I mainframe IBM vengono utilizzati dalle organizzazioni per eseguire attività di computing critiche. Negli ultimi anni, molte aziende che si affidano ai mainframe hanno lavorato per eseguire la migrazione al cloud. Mainframe Connector ti consente di spostare i dati del mainframe su Google Cloud in modo da poter scaricare i carichi di lavoro dei report che richiedono un uso intensivo della CPU su Google Cloud.
Principali vantaggi di Mainframe Connector
Di seguito sono riportati i principali vantaggi dell'utilizzo di Mainframe Connector per spostare i dati del mainframe in Google Cloud:
- Trasferimento dei dati semplificato:semplifica lo spostamento dei dati del mainframe in Google Cloud servizi di archiviazione come Cloud Storage e BigQuery.
- Integrazione dei job batch:consente di inviare job BigQuery utilizzando job batch mainframe definiti nel linguaggio di controllo dei job (JCL). Man mano che le query vengono lette dai set di dati o dai file, gli analisti possono utilizzare i job pianificati con una conoscenza e una comprensione minime degli ambienti mainframe.
- Monitoraggio semplice:il personale operativo del mainframe non deve monitorare un ambiente diverso, poiché i job vengono inviati con pianificazioni familiari utilizzando JCL.
- MIPS ridotti:Mainframe Connector utilizza una Java Virtual Machine (JVM) per la maggior parte dell'elaborazione per ridurre al minimo il carico di lavoro del processore mainframe durante il trasferimento dei dati, riducendo i milioni di istruzioni al secondo (MIPS) e quindi i costi. Mainframe Connector delega la maggior parte del lavoro che richiede un uso intensivo del processore a processori ausiliari. Se i processori ausiliari sono sovraccarichi, puoi anche configurare Mainframe Connector per eseguire la transcodifica e la conversione utilizzando Compute Engine. Per ulteriori informazioni sulle configurazioni di Mainframe Connector, consulta Configurazioni di Mainframe Connector.
Trasformazione in streaming:transcodifica i file nei formati ORC, JSON o CSV, compatibili con servizi Google Cloud come BigQuery. Mainframe Connector supporta la transcodifica per i seguenti tipi di file:
- Set di dati mainframe Queued Sequential Access Method (QSAM) o Virtual Storage Access Method (VSAM) associati a copybook COBOL in Extended Binary Coded Decimal Interchange Code (EBCDIC)
- File in formato ASCII UTF-8
Per impostazione predefinita, Mainframe Connector transcodifica i set di dati dal set di caratteri US EBCDIC: Cp037 ai formati ORC, JSON e CSV. Tuttavia, Mainframe Connector supporta anche la transcodifica dei set di dati dai seguenti set di caratteri EBCDIC regionali:
- Francese: Cp297
- Tedesco: Cp1141
- Spagnolo: Cp1145
È possibile implementare un set di caratteri personalizzato se non ne è incluso uno appropriato nella JVM IBM.
Come funziona Mainframe Connector
Mainframe Connector consente di spostare i dati che si trovano sul mainframe in Cloud Storage e viceversa, nonché di inviare job BigQuery da job batch basati su mainframe definiti in JCL. Mainframe Connector ti consente di transcodificare i set di dati mainframe direttamente nel formato Optimized Row Columnar (ORC).
La transcodifica è il processo di conversione delle informazioni da una forma di rappresentazione codificata a un'altra, in questo caso in ORC. ORC è un formato di dati open source orientato alle colonne ampiamente utilizzato nell'ecosistema Apache Hadoop e supportato da BigQuery.
Mainframe Connector fornisce un sottoinsieme delle utilità della riga di comando di Google Cloud SDK che ti consentono di trasferire dati e interagire con i servizi Google Cloud . L'interprete della shell e le implementazioni basate su JVM delle utilità a riga di comando gsutil e bq ti consentono di gestire una pipeline completa di estrazione, caricamento e trasformazione (ELT) interamente da IBM z/OS mantenendo lo scheduler dei job esistente.
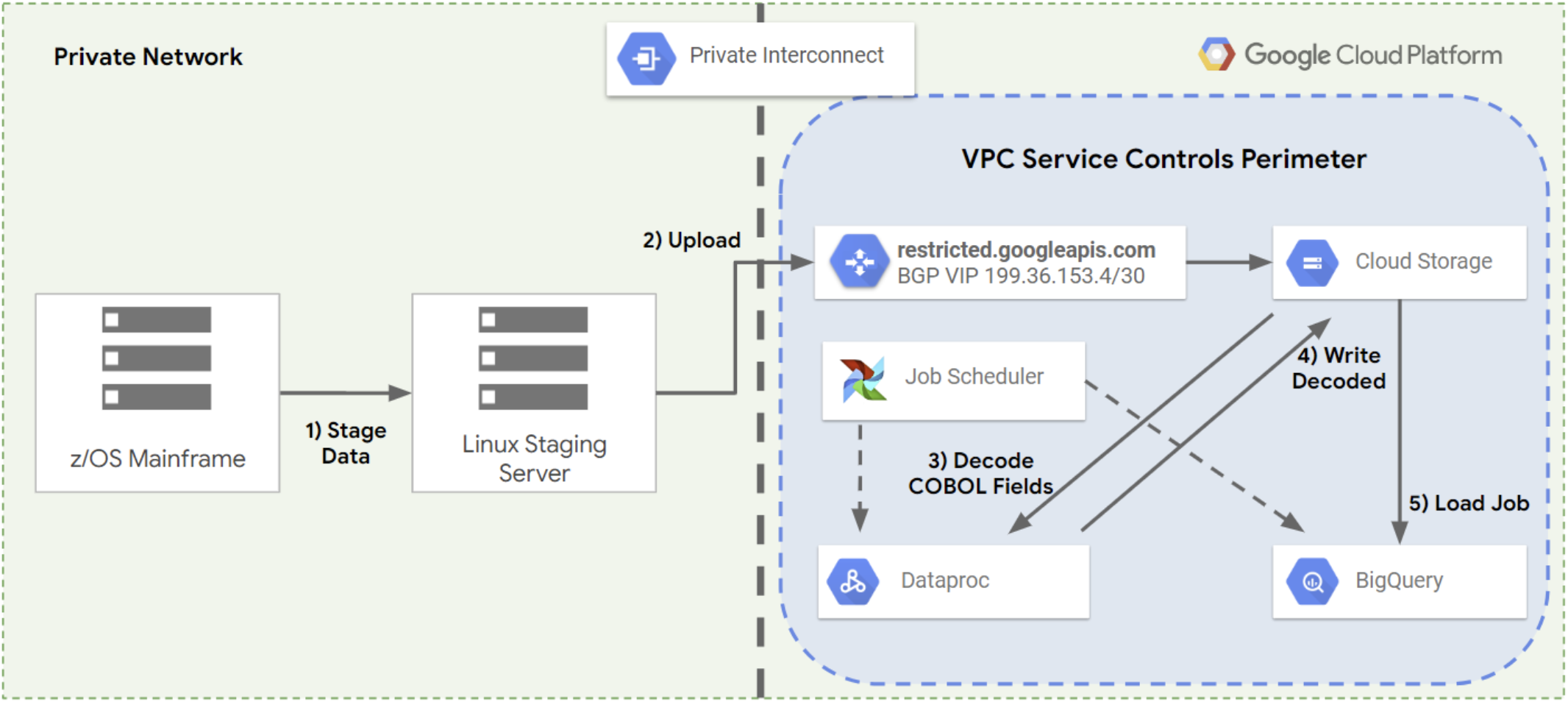
Una delle sfide principali del trasferimento dei dati mainframe da e verso il cloud è che si tratta di un processo in più fasi che normalmente include l'esecuzione dei seguenti passaggi:
- Copia i dati su un file server.
- Copia i dati dal file server in un'altra posizione per l'elaborazione.
- Utilizza uno stack di elaborazione dei dati per convertire i dati in un formato moderno.
- Scrivi nuovamente i dati elaborati in un'altra posizione.
- Carica i dati elaborati in un database o in un data warehouse in cui possono essere interrogati o utilizzati.
La figura seguente mostra il processo in più passaggi normalmente utilizzato per trasferire i dati da un mainframe a Google Cloud.
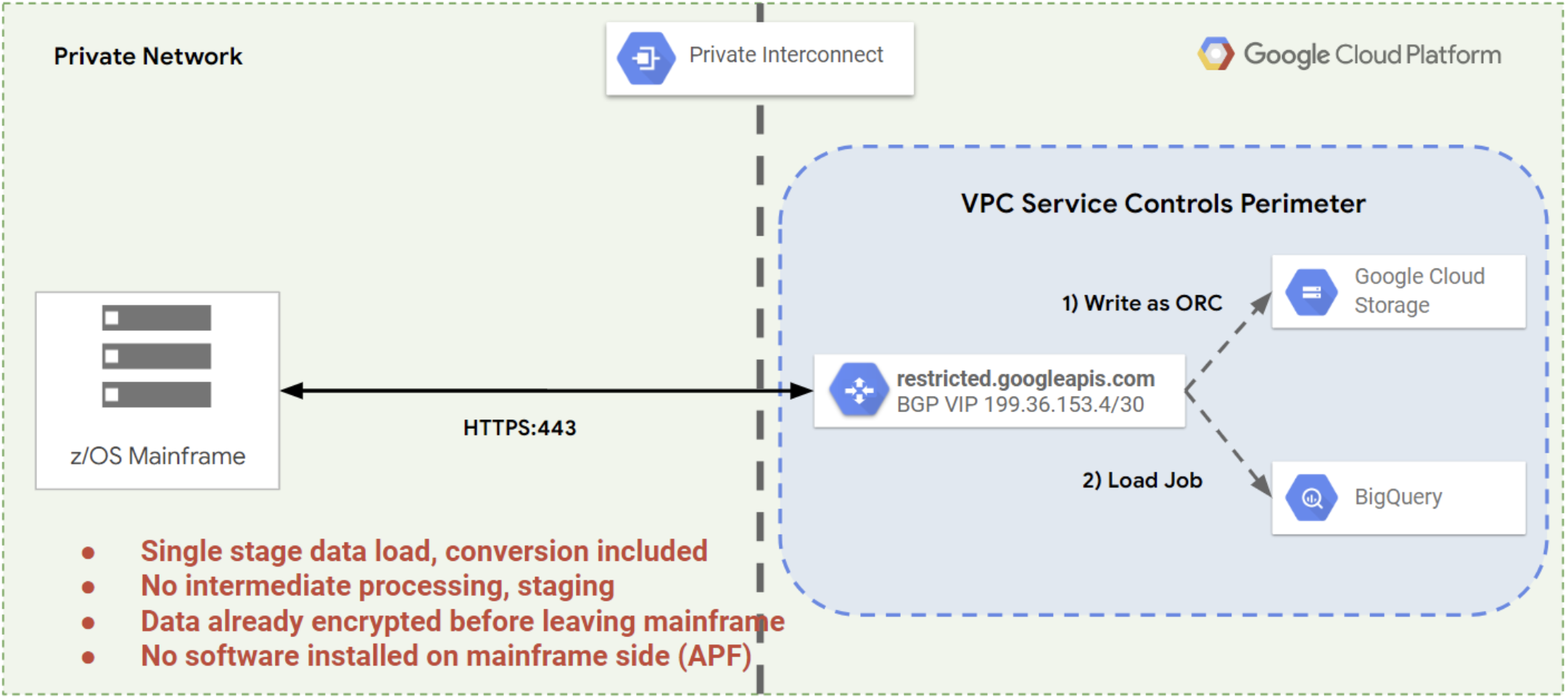
Mainframe Connector ti consente di eseguire tutti questi passaggi con un unico comando utilizzando Cloud Storage come posizione di archiviazione intermedia. In questo modo si riduce il tempo necessario per l'elaborazione e la disponibilità dei dati del mainframe in un database o in un data warehouse, come mostrato nella figura seguente.
Passaggi successivi
- Architettura di Mainframe Connector
- Configurazioni di Mainframe Connector
- Installa Mainframe Connector