Select the profiles to analyze
The menu settings in the Profiler interface determine which profile data is used to construct the flame graph or the history view.
To generate the flame graph, Profiler identifies the set of profiles that match the current menu settings. It then randomly selects a maximum of 250 profiles from this set, and uses those to construct the flame graph.
To generate the history view, Profiler uses all profiles that match the current settings of the service, zone, and version menus. The value of the Metric filter determines the resource displayed.
Before you begin
In the Google Cloud console, go to the Profiler page:
You can also find this page by using the search bar.
Range of time
To set the range of time for which profiling data is displayed in the flame graph, you use the Timespan menu, the Now button, and the End time menu.
By default, the time fields have the following settings:
- Timespan is set to 7 days.
- Now button is shaded by a blue background.
- End time contains the time when Profiler was started and cannot be modified.
With these settings, Profiler analyzes profiles captured in the previous 7 days.
To set the timespan, click the Timespan down arrow, and then select an option from the list. Your choices range from 10 minutes to 30 days, the limit of the retention period for profile data.
To update the end time to the current time, click Now. The background of this button toggles between blue and white. In either case, a single click updates the end time field to the current time.
To set the end time, do the following:
If the End time text isn't changeable, as shown in the following image, click Now:

In the End time field, enter a date and time, or use the calendar option to select a date:

Service
To select the service whose data you want to analyze, click the Service menu and then make a selection. The service name is specified by you or by the runtime environment when you run your application with profiling enabled. For information about service names, see the appropriate guide for profiling your application:
Profile type
To select the type of profiling data to visualize, click the Profile type menu and then make a selection.
| Profile type | Go | Java | Node.js | Python |
|---|---|---|---|---|
| CPU time | Y | Y | Y | |
| Heap | Y | Y | Y | |
| Allocated heap | Y | |||
| Contention | Y | |||
| Threads | Y | |||
| Wall time | Y | Y | Y |
Each profile type captures a different kind of information:
- CPU time: information about CPU usage.
- Heap: information about the memory allocated in the program's heap when the profile was collected.
- Allocated Heap: information about the total memory that was allocated in the program's heap, including memory that is freed and no longer in use.
- Contention: information about mutex usage.
- Threads: information about thread usage.
- Wall time: information about total time to run.
Zone
To restrict the analysis to instances of the service running in a specific Compute Engine zone, click the Zone menu and then select a zone.
The default setting for this field is All zones.
Version
To restrict the analysis to a specific version of the named service, click the Version menu, and then select the version of interest.
The service version is an optional value you or the runtime environment can specify when your application is run with profiling enabled. For more information on service versions, see the profiling guides for Go, Java, Node.js, or Python.
The default setting for this field is All versions.
Weight
To display in the flame graph only profile data that was captured when the metric consumption was within a selected percentage of peak consumption, you use the Weight menu. An example Weight menu is as follows:
All (9.98 s - 10.08 s), 54 profiles
Top 50% (10.03 s - 10.08 s), 22 profiles
Top 25% (10.06 s - 10.08 s), 11 profiles
Top 10% (10.07 s - 10.08 s), 3 profiles
Top 5% (10.08 s - 10.08 s), 3 profiles
Top 1% (10.08 s - 10.08 s), 3 profiles
Most rows in the Weight menu start with Top followed by a percentage.
For example,Top 5%
indicates that only profiles that were collected during the top 5% of
metric consumption are available for analysis. The two values in the
parentheses list the corresponding range of metric consumption. The last value
is the number of profiles collected over this range.
For the Top 5% row, 3 profiles were collected.
The first row is the default setting for the Weight field. The word
All indicates that all collected profiles, or equivalently 100% of the
collected profiles, are available for analysis.
The following screenshot shows a weight-filtered graph:
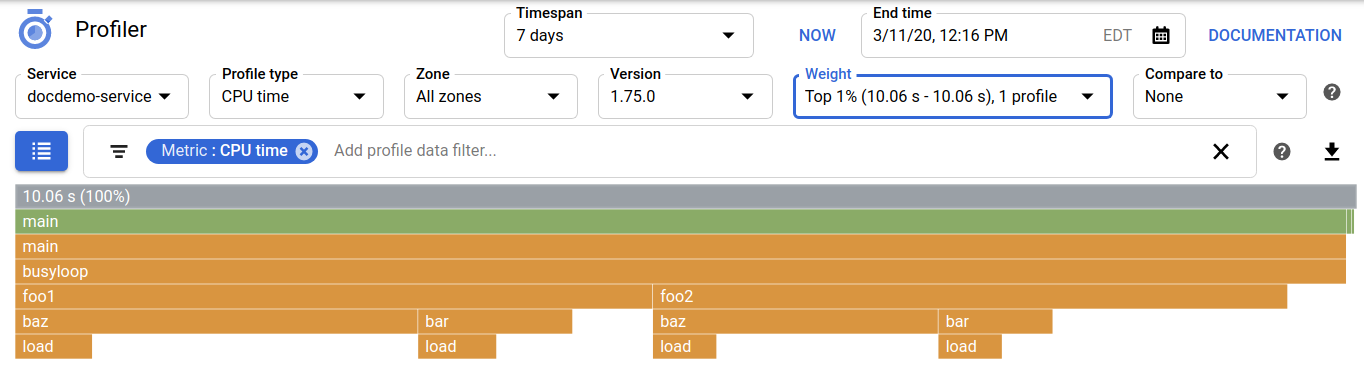
The default setting for this field is all profiles.
Compare to
To create a flame graph that displays a comparison of two profiles that differ by a single user-defined attribute, click the Compare To menu, and then select the attribute. For example, you can compare profiles by zone or by version. The two profiles being compared must have the same profile type and be for the same service.
For more information, see Comparing profiles.
The default setting for this field is None.
What's next
- Interact with the flame graph.
- Filter the flame graph.
- Focus the flame graph on a function.
- View historical trends.
- Compare profiles.