Questo documento fornisce una panoramica di una sottoscrizione BigQuery, del relativo flusso di lavoro e delle proprietà associate.
Una sottoscrizione BigQuery è un tipo di sottoscrizione dell'esportazione che scrive i messaggi in una tabella BigQuery esistente non appena vengono ricevuti. Non è necessario configurare un client sottoscrittore separato. Utilizza la console Google Cloud , Google Cloud CLI, le librerie client o l'API Pub/Sub per creare, aggiornare, elencare, scollegare o eliminare una sottoscrizione BigQuery.
Senza il tipo di sottoscrizione BigQuery, hai bisogno di una sottoscrizione pull o push e di un sottoscrittore (come Dataflow) che legge i messaggi e li scrive in una tabella BigQuery. Il sovraccarico di esecuzione di un job Dataflow non è necessario quando i messaggi non richiedono un'elaborazione aggiuntiva prima di essere archiviati in una tabella BigQuery. Puoi utilizzare un abbonamento BigQuery.
Tuttavia, una pipeline Dataflow è comunque consigliata per i sistemi Pub/Sub in cui è necessaria una trasformazione dei dati prima che vengano archiviati in una tabella BigQuery. Per scoprire come trasmettere dati in streaming da Pub/Sub a BigQuery con la trasformazione utilizzando Dataflow, consulta Trasmettere dati in streaming da Pub/Sub a BigQuery.
Il modello di sottoscrizione Pub/Sub a BigQuery di Dataflow applica la distribuzione esatta una sola volta per impostazione predefinita. Ciò si ottiene in genere tramite meccanismi di deduplicazione all'interno della pipeline Dataflow. Tuttavia, l'abbonamento BigQuery supporta solo la consegna "at-least-once". Se la deduplicazione esatta è fondamentale per il tuo caso d'uso, prendi in considerazione i processi downstream in BigQuery per gestire i potenziali duplicati.
Prima di iniziare
Prima di leggere questo documento, assicurati di conoscere quanto segue:
Come funziona Pub/Sub e i diversi termini di Pub/Sub.
I diversi tipi di sottoscrizioni supportati da Pub/Sub e perché potresti voler utilizzare una sottoscrizione BigQuery.
Come funziona BigQuery e come configurare e gestire le tabelle BigQuery.
Workflow di sottoscrizione BigQuery
L'immagine seguente mostra il flusso di lavoro tra un abbonamento BigQuery e BigQuery.
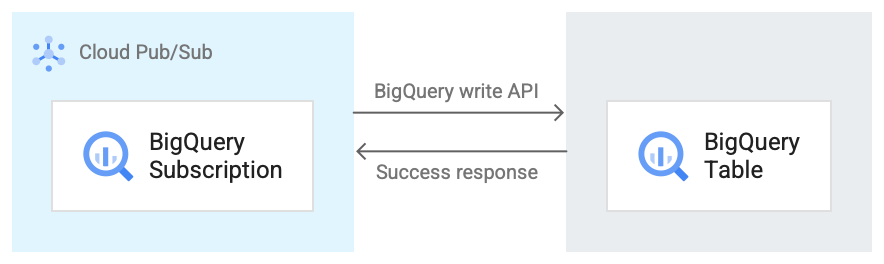
Ecco una breve descrizione del flusso di lavoro che fa riferimento alla Figura 1:
- Pub/Sub utilizza l'API BigQuery Storage Write per inviare dati alla tabella BigQuery.
- I messaggi vengono inviati in batch alla tabella BigQuery.
- Al termine di un'operazione di scrittura, l'API restituisce una risposta OK.
- Se si verificano errori nell'operazione di scrittura, il messaggio Pub/Sub stesso viene riconosciuto negativamente. Il messaggio viene poi inviato di nuovo. Se il messaggio non viene recapitato un numero sufficiente di volte e nella sottoscrizione è configurato un argomento messaggi non recapitabili, il messaggio viene spostato nell'argomento messaggi non recapitabili.
Proprietà di una sottoscrizione BigQuery
Le proprietà che configuri per un abbonamento a BigQuery determinano la tabella BigQuery in cui Pub/Sub scrive i messaggi e il tipo di schema di quella tabella.
Per ulteriori informazioni, consulta Proprietà di BigQuery.
Compatibilità dello schema
Questa sezione è applicabile solo se selezioni l'opzione Utilizza schema argomento quando crei una sottoscrizione BigQuery.
Pub/Sub e BigQuery utilizzano modi diversi per definire i propri schemi. Gli schemi Pub/Sub sono definiti in formato Apache Avro o Protocol Buffer, mentre gli schemi BigQuery sono definiti utilizzando una varietà di formati.
Di seguito è riportato un elenco di informazioni importanti sulla compatibilità dello schema tra un argomento Pub/Sub e una tabella BigQuery.
Qualsiasi messaggio che contiene un campo formattato in modo errato non viene scritto in BigQuery.
Nello schema BigQuery,
INT,SMALLINT,INTEGER,BIGINT,TINYINTeBYTEINTsono alias diINTEGER;DECIMALè un alias diNUMERIC; eBIGDECIMALè un alias diBIGNUMERIC.Quando il tipo nello schema dell'argomento è
stringe il tipo nella tabella BigQuery èJSON,TIMESTAMP,DATETIME,DATE,TIME,NUMERICoBIGNUMERIC, qualsiasi valore per questo campo in un messaggio Pub/Sub deve rispettare il formato specificato per il tipo di dati BigQuery.Sono supportati alcuni tipi logici Avro, come specificato nella tabella seguente. Tutti i tipi logici non elencati corrispondono solo al tipo Avro equivalente che annotano, come descritto nella specifica Avro.
Di seguito è riportata una raccolta di mappature di diversi formati di schema ai tipi di dati BigQuery.
Tipi Avro
| Tipo di Avro | Tipo di dati BigQuery |
null |
Any NULLABLE |
boolean |
BOOLEAN |
int |
INTEGER, NUMERIC o
BIGNUMERIC |
long |
INTEGER, NUMERIC o
BIGNUMERIC |
float |
FLOAT64, NUMERIC o
BIGNUMERIC |
double |
FLOAT64, NUMERIC o
BIGNUMERIC |
bytes |
BYTES, NUMERIC o
BIGNUMERIC |
string |
STRING, JSON,
TIMESTAMP, DATETIME,
DATE, TIME,
NUMERIC o BIGNUMERIC |
record |
RECORD/STRUCT |
array di Type |
REPEATED Type |
map con tipo di valore ValueType
|
REPEATED STRUCT <key STRING, value
ValueType> |
union con due tipi, uno null e l'altro Type |
NULLABLE Type |
altri union |
Non mappabile |
fixed |
BYTES, NUMERIC o
BIGNUMERIC |
enum |
INTEGER |
Tipi logici Avro
| Tipo logico Avro | Tipo di dati BigQuery |
timestamp-micros |
TIMESTAMP |
date |
DATE |
time-micros |
TIME |
duration |
INTERVAL |
decimal |
NUMERIC o BIGNUMERIC |
Tipi di buffer di protocollo
| Tipo di buffer di protocollo | Tipo di dati BigQuery |
double |
FLOAT64, NUMERIC o
BIGNUMERIC |
float |
FLOAT64, NUMERIC o
BIGNUMERIC |
int32 |
INTEGER, NUMERIC,
BIGNUMERIC o DATE |
int64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME o TIMESTAMP |
uint32 |
INTEGER, NUMERIC,
BIGNUMERIC o DATE |
uint64 |
NUMERIC o BIGNUMERIC |
sint32 |
INTEGER, NUMERIC o
BIGNUMERIC |
sint64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME o TIMESTAMP |
fixed32 |
INTEGER, NUMERIC,
BIGNUMERIC o DATE |
fixed64 |
NUMERIC o BIGNUMERIC |
sfixed32 |
INTEGER, NUMERIC,
BIGNUMERIC o DATE |
sfixed64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME o TIMESTAMP |
bool |
BOOLEAN |
string |
STRING, JSON,
TIMESTAMP, DATETIME,
DATE, TIME,
NUMERIC o BIGNUMERIC |
bytes |
BYTES, NUMERIC o
BIGNUMERIC |
enum |
INTEGER |
message |
RECORD/STRUCT |
oneof |
Non mappabile |
map<KeyType, ValueType> |
REPEATED RECORD<key KeyType, value
ValueType> |
enum |
INTEGER |
repeated/array of Type |
REPEATED Type |
Rappresentazione intera di data e ora
Quando esegui il mapping da un numero intero a uno dei tipi di data o ora, il numero deve rappresentare il valore corretto. Di seguito è riportata la mappatura dai tipi di dati BigQuery all'intero che li rappresenta.
| Tipo di dati BigQuery | Rappresentazione di numeri interi |
DATE |
Il numero di giorni trascorsi dall'epoca di Unix, 1° gennaio 1970 |
DATETIME |
La data e l'ora in microsecondi espresse come ora civile utilizzando CivilTimeEncoder |
TIME |
Il tempo in microsecondi espresso come ora civile utilizzando CivilTimeEncoder |
TIMESTAMP |
Il numero di microsecondi trascorsi dall'epoca di Unix, 1° gennaio 1970 00:00:00 UTC |
Change Data Capture di BigQuery
Gli abbonamenti BigQuery supportano gli aggiornamenti di Change Data Capture (CDC) quando use_topic_schema o use_table_schema è impostato su true nelle proprietà dell'abbonamento. Per utilizzare la funzionalità con
use_topic_schema, imposta lo schema dell'argomento con i
seguenti campi:
_CHANGE_TYPE(obbligatorio): un campostringimpostato suUPSERToDELETE.Se un messaggio Pub/Sub scritto nella tabella BigQuery ha
_CHANGE_TYPEimpostato suUPSERT, BigQuery aggiorna la riga con la stessa chiave, se esiste, o inserisce una nuova riga, se non esiste.Se un messaggio Pub/Sub scritto nella tabella BigQuery ha
_CHANGE_TYPEimpostato suDELETE, BigQuery elimina la riga nella tabella con la stessa chiave, se esiste.
_CHANGE_SEQUENCE_NUMBER(facoltativo): un campostringimpostato per garantire che gli aggiornamenti e le eliminazioni apportati alla tabella BigQuery vengano elaborati in ordine. I messaggi per la stessa chiave di riga devono contenere un valore monotonico crescente per_CHANGE_SEQUENCE_NUMBER. I messaggi con numeri di sequenza inferiori al numero di sequenza più alto elaborato per una riga non hanno alcun effetto sulla riga nella tabella BigQuery. Il numero di sequenza deve seguire il formato_CHANGE_SEQUENCE_NUMBER.
Per utilizzare la funzionalità con use_table_schema, includi i campi precedenti nel messaggio JSON.
Per informazioni sui prezzi di CDC, consulta Prezzi di CDC.
Tabelle BigLake per Apache Iceberg in BigQuery
Le sottoscrizioni BigQuery possono essere utilizzate con le tabelle BigLake per Apache Iceberg in BigQuery senza richiedere modifiche aggiuntive.
Le tabelle BigLake per Apache Iceberg in BigQuery forniscono le basi per la creazione di lakehouse in formato aperto su Google Cloud. Queste tabelle offrono la stessa esperienza completamente gestita delle tabelle BigQuery standard (integrate), ma archiviano i dati in bucket di archiviazione di proprietà del cliente utilizzando Parquet per essere interoperabili con i formati di tabella aperti Iceberg.
Per informazioni su come creare tabelle BigLake per Apache Iceberg in BigQuery , consulta Crea una tabella Iceberg.
Gestire gli errori relativi ai messaggi
Quando un messaggio Pub/Sub non può essere scritto in
BigQuery, non può essere riconosciuto. Per inoltrare questi
messaggi non recapitabili, configura un argomento
non recapitabile nell'abbonamento
BigQuery. Il messaggio Pub/Sub
inoltrato all'argomento messaggi non recapitabili contiene un attributo
CloudPubSubDeadLetterSourceDeliveryErrorMessage che indica il motivo per cui il
messaggio Pub/Sub non è stato scritto in
BigQuery.
Se Pub/Sub non riesce a scrivere messaggi in BigQuery, allora Pub/Sub ritarda la consegna dei messaggi in modo simile al comportamento di backoff push. Tuttavia, se la sottoscrizione ha un argomento messaggi non recapitabili collegato, Pub/Sub non esegue il backoff della consegna quando gli errori dei messaggi sono dovuti a errori di compatibilità dello schema.
Quote e limiti
Esistono limitazioni di quota per il throughput del sottoscrittore BigQuery per regione. Per ulteriori informazioni, consulta Quote e limiti di Pub/Sub.
Gli abbonamenti BigQuery scrivono i dati utilizzando l' API BigQuery Storage Write. Per informazioni su quote e limiti per l'API Storage Write, consulta Richieste dell'API BigQuery Storage Write. Gli abbonamenti BigQuery consumano solo la quota di velocità effettiva per l'API Storage Write. In questo caso, puoi ignorare le altre considerazioni relative alla quota dell'API Storage Write.
Prezzi
Per i prezzi delle sottoscrizioni BigQuery, consulta la pagina dei prezzi di Pub/Sub.
Passaggi successivi
Crea una sottoscrizione, ad esempio una sottoscrizione BigQuery.
Risolvi i problemi relativi a un abbonamento BigQuery.
Scopri di più su BigQuery.
Consulta i prezzi di Pub/Sub, incluse le sottoscrizioni BigQuery.
Crea o modifica un abbonamento con i comandi dell'interfaccia a riga di comando
gcloud.Crea o modifica un abbonamento con le API REST.