Per addestrare il tuo modello personalizzato, fornisci esempi rappresentativi del tipo di documenti da analizzare, etichettati in modo che AutoML Natural Language etichetti documenti simili. La qualità dei dati di addestramento ha un impatto significativo sull'efficacia del modello creato e, di conseguenza, sulla qualità delle previsioni restituite da quel modello.
Raccolta ed etichettatura dei documenti di addestramento
Il primo passaggio consiste nel raccogliere un insieme eterogeneo di documenti di addestramento che riflettano l'intervallo di documenti che deve essere gestito dal modello personalizzato. I passaggi di preparazione per i documenti di addestramento variano a seconda che tu stia addestrando un modello per la classificazione, l'estrazione delle entità o l'analisi del sentiment.
Estrazione di entità
Per addestrare un modello di estrazione delle entità, fornisci campioni rappresentativi del tipo di contenuti da analizzare, annotati con etichette che identificano i tipi di entità che vuoi che AutoML Natural Language identifichi.
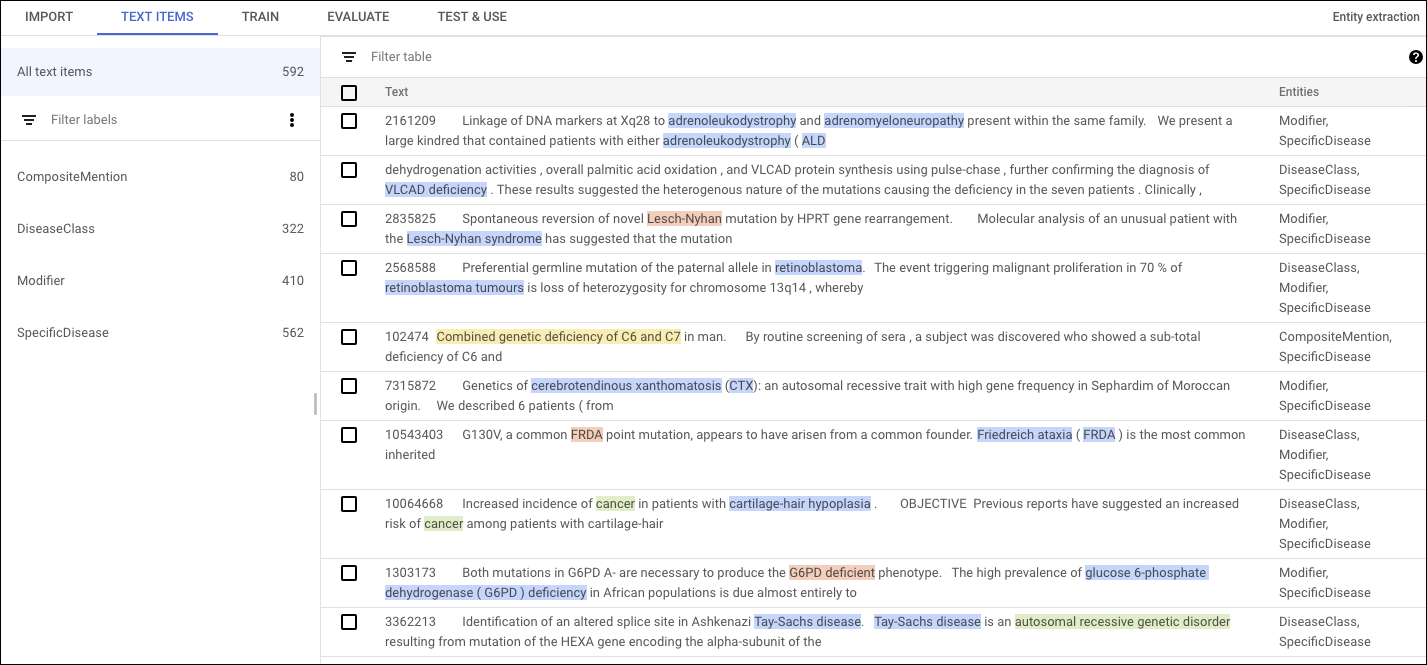
Fornisci tra 50 e 100.000 documenti da utilizzare per l'addestramento del modello personalizzato. Puoi utilizzare da una a 100 etichette univoche per annotare le entità che vuoi che il modello impari a estrarre. Ogni annotazione è un intervallo di testo con un'etichetta associata. I nomi delle etichette possono avere una lunghezza compresa tra 2 e 30 caratteri e possono essere utilizzati per annotare da una a 10 parole. Ti consigliamo di utilizzare ogni etichetta almeno 200 volte nel set di dati di addestramento.
Se stai annotando un tipo di documento strutturato o semistrutturato, ad esempio fatture o contratti, AutoML Natural Language può considerare la posizione di un'annotazione nella pagina come un fattore che contribuisce all'etichetta corretta. Ad esempio, un contratto immobiliare ha sia una data di accettazione che una data di chiusura e AutoML Natural Language può imparare a distinguere le entità in base alla posizione spaziale dell'annotazione.
Formattazione dei documenti di addestramento
Puoi caricare i dati di addestramento in AutoML Natural Language come file JSONL che contengono i documenti di esempio. Ogni riga del file è un singolo documento di addestramento, specificato in una di due forme:
- L'intero contenuto del documento, di lunghezza compresa tra 10 e 10.000 byte (con codifica UTF-8)
- L'URI di un file PDF o TIFF da un bucket Cloud Storage associato al tuo progetto
La considerazione della posizione spaziale è disponibile solo per i documenti di addestramento in formato PDF.
Puoi aggiungere annotazioni ai documenti di testo in tre modi:
- Annota i file JSONL direttamente prima di caricarli
- Aggiungi annotazioni nell'interfaccia utente di AutoML Natural Language dopo aver caricato documenti non annotati
- Richiedi l'etichettatura agli etichettatori umani utilizzando l'AI Platform Data Labeling Service
Puoi combinare le prime due opzioni caricando i file JSONL etichettati e modificandoli nell'interfaccia utente.
Puoi aggiungere annotazioni ai file PDF solo utilizzando l'interfaccia utente di AutoML Natural Language.
Documenti JSONL
Per aiutarti a creare file di addestramento JSONL, AutoML Natural Language offre uno script Python che converte i file di testo normale in file JSONL con formato appropriato. Leggi i commenti nello script per i dettagli.
Ogni documento nel file JSONL ha uno dei seguenti formati:
Ogni documento deve essere costituito da una riga del file JSONL. L'esempio seguente include interruzioni di riga per la leggibilità; devi rimuoverle nel file JSONL. Per ulteriori informazioni, visita il sito http://jsonlines.org/.
Per i documenti non annotati:
{
"text_snippet":
{"content": string}
}
Per i documenti annotati:
{
"annotations": [
{
"text_extraction": {
"text_segment": {
"end_offset": number, "start_offset": number
}
},
"display_name": string
},
{
"text_extraction": {
"text_segment": {
"end_offset": number, "start_offset": number
}
},
"display_name": string
},
...
],
"text_snippet":
{"content": string}
}
Ogni elemento text_extraction identifica un'annotazione all'interno di
text_snippet.content. Indica la posizione del testo annotato specificando il numero di caratteri dall'inizio di text_snippet.content all'inizio (start_offset) e alla fine (end_offset) del testo; display_name è l'etichetta dell'entità.
Sia start_offset che end_offset' sono offset di caratteri
piuttosto che offset di byte. Il carattere in corrispondenza di end_offset non è incluso nel segmento di testo. Consulta la pagina TextSegment
per ulteriori dettagli. Gli elementi text_extraction sono facoltativi; puoi ometterli se prevedi di annotare il documento utilizzando l'interfaccia utente di AutoML Natural Language. Ogni annotazione può coprire fino a dieci token (parole). Non possono sovrapporsi; il start_offset di un'annotazione non può essere compreso tra start_offset e end_offset di un'annotazione nello stesso documento.
Ad esempio, questo documento di formazione di esempio identifica le malattie specifiche menzionate in un estratto del corpus della NCBI.
{
"annotations": [
{
"text_extraction": {
"text_segment": {
"end_offset": 67,
"start_offset": 62
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 158,
"start_offset": 141
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 330,
"start_offset": 290
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 337,
"start_offset": 332
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 627,
"start_offset": 610
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 754,
"start_offset": 749
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 875,
"start_offset": 865
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 968,
"start_offset": 951
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1553,
"start_offset": 1548
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1652,
"start_offset": 1606
}
},
"display_name": "CompositeMention"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1833,
"start_offset": 1826
}
},
"display_name": "DiseaseClass"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1860,
"start_offset": 1843
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1930,
"start_offset": 1913
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2129,
"start_offset": 2111
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2188,
"start_offset": 2160
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2260,
"start_offset": 2243
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2356,
"start_offset": 2339
}
},
"display_name": "Modifier"
}
],
"text_snippet": {
"content": "10051005\tA common MSH2 mutation in English and North American HNPCC families:
origin, phenotypic expression, and sex specific differences in colorectal cancer .\tThe
frequency , origin , and phenotypic expression of a germline MSH2 gene mutation previously
identified in seven kindreds with hereditary non-polyposis cancer syndrome (HNPCC) was
investigated . The mutation ( A-- > T at nt943 + 3 ) disrupts the 3 splice site of exon 5
leading to the deletion of this exon from MSH2 mRNA and represents the only frequent MSH2
mutation so far reported . Although this mutation was initially detected in four of 33
colorectal cancer families analysed from eastern England , more extensive analysis has
reduced the frequency to four of 52 ( 8 % ) English HNPCC kindreds analysed . In contrast ,
the MSH2 mutation was identified in 10 of 20 ( 50 % ) separately identified colorectal
families from Newfoundland . To investigate the origin of this mutation in colorectal cancer
families from England ( n = 4 ) , Newfoundland ( n = 10 ) , and the United States ( n = 3 ) ,
haplotype analysis using microsatellite markers linked to MSH2 was performed . Within the
English and US families there was little evidence for a recent common origin of the MSH2
splice site mutation in most families . In contrast , a common haplotype was identified
at the two flanking markers ( CA5 and D2S288 ) in eight of the Newfoundland families .
These findings suggested a founder effect within Newfoundland similar to that reported by
others for two MLH1 mutations in Finnish HNPCC families . We calculated age related risks
of all , colorectal , endometrial , and ovarian cancers in nt943 + 3 A-- > T MSH2 mutation
carriers ( n = 76 ) for all patients and for men and women separately . For both sexes combined ,
the penetrances at age 60 years for all cancers and for colorectal cancer were 0 . 86 and 0 . 57 ,
respectively . The risk of colorectal cancer was significantly higher ( p < 0.01 ) in males
than females ( 0 . 63 v 0 . 30 and 0 . 84 v 0 . 44 at ages 50 and 60 years , respectively ) .
For females there was a high risk of endometrial cancer ( 0 . 5 at age 60 years ) and premenopausal
ovarian cancer ( 0 . 2 at 50 years ) . These intersex differences in colorectal cancer risks
have implications for screening programmes and for attempts to identify colorectal cancer
susceptibility modifiers .\n "
}
}
Un file JSONL può contenere più documenti di addestramento con questa struttura, uno per ogni riga del file.
Documenti PDF o TIFF
Per caricare un file PDF o TIFF come documento, aggrega il percorso del file all'interno di un elemento document JSONL:
Ogni documento deve essere costituito da una riga del file JSONL. L'esempio seguente include interruzioni di riga per la leggibilità; devi rimuoverle nel file JSONL. Per ulteriori informazioni, visita il sito http://jsonlines.org/.
{
"document": {
"input_config": {
"gcs_source": {
"input_uris": [ "gs://cloud-ml-data/NL-entity/sample.pdf" ]
}
}
}
}
Il valore dell'elemento input_uris è il percorso di un file PDF o TIFF in un bucket Cloud Storage associato al progetto. La dimensione massima del file PDF o TIFF è 2 MB.
Importazione dei documenti di addestramento
Puoi importare i dati di addestramento in AutoML Natural Language utilizzando un file CSV che elenca i documenti e, facoltativamente, include le etichette delle categorie o i valori di sentiment. AutoML Natural Language crea un set di dati dai documenti elencati.
Dati di addestramento e di valutazione
AutoML Natural Language suddivide i documenti di addestramento in tre set per addestrare un modello: un set di addestramento, un set di convalida e un set di test.
AutoML Natural Language utilizza il set di addestramento per creare il modello. Il modello prova più algoritmi e parametri durante la ricerca di pattern nei dati di addestramento. Poiché il modello identifica i pattern, utilizza il set di convalida per testare algoritmi e pattern. AutoML Natural Language sceglie gli algoritmi e i pattern con le migliori prestazioni tra quelli identificati durante la fase di addestramento.
Dopo aver identificato gli algoritmi e i pattern con le migliori prestazioni, AutoML Natural Language li applica al set di test per verificare il tasso di errore, la qualità e l'accuratezza.
Per impostazione predefinita, AutoML Natural Language suddivide i dati di addestramento in modo casuale nei tre insiemi:
- L'80% dei documenti viene utilizzato per l'addestramento
- Il 10% dei documenti viene utilizzato per la convalida (ottimizzazione iperparametri e/o per decidere quando interrompere l'addestramento)
- Il 10% dei documenti è riservato ai test (non viene utilizzato durante l'addestramento)
Se vuoi specificare a quale set deve appartenere ogni documento nei tuoi dati di addestramento, puoi assegnare esplicitamente i documenti ai set nel file CSV, come descritto nella sezione successiva.
Creazione di un file CSV di importazione
Dopo aver raccolto tutti i documenti di addestramento, crea un file CSV che li elenca tutti. Il file CSV può avere qualsiasi nome, deve avere la codifica UTF-8 e deve terminare con un'estensione .csv. Deve essere archiviato nel bucket Cloud Storage associato al progetto.
Il file CSV ha una riga per ogni documento di addestramento, con le seguenti colonne per riga:
Quale insieme a cui assegnare i contenuti di questa riga. Questa colonna è facoltativa e può avere uno dei seguenti valori:
TRAIN: utilizza document per addestrare il modello.VALIDATION: utilizza document per convalidare i risultati restituiti dal modello durante l'addestramento.TEST: utilizza document per verificare i risultati del modello dopo l'addestramento.
Se includi valori in questa colonna per specificare gli insiemi, ti consigliamo di identificare almeno il 5% dei dati per ogni categoria. L'utilizzo di meno del 5% dei dati per addestramento, convalida o test può produrre risultati inaspettati e modelli inefficaci.
Se non includi valori in questa colonna, fai iniziare ogni riga con una virgola per indicare la prima colonna vuota. AutoML Natural Language suddivide automaticamente i documenti in tre set, utilizzando circa l'80% dei dati per l'addestramento, il 10% per la convalida e il 10% per i test (fino a 10.000 coppie per convalida e test).
I contenuti da classificare. Questa colonna contiene l'URI Cloud Storage del documento. Gli URI Cloud Storage sono sensibili alle maiuscole.
Per la classificazione e l'analisi del sentiment, il documento può essere un file di testo, un file PDF, un file TIFF o un file ZIP; per l'estrazione di entità, è un file JSONL.
Per la classificazione e l'analisi del sentiment, il valore in questa colonna può essere riportato tra virgolette, anziché come URI Cloud Storage.
Per i set di dati di classificazione, puoi facoltativamente includere un elenco separato da virgole di etichette che identificano il modo in cui è classificato il documento. Le etichette devono iniziare con una lettera e contenere solo lettere, numeri e trattini bassi. Puoi includere fino a 20 etichette per ogni documento.
Per i set di dati di analisi del sentiment, puoi facoltativamente includere un numero intero che indichi il valore di sentiment per il contenuto. Il valore del sentiment va da 0 (fortemente negativo) a un valore massimo di 10 (fortemente positivo).
Ad esempio, il file CSV per un set di dati di classificazione con più etichette potrebbe avere:
TRAIN, gs://my-project-lcm/training-data/file1.txt,Sports,Basketball VALIDATION, gs://my-project-lcm/training-data/ubuntu.zip,Computers,Software,Operating_Systems,Linux,Ubuntu TRAIN, gs://news/documents/file2.txt,Sports,Baseball TEST, "Miles Davis was an American jazz trumpeter, bandleader, and composer.",Arts_Entertainment,Music,Jazz TRAIN,gs://my-project-lcm/training-data/astros.txt,Sports,Baseball VALIDATION,gs://my-project-lcm/training-data/mariners.txt,Sports,Baseball TEST,gs://my-project-lcm/training-data/cubs.txt,Sports,Baseball
Errori comuni relativi ai file CSV
- Utilizzo di caratteri Unicode nelle etichette. Ad esempio, i caratteri giapponesi non sono supportati.
- Utilizzare spazi e caratteri non alfanumerici nelle etichette.
- Righe vuote.
- Colonne vuote (righe con due virgole successive).
- Racchiuso tra virgolette per il testo incorporato che include virgole.
- Uso errato delle lettere maiuscole nei percorsi di Cloud Storage.
- Controllo dell'accesso non corretto configurato per i tuoi documenti. Il tuo account di servizio deve disporre di un accesso in lettura o superiore oppure i file devono essere leggibili pubblicamente.
- Riferimenti a file non di testo, ad esempio i file JPEG. Allo stesso modo, i file che non sono file di testo, ma che sono stati rinominati con un'estensione di testo, causeranno un errore.
- L'URI di un documento punta a un bucket diverso da quello del progetto corrente. È possibile accedere solo ai file nel bucket del progetto.
- File non in formato CSV.
Creazione di un file ZIP di importazione
Per i set di dati di classificazione, puoi importare i documenti di addestramento utilizzando un file ZIP. All'interno del file ZIP, crea una cartella per ogni valore di etichetta o sentiment e salva ogni documento all'interno della cartella corrispondente all'etichetta o al valore da applicare al documento. Ad esempio, il file ZIP per un modello che classifica la corrispondenza aziendale potrebbe avere questa struttura:
correspondence.zip
transactional
letter1.pdf
letter2.pdf
letter5.pdf
persuasive
letter3.pdf
letter7.pdf
letter8.pdf
informational
letter6.pdf
instructional
letter4.pdf
letter9.pdf
AutoML Natural Language applica i nomi delle cartelle come etichette ai documenti al loro interno. Per un set di dati di analisi del sentiment, i nomi delle cartelle sono i valori del sentiment:
sentiment.zip
0
document4.txt
1
document3.txt
document1.txt
document5.txt
2
document2.txt
document6.txt
document8.txt
document9.txt
3
document7.txt
Passaggi successivi
- Importa i dati per creare il set di dati.