Questa pagina fornisce dettagli sulle configurazioni predefinite e personalizzate dell'agente Cloud Logging.
La maggior parte degli utenti non deve leggere questa pagina. Leggi questa pagina se:
Ti interessano dettagli tecnici approfonditi sulla configurazione dell'agente Cloud Logging.
Vuoi modificare la configurazione dell'agente Cloud Logging.
Configurazione predefinita
L'agente Logging google-fluentd è una versione modificata del raccoltore di dati di log fluentd.
L'agente di logging viene fornito con una configurazione predefinita. Nella maggior parte dei casi, non è necessaria alcuna configurazione aggiuntiva.
Nella configurazione predefinita, l'agente Logging esegue lo streaming dei log, come incluso nell'elenco dei log predefiniti, in Cloud Logging. Puoi configurare l'agente per trasmettere in streaming log aggiuntivi. Per maggiori dettagli, vai a Personalizzare la agente Logging logging in questa pagina.
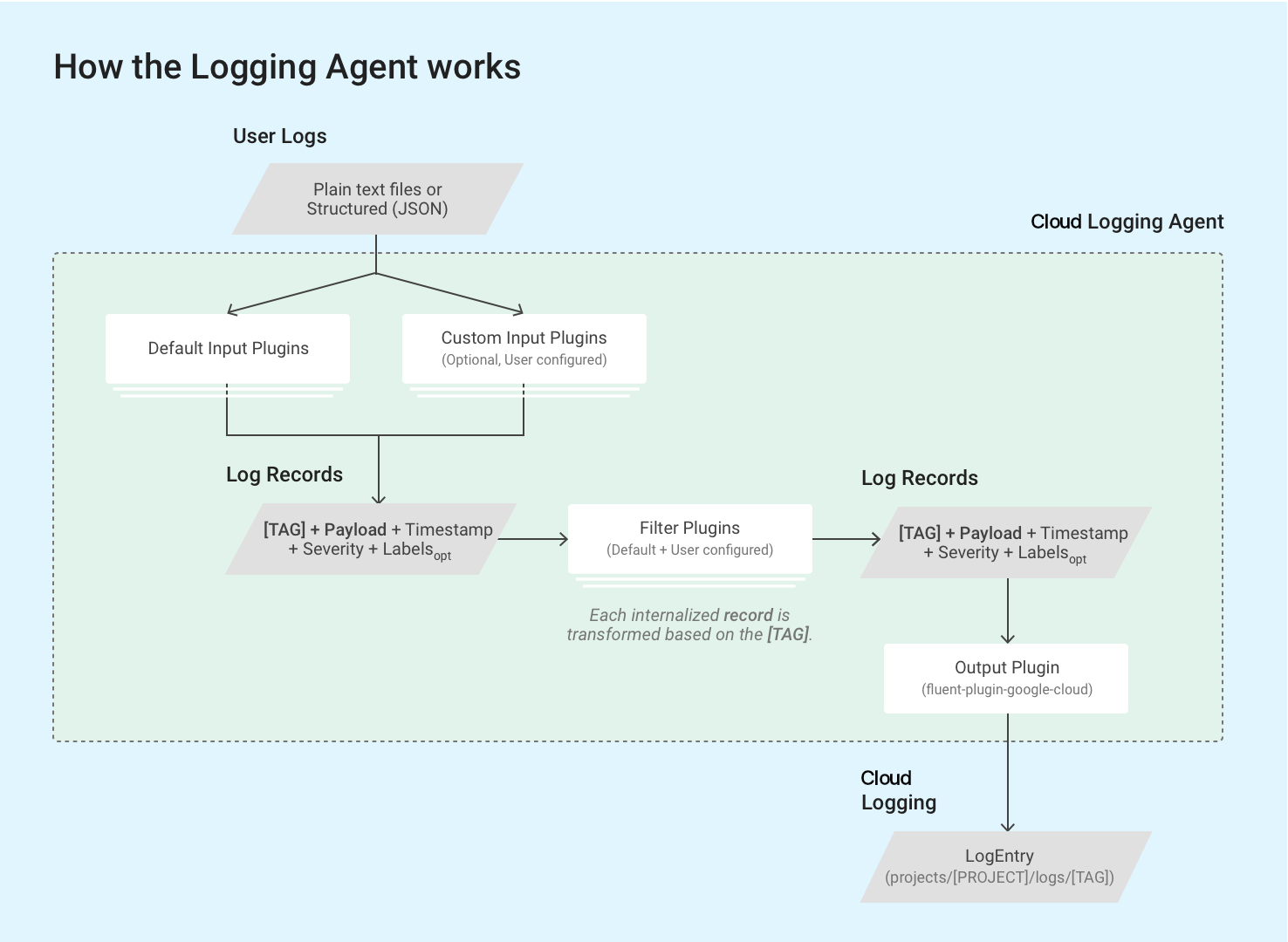
L'agente di logging utilizza i plug-in di input fluentd per recuperare e estrarre i log eventi da origini esterne, ad esempio file su disco, o per analizzare i record dei log in arrivo. I plug-in di input sono inclusi nell'agente o possono essere installati separatamente come gem di Ruby. Consulta l'elenco dei plug-in in bundle.
L'agente legge i record dei log memorizzati nei file di log sull'istanza VM tramite il plug-in in_tail integrato di fluentd. Ogni record del log viene convertito in una struttura di voce del log per Cloud Logging. I contenuti di ogni record del log vengono registrati principalmente nel payload delle voci di log, ma queste ultime contengono anche elementi standard come un timestamp e la gravità. L'agente di logging richiede che ogni record di log sia contrassegnato con un tag in formato stringa. Tutte le query e i plug-in di output corrispondono a un insieme specifico di tag. Il nome del log solitamente segue il formato projects/[PROJECT-ID]/logs/[TAG]. Ad esempio, questo nome del log include il
tag structured-log:
projects/my-sample-project-12345/logs/structured-log
Il plug-in di output trasforma ogni messaggio strutturato internalizzato in una voce di log in Cloud Logging. Il payload diventa il payload di testo o JSON.
Le sezioni seguenti di questa pagina illustrano in dettaglio la configurazione predefinita.
Definizioni di configurazione predefinite
Le sezioni seguenti descrivono le definizioni di configurazione predefinite per syslog, il plug-in di input inoltrato, le configurazioni di input per i log delle applicazioni di terze parti, come quelli nell'elenco dei log predefiniti, e il nostro plug-in di output fluentd di Google Cloud.
Posizione del file di configurazione principale
Linux:
/etc/google-fluentd/google-fluentd.confQuesto file di configurazione principale importa anche tutti i file di configurazione dalla
/etc/google-fluentd/config.dcartella.Windows:
C:\Program Files (x86)\Stackdriver\LoggingAgent\fluent.confSe utilizzi un agente di logging precedente alla versione 1-5, la posizione è:
C:\GoogleStackdriverLoggingAgent\fluent.conf
Configurazione Syslog
Località dei file di configurazione:
/etc/google-fluentd/config.d/syslog.confDescrizione: questo file include la configurazione per specificare syslog come input di log.
Esamina il repository di configurazione.
| Nome della configurazione | Tipo | Predefinito | Descrizione |
|---|---|---|---|
format |
string | /^(?<message>(?<time>[^ ]*\s*[^ ]* [^ ]*) .*)$/ |
Il formato del file syslog. |
path |
string | /var/log/syslog |
Il percorso del file syslog. |
pos_file |
string | /var/lib/google-fluentd/pos/syslog.pos |
Il percorso del file di posizione per questo input di log. fluentd registra la posizione dell'ultima lettura in questo file. Consulta la documentazione dettagliata di fluentd. |
read_from_head |
bool | true |
Indica se iniziare a leggere i log dall'inizio del file anziché dalla fine. Consulta la documentazione dettagliata di fluentd. |
tag |
string | syslog |
Il tag log per questo input log. |
in_forward Configurazione del plug-in di immissione
Località dei file di configurazione:
/etc/google-fluentd/config.d/forward.confDescrizione: questo file include la configurazione per il plug-in di input
in_forwardfluentd. Il plug-in di inputin_forwardti consente di trasmettere i log tramite una socket TCP.Consulta la documentazione dettagliata di
fluentdper questo plug-in e il repository di configurazione.
| Nome della configurazione | Tipo | Predefinito | Descrizione |
|---|---|---|---|
port |
int | 24224 |
La porta da monitorare. |
bind |
string | 127.0.0.1 |
L'indirizzo di associazione da monitorare. Per impostazione predefinita, vengono accettate solo le connessioni da localhost. Per aprire questa opzione, la configurazione deve essere modificata in 0.0.0.0. |
Configurazione dell'input dei log delle applicazioni di terze parti
Località dei file di configurazione:
/etc/google-fluentd/config.d/[APPLICATION_NAME].confDescrizione: questa directory include file di configurazione per specificare i file di log delle applicazioni di terze parti come input di log. Ogni file, ad eccezione di
syslog.confeforward.conf, rappresenta un'applicazione (ad es.apache.confper l'applicazione Apache).Esamina il repository di configurazione.
| Nome della configurazione | Tipo | Predefinito | Descrizione |
|---|---|---|---|
format1 |
string | Varia in base all'applicazione | Il formato del log. Consulta la documentazione dettagliata di fluentd. |
path |
string | Varia in base all'applicazione | Il percorso dei file di log. È possibile specificare più percorsi, separati da ",". È possibile includere * e il formato strftime per aggiungere/rimuovere dinamicamente il file di monitoraggio. Consulta la documentazione dettagliata di fluentd. |
pos_file |
string | Varia in base all'applicazione | Il percorso del file di posizione per questo input di log. fluentd registra la posizione dell'ultima lettura in questo file. Consulta la documentazione dettagliata di fluentd. |
read_from_head |
bool | true |
Indica se iniziare a leggere i log dall'inizio del file anziché dalla fine. Consulta la documentazione dettagliata di fluentd. |
tag |
string | Varia; il nome dell'applicazione. | Il tag log per questo input log. |
1 Se utilizzi la stanza <parse>, specifica il formato del log utilizzando @type.
Configurazione del plug-in di outputGoogle Cloud fluentd
Posizione dei file di configurazione:
- Linux:
/etc/google-fluentd/google-fluentd.conf Windows:
C:\Program Files (x86)\Stackdriver\LoggingAgent\fluent.confSe utilizzi un agente di logging precedente alla versione 1-5, la posizione è:
C:\GoogleStackdriverLoggingAgent\fluent.conf
- Linux:
Descrizione: questo file include opzioni di configurazione per controllare il comportamento del plug-in di outputGoogle Cloud
fluentd.Vai al repository di configurazione.
| Nome della configurazione | Tipo | Predefinito | Descrizione |
|---|---|---|---|
buffer_chunk_limit |
string | 512KB |
Quando arrivano i record dei log, quelli che non possono essere scritti nei componenti a valle abbastanza velocemente vengono inseriti in una coda di chunk. Questa configurazione imposta il limite di dimensioni di ogni chunk. Per impostazione predefinita, impostiamo il limite di chunk in modo conservativo per evitare di superare la dimensione consigliata di 5 MB per richiesta di scrittura nell'API Logging. Le voci di log nella richiesta API possono essere 5-8 volte più grandi delle dimensioni del log originale con tutti i metadati aggiuntivi allegati. Un chunk del buffer viene svuotato se è soddisfatta una delle due condizioni: 1. flush_interval viene attivato. 2. La dimensione del buffer raggiunge buffer_chunk_limit. |
flush_interval |
string | 5s |
Quando arrivano i record dei log, quelli che non possono essere scritti nei componenti a valle abbastanza velocemente vengono inseriti in una coda di chunk. La configurazione imposta il tempo che deve trascorrere prima di svuotare un buffer di chunk. Un chunk del buffer viene svuotato se è soddisfatta una delle due condizioni: 1. flush_interval viene attivato. 2. La dimensione del buffer raggiunge buffer_chunk_limit. |
disable_retry_limit |
bool | false |
Applica un limite al numero di nuovi tentativi di svuotamento non riuscito dei chunk del buffer. Consulta le specifiche dettagliate in retry_limit, retry_wait e max_retry_wait. |
retry_limit |
int | 3 |
Quando non è possibile svuotare un chunk del buffer, per impostazione predefinita fluentd riprova in un secondo momento. Questa configurazione imposta il numero di tentativi da eseguire prima di eliminare un chunk del buffer problematico. |
retry_wait |
int | 10s |
Quando non è possibile svuotare un chunk del buffer, per impostazione predefinita fluentd riprova in un secondo momento. Questa configurazione imposta l'intervallo di attesa in secondi prima del primo tentativo. L'intervallo di attesa raddoppia a ogni tentativo successivo (20 secondi, 40 secondi e così via) fino a quando non viene raggiunto retry_ limit o max_retry_wait. |
max_retry_wait |
int | 300 |
Quando non è possibile svuotare un chunk del buffer, per impostazione predefinita fluentd riprova in un secondo momento. L'intervallo di attesa raddoppia a ogni nuovo tentativo (20 secondi, 40 secondi e così via). Questa configurazione imposta il numero massimo di intervalli di attesa in secondi. Se l'intervallo di attesa raggiunge questo limite, il raddoppio si interrompe. |
num_threads |
int | 8 |
Il numero di svuotamenti simultanei dei log che possono essere elaborati dal plug-in di output. |
use_grpc |
bool | true |
Indica se utilizzare gRPC anziché REST/JSON per comunicare con l'API Logging. Con gRPC abilitato, l'utilizzo della CPU è in genere inferiore |
grpc_compression_algorithm |
enum | none |
Se utilizzi gRPC, imposta lo schema di compressione da utilizzare. Può essere none o gzip. |
partial_success |
bool | true |
Indica se supportare l'esito positivo parziale per l'importazione dei log. Se true, le voci di log non valide in un set completo vengono eliminate e le voci di log valide vengono importate correttamente nell'API Logging. Se false, l'intero set verrà eliminato se contiene voci di log non valide. |
enable_monitoring |
bool | true |
Se impostato su true, l'agente Logging esporta la telemetria interna. Per maggiori dettagli, consulta la sezione Telemetria del plug-in di output. |
monitoring_type |
string | opencensus |
Il tipo di monitoraggio. Le opzioni supportate sono opencensus e prometheus. Per maggiori dettagli, consulta la sezione Telemetria del plug-in di output. |
autoformat_stackdriver_trace |
bool | true |
Se impostato su true, la traccia viene riformattata se il valore del campo del payload strutturato logging.googleapis.com/trace corrisponde al formato traceId di ResourceTrace. I dettagli della formattazione automatica sono disponibili nella sezione Campi speciali nei payload strutturati di questa pagina. |
Configurazione del monitoraggio
Telemetria del plug-in di output
L'opzione enable_monitoring controlla se il plug-in di output Google Cloud fluentd raccoglie la telemetria interna. Se impostato su true, l'agente di logging tiene traccia del numero di voci di log richieste di essere inviate a Cloud Logging e del numero effettivo di voci di log importate correttamente da Cloud Logging. Se impostato su false, il plug-in di output non raccoglie alcuna metrica.
L'opzione monitoring_type controlla il modo in cui questa telemetria viene esposta dall'agente. Di seguito è riportato l'elenco delle metriche.
Se impostato su prometheus, l'agente di logging espone le metriche in formato Prometheus sull'endpoint Prometheus (localhost:24231/metrics per impostazione predefinita; consulta la configurazione dei plug-in prometheus e prometheus_monitor per informazioni dettagliate sulla personalizzazione). Sulle VM Compute Engine, affinché queste metriche vengano scritte nell'API Monitoring, è necessario che anche l'agente di monitoraggio sia installato ed eseguito.
Se impostato su opencensus (valore predefinito dalla
v1.6.25),
l'agente Logging scrive direttamente le proprie metriche di stato nell'
API Monitoring. Ciò richiede che il ruolo roles/monitoring.metricWriter
viene concesso al
service account Compute Engine predefinito, anche se l'agente di monitoraggio non è installato.
Le seguenti metriche vengono scritte nell'API Monitoring sia dall'agente Monitoring sia dall'agente Logging in modalità opencensus:
agent.googleapis.com/agent/uptimecon un'etichettaversion: tempo di attività dell'agente Logging.agent.googleapis.com/agent/log_entry_countcon un'etichettaresponse_code: numero di voci di log scritte dall'agente Logging.agent.googleapis.com/agent/log_entry_retry_countcon un'etichettaresponse_code: Numero di voci di log scritte dall'agente Logging.agent.googleapis.com/agent/request_countcon un'etichettaresponse_code: numero di richieste API dall'agente Logging.
Queste metriche sono descritte in modo più dettagliato nella pagina Metriche agente.
Inoltre, il plug-in di output in modalità prometheus espone le seguenti metriche Prometheus:
uptimecon un'etichettaversion: tempo di attività dell'agente Logging.stackdriver_successful_requests_countcon le etichettegrpcecode: Il numero di richieste riuscite all'API Logging.stackdriver_failed_requests_countcon le etichettegrpcecode: Il numero di richieste non riuscite all'API Logging, suddivise per codice di errore.stackdriver_ingested_entries_countcon le etichettegrpcecode: Il numero di voci di log importate dall'API Logging.stackdriver_dropped_entries_countcon le etichettegrpcecode: Il numero di voci di log rifiutate dall'API Logging.stackdriver_retried_entries_countcon etichettegrpcecode: Il numero di voci di log che non sono state importate dal plug-in di output Google Cloudfluentda causa di un errore temporaneo e per le quali è stato eseguito un nuovo tentativo.
Configurazione dei plug-in prometheus e prometheus_monitor
Località dei file di configurazione:
/etc/google-fluentd/google-fluentd.confDescrizione: Questo file include opzioni di configurazione per controllare il comportamento dei plug-in
prometheuseprometheus_monitor. Il plug-inprometheus_monitormonitora l'infrastruttura di base di Fluentd. Il plug-inprometheusespone le metriche, incluse quelle del plug-inprometheus_monitore quelle del plug-ingoogle_cloudsopra, tramite una porta locale in formato Prometheus. Per ulteriori dettagli, visita la pagina https://docs.fluentd.org/deployment/monitoring-prometheus.Vai al repository di configurazione.
Per il monitoraggio di Fluentd, il server delle metriche HTTP Prometheus integrato è abilitato per impostazione predefinita. Per impedire l'avvio di questo endpoint, puoi rimuovere la sezione seguente dalla configurazione:
# Prometheus monitoring.
<source>
@type prometheus
port 24231
</source>
<source>
@type prometheus_monitor
</source>
Elaborazione dei payload
La maggior parte dei log supportati nella configurazione predefinita dell'agente Logging proviene da file di log e viene importata come payload non strutturati (di testo) nelle voci di log.
L'unica eccezione è che il plug-in di input in_forward, attivato anche per impostazione predefinita, accetta solo log strutturati e li importa come payload strutturati (JSON) nelle voci di log. Per maggiori dettagli, leggi
Streaming dei record di log strutturati (JSON) tramite il plug-in in_forward
in questa pagina.
Quando la riga di log è un oggetto JSON serializzato e l'opzione detect_json è attivata, il plug-in di output trasforma la voce di log in un payload strutturato (JSON). Questa opzione è attivata per impostazione predefinita nelle istanze VM in esecuzione nell'ambiente flessibile di App Engine e in Google Kubernetes Engine. Questa opzione non è attiva per impostazione predefinita nelle istanze VM eseguite nell'ambiente standard di App Engine. Qualsiasi JSON analizzato con l'opzione detect_json attivata viene sempre importato come jsonPayload.
Puoi personalizzare la configurazione degli agenti per supportare l'importazione di log strutturati da risorse aggiuntive. Per maggiori dettagli, consulta Eseguire lo streaming dei record dei log strutturati (JSON) in Cloud Logging.
Il payload dei record di log in streaming da un agente di logging configurato in modo personalizzato può essere un singolo messaggio di testo non strutturato (textPayload) o un messaggio JSON strutturato (jsonPayload).
Campi speciali nei payload strutturati
Quando l'agente di logging riceve un record di log strutturato, sposta qualsiasi chiave che corrisponde alla tabella seguente nel campo corrispondente dell'oggetto LogEntry. In caso contrario, la chiave diventa parte del
campo LogEntry.jsonPayload. Questo comportamento ti consente di impostare campi specifici nell'oggetto LogEntry, che viene scritto nell'API Logging.
Ad esempio, se il record del log strutturato contiene una chiave severity,
l'agente Logging compila il campo LogEntry.severity.
| Campo log JSON |
LogEntry
campo
|
Funzione agente Cloud Logging | Valore di esempio |
|---|---|---|---|
severity
|
severity
|
L'agente di logging tenta di associare una serie di stringhe di gravità comuni, tra cui l'elenco di stringhe LogSeverity riconosciute dall'API Logging. | "severity":"ERROR"
|
message
|
textPayload
(o parte di
jsonPayload)
|
Il messaggio visualizzato nella riga di inserimento del log in Esplora log. | "message":"There was an error in the application." Nota: message viene salvato come textPayload se è l'unico campo rimanente dopo che l'agente di registrazione ha spostato gli altri campi per scopi speciali e
detect_json non è stato attivato; in caso contrario, message rimane in jsonPayload. detect_json non è applicabile agli ambienti di logging gestiti come Google Kubernetes Engine. Se la voce di log contiene una analisi dello stack di eccezioni, questa deve essere impostata in questo campo del log JSON message, in modo che possa essere analizzata e salvata in Error Reporting. |
log
(solo
Google Kubernetes Engine
legacy) |
textPayload
|
Si applica solo a Google Kubernetes Engine precedente:
se, dopo aver spostato i campi per scopi speciali, rimane solo un campo log, questo viene salvato come textPayload. |
|
httpRequest
|
httpRequest
|
Un record strutturato nel formato
del campo LogEntry
HttpRequest. |
"httpRequest":{"requestMethod":"GET"}
|
| campi correlati al tempo | timestamp
|
Per ulteriori informazioni, consulta Campi relativi al tempo. | "time":"2020-10-12T07:20:50.52Z"
|
logging.googleapis.com/insertId
|
insertId
|
Per ulteriori informazioni, consulta insertId nella pagina LogEntry. |
"logging.googleapis.com/insertId":"42"
|
logging.googleapis.com/labels
|
labels
|
Il valore di questo campo deve essere un record strutturato.
Per ulteriori informazioni, consulta labels nella pagina LogEntry. |
"logging.googleapis.com/labels":
{"user_label_1":"value_1","user_label_2":"value_2"}
|
logging.googleapis.com/operation
|
operation
|
Il valore di questo campo viene utilizzato anche da Logs Explorer per raggruppare le voci di log correlate.
Per ulteriori informazioni, consulta operation nella pagina LogEntry. |
"logging.googleapis.com/operation":
{"id":"get_data","producer":"github.com/MyProject/MyApplication",
"first":"true"}
|
logging.googleapis.com/sourceLocation
|
sourceLocation
|
Informazioni sulla posizione del codice
sorgente associata
all'eventuale voce di log.
Per ulteriori informazioni, consulta LogEntrySourceLocation nella pagina LogEntry. |
"logging.googleapis.com/sourceLocation":
{"file":"get_data.py","line":"142","function":"getData"}
|
logging.googleapis.com/spanId
|
spanId
|
L'ID intervallo all'interno della traccia associata alla voce di log.
Per ulteriori informazioni, consulta spanId nella pagina LogEntry. |
"logging.googleapis.com/spanId":"000000000000004a"
|
logging.googleapis.com/trace
|
trace
|
Nome della risorsa della traccia associata all'eventuale voce di log.
Per ulteriori informazioni, consulta trace nella pagina LogEntry.
|
"logging.googleapis.com/trace":"projects/my-projectid/traces/0679686673a" Nota: se non scrivi in stdout o stderr,
il valore di questo campo deve essere formattato come
projects/[PROJECT-ID]/traces/[TRACE-ID],
in modo che possa essere utilizzato da Logs Explorer e
dal visualizzatore di traccia per raggruppare le voci di log
e visualizzarle in linea con le tracce.
Se autoformat_stackdriver_trace è true e
[V] corrisponde al formato di ResourceTrace
traceId, il campo LogEntry trace ha il valore
projects/[PROJECT-ID]/traces/[V]. |
logging.googleapis.com/trace_sampled
|
traceSampled
|
Il valore di questo campo deve essere true o false.
Per ulteriori informazioni, consulta traceSampled nella pagina LogEntry. |
"logging.googleapis.com/trace_sampled": false
|
Campi relativi al tempo
In generale, le informazioni relative al tempo di una voce di log vengono memorizzate nel campo timestamp dell'oggetto LogEntry:
{
insertId: "1ad8d08f-6529-47ea-832e-467f869a2da4"
...
resource: {2}
timestamp: "2023-10-30T16:33:15.505196Z"
}
Quando l'origine di una voce di log è costituita da dati strutturati, l'agente di logging utilizza le seguenti regole per cercare informazioni relative al tempo nei campi della voce jsonPayload:
Cerca un campo
timestampche sia un oggetto JSON che includa i campisecondsenanos, che rappresentano rispettivamente un numero di secondi firmato dall'epoca UTC e un numero non negativo di secondi frazionari:jsonPayload: { ... "timestamp": { "seconds": CURRENT_SECONDS, "nanos": CURRENT_NANOS } }Se la ricerca precedente non va a buon fine, cerca una coppia di campi
timestampSecondsetimestampNanos:jsonPayload: { ... "timestampSeconds": CURRENT_SECONDS, "timestampNanos": CURRENT_NANOS }Se la ricerca precedente non va a buon fine, cerca un campo
timeche sia una stringa nel formato RFC 3339:jsonPayload: { ... "time": CURRENT_TIME_RFC3339 }
Quando vengono trovate informazioni relative al tempo, l'agente Logging le utilizza per impostare il valore di LogEntry.timestamp e non le copia dal record strutturato nell'oggetto LogEntry.jsonPayload.
I campi relativi al tempo che non vengono utilizzati per impostare il valore del campo LogEntry.timestamp vengono copiati dal record strutturato nell'oggetto LogEntry.jsonPayload. Ad esempio, se il
record strutturato contiene un oggetto JSON timestamp e un campo time,
i dati nell'oggetto JSON timestamp vengono utilizzati per impostare il
campo LogEntry.timestamp. L'oggetto LogEntry.jsonPayload contiene un campo time
perché questo campo non è stato utilizzato per impostare il valore LogEntry.timestamp.
Personalizzazione della configurazione dell'agente
Oltre all'elenco dei log predefiniti che l'agente Logging esegue in streaming per impostazione predefinita, puoi personalizzare l'agente Logging per inviare log aggiuntivi a Logging o per modificare le impostazioni dell'agente aggiungendo configurazioni di input.
Le definizioni di configurazione in queste sezioni si applicano solo al plug-in di output fluent-plugin-google-cloud e specificano in che modo i log vengono trasformati e importati in Cloud Logging.
Località dei file di configurazione principali:
- Linux:
/etc/google-fluentd/google-fluentd.conf Windows:
C:\Program Files (x86)\Stackdriver\LoggingAgent\fluent.confSe utilizzi un agente di logging precedente alla versione 1-5, la posizione è:
C:\GoogleStackdriverLoggingAgent\fluent.conf
- Linux:
Descrizione: questo file include opzioni di configurazione per controllare il comportamento del plug-in di output
fluent-plugin-google-cloud.Esamina il repository di configurazione.
Log di streaming da input aggiuntivi
Puoi personalizzare l'agente Logging in modo che invii log aggiuntivi a Logging aggiungendo configurazioni di input.
Streaming di log non strutturati (di testo) tramite file di log
Dal prompt dei comandi di Linux, crea un file di log:
touch /tmp/test-unstructured-log.logCrea un nuovo file di configurazione denominato
test-unstructured-log.confnella directory di configurazione aggiuntiva/etc/google-fluentd/config.d:sudo tee /etc/google-fluentd/config.d/test-unstructured-log.conf <<EOF <source> @type tail <parse> # 'none' indicates the log is unstructured (text). @type none </parse> # The path of the log file. path /tmp/test-unstructured-log.log # The path of the position file that records where in the log file # we have processed already. This is useful when the agent # restarts. pos_file /var/lib/google-fluentd/pos/test-unstructured-log.pos read_from_head true # The log tag for this log input. tag unstructured-log </source> EOFUn'alternativa alla creazione di un nuovo file è aggiungere le informazioni di configurazione a un file di configurazione esistente.
Riavvia l'agente per applicare le modifiche alla configurazione:
sudo service google-fluentd restartGenera un record di log nel file di log:
echo 'This is a log from the log file at test-unstructured-log.log' >> /tmp/test-unstructured-log.logControlla Esplora log per visualizzare la voce di log importata:
{ insertId: "eps2n7g1hq99qp" labels: { compute.googleapis.com/resource_name: "add-unstructured-log-resource" } logName: "projects/my-sample-project-12345/logs/unstructured-log" receiveTimestamp: "2018-03-21T01:47:11.475065313Z" resource: { labels: { instance_id: "3914079432219560274" project_id: "my-sample-project-12345" zone: "us-central1-c" } type: "gce_instance" } textPayload: "This is a log from the log file at test-unstructured-log.log" timestamp: "2018-03-21T01:47:05.051902169Z" }
Streaming dei log strutturati (JSON) tramite file di log
Puoi configurare l'agente Logging in modo che richieda che ogni voce di log sia strutturata per determinati input di log. Puoi anche personalizzare l'agente di logging per importare contenuti in formato JSON da un file di log. Quando l'agente è configurato per importare contenuti JSON, l'input deve essere formattato in modo che ogni oggetto JSON sia su una nuova riga:
{"name" : "zeeshan", "age" : 28}
{"name" : "reeba", "age" : 15}
Per configurare l'agente Logging in modo che importi i contenuti in formato JSON, procedi nel seguente modo:
Dal prompt dei comandi di Linux, crea un file di log:
touch /tmp/test-structured-log.logCrea un nuovo file di configurazione denominato
test-structured-log.confnella directory di configurazione aggiuntiva/etc/google-fluentd/config.d:sudo tee /etc/google-fluentd/config.d/test-structured-log.conf <<EOF <source> @type tail <parse> # 'json' indicates the log is structured (JSON). @type json </parse> # The path of the log file. path /tmp/test-structured-log.log # The path of the position file that records where in the log file # we have processed already. This is useful when the agent # restarts. pos_file /var/lib/google-fluentd/pos/test-structured-log.pos read_from_head true # The log tag for this log input. tag structured-log </source> EOFUn'alternativa alla creazione di un nuovo file è aggiungere le informazioni di configurazione a un file di configurazione esistente.
Riavvia l'agente per applicare le modifiche alla configurazione:
sudo service google-fluentd restartGenera un record di log nel file di log:
echo '{"code": "structured-log-code", "message": "This is a log from the log file at test-structured-log.log"}' >> /tmp/test-structured-log.logControlla Esplora log per visualizzare la voce di log importata:
{ insertId: "1m9mtk4g3mwilhp" jsonPayload: { code: "structured-log-code" message: "This is a log from the log file at test-structured-log.log" } labels: { compute.googleapis.com/resource_name: "add-structured-log-resource" } logName: "projects/my-sample-project-12345/logs/structured-log" receiveTimestamp: "2018-03-21T01:53:41.118200931Z" resource: { labels: { instance_id: "5351724540900470204" project_id: "my-sample-project-12345" zone: "us-central1-c" } type: "gce_instance" } timestamp: "2018-03-21T01:53:39.071920609Z" }In Esplora log, filtra in base al tipo di risorsa e a un valore logName di
structured-log.
Per ulteriori opzioni per personalizzare il formato di input dei log per applicazioni di terze parti comuni, consulta Formati di log comuni e come analizzarli.
Streaming dei log strutturati (JSON) tramite il plug-in in_forward
Inoltre, puoi inviare i log tramite il plug-in fluentd in_forward.
fluentd-cat è uno strumento integrato che consente di inviare facilmente i log al plug-in in_forward. La documentazione di fluentd contiene ulteriori dettagli su questo strumento.
Per inviare i log tramite il plug-in fluentd in_forward, leggi le seguenti istruzioni:
Esegui il seguente comando sulla VM con l'agente di logging installato:
echo '{"code": "send-log-via-fluent-cat", "message": "This is a log from in_forward plugin."}' | /opt/google-fluentd/embedded/bin/fluent-cat log-via-in-forward-pluginControlla Esplora log per visualizzare la voce di log importata:
{ insertId: "1kvvmhsg1ib4689" jsonPayload: { code: "send-log-via-fluent-cat" message: "This is a log from in_forward plugin." } labels: { compute.googleapis.com/resource_name: "add-structured-log-resource" } logName: "projects/my-sample-project-12345/logs/log-via-in-forward-plugin" receiveTimestamp: "2018-03-21T02:11:27.981020900Z" resource: { labels: { instance_id: "5351724540900470204" project_id: "my-sample-project-12345" zone: "us-central1-c" } type: "gce_instance" } timestamp: "2018-03-21T02:11:22.717692494Z" }
Streaming di record di log strutturati (JSON) dal codice dell'applicazione
Puoi attivare connettori in vari linguaggi per inviare log strutturati dal codice dell'applicazione. Per ulteriori informazioni, consulta la documentazione fluentd.
Questi connettori sono creati in base al plug-in in_forward.
Impostazione delle etichette delle voci di log
Le seguenti opzioni di configurazione ti consentono di sostituire le etichette LogEntry e MonitoredResource durante l'importazione dei log in Cloud Logging. Tutte le voci del log sono associate alle risorse monitorate. Per ulteriori informazioni, consulta l'elenco dei tipi di risorsa monitorata di Cloud Logging.
| Nome della configurazione | Tipo | Predefinito | Descrizione |
|---|---|---|---|
label_map |
hash | nil | label_map (specificato come oggetto JSON) è un insieme non ordinato di nomi di campi fluentd i cui valori vengono inviati come etichette anziché come parte del payload strutturato. Ogni voce della mappa è una coppia {field_name: label_name}. Quando viene rilevato field_name (come analizzato dal plug-in di input), alla voce del log viene aggiunta un'etichetta con il field_name corrispondente.label_name Il valore del campo viene utilizzato come valore dell'etichetta. La mappa offre una maggiore flessibilità nella specifica dei nomi delle etichette, inclusa la possibilità di utilizzare caratteri che non sarebbero consentiti all'interno dei nomi dei campi fluentd. Per un esempio, consulta Impostare le etichette nelle voci di log strutturate. |
labels |
hash | nil | labels (specificato come oggetto JSON) è un insieme di etichette personalizzate fornite al momento della configurazione. Ti consente di inserire informazioni ambientali aggiuntive in ogni messaggio o di personalizzare le etichette altrimenti rilevate automaticamente. Ogni voce della mappa è una coppia {label_name: label_value}. |
Il plug-in di output dell'agente Logging supporta tre modi per impostare le etichette LogEntry:
- Sostituzione dinamica di etichette specifiche in una voce strutturata con altre. Per maggiori dettagli, vedi Impostare le etichette nelle voci di log strutturate in questa pagina.
- In modo statico, l'etichetta viene associata a qualsiasi occorrenza di un valore. Per maggiori dettagli, vai a Impostare le etichette in modo statico in questa pagina.
Impostazione delle etichette nelle voci di log strutturate
Supponiamo che tu abbia scritto un payload di voce di log strutturato come questo:
{ "message": "This is a log message", "timestamp": "Aug 10 20:07:00", "env": "production" }
Supponiamo che tu voglia tradurre il campo del payload env in un'etichetta dei metadati environment. Per farlo, aggiungi quanto segue alla configurazione del plug-in di output nel file di configurazione principale (/etc/google-fluentd/google-fluentd.conf su Linux o C:\Program Files (x86)\Stackdriver\LoggingAgent\fluent.conf su Windows):
# Configure all sources to output to Cloud Logging
<match **>
@type google_cloud
label_map {
"env": "environment"
}
...
</match>
L'impostazione label_map qui sostituisce l'etichetta env nel payload con
environment, pertanto la voce di log risultante ha un'etichetta environment con
il valore production.
Impostazione delle etichette in modo statico
Se non disponi di queste informazioni nel payload e vuoi semplicemente aggiungere un'etichetta dei metadati statica denominata environment, aggiungi quanto segue alla configurazione del plug-in di output nel file di configurazione principale (/etc/google-fluentd/google-fluentd.conf su Linux o C:\Program Files (x86)\Stackdriver\LoggingAgent\fluent.conf su Windows):
# Configure all sources to output to Cloud Logging
<match **>
@type google_cloud
labels {
"environment": "production"
}
...
</match>
In questo caso, anziché utilizzare una mappa per sostituire un'etichetta con un'altra, utilizziamo un'impostazione labels per associare un'etichetta con un determinato valore letterale a una voce di log, indipendentemente dal fatto che la voce abbia già un'etichetta o meno. Questo approccio può essere utilizzato anche se invii log non strutturati.
Per scoprire di più su come configurare labels, label_map e altre impostazioni dell'agente Logging, vai a Impostare le etichette delle voci di log in questa pagina.
Modifica dei record dei log
Fluentd fornisce plug-in di filtro integrati che possono essere utilizzati per modificare le voci di log.
Il plug-in di filtro più utilizzato è filter_record_transformer. Ti consente di:
- Aggiungere nuovi campi alle voci di log
- Aggiornare i campi nelle voci di log
- Eliminare i campi nelle voci di log
Alcuni plug-in di output ti consentono anche di modificare le voci di log.
Il plug-in di output fluent-plugin-record-reformer fornisce funzionalità simili al plug-in di filtro filter_record_transformer, tranne per il fatto che consente anche di modificare i tag di log.
Con questo plug-in è previsto un maggiore utilizzo delle risorse: ogni volta che un tag log viene aggiornato, viene generata una nuova voce di log con il nuovo tag.
Tieni presente che il campo tag nella configurazione è obbligatorio. Ti consigliamo inoltre di modificarlo per evitare di entrare in un loop infinito.
Il plug-in di output fluent-plugin-detect-exceptions esegue la scansione di uno stream di log, di record di log non strutturati (di testo) o in formato JSON, per rilevare tracce dello stack delle eccezioni su più righe. Se una sequenza consecutiva di voci di log forma una analisi dello stack delle eccezioni,
le voci di log vengono inoltrate come un singolo messaggio di log combinato. In caso contrario, la voce di log viene inoltrata così com'è.
Definizioni di configurazione avanzate (non predefinite)
Se vuoi personalizzare la configurazione dell'agente di logging oltre la configurazione predefinita, continua a leggere questa pagina.
Opzioni di configurazione relative ai buffer
Le seguenti opzioni di configurazione ti consentono di regolare il meccanismo di buffering interno dell'agente di logging.
| Nome della configurazione | Tipo | Predefinito | Descrizione |
|---|---|---|---|
buffer_type |
string | buf_memory |
I record che non possono essere scritti nell'API Logging abbastanza rapidamente vengono inseriti in un buffer. Il buffer può essere in memoria o in file effettivi. Valore consigliato: buf_file. Il valore predefinito buf_memory è veloce, ma non persistente. Esiste il rischio di perdere i log. Se buffer_type è buf_file, è necessario specificare anche buffer_path. |
buffer_path |
string | Specificato dall'utente | Il percorso in cui sono archiviati i blocchi del buffer. Questo parametro è obbligatorio se buffer_type è file. Questa configurazione deve essere univoca per evitare una race condition. |
buffer_queue_limit |
int | 64 |
Specifica il limite di lunghezza della coda di chunk. Quando la coda del buffer raggiunge questo numero di chunk, il comportamento del buffer è controllato da buffer_queue_full_action. Per impostazione predefinita, vengono lanciate eccezioni. Questa opzione, in combinazione con buffer_chunk_limit, determina lo spazio su disco massimo utilizzato da fluentd per il buffering. |
buffer_queue_full_action |
string | exception |
Controlla il comportamento del buffer quando la coda del buffer è piena. Valori possibili: 1. exception: lancia BufferQueueLimitError quando la coda è piena. La modalità di gestione di BufferQueueLimitError dipende dai plug-in di input. Ad esempio, il plug-in di input in_tail interrompe la lettura di nuove righe, mentre il plug-in di input in_forward restituisce un errore. 2. block: questa modalità interrompe il thread del plug-in di input finché la condizione di buffer pieno non viene risolta. Questa azione è ideale per i casi d'uso batch. fluentd sconsiglia di utilizzare l'azione di blocco per evitare BufferQueueLimitError. Se raggiungi spesso BufferQueueLimitError, significa che la capacità di destinazione non è sufficiente per il tuo traffico. 3. drop_oldest_chunk: questa modalità elimina i chunk più vecchi. |
Opzioni di configurazione relative ai progetti e alle risorse monitorate
Le seguenti opzioni di configurazione ti consentono di specificare manualmente un progetto e alcuni campi dell'oggetto MonitoredResource. Questi valori vengono raccolti automaticamente dall'agente Logging. Non è consigliabile specificarli manualmente.
| Nome della configurazione | Tipo | Predefinito | Descrizione |
|---|---|---|---|
project_id |
string | nil | Se specificato, sostituisce il project_id che identifica il progetto Google Cloud o AWS sottostante in cui è in esecuzione l'agente di logging. |
zone |
string | nil | Se specificato, sostituisce la zona. |
vm_id |
string | nil | Se specificato, sostituisce l'ID VM. |
vm_name |
string | nil | Se specificato, sostituisce il nome della VM. |
Altre opzioni di configurazione del plug-in di output
| Nome della configurazione | Tipo | Predefinito | Descrizione |
|---|---|---|---|
detect_json1 |
bool | false |
Indica se tentare di rilevare se il record del log è una voce di log di testo con contenuti JSON che devono essere analizzati. Se questa opzione è true e viene rilevata una voce di log non strutturata (di testo) in formato JSON, viene analizzata e inviata come payload strutturato (JSON). |
coerce_to_utf8 |
bool | true |
Indica se consentire caratteri non UTF-8 nei log utente. Se impostato su true, qualsiasi carattere non UTF-8 verrà sostituito dalla stringa specificata da non_utf8_replacement_string. Se impostato su false, qualsiasi carattere non UTF-8 attiverà un errore nel plug-in. |
require_valid_tags |
bool | false |
Indica se rifiutare le voci di log con tag non validi. Se questa opzione è impostata su false, i tag vengono convalidati convertendo qualsiasi tag non stringa in una stringa e sottoponendo a sanificazione tutti i caratteri non UTF-8 o altri caratteri non validi. |
non_utf8_replacement_string |
string | ""(spazio) |
Se coerce_to_utf8 è impostato su true, qualsiasi carattere non UTF-8 verrà sostituito dalla stringa specificata qui. |
1 Questa funzionalità è abilitata per impostazione predefinita nelle istanze VM in esecuzione nell'ambiente flessibile di App Engine e in Google Kubernetes Engine.
Applicazione della configurazione dell'agente personalizzata
La personalizzazione dell'agente Logging ti consente di aggiungere i tuoi file di configurazione fluentd:
Istanza Linux
Copia i file di configurazione nella seguente directory:
/etc/google-fluentd/config.d/Lo script di installazione dell'agente Logging compila questa directory con i file di configurazione catch-all predefiniti. Per ulteriori informazioni, consulta Ottenere il codice sorgente dellagente Logging log.
Facoltativo. Convalida la modifica della configurazione eseguendo il seguente comando:
sudo service google-fluentd configtestRiavviare l'agente eseguendo il seguente comando:
sudo service google-fluentd force-reload
Instanza Windows
Copia i file di configurazione nella sottodirectory
config.ddella directory di installazione dell'agente. Se hai accettato la directory di installazione predefinita, questa è:C:\Program Files (x86)\Stackdriver\LoggingAgent\config.d\Riavviare l'agente eseguendo i seguenti comandi in una shell di riga di comando:
net stop StackdriverLogging net start StackdriverLogging
Per ulteriori informazioni sui file di configurazione fluentd, consulta la documentazione sulla sintassi dei file di configurazione di fluentd.