This document provides an overview of a BigQuery subscription, its workflow, and associated properties.
A BigQuery subscription is a type of export subscription that writes messages to an existing BigQuery table as they are received. You don't need to configure a separate subscriber client. Use the Google Cloud console, the Google Cloud CLI, the client libraries, or the Pub/Sub API to create, update, list, detach, or delete a BigQuery subscription.
Without the BigQuery subscription type, you need a pull or push subscription and a subscriber (such as Dataflow) that reads messages and writes them to a BigQuery table. The overhead of running a Dataflow job is not necessary when messages don't require additional processing before storing them in a BigQuery table; you can use a BigQuery subscription instead.
However, a Dataflow pipeline is still recommended for Pub/Sub systems where some data transformation is required before the data is stored in a BigQuery table. To learn how to stream data from Pub/Sub to BigQuery with transformation by using Dataflow, see Stream from Pub/Sub to BigQuery.
The Pub/Sub subscription to BigQuery template from Dataflow enforces exactly once delivery by default. This is typically achieved through deduplication mechanisms within the Dataflow pipeline. However, the BigQuery subscription only supports at least once delivery. If exact deduplication is critical for your use case, consider downstream processes in BigQuery to handle potential duplicates.
Before you begin
Before reading this document, ensure that you're familiar with the following:
How Pub/Sub works and the different Pub/Sub terms.
The different kinds of subscriptions that Pub/Sub supports and why you might want to use a BigQuery subscription.
How BigQuery works and how to configure and manage BigQuery tables.
BigQuery subscription workflow
The following image shows the workflow between a BigQuery subscription and BigQuery.
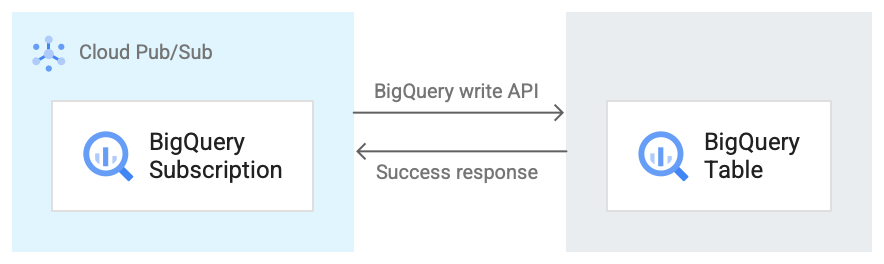
Here is a brief description of the workflow that references Figure 1:
- Pub/Sub uses the BigQuery storage write API to send data to the BigQuery table.
- The messages are sent in batches to the BigQuery table.
- After a successful completion of a write operation, the API returns an OK response.
- If there are any failures in the write operation, the Pub/Sub message itself is negatively acknowledged. The message is then re-sent. If the message fails enough times and there's a dead letter topic configured on the subscription, then the message is moved to the dead letter topic.
Properties of a BigQuery subscription
The properties that you configure for a BigQuery subscription determine the BigQuery table to which Pub/Sub writes messages and the type of schema of that table.
For more information, see BigQuery properties.
Schema compatibility
This section is only applicable if you select the option Use topic schema when you create a BigQuery subscription.
Pub/Sub and BigQuery use different ways to define their schemas. Pub/Sub schemas are defined in Apache Avro or Protocol Buffer format while BigQuery schemas are defined using a variety of formats.
The following is a list of important information regarding the schema compatibility between a Pub/Sub topic and a BigQuery table.
Any message that contains an improperly formatted field is not written to BigQuery.
In the BigQuery schema,
INT,SMALLINT,INTEGER,BIGINT,TINYINT, andBYTEINTare aliases forINTEGER;DECIMALis an alias forNUMERIC; andBIGDECIMALis an alias forBIGNUMERIC.When the type in the topic schema is a
stringand the type in the BigQuery table isJSON,TIMESTAMP,DATETIME,DATE,TIME,NUMERIC, orBIGNUMERIC, then any value for this field in a Pub/Sub message must adhere to the format specified for the BigQuery data type.Some Avro logical types are supported, as specified in the following table. Any logical types not listed only match the equivalent Avro type that they annotate, as detailed in the Avro specification.
The following is a collection of mapping of different schema formats to BigQuery data types.
Avro types
| Avro Type | BigQuery Data Type |
null |
Any NULLABLE |
boolean |
BOOLEAN |
int |
INTEGER, NUMERIC, or
BIGNUMERIC |
long |
INTEGER, NUMERIC, or
BIGNUMERIC |
float |
FLOAT64, NUMERIC, or
BIGNUMERIC |
double |
FLOAT64, NUMERIC, or
BIGNUMERIC |
bytes |
BYTES, NUMERIC, or
BIGNUMERIC |
string |
STRING, JSON,
TIMESTAMP, DATETIME,
DATE, TIME,
NUMERIC, or BIGNUMERIC |
record |
RECORD/STRUCT |
array of Type |
REPEATED Type |
map with value type ValueType
|
REPEATED STRUCT <key STRING, value
ValueType> |
union with two types, one that is
null and the other Type |
NULLABLE Type |
other unions |
Unmappable |
fixed |
BYTES, NUMERIC, or
BIGNUMERIC |
enum |
INTEGER |
Avro logical types
| Avro Logical Type | BigQuery Data Type |
timestamp-micros |
TIMESTAMP |
date |
DATE |
time-micros |
TIME |
duration |
INTERVAL |
decimal |
NUMERIC or BIGNUMERIC |
Protocol Buffer types
| Protocol Buffer Type | BigQuery Data Type |
double |
FLOAT64, NUMERIC, or
BIGNUMERIC |
float |
FLOAT64, NUMERIC, or
BIGNUMERIC |
int32 |
INTEGER, NUMERIC,
BIGNUMERIC, or DATE |
int64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME, or TIMESTAMP |
uint32 |
INTEGER, NUMERIC,
BIGNUMERIC, or DATE |
uint64 |
NUMERIC or BIGNUMERIC |
sint32 |
INTEGER, NUMERIC, or
BIGNUMERIC |
sint64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME, or TIMESTAMP |
fixed32 |
INTEGER, NUMERIC,
BIGNUMERIC, or DATE |
fixed64 |
NUMERIC or BIGNUMERIC |
sfixed32 |
INTEGER, NUMERIC,
BIGNUMERIC, or DATE |
sfixed64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME, or TIMESTAMP |
bool |
BOOLEAN |
string |
STRING, JSON,
TIMESTAMP, DATETIME,
DATE, TIME,
NUMERIC, or BIGNUMERIC |
bytes |
BYTES, NUMERIC, or
BIGNUMERIC |
enum |
INTEGER |
message |
RECORD/STRUCT |
oneof |
Unmappable |
map<KeyType, ValueType> |
REPEATED RECORD<key KeyType, value
ValueType> |
enum |
INTEGER |
repeated/array of Type |
REPEATED Type |
Date and time integer representation
When mapping from an integer to one of the date or time types, the number must represent the correct value. The following is the mapping from BigQuery data types to the integer that represents them.
| BigQuery Data Type | Integer Representation |
DATE |
The number of days since the Unix epoch, January 1, 1970 |
DATETIME |
The date and time in microseconds expressed as civil time using the CivilTimeEncoder |
TIME |
The time in microseconds expressed as civil time using the CivilTimeEncoder |
TIMESTAMP |
The number of microseconds since the Unix epoch, January 1, 1970 00:00:00 UTC |
BigQuery change data capture
BigQuery subscriptions support change data capture (CDC)
updates when
use_topic_schema or
use_table_schema
is set to true in the subscription properties. To use the feature with
use_topic_schema, set the schema of the topic with the
following fields:
_CHANGE_TYPE(required): Astringfield set toUPSERTorDELETE.If a Pub/Sub message written to the BigQuery table has
_CHANGE_TYPEset toUPSERT, then BigQuery updates the row with the same key if it exists or inserts a new row if it does not.If a Pub/Sub message written to the BigQuery table has
_CHANGE_TYPEset toDELETE, then BigQuery deletes the row in the table with the same key if it exists.
_CHANGE_SEQUENCE_NUMBER(optional): Astringfield set to ensure that updates and deletes made to the BigQuery table are processed in order. Messages for the same row key must contain a monotonically increasing value for_CHANGE_SEQUENCE_NUMBER. Messages with sequence numbers that are less than the highest sequence number processed for a row don't have any effect on the row in the BigQuery table. The sequence number must follow the_CHANGE_SEQUENCE_NUMBERformat.
To use the feature with use_table_schema, include the preceding fields in
the JSON message.
For information about CDC pricing, see CDC pricing.
BigLake tables for Apache Iceberg in BigQuery
BigQuery subscriptions can be used with BigLake tables for Apache Iceberg in BigQuery with no additional changes required.
BigLake tables for Apache Iceberg in BigQuery provide the foundation for building open-format lakehouses on Google Cloud. These tables offer the same fully managed experience as standard (built-in) BigQuery tables, but store data in customer-owned storage buckets using Parquet to be interoperable with Iceberg open table formats.
For information on how to create an BigLake tables for Apache Iceberg in BigQuery , see Create an Iceberg table.
Handle message failures
When a Pub/Sub message cannot be written to
BigQuery, the message cannot be acknowledged. To forward such
undeliverable messages, configure a dead-letter
topic on the
BigQuery subscription. The Pub/Sub message
forwarded to the dead-letter topic contains an attribute
CloudPubSubDeadLetterSourceDeliveryErrorMessage that has the reason that the
Pub/Sub message couldn't be written to
BigQuery.
If Pub/Sub cannot write messages to BigQuery, then Pub/Sub backs off delivery of messages in a way similar to push backoff behavior. However, if the subscription has a dead-letter topic attached to it, Pub/Sub does not back off delivery when message failures are due to schema compatibility errors.
Quotas and limits
There are quota limitations on the BigQuery subscriber throughput per region. For more information, see Pub/Sub quotas and limits.
BigQuery subscriptions write data by using the BigQuery Storage Write API. For information about the quotas and limits for the Storage Write API, see BigQuery Storage Write API requests. BigQuery subscriptions only consume the throughput quota for the Storage Write API. You can ignore the other Storage Write API quota considerations in this instance.
Pricing
For the pricing for BigQuery subscriptions, see the Pub/Sub pricing page.
What's next
Create a subscription, such as a BigQuery subscription.
Troubleshoot a BigQuery subscription.
Read about BigQuery.
Review pricing for Pub/Sub, including BigQuery subscriptions.
Create or modify a subscription with
gcloudCLI commands.Create or modify a subscription with REST APIs.