Pontos de divisão adicionados por solicitação de API | 100 |
| Tamanho da solicitação da API de ponto de divisão | 1 MiB |
| Pontos de divisão adicionados por nó para todos os bancos de dados na instância | 50 |
| Pontos de divisão adicionados ou atualizados por minuto por nó | 10 |
| Pontos de divisão adicionados ou atualizados por dia e por nó | 200 |
Observações
1. Para você usar o Spanner e acessar um banco de dados com alta disponibilidade e baixa latência, os limites de armazenamento são definidos com base na capacidade de computação da instância:
- Para instâncias menores que 1 nó (1.000 unidades de processamento), o Spanner aloca 1024,0 GiB de dados para cada 100 unidades de processamento no banco de dados.
- Para instâncias de um nó ou mais, o Spanner reserva 10 TiB de dados para cada nó.
Por exemplo, para criar uma instância para um banco de dados de 1500 GiB, é preciso definir a capacidade de computação como 200 unidades de processamento. Essa quantidade de capacidade de computação manterá a instância abaixo do limite até que o banco de dados aumente para mais de 2048,0 GiB. Depois que o banco de dados atingir esse tamanho, você precisará adicionar mais 100 unidades de processamento para que o banco de dados possa crescer. Caso contrário, as gravações no banco de dados podem ser rejeitadas. Para mais informações, consulte Recomendações para a utilização do armazenamento do banco de dados.
Para ter uma experiência de crescimento otimizada, adicione capacidade de computação antes que o limite do banco de dados seja atingido.
2. Os objetos de esquema contabilizados incluem todos os tipos de objetos descritos em DDL, como tabelas, colunas, índices, sequências etc. O limite de objetos de esquema é aplicado no nível da instância e depende das unidades de processamento disponíveis para sua instância.
- Para instâncias de um nó ou mais, o limite padrão é de um milhão de objetos.
- Para instâncias menores que um nó (1.000 unidades de processamento), o limite diminui proporcionalmente ao tamanho da instância. Por exemplo, o limite é de 100.000 objetos de esquema para instâncias com 100 unidades de processamento.
Para verificar a contagem de objetos de esquema dos seus bancos de dados e o limite de objetos da sua instância, procure as métricas spanner.googleapis.com/instance/schema_objects e spanner.googleapis.com/instance/schema_object_count no Metrics Explorer.
Para mais informações sobre monitoramento, consulte
Monitorar instâncias com o
Cloud Monitoring.
Se você atingir o limite, o Spanner vai impedir que você execute operações que excedam o limite, como:
- Modificar o esquema do banco de dados (por exemplo, adicionar um índice).
- Criando um novo banco de dados na instância.
- Restaurar um banco de dados de um backup na mesma instância. Nesse caso, você pode restaurar o backup em uma instância diferente com a mesma configuração ou criar uma nova instância com a mesma configuração e restaurar o backup nela.
3. As operações de inserção e atualização consideram a multiplicidade do número de colunas que elas afetam, e as colunas de chave primária são sempre afetadas. Por exemplo, inserir um novo registro poderá contabilizar cinco mutações caso os valores sejam inseridos em cinco colunas. A atualização de três colunas em um registro também poderá contar como cinco mutações se o registro tiver duas colunas de chave primária. As operações
de exclusão e de remoção de intervalos contam como uma mutação, independentemente do número de
colunas afetadas.
Excluir uma linha de uma tabela mãe que tem a anotação
ON DELETE
CASCADE também conta como uma mutação, independentemente do
número de linhas filhas intercaladas. A exceção é que,
se houver índices secundários definidos em linhas que estejam sendo excluídas, as alterações
nos índices secundários serão contadas individualmente. Por exemplo, se uma tabela tiver dois índices secundários, excluir um intervalo de linhas na tabela vai contar como uma mutação para a tabela e duas mutações para cada linha excluída. Isso acontece porque as linhas no índice secundário podem estar espalhadas pelo espaço de chaves, o que impede que o Spanner chame uma única operação de exclusão de intervalo nos índices secundários. Índices secundários incluem os
índices de backup
de chaves externas.
Para encontrar a contagem de mutações de uma transação, consulte Como recuperar estatísticas de confirmação para uma transação.
Os fluxos de alterações não adicionam mutações que contam para esse limite.
4. O limite de uma solicitação de ação administrativa exclui confirmações, solicitações listadas na observação 9 e alterações de esquema.
5. Essa limitação de taxa inclui todas as chamadas para a API admin, inclusive chamadas para apurar operações de longa duração em uma instância, um banco de dados ou um backup.
6. Esse limite inclui solicitações de criação e atualização de um banco de dados, leitura, streaming de leituras, execução de consultas SQL e realização de consultas SQL de streaming.
7. Um fluxo de alterações que monitora uma tabela ou um banco de dados inteiro monitora implicitamente todas as colunas dessa tabela ou banco de dados e, portanto, conta para esse limite.
8. Esse limite se aplica a leitores simultâneos da mesma partição de fluxos de alterações, sejam pipelines do Dataflow ou consultas diretas da API.
9. Os limites padrão variam de acordo com o projeto e as regiões. Para mais informações, consulte Monitorar e gerenciar o uso da cota do Data Boost.