This page provides troubleshooting information for common scenarios when using log-based metrics in Cloud Logging.
Cannot view or create metrics
Log-based metrics apply only to a single Google Cloud project or to a Logging bucket within a Google Cloud project. You can't create log-based metrics for other Google Cloud resources such as billing accounts or organizations. Log-based metrics are computed for logs only in the Google Cloud project or bucket in which they're received.
To create metrics, you need the correct Identity and Access Management permissions. For details, see Access control with IAM: Log-based metrics.
Metric is missing logs data
There are several possible reasons for missing data in log-based metrics:
New log entries might not match your metric's filter. A log-based metric gets data from matching log entries that are received after the metric is created. Logging doesn't backfill the metric from previous log entries.
New log entries might not contain the correct field, or the data might not be in the correct format for extraction by your distribution metric. Check that your field names and regular expressions are correct.
Your metric counts might be delayed. Even though countable log entries appear in the Logs Explorer, it may take up to 10 minutes to update the log-based metrics in Cloud Monitoring.
The log entries that are displayed might be counted late or might not be counted at all, because they are time-stamped too far in the past or future. If a log entry is received by Cloud Logging more than 24 hours in the past or 10 minutes in the future, then the log entry won't be counted in the log-based metric.
The number of late-arriving entries is recorded in the log-based metric
logging.googleapis.com/logs_based_metrics_error_count.Example: A log entry matching a log-based metric arrives late. It has a
timestampof 2:30 PM on February 20, 2020 and areceivedTimestampof 2:45 PM on February 21, 2020. This entry won't be counted in the log-based metric.The log-based metric was created after the arrival of log entries that the metric might count. Log-based metrics evaluate log entries as they're stored in log buckets; these metrics don't evaluate log entries stored in Logging.
The logs-based metric has gaps in the data. Some data gaps are expected, because the systems that process the log-based metric data don't guarantee the persistence of every metric data point. When gaps occur, they are typically rare and of short duration. However, if you have an alerting policy that monitors a log-based metric, then gaps in the data might cause a false notification. The settings you use in your alerting policy can reduce this possibility.
Example: A "heartbeat" log entry is written every five minutes, and a log-based metric counts the number of "heartbeat" log entries. An alerting policy sums up the counts in a five-minute interval and notifies you when the total is less than one. When the time series is missing a data point, the alerting policy injects a synthetic value, which is a duplicate of the most recent sample and is most likely to be zero, and then evaluates the condition. Therefore, even a single missing data point could result in the summed value being zero, which causes this alerting policy to send a notification.
To reduce the risk of a false notification, configure the policy to count multiple "heartbeat" log entries, not just one.
Resource type is "undefined" in Cloud Monitoring
Some Cloud Logging monitored-resource types don't map directly to Cloud Monitoring monitored-resource types. For example, when you first create either an alerting policy or chart from a log-based metric, you might see that the resource type is "undefined".
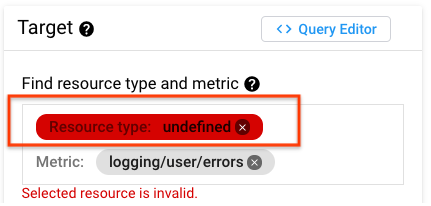
The monitored-resource type maps either to global or a different
monitored-resource type in Cloud Monitoring. See the
Mappings for Logging-only resources
to determine which monitored-resource type you need to choose.
Labels in a notification aren't resolved
You create a log-based metric, and then you create an alerting policy to
monitor that log-based metric.
In the documentation field of your alerting policy, you refer to the
extracted labels by using a variable of the form
${log.extracted_label.KEY}, where KEY is the name you gave
the extracted label. The label isn't resolved in the notification.
To resolve this problem, do one of the following:
Remove the extracted label content from the documentation. Alerting policies that monitor log-based metrics can't extract data from log entries.
Create a log-based alert. These alerting policies can extract data from the log entry that causes the alerting policy to trigger.
Incidents aren't created or are false-positive
You could get false-positive incidents or situations where Monitoring doesn't create incidents from log-based metrics because the alignment period for the alerting policy is too short. You might encounter false positives in the following scenarios:
- When an alerting policy uses less than logic.
- When an alerting policy is based on a percentile condition for a distribution metric.
- When there is a gap in the metric data.
False-positive incidents can occur because log entries can be sent to
Logging late. For example, the log fields timestamp and
receiveTimestamp can have a delta of minutes in some cases. Also, when
Logging stored logs in log buckets, there is an inherent delay
between when the log entries are generated and when Logging
receives them. This means that Logging might not have the total
count for a particular log entry until some later point in time after the log
entries were generated. This is why an alerting policy using less than logic
or based on a percentile condition for a distribution metric can produce a
false-positive alert: not all the log entries have been accounted for yet.
However, log-based metrics are eventually consistent because a log entry that
matches a log-based metric can be sent to Logging with a
timestamp that is significantly older or newer than the log's
receiveTimestamp.
This means that the log-based metric can receive log entries with older timestamps after existing log entries with the same timestamp have already been received by Logging. Thus, the metric value must be updated.
For notifications to remain accurate even for on-time data, we recommend that
you set the alignment period for the condition to be at least
10 minutes. In particular, this value should be large enough
to make sure that multiple log entries that match your filter are counted. For
example, if a log-based metric counts "heartbeat" log entries, which are
expected every N minutes, then set the alignment period to 2N minutes or
10 minutes, whichever is larger:
If you use the Google Cloud console, then use the Rolling window menu to set the alignment period.
If you use the API, then use the
aggregations.alignmentPeriodfield of the condition to set the alignment period.
Metric has too many time series
The number of time series in a metric depends on the number of different combinations of label values. The number of time series is called the cardinality of the metric, and it must not exceed 30,000.
Because you can generate a time series for every combination of label values, if you have one or more labels with high number of values, it isn't difficult to exceed 30,000 time series. You want to avoid high-cardinality metrics.
As the cardinality of a metric increases, the metric can get throttled and some data points might not be written to the metric. Charts that display the metric can be slow to load due to the large number of time series that the chart has to process. You might also incur costs for API calls to query time series data; review the Cloud Monitoring sections of the Google Cloud Observability pricing page.
To avoid creating high cardinality metrics:
Check that your label fields and extractor regular expressions match values that have a limited cardinality.
For example, don't store sizes, counts, or durations in labels. Also, don't store fields like URLs, IP addresses, or unique IDs, as these can all result in a large number of time series.
Avoid extracting text messages that can change, without bounds, as label values.
Avoid extracting numerical values with unbounded cardinality.
Only extract values from labels of known cardinality; for example, status codes with a set of known values.
These system log-based metrics can help you measure the effect that adding or removing labels has on the cardinality of your metric:
logging.googleapis.com/metric_throttledlogging.googleapis.com/time_series_countlogging.googleapis.com/metric_label_throttledlogging.googleapis.com/metric_label_cardinality
When you inspect these metrics, you can further filter your results by metric name. For details, see Selecting metrics: filtering.
Metric name is invalid
When you create a counter or distribution metric, choose a metric name that is unique among the log-based metrics in your Google Cloud project.
Metric-name strings must not exceed 100 characters and can include only the following characters:
A-Za-z0-9The special characters
_-.,+!*',()%\/.The forward slash character
/denotes a hierarchy of pieces within the metric name and cannot be the first character of the name.
Metric values aren't correct
You notice that the values reported for a log-based metric are sometimes different from the number of log entries reported by the Logs Explorer.
To minimize the discrepancy, do the following:
Make sure applications aren't sending duplicate log entries. Log entries are considered duplicates when they have the same
timestampandinsertId. The Logs Explorer automatically suppresses duplicate log entries. However, log-based metrics count each log entry that matches the filter for the metric.Make sure that a log entry is sent to Cloud Logging when the timestamp is less than 24 hours in the past or less than 10 minutes in the future. Log entries whose timestamps aren't within these bounds aren't counted by log-based metrics.
You can't eliminate the possibility of duplicate logs. If an internal error occurs during the handling of a log entry, a retry process is invoked by Cloud Logging. The retry process might cause a duplicate log entry. When duplicates log entries exist, the value of a log-based metric might be too large because these metrics count each log entry that matches the filter for the metric.
Label values are truncated
Values for user-defined labels must not exceed 1,024 bytes.
Cannot delete a custom log metric
You attempt to delete a custom log-based metric by using the Google Cloud console.
The delete request fails and the deletion dialog displays
the error message There is an unknown error while executing this operation.
To resolve this problem, try the following:
Refresh the Log-based metrics page in the Google Cloud console. The error message might be shown due to an internal timing issue.
Identify and delete any alerting policies that monitor the log-based metric. After you verify that the log-based metric isn't monitored by an alerting policy, delete the log-based metric. Log-based metrics that are monitored by an alerting policy can't be deleted.