Cloud Profiler 概览
众所周知,想要准确衡量生产系统的性能是十分困难的。在测试环境中衡量性能所做的尝试,通常无法准确再现生产系统面临的压力。对应用的一些部分进行微基准测试有时可行,但它通常也无法准确再现生产系统的工作负载和行为。
当服务在其工作环境中运行时,要探索 CPU 周期和内存等资源用在了何处,持续剖析生产系统的性能不失为一种有效方式。不过,性能剖析过程会给生产系统带来额外负载:要让用户接受这种探索资源耗用模式的方式,性能剖析过程带来的额外负载必须很小。
Cloud Profiler 是一个低开销的统计性能剖析器,可从生产应用中持续收集有关 CPU 使用率和内存分配情况的信息。它会将获得的信息归因于生成这些信息的源代码,从而帮助您识别应用中资源耗用量最大的部分,还可以阐明应用的性能特征。
可用的性能剖析类型
Cloud Profiler 支持基于编写程序所采用的语言来执行不同类型的性能剖析。下表汇总了各语言支持的性能剖析类型:
| 性能剖析类型 | Go | Java | Node.js | Python |
|---|---|---|---|---|
| CPU 时间 | 是 | 是 | 是 | |
| 堆 | 是 | 是 | 是 | |
| 分配的堆 | 是 | |||
| 争用 | 是 | |||
| 线程 | 是 | |||
| 实际用时 | 是 | 是 | 是 |
如需查看语言要求和任何限制的完整信息,请参阅语言的“方法”页面。 如需详细了解这些性能剖析文件类型,请参阅性能剖析相关概念。
受支持的配置
在对应用进行插桩处理以捕获性能剖析文件数据时,您需要包含语言专属的性能剖析代理。 下表汇总了支持的环境:
| 环境 | Go | Java | Node.js | Python |
|---|---|---|---|---|
| Compute Engine | 是 | 是 | 是 | 是 |
| Google Kubernetes Engine | 是 | 是 | 是 | 是 |
| App Engine 柔性环境 | 是 | 是 | 是 | 是 |
| App Engine 标准环境 | 是 | 是 | 是 | 是 |
| Dataproc | 是 | |||
| Dataflow | 是 | 是 | ||
| Google Cloud之外 | 是 | 是 | 是 | 是 |
下表汇总了支持的操作系统:
| 操作系统 | Go | Java | Node.js | Python |
|---|---|---|---|---|
标准 C 库的 Linuxglibc 实现 |
是 | 是 | 是 | 是 |
标准 C 库的 Linuxmusl 实现 |
是 | 是(Alpha 版) | 是 | 是(Alpha 版) |
性能影响
Cloud Profiler 每 1 分钟针对单个 Compute Engine 地区中已配置服务的单个实例收集一次性能剖析数据(一次通常持续 10 秒),以创建单个性能剖析文件。例如,如果您的 GKE 服务运行某 pod 的 10 个副本,那么在 10 分钟内,大约会创建 10 个性能剖析文件,差不多对每个 pod 都会执行一次性能剖析。性能剖析周期是随机的,因此存在各种变化。如需了解详情,请参阅性能剖析文件收集。
CPU 和堆分配性能剖析在收集数据时的开销小于 5%。在执行期间分摊到一项服务的多个副本后,开销通常会低于 0.5%,因此,要在生产系统中实现始终执行的性能剖析,这是一个经济实惠的选择。
组件
Cloud Profiler 由性能分析代理和 Google Cloud上的控制台界面组成;前者用于收集数据,后者用于查看和分析性能分析代理收集的数据。
性能剖析代理
您可以在运行您的应用的虚拟机上安装该代理。该代理通常作为您在运行应用时连接到应用的库。代理在应用运行期间收集性能剖析数据。
如需了解如何运行 Cloud Profiler 代理,请参阅:Profiler 界面
在代理收集了一些性能剖析数据之后,您可以使用 Profiler 界面查看关于 CPU 和内存使用情况的统计信息与应用的各部分有何关联。
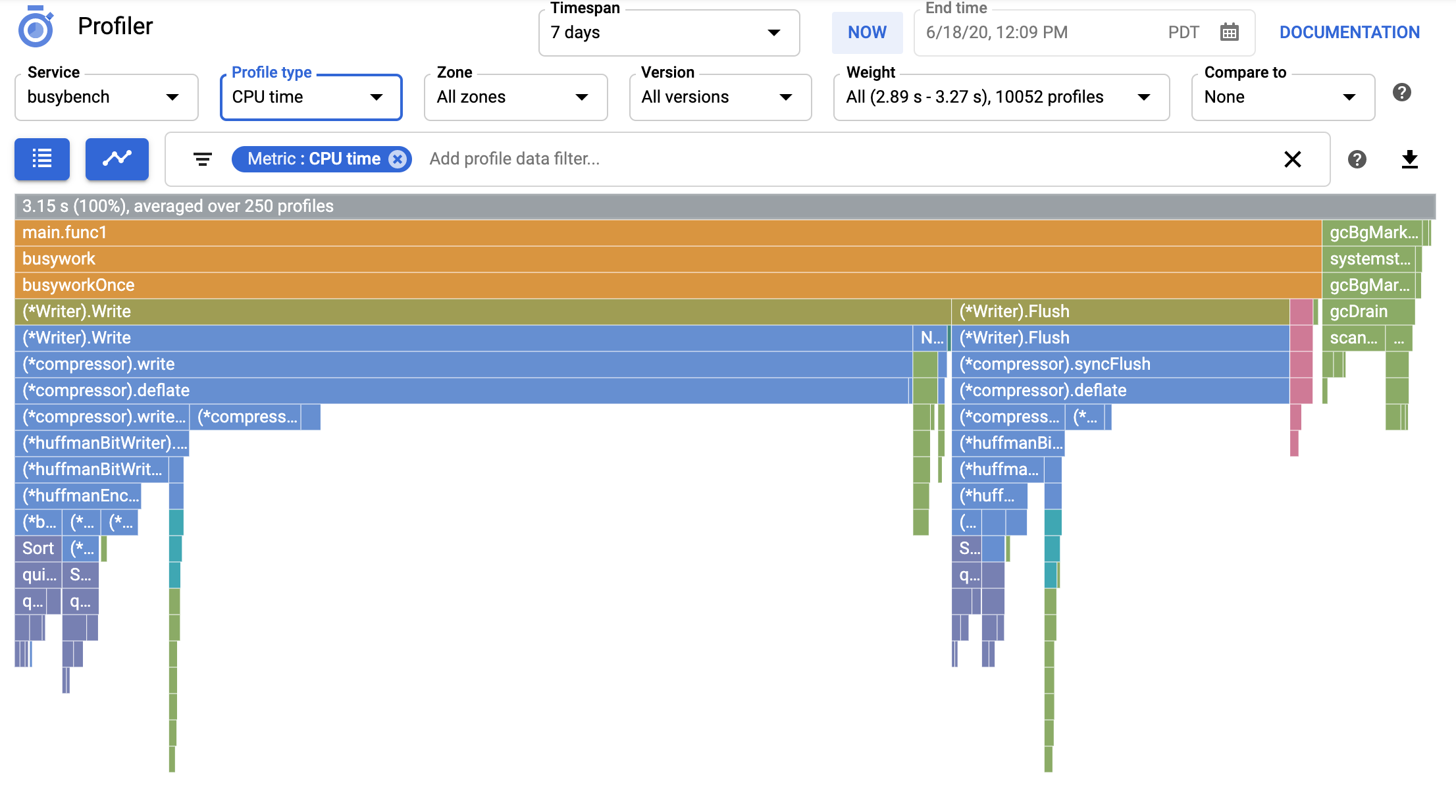
性能剖析数据将保留 30 天,因此您可以分析最长 30 天以内的性能数据。您可以下载性能剖析文件以长期存储。
配额和限制
如需了解如何查看和管理您的 Profiler 配额,请参阅配额和限制。
数据安全
Cloud Profiler 是 VPC Service Controls 支持的一项服务。如需了解详情,请参阅 VPC Service Controls 文档。