Introduzione
Immagina che il tuo sito web della tua attività abbia un modulo di contatto. Ogni giorno ricevi molti messaggi dal modulo, molti dei quali sono in qualche modo attuabili, ma vengono tutti inseriti insieme ed è facile rimanere indietro nel modo in cui trattarli, dato che dipendenti diversi gestiscono tipi di messaggi diversi. Sarebbe fantastico se un sistema automatizzato potesse categorizzare i commenti in modo che la persona giusta veda i commenti giusti.
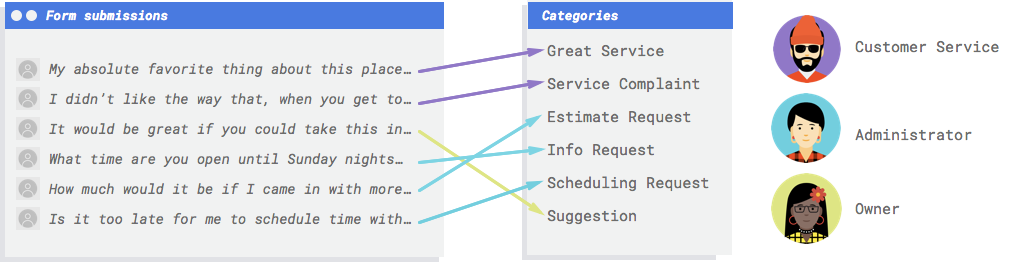
Hai bisogno di un sistema per esaminare i commenti e decidere se rappresentano reclami, elogi per il servizio passato, un tentativo di saperne di più sulla tua attività, fissare un appuntamento o stabilire una relazione.
Perché il machine learning (ML) è lo strumento giusto per risolvere questo problema?
 Per utilizzare la programmazione classica, il programmatore deve specificare le istruzioni dettagliate da seguire per il computer. Ma questo approccio diventa rapidamente impossibile. I commenti dei clienti utilizzano un vocabolario e una struttura ampi e diversi, troppo diversificati per essere acquisiti da un semplice insieme di regole. Se provassi a creare filtri manuali, scoprirai rapidamente che non sei riuscito a classificare la stragrande maggioranza dei commenti
dei clienti. Hai bisogno di un sistema in grado di generalizzare un'ampia varietà di commenti.
In uno scenario in cui una sequenza di regole specifiche è destinata a espandersi in modo esponenziale,
è necessario un sistema che possa apprendere dagli esempi. Fortunatamente, i sistemi di machine learning
sono in una posizione ideale per risolvere questo problema.
Per utilizzare la programmazione classica, il programmatore deve specificare le istruzioni dettagliate da seguire per il computer. Ma questo approccio diventa rapidamente impossibile. I commenti dei clienti utilizzano un vocabolario e una struttura ampi e diversi, troppo diversificati per essere acquisiti da un semplice insieme di regole. Se provassi a creare filtri manuali, scoprirai rapidamente che non sei riuscito a classificare la stragrande maggioranza dei commenti
dei clienti. Hai bisogno di un sistema in grado di generalizzare un'ampia varietà di commenti.
In uno scenario in cui una sequenza di regole specifiche è destinata a espandersi in modo esponenziale,
è necessario un sistema che possa apprendere dagli esempi. Fortunatamente, i sistemi di machine learning
sono in una posizione ideale per risolvere questo problema.
L'API Cloud Natural Language o AutoML Natural Language sono lo strumento giusto per me?
L'API Natural Language rileva sintassi, entità e sentiment nel testo e classifica il testo in un insieme predefinito di categorie. Se il testo è costituito da articoli o altri contenuti che vuoi classificare o se vuoi conoscere il sentiment dei tuoi esempi, ti consigliamo di provare l'API Natural Language. Tuttavia, se i tuoi esempi di testo non si adattano perfettamente allo schema di classificazione basato sul sentiment o sull'argomento verticale disponibile nell'API Natural Language e vuoi utilizzare le tue etichette, vale la pena provare un classificatore personalizzato per vedere se è adatto alle tue esigenze.
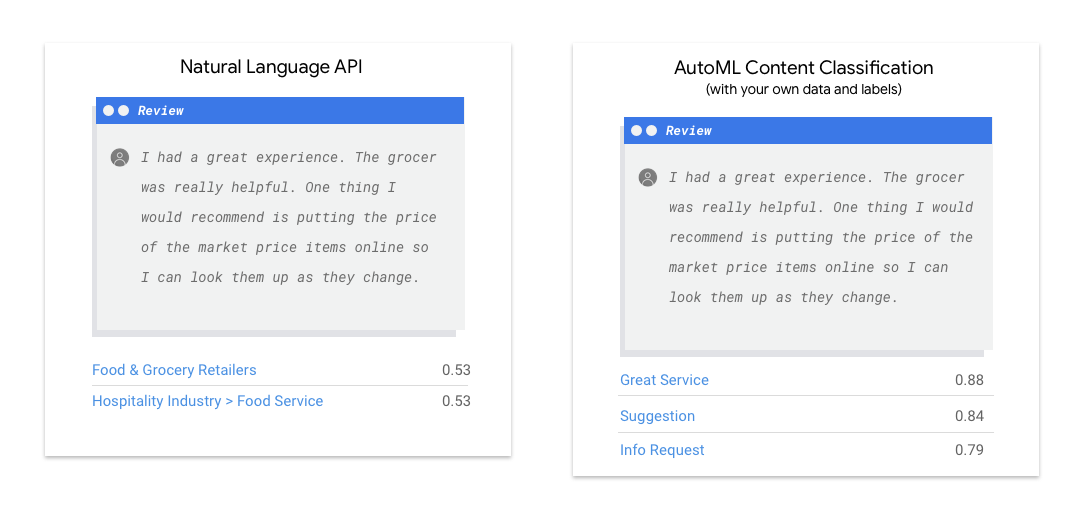
| Prova l'API Natural Language | Inizia a utilizzare AutoML |
Cosa comporta il machine learning in AutoML Natural Language?
 Il machine learning prevede l'utilizzo dei dati per addestrare gli algoritmi e ottenere il risultato desiderato. Le specifiche dell'algoritmo e dei metodi di addestramento cambiano in base al caso d'uso. Esistono numerose sottocategorie di machine learning, che risolvono problemi diversi e funzionano all'interno di vincoli differenti. AutoML Natural Language consente
di eseguire l'apprendimento supervisionato, ovvero di addestrare un computer a riconoscere
pattern a partire da dati etichettati. Con l'apprendimento supervisionato, puoi addestrare un modello
personalizzato affinché riconosca i contenuti che ti interessano.
Il machine learning prevede l'utilizzo dei dati per addestrare gli algoritmi e ottenere il risultato desiderato. Le specifiche dell'algoritmo e dei metodi di addestramento cambiano in base al caso d'uso. Esistono numerose sottocategorie di machine learning, che risolvono problemi diversi e funzionano all'interno di vincoli differenti. AutoML Natural Language consente
di eseguire l'apprendimento supervisionato, ovvero di addestrare un computer a riconoscere
pattern a partire da dati etichettati. Con l'apprendimento supervisionato, puoi addestrare un modello
personalizzato affinché riconosca i contenuti che ti interessano.
Preparazione dati
Per addestrare un modello personalizzato con AutoML Natural Language, devi fornire esempi etichettati dei tipi di elementi di testo (input) che vuoi classificare e le categorie o etichette (la risposta) che vuoi che i sistemi di ML prevedano.
Valuta il tuo caso d'uso

Quando componi il set di dati, inizia sempre con il caso d'uso. Puoi iniziare con le seguenti domande:
- Quale risultato stai cercando di ottenere?
- Quali tipi di categorie devi riconoscere per ottenere questo risultato?
- Gli esseri umani possono riconoscere queste categorie? Sebbene AutoML Natural Language sia in grado di gestire più categorie di quelle che gli esseri umani possono ricordare e assegnare in qualsiasi momento, se un essere umano non è in grado di riconoscere una categoria specifica, anche AutoML Natural Language avrà difficoltà.
- Quali tipi di esempi potrebbero riflettere meglio il tipo e l'intervallo di dati che verranno classificati dal sistema?
Uno dei principi fondamentali alla base dei prodotti ML di Google è il machine learning incentrato sulla persona, un approccio che mette in primo piano le pratiche di un'IA responsabile, inclusa l'equità. L'obiettivo dell'equità nel machine learning è comprendere e prevenire trattamenti ingiusti o pregiudizievoli delle persone in relazione a gruppo etnico, reddito, orientamento sessuale, religione, genere e altre caratteristiche storicamente associate alla discriminazione e all'emarginazione, nonché capire quando e dove si manifestano nei sistemi algoritmici o nel processo decisionale assistito da algoritmi. Puoi scoprire di più nella Guida al machine learning inclusivo e trovare note "fair-aware" ✽ nelle linee guida riportate di seguito. Mentre leggi le linee guida per la creazione del set di dati, ti invitiamo a considerare l'equità nel machine learning laddove pertinente per il tuo caso d'uso.
Ottieni i dati da un'origine
 Dopo aver stabilito di quali dati hai bisogno, devi trovare un modo per recuperarli. Puoi iniziare prendendo in considerazione tutti i dati raccolti dalla tua organizzazione.
Potresti scoprire che stai già raccogliendo i dati necessari per addestrare un modello.
Se non disponi dei dati di cui hai bisogno, puoi ottenerli manualmente o affidarli a un fornitore di terze parti.
Dopo aver stabilito di quali dati hai bisogno, devi trovare un modo per recuperarli. Puoi iniziare prendendo in considerazione tutti i dati raccolti dalla tua organizzazione.
Potresti scoprire che stai già raccogliendo i dati necessari per addestrare un modello.
Se non disponi dei dati di cui hai bisogno, puoi ottenerli manualmente o affidarli a un fornitore di terze parti.
Includi un numero sufficiente di esempi etichettati in ogni categoria
 Il minimo indispensabile richiesto da AutoML Natural Language per l'addestramento è di 10 esempi di testo per categoria/etichetta.
La probabilità di riconoscere correttamente un'etichetta aumenta con il numero di esempi di alta qualità per ciascuna. In generale, più dati etichettati puoi introdurre nel processo di addestramento, migliore sarà il modello. Il numero di campioni necessari varia anche in base al grado di coerenza dei dati che vuoi prevedere e al livello di precisione target. Puoi utilizzare meno esempi per
set di dati coerenti o per ottenere un'accuratezza dell'80% anziché del 97%.
Addestra un modello utilizzando 50 esempi per etichetta, quindi valuta i risultati. Aggiungi altri esempi e riaddestra finché non raggiungi i tuoi obiettivi di precisione, il che potrebbe richiedere centinaia o addirittura migliaia di esempi per etichetta.
Il minimo indispensabile richiesto da AutoML Natural Language per l'addestramento è di 10 esempi di testo per categoria/etichetta.
La probabilità di riconoscere correttamente un'etichetta aumenta con il numero di esempi di alta qualità per ciascuna. In generale, più dati etichettati puoi introdurre nel processo di addestramento, migliore sarà il modello. Il numero di campioni necessari varia anche in base al grado di coerenza dei dati che vuoi prevedere e al livello di precisione target. Puoi utilizzare meno esempi per
set di dati coerenti o per ottenere un'accuratezza dell'80% anziché del 97%.
Addestra un modello utilizzando 50 esempi per etichetta, quindi valuta i risultati. Aggiungi altri esempi e riaddestra finché non raggiungi i tuoi obiettivi di precisione, il che potrebbe richiedere centinaia o addirittura migliaia di esempi per etichetta.
Distribuisci equamente gli esempi tra le categorie
È importante acquisire un numero più o meno simile di esempi di addestramento per ogni categoria. Anche se hai un'abbondanza di dati per un'etichetta, è meglio avere una distribuzione uguale per ogni etichetta. Per capire perché, immagina che l'80% dei commenti dei clienti che utilizzi per creare il tuo modello siano richieste di stime. Con una distribuzione così sbilanciata delle etichette, è molto probabile che il tuo modello impari che puoi sempre dirti che un commento del cliente è una richiesta di stima, piuttosto che cercare di prevedere un'etichetta molto meno comune. È come scrivere un test a scelta multipla in cui quasi tutte le risposte corrette sono "C". Presto il tuo candidato esperto capirà di poter rispondere "C" ogni volta, senza nemmeno guardare la domanda.

Potrebbe non essere sempre possibile fornire un numero approssimativamente uguale di esempi per ogni etichetta. Potrebbe essere più difficile reperire esempi di alta qualità e imparziali per alcune categorie. In questi casi, l'etichetta con il numero più basso di esempi dovrebbe avere almeno il 10% di esempi come l'etichetta con il maggior numero di esempi. Quindi, se l'etichetta più grande ha 10.000 esempi, l'etichetta più piccola dovrebbe avere almeno 1000 esempi.
Acquisisci la variazione dello spazio problematico
Per motivi simili, cerca di fare in modo che i tuoi dati catturino la varietà e la diversità dello spazio dei problemi. Se fornisci un insieme più ampio di esempi, il modello è più in grado di generalizzare a nuovi dati. Supponiamo che tu stia cercando di classificare in argomenti articoli sull'elettronica di consumo. Più nomi di brand e specifiche tecniche fornisci, più facile sarà per il modello capire l'argomento di un articolo, anche se l'articolo riguarda un brand che non è stato incluso nel set di addestramento. Potresti anche prendere in considerazione l'inclusione di un'etichetta "none_of_the_above" per i documenti che non corrispondono a nessuna delle etichette definite per migliorare ulteriormente le prestazioni del modello.
Abbina i dati all'output previsto per il modello

Trova esempi di testo simili a quelli su cui prevedi di fare previsioni. Se stai cercando di classificare post sui social media sulla soffiatura del vetro, probabilmente non otterrai ottime prestazioni da un modello addestrato su siti web di informazioni sulla soffiatura del vetro, poiché il vocabolario e lo stile potrebbero essere molto diversi. Idealmente, gli esempi di addestramento sono dati reali ricavati dallo stesso set di dati in cui prevedi di utilizzare il modello per la classificazione.
Considera come AutoML Natural Language utilizza il tuo set di dati per creare un modello personalizzato
Il set di dati contiene set di addestramento, convalida e test. Se non specifichi le suddivisioni come spiegato in Preparare i dati, AutoML Natural Language utilizza automaticamente l'80% dei documenti relativi ai contenuti per l'addestramento, il 10% per la convalida e il 10% per i test.
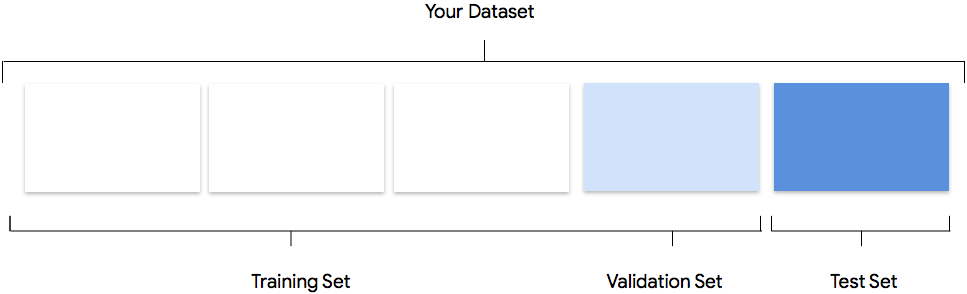
Set per l'addestramento
 La maggior parte dei tuoi dati dovrebbe essere nel set di addestramento. Si tratta dei dati che il modello "vede" durante l'addestramento e viene utilizzato per apprendere i parametri del modello, ovvero i pesi delle connessioni tra i nodi della rete neurale.
La maggior parte dei tuoi dati dovrebbe essere nel set di addestramento. Si tratta dei dati che il modello "vede" durante l'addestramento e viene utilizzato per apprendere i parametri del modello, ovvero i pesi delle connessioni tra i nodi della rete neurale.
Set di convalida
 Il set di convalida, a volte chiamato anche set "dev", viene utilizzato anche durante il processo di addestramento. Dopo che il framework di apprendimento del modello ha incorporato i dati di addestramento durante ogni iterazione del processo di addestramento, utilizza le prestazioni del modello sul set di convalida per ottimizzare gli iperparametri del modello, variabili che specificano la struttura del modello. Se provi a utilizzare il set di addestramento per ottimizzare gli iperparametri, è probabile che il modello finisca eccessivamente sui dati di addestramento e abbia difficoltà a generalizzare gli esempi che non corrispondono esattamente. L'utilizzo di un set di dati innovativo per perfezionare la struttura del modello
significa che il modello si generalizza meglio.
Il set di convalida, a volte chiamato anche set "dev", viene utilizzato anche durante il processo di addestramento. Dopo che il framework di apprendimento del modello ha incorporato i dati di addestramento durante ogni iterazione del processo di addestramento, utilizza le prestazioni del modello sul set di convalida per ottimizzare gli iperparametri del modello, variabili che specificano la struttura del modello. Se provi a utilizzare il set di addestramento per ottimizzare gli iperparametri, è probabile che il modello finisca eccessivamente sui dati di addestramento e abbia difficoltà a generalizzare gli esempi che non corrispondono esattamente. L'utilizzo di un set di dati innovativo per perfezionare la struttura del modello
significa che il modello si generalizza meglio.
Set di test
 Il set di test non è coinvolto nel processo di addestramento. Una volta completato l'addestramento del modello, AutoML Natural Language utilizza il set di test come verifica del modello. Le prestazioni del modello nel set di test hanno lo scopo di darti un'idea delle prestazioni del modello sui dati reali.
Il set di test non è coinvolto nel processo di addestramento. Una volta completato l'addestramento del modello, AutoML Natural Language utilizza il set di test come verifica del modello. Le prestazioni del modello nel set di test hanno lo scopo di darti un'idea delle prestazioni del modello sui dati reali.
Suddivisione manuale
 Puoi suddividere autonomamente il set di dati. La suddivisione manuale dei dati ti consente di esercitare un maggiore controllo sul processo o se ci sono esempi specifici che sicuramente vorrai includere in una determinata parte del tuo ciclo di vita di addestramento del modello.
Puoi suddividere autonomamente il set di dati. La suddivisione manuale dei dati ti consente di esercitare un maggiore controllo sul processo o se ci sono esempi specifici che sicuramente vorrai includere in una determinata parte del tuo ciclo di vita di addestramento del modello.
Prepara i dati per l'importazione

Dopo aver deciso se una suddivisione manuale o automatica dei dati è adatta alle tue esigenze, puoi aggiungere dati in AutoML Natural Language in tre modi:
- Puoi importare i dati con gli esempi di testo ordinati e archiviati in cartelle corrispondenti alle tue etichette.
- Puoi importare i dati dal computer o da Cloud Storage in formato CSV con le etichette incorporate, come specificato in Preparazione dei dati di addestramento. Se vuoi suddividere il set di dati manualmente, devi scegliere questa opzione e formattare il file CSV di conseguenza.
- Se i dati non sono stati etichettati, puoi caricare esempi di testo senza etichetta e utilizzare l'interfaccia utente di AutoML Natural Language per applicare etichette a ognuno.
Valuta
Dopo l'addestramento del modello, riceverai un riepilogo delle sue prestazioni. Per visualizzare un'analisi dettagliata, fai clic su evaluate o evaluate.
Che cosa devo ricordare prima di valutare il mio modello?
 Eseguire il debug di un modello riguarda più il debug dei dati che del modello stesso. Se il modello inizia ad agire in modo imprevisto mentre ne valuti le prestazioni prima e dopo il push in produzione, devi restituire i dati e controllarli per capire dove potrebbero essere migliorati.
Eseguire il debug di un modello riguarda più il debug dei dati che del modello stesso. Se il modello inizia ad agire in modo imprevisto mentre ne valuti le prestazioni prima e dopo il push in produzione, devi restituire i dati e controllarli per capire dove potrebbero essere migliorati.
Che tipo di analisi posso eseguire in AutoML Natural Language?
Nella sezione sulla valutazione di AutoML Natural Language, puoi valutare le prestazioni del tuo modello personalizzato utilizzando l'output del modello su esempi di test e metriche comuni di machine learning. Questa sezione illustra il significato di ciascuno dei seguenti concetti:
- L'output del modello
- Soglia di punteggio
- Veri positivi, veri negativi, falsi positivi e falsi negativi
- Precisione e richiamo
- Curve di precisione/richiamo
- Precisione media
Come faccio a interpretare l'output del modello?
AutoML Natural Language estrae esempi dai dati di test per presentare nuove sfide per il tuo modello. Per ogni esempio, il modello restituisce una serie di numeri che indicano il livello di associazione di ogni etichetta all'esempio in questione. Se il numero è alto, il modello ha un'elevata probabilità di applicare l'etichetta al documento.
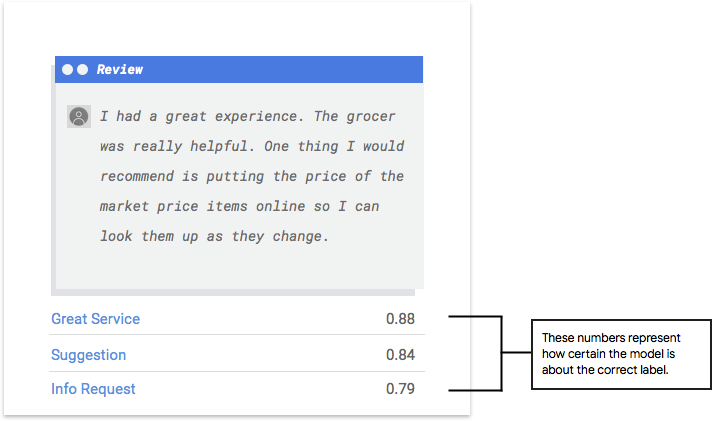
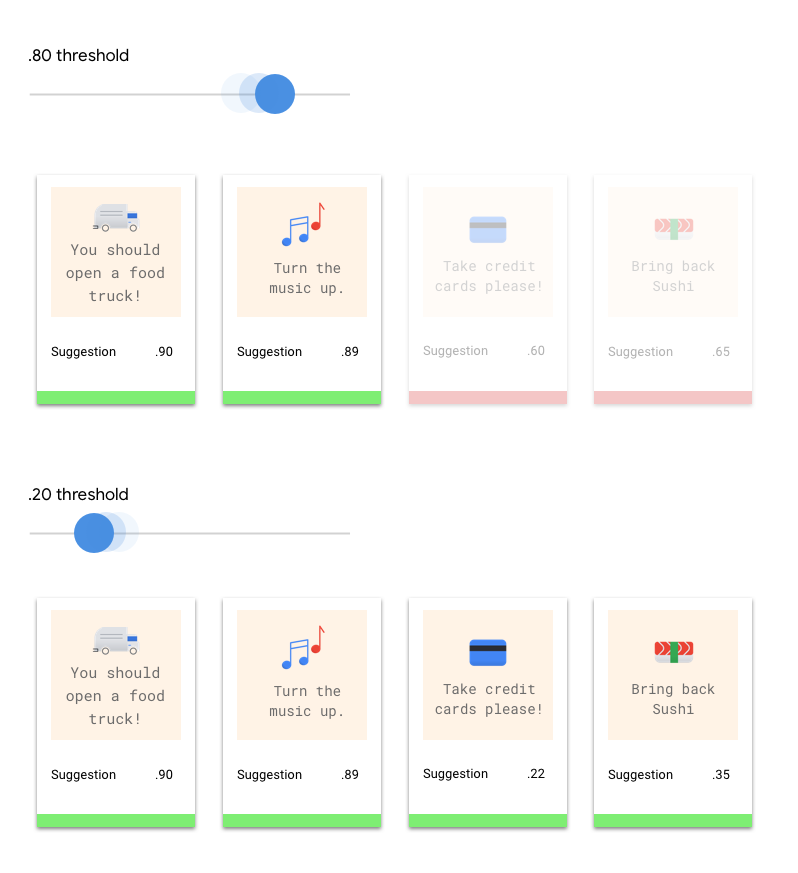
Che cos'è la soglia di punteggio?
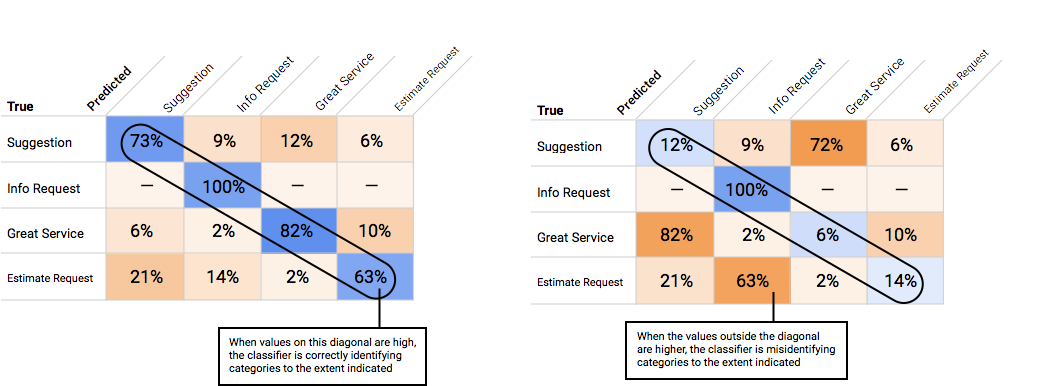
La soglia di punteggio consente ad AutoML Natural Language di convertire le probabilità in valori binari "on"/"off". La soglia di punteggio si riferisce al livello di affidabilità che il modello deve assegnare una categoria a un elemento di test. Il cursore della soglia di punteggio nella UI è uno strumento visivo per testare l'impatto di soglie diverse nel tuo set di dati. Nell'esempio precedente, se impostiamo la soglia di punteggio su 0,8 per tutte le categorie, vengono assegnati "Ottimo Servizio" e "Suggerimento", ma non "Richiesta di informazioni". Se la soglia di punteggio è bassa, il modello classificherà più elementi di testo, ma rischia di classificare in modo errato altri elementi di testo durante il processo. Se la soglia di punteggio è alta, il modello classificherà meno elementi di testo, ma il rischio di classificazioni erronee degli elementi di testo sarà minore. Per sperimentare, puoi modificare le soglie per categoria nell'interfaccia utente. Tuttavia, quando utilizzi il modello in produzione, dovrai applicare le soglie che ritieni ottimali sul tuo lato.
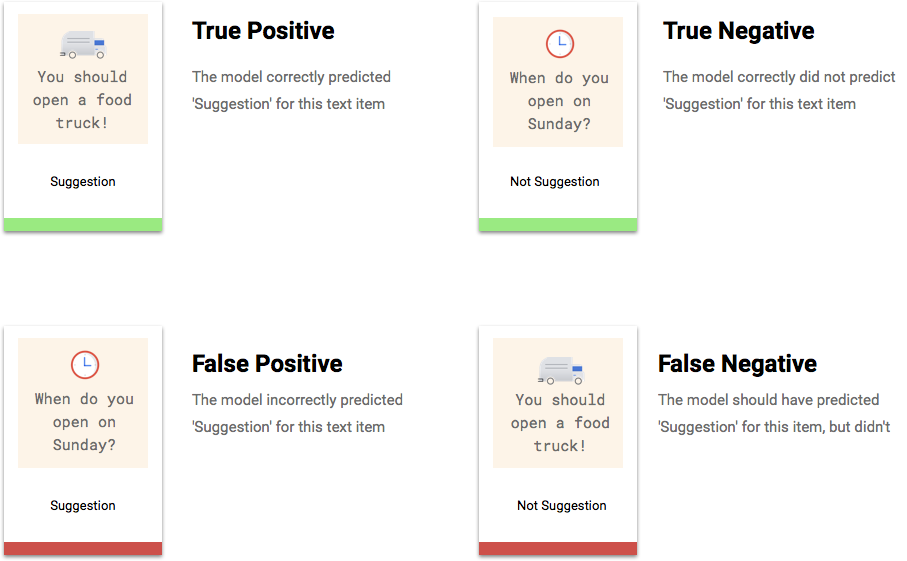
Cosa sono i veri positivi, i veri negativi, i falsi positivi e i falsi negativi?
Dopo aver applicato la soglia di punteggio, le previsioni effettuate dal modello rientrano in una delle quattro categorie seguenti.
Puoi utilizzare queste categorie per calcolare precisione e richiamo, metriche che aiutano a valutare l'efficacia del tuo modello.
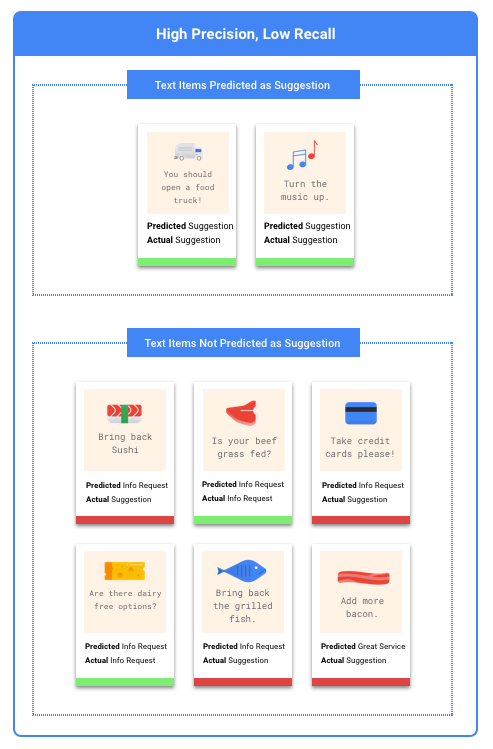
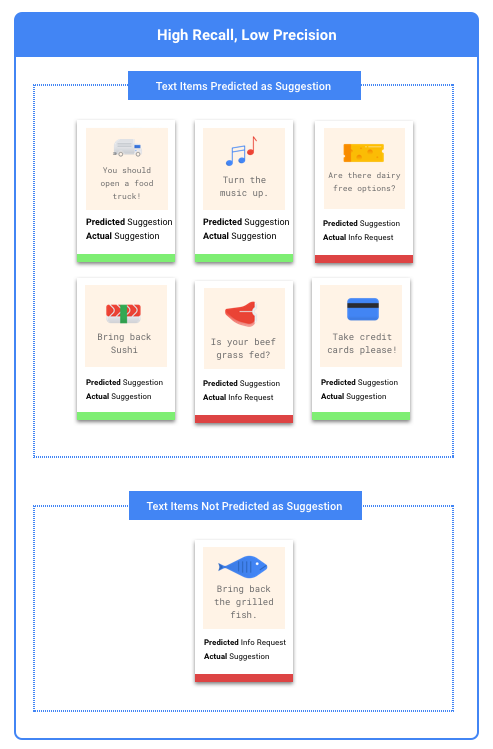
Che cosa sono la precisione e il richiamo?
La precisione e il richiamo ci aiutano a capire in che misura il nostro modello sta acquisendo le informazioni e quanto le omette. Da tutti gli esempi di test a cui è stata assegnata un'etichetta, la precisione ci indica quanti avrebbero dovuto essere classificati con quell'etichetta. Da tutti gli esempi di test che avrebbero dovuto assegnare l'etichetta, Richiamo indica a quanti di questi esempi l'etichetta era stata effettivamente assegnata.
Devo ottimizzare la precisione o il richiamo?
A seconda del tuo caso d'uso, ti consigliamo di ottimizzare per la precisione o il richiamo. Vediamo come puoi affrontare questa decisione con i seguenti due casi d'uso.
Caso d'uso: documenti urgenti
Supponiamo che tu voglia creare un sistema in grado di dare priorità ai documenti urgenti da quelli che non lo sono.

Un falso positivo in questo caso sarebbe un documento che non è urgente, ma viene contrassegnato come tale. L'utente può ignorarli come non urgenti e andare avanti.

Un falso negativo in questo caso potrebbe essere un documento urgente, ma il sistema non riesce a segnalarlo come tale. Questo potrebbe causare problemi.
In questo caso, ti consigliamo di eseguire l'ottimizzazione per il richiamo. Questa metrica misura, per tutte le previsioni effettuate, quanto viene tralasciato. È probabile che un modello ad alto richiamo etichetta gli esempi marginalmente pertinenti, il che è utile nei casi in cui la categoria abbia dati di addestramento scarsi.
Caso d'uso: filtro antispam
Supponiamo che tu voglia creare un sistema che filtri automaticamente i messaggi email che sono spam dai messaggi che non lo sono.

Un falso negativo in questo caso potrebbe essere un'email di spam che non viene rilevata e che vedi nella posta in arrivo. Solitamente, è solo un po' fastidioso.

Un falso positivo in questo caso potrebbe essere un'email erroneamente contrassegnata come spam e rimossa dalla posta in arrivo. Se l'email era importante, l'utente potrebbe essere interessato in modo negativo.
In questo caso, ti consigliamo di ottimizzare per la precisione. Questa metrica misura quanto sono corrette tutte le previsioni effettuate. È probabile che un modello ad alta precisione etichetta solo gli esempi più pertinenti, il che è utile nei casi in cui la tua categoria è comune nei dati di addestramento.
Come si utilizza la matrice di confusione?
Possiamo confrontare le prestazioni del modello su ogni etichetta utilizzando una matrice di confusione. In un modello ideale, tutti i valori in diagonale saranno alti, mentre tutti gli altri valori saranno bassi. Questo dimostra che le categorie desiderate vengono identificate correttamente. Se altri valori sono alti, ci danno un indizio su come il modello sta classificando erroneamente gli elementi di test.
Come si interpretano le curve di precisione-richiamo?
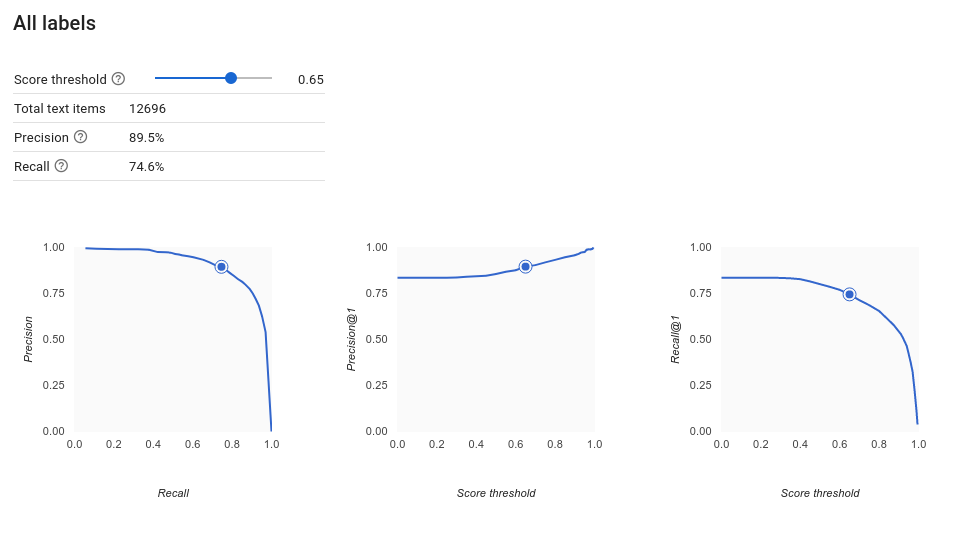
Lo strumento Soglia di punteggio ti consente di scoprire in che modo la soglia di punteggio che hai scelto influisce sulla precisione e sul richiamo. Trascinando il dispositivo di scorrimento sulla barra della soglia di punteggio, puoi vedere dove ti posiziona quella soglia sulla curva di compromesso precisione-richiamo e in che modo questa soglia influisce sulla precisione e sul richiamo individualmente (per i modelli multiclasse, in questi grafici, precisione e richiamo significa che l'unica etichetta utilizzata per calcolare le metriche di precisione e richiamo è l'etichetta con il punteggio più alto nell'insieme di etichette che restituiamo). Questo può aiutarti a trovare un buon equilibrio tra falsi positivi e falsi negativi.
Dopo aver scelto una soglia che sembra accettabile per il tuo modello nel complesso, puoi fare clic sulle singole etichette e vedere dove ricade sulla curva di precisione-richiamo per etichetta. In alcuni casi, può significare che ricevi molte previsioni errate per alcune etichette, il che può aiutarti a decidere di scegliere una soglia per classe personalizzata in base a quelle etichette. Ad esempio, supponiamo che, esaminando il set di dati dei commenti dei clienti, noti che una soglia pari a 0,5 abbia una precisione e un richiamo ragionevoli per ogni tipo di commento tranne "Suggerimento", forse perché è una categoria molto generica. Per quella categoria, puoi vedere un sacco di falsi positivi. In tal caso, potresti decidere di utilizzare una soglia di 0,8 solo per "Suggerimento" quando chiami il classificatore per le previsioni.
Che cos'è la precisione media?
Una metrica utile per l'accuratezza del modello è l'area sotto la curva di precisione-richiamo. Misura le prestazioni del modello in tutte le soglie di punteggio. In AutoML Natural Language, questa metrica si chiama Precisione media. Più questo punteggio è vicino a 1,0, migliori saranno le prestazioni del modello nel set di test; un modello che effettua ipotesi casuali per ogni etichetta otterrà una precisione media di circa 0,5.
Test del modello
 AutoML Natural Language utilizza automaticamente il 10% dei tuoi dati (o, se hai scelto personalmente la suddivisione dei dati, qualsiasi percentuale tu abbia scelto di utilizzare) per testare il modello e la pagina "Valuta" indica come ha fatto il modello su quei dati di test. Se, però, vuoi eseguire un controllo di integrità del modello, ci sono diversi modi per farlo. Il più semplice è inserire esempi di testo nella casella di testo della pagina "Previsione" e controllare le etichette scelte dal modello per i tuoi esempi. Spero che questo corrisponda
alle tue aspettative. Prova a fare alcuni esempi per ciascun tipo di commento che ti aspetti di ricevere.
AutoML Natural Language utilizza automaticamente il 10% dei tuoi dati (o, se hai scelto personalmente la suddivisione dei dati, qualsiasi percentuale tu abbia scelto di utilizzare) per testare il modello e la pagina "Valuta" indica come ha fatto il modello su quei dati di test. Se, però, vuoi eseguire un controllo di integrità del modello, ci sono diversi modi per farlo. Il più semplice è inserire esempi di testo nella casella di testo della pagina "Previsione" e controllare le etichette scelte dal modello per i tuoi esempi. Spero che questo corrisponda
alle tue aspettative. Prova a fare alcuni esempi per ciascun tipo di commento che ti aspetti di ricevere.
Se vuoi utilizzare il modello nei tuoi test automatici, nella pagina "Previsione" ti viene spiegato come effettuare chiamate al modello in modo programmatico.