A seconda delle dimensioni del set di dati e della complessità del modello, l'addestramento può richiedere molto tempo. L'addestramento con dati reali può durare molte ore. Puoi monitorare diversi aspetti del job durante l'esecuzione.
Controllo dello stato del job
Per lo stato generale, il modo più semplice per controllare il job è la pagina Job di addestramento della piattaforma AI nella console Google Cloud. Puoi ottenere gli stessi dettagli in modo programmatico e con Google Cloud CLI.
console
Apri la pagina Job di AI Platform Training nella console Google Cloud.
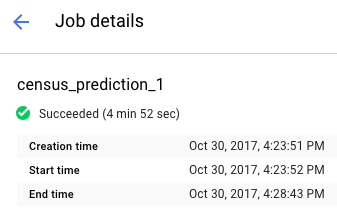
Fai clic sul nome del job nell'elenco per aprire la pagina Dettagli job.
Trova lo stato del tuo job nella parte superiore del report. L'icona e il testo descrive lo stato corrente del job.
Filtrare i job
Nella pagina Job, puoi filtrare i job in base a diversi parametri, tra cui Tipo, JobID, Stato e ora di creazione del job.
- Fai clic all'interno del Campo Filtra per prefisso, che si trova sopra l'elenco dei job. Seleziona un prefisso da utilizzare per i filtri. Ad esempio, seleziona Tipo.
Per completare il filtro, fai clic sul suffisso del filtro che vuoi utilizzare. Ad esempio, le opzioni di suffisso per il prefisso Tipo sono:
- Addestramento con codice personalizzato
- Addestramento con algoritmi integrati
- Previsione
Il filtro viene applicato all'elenco Jobs e il nome del filtro viene visualizzato nel campo del filtro. Ad esempio, se hai selezionato Addestramento con codice personalizzato, in alto viene visualizzato il filtro Tipo:addestramento con codice personalizzato, che filtra l'elenco dei job. Se necessario, puoi aggiungere più filtri.
Visualizzazione delle prove degli iperparametri
Nella pagina Dettagli job, puoi visualizzare le metriche per ogni prova nella tabella HyperTune trials (Prove HyperTune). Questa tabella viene visualizzata solo per i job che utilizzano
l'ottimizzazione iperparametri. Puoi attivare/disattivare le metriche per visualizzare le prove in base ai valori più elevati o più bassi di rmse, Training steps e learning_rate.
Per visualizzare i log di una prova specifica, fai clic sul
gcloud
Utilizza
gcloud ai-platform jobs describe
per ottenere dettagli sullo stato corrente del job sulla riga di comando:
gcloud ai-platform jobs describe job_name
Puoi ottenere un elenco dei job associati al tuo progetto che include lo stato e la data di creazione con gcloud ai-platform jobs list.
Tieni presente che questo comando nella sua forma più semplice elenca tutti i job mai creati per il tuo progetto. Devi delimitare l'ambito della richiesta per limitare il numero di job registrati. I seguenti esempi dovrebbero aiutarti a iniziare:
Utilizza l'argomento --limit per limitare il numero di job. Questo esempio elenca i 5 job più recenti:
gcloud ai-platform jobs list --limit=5
Utilizza l'argomento --filter per limitare l'elenco dei job a quelli con un determinato valore dell'attributo. Puoi filtrare in base a uno o più attributi dell'oggetto
Job. Oltre agli attributi di base del job, puoi filtrare in base agli oggetti all'interno del job, ad esempio l'oggetto TrainingInput.
Esempi di filtri dell'elenco:
Elenca tutti i job avviati dopo una determinata ora. Questo esempio utilizza le 19:00 della sera del 15 gennaio 2017:
gcloud ai-platform jobs list --filter='createTime>2017-01-15T19:00'Elenca gli ultimi tre job con nomi che iniziano con una determinata stringa. Ad esempio, la stringa potrebbe rappresentare il nome utilizzato per tutti i job di addestramento di un determinato modello. Questo esempio utilizza un modello in cui l 'identificatore del job è "census" con un suffisso che è un indice incrementato per ogni job:
gcloud ai-platform jobs list --filter='jobId:census*' --limit=3Elenca tutti i job non riusciti con nomi che iniziano con "rnn":
gcloud ai-platform jobs list --filter='jobId:rnn* AND state:FAILED'
Per informazioni dettagliate sulle espressioni supportate dall'opzione di filtro, consulta la documentazione del comando gcloud.
Python
Assembla la stringa di identificatore del job combinando il nome del progetto e il nome del job nel seguente formato:
'projects/your_project_name/jobs/your_job_name':projectName = 'your_project_name' projectId = 'projects/{}'.format(projectName) jobName = 'your_job_name' jobId = '{}/jobs/{}'.format(projectId, jobName)Forma la richiesta a projects.jobs.get:
request = ml.projects().jobs().get(name=jobId)Esegui la richiesta (questo esempio inserisce la chiamata
executein un bloccotryper rilevare le eccezioni):response = None try: response = request.execute() except errors.HttpError, err: # Something went wrong. Handle the exception in an appropriate # way for your application.Controlla la risposta per assicurarti che, indipendentemente dagli errori HTTP, la chiamata al servizio abbia restituito dati.
if response == None: # Treat this condition as an error as best suits your # application.Recupera i dati sullo stato. L'oggetto risposta è un dizionario contenente tutti i membri applicabili della risorsa Job, inclusa la risorsa completa TrainingInput e i membri applicabili della risorsa TrainingOutput. L'esempio seguente stampa lo stato del job e il numero di unità ML consumate dal job.
print('Job status for {}.{}:'.format(projectName, jobName)) print(' state : {}'.format(response['state'])) print(' consumedMLUnits : {}'.format( response['trainingOutput']['consumedMLUnits']))
I job possono non riuscire se si verifica un problema con l'applicazione di addestramento o con l'infrastruttura di AI Platform Training. Puoi utilizzare Cloud Logging per iniziare il debug.
Puoi anche utilizzare una shell interattiva per ispezionare i container di addestramento durante l'esecuzione del job di addestramento.
Monitoraggio del consumo di risorse
Nella pagina Dettagli job puoi trovare i seguenti grafici di utilizzo delle risorse per i job di addestramento:
- L'utilizzo aggregato della CPU o della GPU del job e l'utilizzo della memoria. Questi parametri sono suddivisi in base a server master, worker e parametri.
- L'utilizzo della rete del job, misurato in byte al secondo. Esistono grafici distinti per i byte inviati e per i byte ricevuti.
Vai alla pagina Job di addestramento della piattaforma AI nella console Google Cloud.
Trova il tuo lavoro nell'elenco.
Fai clic sul nome del job nell'elenco per aprire la pagina Dettagli job.
Seleziona le schede etichettate CPU, GPU o Rete per visualizzare i grafici di utilizzo delle risorse associati.
Puoi anche accedere alle informazioni sulle risorse online utilizzate dai tuoi job di addestramento con Cloud Monitoring. AI Platform Training esporta le metriche in Cloud Monitoring.
Ogni tipo di metrica di AI Platform Training include "training" nel nome. Ad esempio, ml.googleapis.com/training/cpu/utilization o
ml.googleapis.com/training/accelerator/memory/utilization.
Monitoraggio con TensorBoard
Puoi configurare l'applicazione di addestramento in modo che salvi i dati di riepilogo che potrai esaminare e visualizzare utilizzando TensorBoard.
Salva i dati di riepilogo in una posizione Cloud Storage e indirizza TensorBoard a quella posizione per esaminare i dati. Puoi anche indirizzare TensorBoard a una directory con sottodirectory contenenti l'output di più job.
Scopri di più su TensorBoard e AI Platform Training nella guida introduttiva.
Passaggi successivi
- Risolvi i problemi relativi al job di addestramento.
- Esegui il deployment del modello addestrato per testing online e pubblicazione di previsioni.