Options for load balancing
Depending on the type of traffic sent to your application, you have several options for external load balancing. The following table summarizes your options:
| Option | Description | Traffic flow | Scope |
|---|---|---|---|
| External Application Load Balancer | Supports HTTP(S) traffic and advanced features, such as URL mapping
and SSL offloading Use an external proxy Network Load Balancer for non-HTTP traffic on specific ports. |
The TCP or SSL (TLS) session is terminated at Google Front Ends (GFEs), at Google's network edge, and traffic is proxied to the backends. | Global |
| External passthrough Network Load Balancer | Allows TCP/UDP traffic using any port to pass through the load balancer. | Delivered using Google's Maglev technology to distribute the traffic to the backends. | Regional |
Because the internal load balancers and Cloud Service Mesh don't support user-facing traffic, they are out of scope for this article.
This article's measurements use the Premium Tier in Network Service Tiers because global load balancing requires this service tier.
Measuring latency
When accessing a website that is hosted in us-central1, a user in Germany uses
the following methods to test latency:
- Ping: While ICMP ping is a common way to measure server reachability, ICMP ping doesn't measure end-user latency. For more information, see Additional latency effects of an external Application Load Balancer.
- Curl: Curl measures Time To First Byte (TTFB). Issue a
curlcommand repeatedly to the server.
When comparing results, be aware that latency on fiber links is constrained by the distance and the speed of light in fiber, which is roughly 200,000 km per second (or 124,724 miles per second).
The distance between Frankfurt, Germany and Council Bluffs, Iowa (the
us-central1 region), is roughly 7,500 km. With straight fiber between the
locations, round-trip latency is the following:
7,500 km * 2 / 200,000 km/s * 1000 ms/s = 75 milliseconds (ms)
Fiber optic cable doesn't follow a straight path between the user and the data center. Light on the fiber cable passes through active and passive equipment along its path. An observed latency of approximately 1.5 times the ideal, or 112.5 ms, indicates a near-ideal configuration.
Comparing latency
This section compares load balancing in the following configurations:
- No load balancing
- External passthrough Network Load Balancer
- External Application Load Balancer or External proxy Network Load Balancer
In this scenario, the application consists of a regional managed instance group
of HTTP web servers. Because the application relies on low-latency calls to a
central database, the web servers must be hosted in one location. The
application is deployed in the us-central1 region, and users are distributed
across the globe. The latency that the user in Germany observes in this scenario
illustrates what users worldwide might experience.

No load balancing
When a user makes an HTTP request, unless load balancing is configured, the traffic flows directly from the user’s network to the virtual machine (VM) hosted on Compute Engine. For Premium Tier, traffic then enters Google's network at an edge point of presence (PoP) close to the user's location. For Standard Tier, the user traffic enters Google's network at a PoP close to the destination region. For more information, see the Network Service Tiers documentation.
{kind=link}

The following table shows the results when the user in Germany tested latency of a system with no load balancing:
| Method | Result | Minimum latency |
|---|---|---|
| Ping the VM IP address (Response is directly from web server) |
ping -c 5 compute-engine-vm PING compute-engine-vm (xxx.xxx.xxx.xxx) 56(84) bytes of data. 64 bytes from compute-engine-vm (xxx.xxx.xxx.xxx): icmp_seq=1 ttl=56 time=111 ms 64 bytes from compute-engine-vm (xxx.xxx.xxx.xxx): icmp_seq=2 ttl=56 time=110 ms [...] --- compute-engine-vm ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4004ms rtt min/avg/max/mdev = 110.818/110.944/111.265/0.451 ms |
110 ms |
| TTFB |
for ((i=0; i < 500; i++)); do curl -w /
"%{time_starttransfer}\n" -o /dev/null -s compute-engine-vm; done
0.230 0.230 0.231 0.231 0.230 [...] 0.232 0.231 0.231 |
230 ms |
The TTFB latency is stable, as shown in the following graph of the first 500 requests:
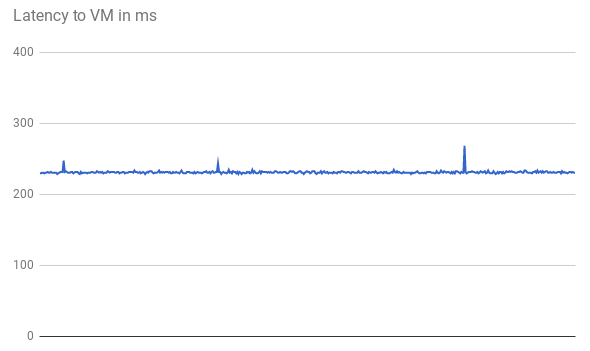
When pinging the VM IP address, the response comes directly from the web server. The response time from the web server is minimal compared to the network latency (TTFB). This is because a new TCP connection is opened for every HTTP request. An initial three-way handshake is needed before the HTTP response is sent, as shown in the following diagram. Therefore, the observed latency is close to double the ping latency.

External passthrough Network Load Balancer
With external passthrough Network Load Balancers, user requests still enter the Google network at the closest edge PoP (in Premium Tier). In the region where the project's VMs are located, traffic flows first through an external passthrough Network Load Balancer. It is then forwarded without changes to the target backend VM. The external passthrough Network Load Balancer distributes traffic based on a stable hashing algorithm. The algorithm uses a combination of source and destination port, IP address, and protocol. The VMs listen to the load balancer IP and accept the traffic unaltered.

The following table shows the results when the user in Germany tested latency for the network-load-balancing option.
| Method | Result | Minimum latency |
|---|---|---|
| Ping the external passthrough Network Load Balancer |
ping -c 5 net-lb PING net-lb (xxx.xxx.xxx.xxx) 56(84) bytes of data. 64 bytes from net-lb (xxx.xxx.xxx.xxx): icmp_seq=1 ttl=44 time=110 ms 64 bytes from net-lb (xxx.xxx.xxx.xxx): icmp_seq=2 ttl=44 time=110 ms [...] 64 bytes from net-lb (xxx.xxx.xxx.xxx): icmp_seq=5 ttl=44 time=110 ms --- net-lb ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4007ms rtt min/avg/max/mdev = 110.658/110.705/110.756/0.299 ms |
110 ms |
| TTFB |
for ((i=0; i < 500; i++)); do curl -w /
"%{time_starttransfer}\n" -o /dev/null -s net-lb
0.231 0.232 0.230 0.230 0.232 [...] 0.232 0.231 |
230 ms |
Because load balancing takes place within a region and traffic is only forwarded, there is no significant latency impact compared with having no load balancer.
External load balancing
With external Application Load Balancers, GFEs proxy traffic. These GFEs are at the edge of Google's global network. The GFE terminates the TCP session and connects to a backend in the closest region that can serve the traffic.

The following table shows the results when the user in Germany tested latency for the HTTP-load-balancing option.
| Method | Result | Minimum latency |
|---|---|---|
| Ping the external Application Load Balancer |
ping -c 5 http-lb PING http-lb (xxx.xxx.xxx.xxx) 56(84) bytes of data. 64 bytes from http-lb (xxx.xxx.xxx.xxx): icmp_seq=1 ttl=56 time=1.22 ms 64 bytes from http-lb (xxx.xxx.xxx.xxx): icmp_seq=2 ttl=56 time=1.20 ms 64 bytes from http-lb (xxx.xxx.xxx.xxx): icmp_seq=3 ttl=56 time=1.16 ms 64 bytes from http-lb (xxx.xxx.xxx.xxx): icmp_seq=4 ttl=56 time=1.17 ms 64 bytes from http-lb (xxx.xxx.xxx.xxx): icmp_seq=5 ttl=56 time=1.20 ms --- http-lb ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4005ms rtt min/avg/max/mdev = 1.163/1.195/1.229/0.039 ms |
1 ms |
| TTFB |
for ((i=0; i < 500; i++)); do curl -w /
"%{time_starttransfer}\n" -o /dev/null -s http-lb; done
0.309 0.230 0.229 0.233 0.230 [...] 0.123 0.124 0.126 |
123 ms |
The results for the external Application Load Balancer are significantly different. When
pinging the external Application Load Balancer, the round-trip latency is slightly over
1 ms. This result represents latency to the closest GFE, which is located in the
same city as the user. This result doesn't reflect the actual latency that the
user experiences when trying to access the application that is hosted in the
us-central1 region. Experiments using protocols (ICMP) that differ from your
application communication protocol (HTTP) can be misleading.
When measuring TTFB, the initial requests show similar response latency. Some requests achieve the lower minimum latency of 123 ms, as shown in the following graph:
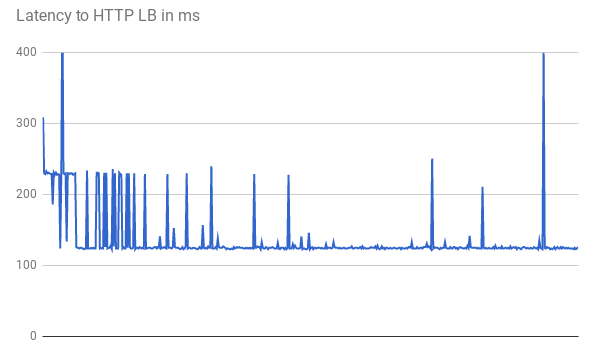
Two round trips between the client and the VM take more than 123 ms even with straight fiber. The latency is lower because GFEs proxy the traffic. GFEs maintain persistent connections to the backend VMs. Therefore, only the first request from a specific GFE to a specific backend requires a three-way handshake.
Each location has multiple GFEs. The latency graph shows multiple, fluctuating spikes the first time that traffic reaches each GFE-backend pair. The GFE must then establish a new connection to that backend. These spikes reflect differing request hashes. Subsequent requests show lower latency.

These scenarios demonstrate the reduced latency that users can experience in a production environment. The following table summarizes the results:
| Option | Ping | TTFB |
|---|---|---|
| No load balancing | 110 ms to the web server | 230 ms |
| External passthrough Network Load Balancer | 110 ms to the in-region external passthrough Network Load Balancer | 230 ms |
| External Application Load Balancer | 1 ms to the closest GFE | 123 ms |
When a healthy application is serving users in a specific region, GFEs in that region maintain a persistent connection open to all serving backends. Because of this, users in that region notice reduced latency on their first HTTP request if users are far from the application backend. If users are near the application backend, the users don't notice latency improvement.
For subsequent requests, such as clicking a page link, there is no latency
improvement because modern browsers maintain a persistent connection to the
service. This differs from a curl command issued from the command line.
Additional latency effects of the external Application Load Balancer
Additional observable effects with the external Application Load Balancer depend on traffic patterns.
The external Application Load Balancer has less latency for complex assets than the external passthrough Network Load Balancer because fewer round trips are needed before a response completes. For example, when the user in Germany measures latency over the same connection by repeatedly downloading a 10 MB file, the average latency for the external passthrough Network Load Balancer is 1911 ms. With the external Application Load Balancer, the average latency is 1341 ms. This saves approximately 5 round trips per request. Persistent connections between GFEs and serving backends reduce the effects of TCP Slow Start.
The external Application Load Balancer significantly reduces the additional latency for a TLS handshake (typically 1–2 extra roundtrips). This is because the external Application Load Balancer uses SSL offloading, and only the latency to the edge PoP is relevant. For the user in Germany, the minimum observed latency is 201 ms using the external Application Load Balancer, versus 525 ms using HTTP(S) through the external passthrough Network Load Balancer.
The external Application Load Balancer allows an automatic upgrade of the user-facing session to HTTP/2. HTTP/2 can reduce the number of packets needed, by using improvements in binary protocol, header compression, and connection multiplexing. These improvements can reduce the observed latency even more than that observed by switching to the external Application Load Balancer. HTTP/2 is supported with current browsers that use SSL/TLS. For the user in Germany, minimum latency decreased further from 201 ms to 145 ms when using HTTP/2 instead of HTTPS.
Optimizing external Application Load Balancers
You can optimize latency for your application by using the external Application Load Balancer as follows:
If some of the traffic you serve is cacheable, you can integrate with Cloud CDN. Cloud CDN reduces latency by serving assets directly at Google's network edge. Cloud CDN also uses the TCP and HTTP optimizations from HTTP/2 mentioned in the Additional latency effects of the external Application Load Balancer section.
You can use any CDN partner with Google Cloud. By using one of Google's CDN Interconnect partners, you benefit from discounted data transfer costs.
If content is static, you can reduce the load on the web servers by serving content directly from Cloud Storage through the external Application Load Balancer. This option combines with the Cloud CDN.
Deploying your web servers in multiple regions close to your users can reduce latency because the load balancer automatically directs users to the closest region. However, if your application is partly centralized, design it to decrease the number of inter-regional round trips.
To reduce latency inside your applications, examine any remote procedure calls (RPCs) that communicate between VMs. This latency typically occurs when applications communicate between tiers or services. Tools such as Cloud Trace can help you decrease latency caused by application-serving requests.
Because external proxy Network Load Balancers are based on GFEs, the effect on latency is the same as observed with the external Application Load Balancer. Because the external Application Load Balancer has more features than the external proxy Network Load Balancer, we recommend using external Application Load Balancers for HTTP(S) traffic.
Next steps
We recommend that you deploy your application close to most of your users. For more information about the different load balancing options in Google Cloud, see the following documents:
- External passthrough Network Load Balancer
- External Application Load Balancer
- External proxy Network Load Balancer