大多数负载平衡器均使用轮循或基于流的哈希方法来分配流量。当流量需求超出可用传送容量时,使用此方法的负载均衡器可能难以适应。本教程介绍了 Cloud Load Balancing 如何优化您的全球应用容量,与大多数负载均衡实现相比,这种方法可以改进用户体验并降低费用。
本文是 Cloud Load Balancing 产品最佳做法系列文章的一部分。本教程与通过全球负载均衡优化应用容量配套,后者是一篇概念性文章,更详细地解释了全局负载均衡溢出的基本机制。如需更深入地了解延迟,请参阅使用 Cloud Load Balancing 优化应用延迟。
本教程假定您具有使用 Compute Engine 的一定经验。 您还应该熟悉外部应用负载均衡器基础知识。
目标
在本教程中,您将设置一个运行 CPU 密集型应用的简单网络服务器,该应用计算 Mandelbrot 集。首先,使用负载测试工具(siege 和 httperf)衡量其网络容量。然后,您可以将网络扩展到单个区域中的多个虚拟机实例,并测量负载下的响应时间。最后,使用全局负载均衡将网络扩展到多个区域,并测量服务器在负载下的响应时间,然后将其与单区域负载均衡进行比较。通过执行此测试序列,您就可以了解 Cloud Load Balancing 的跨区域负载管理的积极影响。
典型三层服务器架构的网络通信速度通常受应用服务器速度或数据库容量的限制,但不受网络服务器上 CPU 负载的限制。完成本教程的学习后,您可以使用相同的负载测试工具和容量设置来优化实际应用中的负载均衡行为。
您将学习以下内容:
- 了解如何使用负载测试工具(
siege和httperf)。 - 确定单个虚拟机实例的传送容量。
- 用单区域负载均衡测量过载的影响。
- 使用全局负载均衡测量溢出对于另一个区域的影响。
费用
本教程使用 Google Cloud的计费组件,包括:
- Compute Engine
- 负载均衡和转发规则
您可使用价格计算器根据您的预计使用情况来估算费用。
准备工作
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
设置环境
在本部分中,您将配置完成本教程所需的项目设置、VPC 网络和基本防火墙规则。
启动 Cloud Shell 实例
从 Google Cloud 控制台打开 Cloud Shell。 除非另有说明,否则您可以直接在 Cloud Shell 内完成本教程其余部分的操作。
配置项目设置
为更加轻松地运行 gcloud 命令,您可以设置属性,这样就不必在输入每条命令时都提供有关这些属性的选项。
使用
[PROJECT_ID]的项目 ID 设置默认项目:gcloud config set project [PROJECT_ID]
使用
[ZONE]的首选可用区设置默认的 Compute Engine 可用区,然后将此设置为一个环境变量,以供后续使用:gcloud config set compute/zone [ZONE] export ZONE=[ZONE]
创建和配置 VPC 网络
为测试创建一个 VPC 网络:
gcloud compute networks create lb-testing --subnet-mode auto
定义一条防火墙规则以允许内部流量:
gcloud compute firewall-rules create lb-testing-internal \ --network lb-testing --allow all --source-ranges 10.128.0.0/11定义一条防火墙规则以允许 SSH 流量与 VPC 网络通信:
gcloud compute firewall-rules create lb-testing-ssh \ --network lb-testing --allow tcp:22 --source-ranges 0.0.0.0/0
确定单个虚拟机实例的服务容量
为了检查一个虚拟机实例类型的性能特征,您需要执行以下操作:
设置一个用于传送示例工作负载的虚拟机实例(网络服务器实例)。
在同一地区创建第二个虚拟机示例(负载测试实例)。
您将使用第二个虚拟机实例,通过简单的负载测试和性能测量工具来衡量性能。您将在本教程稍后部分中使用这些测量结果,帮助为实例组定义正确的负载平衡容量设置。
第一个虚拟机实例使用 Python 脚本,在每次请求中计算 Mandelbrot 集合并将其显示到根 (/) 路径下,从而创建 CPU 密集型任务。结果不会缓存。在本教程中,您将从此解决方案 GitHub 代码库中获取 Python 脚本。
设置虚拟机实例
首先安装并启动 Mandelbrot 服务器,将
webserver虚拟机实例设置为一个 4 核虚拟机实例:gcloud compute instances create webserver --machine-type n1-highcpu-4 \ --network=lb-testing --image-family=debian-12 \ --image-project=debian-cloud --tags=http-server \ --metadata startup-script='#! /bin/bash apt-get -y update apt-get install -y git python-numpy python-matplotlib git clone \ https://github.com/GoogleCloudPlatform/lb-app-capacity-tutorial-python.git cd lb-app-capacity-tutorial-python python webserver.py'创建一条防火墙规则以允许您使用自己的机器从外部访问
webserver实例:gcloud compute firewall-rules create lb-testing-http \ --network lb-testing --allow tcp:80 --source-ranges 0.0.0.0/0 \ --target-tags http-server获取
webserver实例的 IP 地址:gcloud compute instances describe webserver \ --format "value(networkInterfaces[0].accessConfigs[0].natIP)"在网络浏览器中,转到上一个命令返回的 IP 地址。 您会看到一个计算得出的 Mandelbrot 集:
创建负载测试实例:
gcloud compute instances create loadtest --machine-type n1-standard-1 \ --network=lb-testing --image-family=debian-12 \ --image-project=debian-cloud
测试虚拟机实例
下一步是运行请求以衡量负载测试虚拟机实例的性能特征。
使用
ssh命令连接到负载测试虚拟机实例:gcloud compute ssh loadtest
在负载测试实例上,安装 siege 和 httperf 作为负载测试工具:
sudo apt-get install -y siege httperf
siege工具允许模拟来自指定数量用户的请求,仅在用户收到响应后才生成后续请求。这使您可以深入了解真实环境中应用的容量和预期响应时间。无论是否收到响应或错误,
httperf工具都允许每秒发送特定数量的请求。这使您可以深入了解应用如何响应特定负载。为针对网络服务器发出的简单请求计时:
curl -w "%{time_total}\n" -o /dev/#objectives_2 -s webserver您收到一条响应,例如 0.395260。也就是说,服务器花了 395 毫秒 (ms) 来响应您的请求。
使用以下命令并行运行来自 4 个用户的 20 个请求:
siege -c 4 -r 20 webserver
您将看到类似如下所示的输出:
** SIEGE 4.0.2 ** Preparing 4 concurrent users for battle. The server is now under siege... Transactions: 80 hits Availability: 100.00 % Elapsed time: 14.45 secs Data transferred: 1.81 MB Response time: 0.52 secs Transaction rate: 5.05 trans/sec Throughput: 0.12 MB/sec Concurrency: 3.92 Successful transactions: 80 Failed transactions: 0 **Longest transaction: 0.70 Shortest transaction: 0.37 **
siege 手册中完整解释了输出结果,但在本例中您可以看到,响应时间在 0.37 秒与 0.7 秒之间不等。系统每秒平均响应 5.05 个请求。该数据有助于预估系统的传送容量。
运行以下命令以使用
httperf负载测试工具验证发现结果:httperf --server webserver --num-conns 500 --rate 4
此命令以每秒 4 个请求的速率运行 500 个请求,这小于
siege完成的每秒 5.05 个事务。您将看到类似如下所示的输出:
httperf --client=0/1 --server=webserver --port=80 --uri=/ --rate=4 --send-buffer=4096 --recv-buffer=16384 --num-conns=500 --num-calls=1 httperf: warning: open file limit > FD_SETSIZE; limiting max. # of open files to FD_SETSIZE Maximum connect burst length: 1 Total: connections 500 requests 500 replies 500 test-duration 125.333 s Connection rate: 4.0 conn/s (251.4 ms/conn, <=2 concurrent connections) **Connection time [ms]: min 369.6 avg 384.5 max 487.8 median 377.5 stddev 18.0 Connection time [ms]: connect 0.3** Connection length [replies/conn]: 1.000 Request rate: 4.0 req/s (251.4 ms/req) Request size [B]: 62.0 Reply rate [replies/s]: min 3.8 avg 4.0 max 4.0 stddev 0.1 (5 samples) Reply time [ms]: response 383.8 transfer 0.4 Reply size [B]: header 117.0 content 24051.0 footer 0.0 (total 24168.0) Reply status: 1xx=0 2xx=100 3xx=0 4xx=0 5xx=0 CPU time [s]: user 4.94 system 20.19 (user 19.6% system 80.3% total 99.9%) Net I/O: 94.1 KB/s (0.8*10^6 bps) Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
httperf README 文件中解释了输出结果。请注意以
Connection time [ms]开头的行,其中显示连接总计用时介于 369.6 毫秒与 487.8 毫秒之间,生成的错误数量是零。重复该测试 3 次,将
rate选项设置为每秒 5 个、7 个和 10 个请求。以下代码块显示了
httperf命令及其输出(仅显示带有连接时间信息的相关行)。每秒 5 个请求的命令:
httperf --server webserver --num-conns 500 --rate 5 2>&1| grep 'Errors\|ion time'
每秒 5 个请求的结果:
Connection time [ms]: min 371.2 avg 381.1 max 447.7 median 378.5 stddev 7.2 Connection time [ms]: connect 0.2 Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
每秒 7 个请求的命令:
httperf --server webserver --num-conns 500 --rate 7 2>&1| grep 'Errors\|ion time'
每秒 7 个请求的结果:
Connection time [ms]: min 373.4 avg 11075.5 max 60100.6 median 8481.5 stddev 10284.2 Connection time [ms]: connect 654.9 Errors: total 4 client-timo 0 socket-timo 0 connrefused 0 connreset 4 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
每秒 10 个请求的命令:
httperf --server webserver --num-conns 500 --rate 10 2>&1| grep 'Errors\|ion time'
每秒 10 个请求的结果:
Connection time [ms]: min 374.3 avg 18335.6 max 65533.9 median 10052.5 stddev 16654.5 Connection time [ms]: connect 181.3 Errors: total 32 client-timo 0 socket-timo 0 connrefused 0 connreset 32 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
退出
webserver实例:exit
您可以根据这些测量结果得出结论,系统的容量大约为 5 个请求/秒 (RPS)。在每秒 5 个请求的速率下,虚拟机实例的响应时间可与 4 个连接相媲美。在每秒 7 个连接和 10 个连接的情况下,由于存在多个连接错误,平均响应时间会急剧增加到 10 秒以上。换句话说,只要每秒请求数超过 5 个,那么就会显著降低性能。
在更复杂的系统中,服务器容量会以类似的方式确定,但在很大程度上取决于其所有组件的容量。您可以将 siege 和 httperf 工具与所有组件(例如前端服务器、应用服务器和数据库服务器)的 CPU 与 I/O 负载监控结合使用,以帮助识别瓶颈问题。这可以进而帮助您为各组件实现最优扩缩。
使用单区域负载均衡器测量过载的影响
在本部分中,您将了解过载对于单区域负载均衡器的影响,例如在本地使用的典型负载均衡器或 Google Cloud外部直通式网络负载均衡器。 在负载均衡器用于区域(而非全球)部署时,您还可以使用 HTTP(S) 负载均衡器观察此效果。
创建单区域 HTTP(S) 负载均衡器
以下步骤描述了如何创建大小规定为 3 个虚拟机实例的单区域 HTTP(S) 负载均衡器。
使用您之前使用的 Python Mandelbrot 生成脚本,为网络服务器虚拟机实例创建实例模板。在 Cloud Shell 中运行以下命令:
gcloud compute instance-templates create webservers \ --machine-type n1-highcpu-4 \ --image-family=debian-12 --image-project=debian-cloud \ --tags=http-server \ --network=lb-testing \ --metadata startup-script='#! /bin/bash apt-get -y update apt-get install -y git python-numpy python-matplotlib git clone \ https://github.com/GoogleCloudPlatform/lb-app-capacity-tutorial-python.git cd lb-app-capacity-tutorial-python python webserver.py'根据上一步中的模板创建一个包含 3 个实例的托管式实例组:
gcloud compute instance-groups managed create webserver-region1 \ --size=3 --template=webservers创建生成 HTTP 负载均衡所需的运行状况检查、后端服务、网址映射、目标代理和全局转发规则:
gcloud compute health-checks create http basic-check \ --request-path="/health-check" --check-interval=60s gcloud compute backend-services create web-service \ --health-checks basic-check --global gcloud compute backend-services add-backend web-service \ --global --instance-group=webserver-region1 \ --instance-group-zone $ZONE gcloud compute url-maps create web-map --default-service web-service gcloud compute target-http-proxies create web-proxy --url-map web-map gcloud compute forwarding-rules create web-rule --global \ --target-http-proxy web-proxy --ports 80获取转发规则的 IP 地址:
gcloud compute forwarding-rules describe --global web-rule --format "value(IPAddress)"
输出是您创建的负载均衡器的公共 IP 地址。
在浏览器中,转到上一条命令返回的 IP 地址。几分钟后,您会看到之前看到过的 Mandelbrot 图片。但是,这次的图片是由新创建的组中的一个虚拟机实例传送的。
登录
loadtest机器:gcloud compute ssh loadtest
在
loadtest机器的命令行中,使用不同的每秒请求数 (RPS) 测试服务器响应。确保至少使用 5 到 20 范围内的 RPS 值。例如,以下命令会生成 10 RPS。将
[IP_address]替换为此过程中先前步骤的负载均衡器的 IP 地址。httperf --server [IP_address] --num-conns 500 --rate 10 2>&1| grep 'Errors\|ion time'
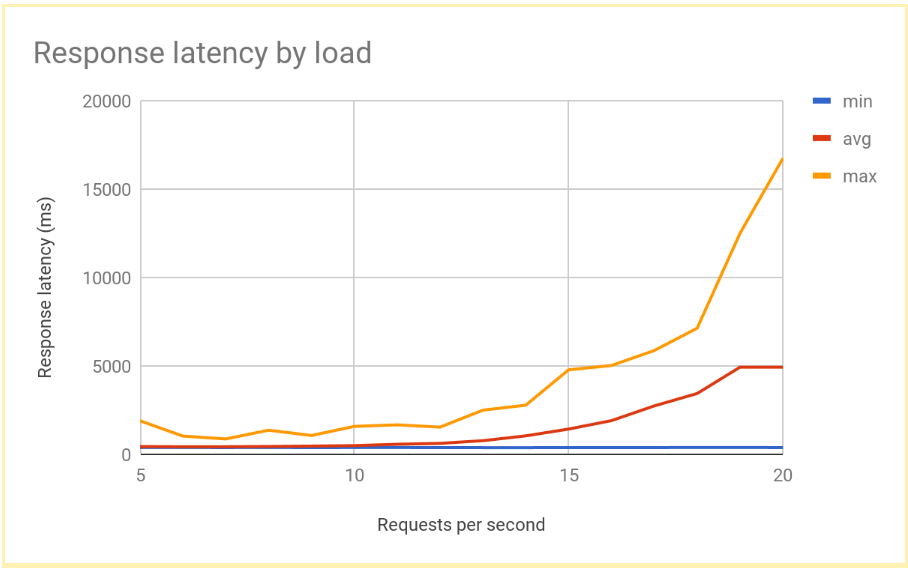
随着 RPS 数量增加到 12 或 13 RPS 以上,响应延迟会显著增加。下图直观呈现了典型结果:
退出
loadtest虚拟机实例:exit
这是区域负载平衡系统能实现的典型性能。随着负载增加到超过传送容量的程度,平均以及最大请求延迟会急剧增加。使用 10 RPS 时,平均请求延迟接近 500 毫秒,但使用 20 RPS 时,延迟为 5000 毫秒。此时延迟增加了十倍,用户体验迅速恶化,导致用户中断和/或应用超时。
在下一部分中,您将向负载平衡拓扑添加第二个区域,并比较跨区域故障转移会对最终用户延迟产生怎样的影响。
测量溢出对于另一个区域的影响
如果您使用具有外部应用负载均衡器的全球应用,并且如果您在多个区域中部署了后端,则在一个区域中发生容量过载时,流量会自动流向另一个区域。为了验证这一点,您可以将另一个区域中的第二个虚拟机实例组添加到您在上一部分中创建的配置。
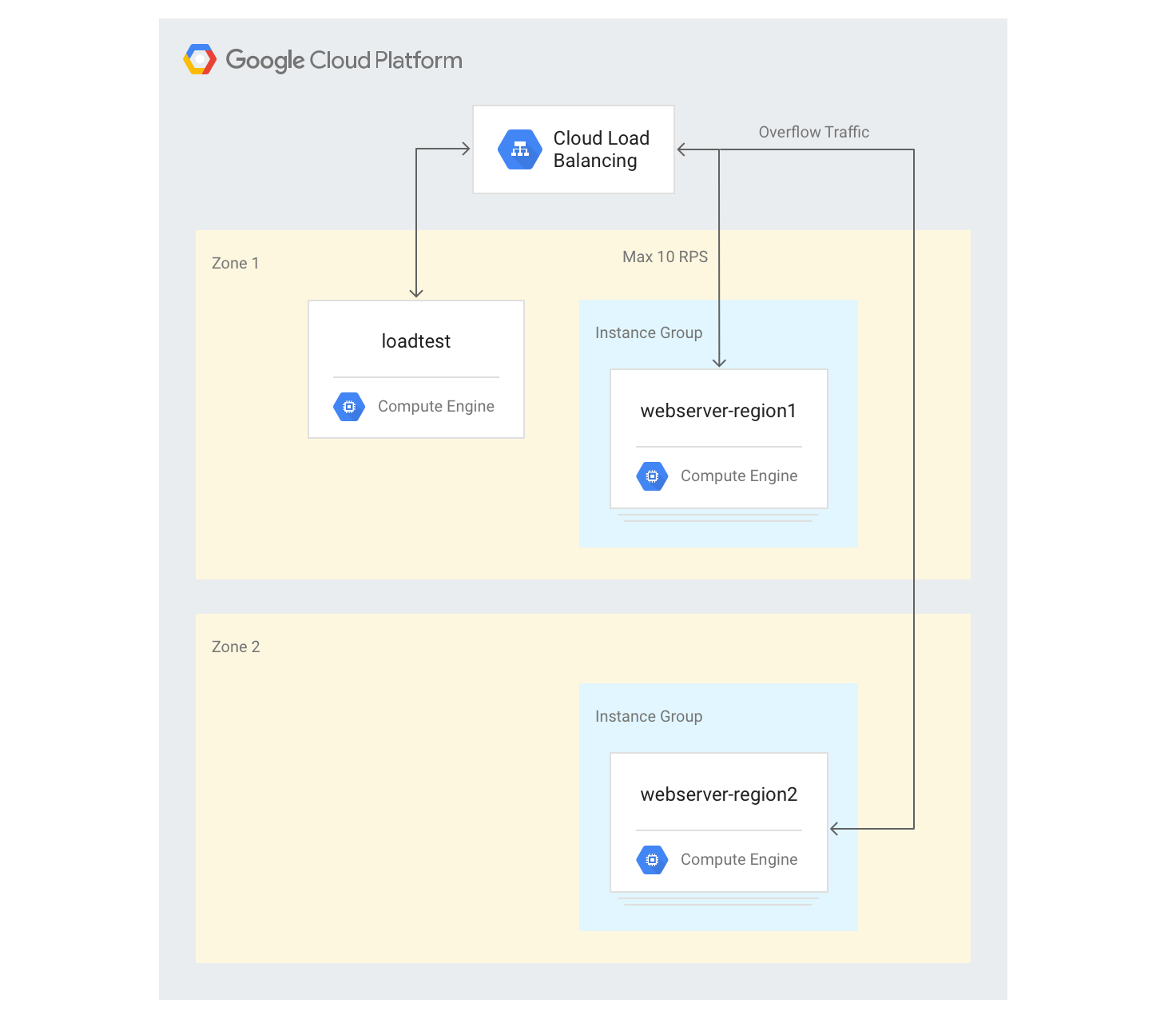
在多个区域中创建服务器
在以下步骤中,您将在另一个区域中添加另一组后端,并为每个区域分配 10 RPS 的容量。随后,您可以查看超出此限制时,负载均衡会产生怎样的反应。
在 Cloud Shell 中,在区域中选择一个不同于默认地区的地区,并将其设置为环境变量:
export ZONE2=[zone]
在具有 3 个虚拟机实例的第二个区域中创建一个新实例组:
gcloud compute instance-groups managed create webserver-region2 \ --size=3 --template=webservers --zone $ZONE2将该实例组添加到最大容量为 10 RPS 的现有后端服务:
gcloud compute backend-services add-backend web-service \ --global --instance-group=webserver-region2 \ --instance-group-zone $ZONE2 --max-rate 10将现有后端服务的
max-rate调整为 10 RPS:gcloud compute backend-services update-backend web-service \ --global --instance-group=webserver-region1 \ --instance-group-zone $ZONE --max-rate 10在所有实例启动后,登录到
loadtest虚拟机实例:gcloud compute ssh loadtest
在 10 RPS 下运行 500 个请求。将
[IP_address]替换为负载均衡器的 IP 地址:httperf --server [IP_address] --num-conns 500 --rate 10 2>&1| grep 'ion time'
您会看到如下所示的结果:
Connection time [ms]: min 405.9 avg 584.7 max 1390.4 median 531.5 stddev 181.3 Connection time [ms]: connect 1.1
结果类似于区域负载均衡器产生的结果。
因为您的测试工具会立即满负载运行,不会像在真实实现中那样缓慢增加负载,因此您必须重复测试多次才能使溢出机制生效。在 20 RPS 下运行 500 个请求 5 次。将
[IP_address]替换为负载均衡器的 IP 地址。for a in \`seq 1 5\`; do httperf --server [IP_address] \ --num-conns 500 --rate 20 2>&1| grep 'ion time' ; done您会看到如下所示的结果:
Connection time [ms]: min 426.7 avg 6396.8 max 13615.1 median 7351.5 stddev 3226.8 Connection time [ms]: connect 0.9 Connection time [ms]: min 417.2 avg 3782.9 max 7979.5 median 3623.5 stddev 2479.8 Connection time [ms]: connect 0.9 Connection time [ms]: min 411.6 avg 860.0 max 3971.2 median 705.5 stddev 492.9 Connection time [ms]: connect 0.7 Connection time [ms]: min 407.3 avg 700.8 max 1927.8 median 667.5 stddev 232.1 Connection time [ms]: connect 0.7 Connection time [ms]: min 410.8 avg 701.8 max 1612.3 median 669.5 stddev 209.0 Connection time [ms]: connect 0.8
在系统稳定后,平均响应时间在 10 RPS 时为 400 毫秒,在 20 RPS 时仅增加到 700 毫秒。与对区域负载均衡器的 5000 毫秒延迟相比,这是一项巨大的改进,带来了更好的用户体验。
下图展示了使用全局负载平衡时,按 RPS 衡量的响应时间:
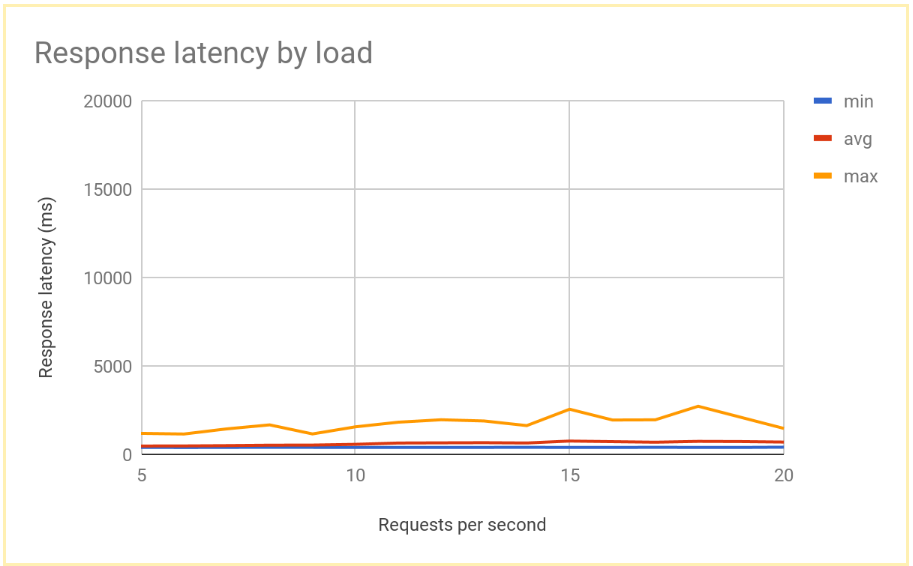
比较区域负载均衡和全局负载均衡的结果
在确定单个节点的容量之后,您可以将基于区域的部署中最终用户观察到的延迟与全局负载均衡架构中的延迟进行比较。虽然传入单个区域的请求数低于该区域中的总传送容量,但最终用户在两个系统中体验到的延迟基本相似,因为系统总是会将用户重定向到最近的区域。
在一个区域承受的负载超出该区域的传送容量时,两种解决方案之间的最终用户延迟时间会出现明显差异:
在流量增加到超过容量的程度时,区域负载均衡解决方案会过载,因为流量只能流到过载的后端虚拟机实例,无法流到其他任何地方。这包括传统的本地负载均衡器、 Google Cloud上的外部直通式网络负载均衡器以及单区域配置中的外部应用负载均衡器(例如,使用标准层级网络)。平均和最大请求延迟时间增加了 10 倍以上,导致用户体验不佳,这可能进而导致用户大量流失。
多个区域中具有后端的全球外部应用负载均衡器允许流量溢出到具有可用服务容量的最近区域。这导致最终用户延迟时间发生可衡量但相对较小的增幅,并且能提供更好的用户体验。如果您的应用无法足够快速地在某个区域中扩容,则建议使用全球外部应用负载均衡器。即使在用户应用服务器发生全区域故障期间,流量也会快速重定向到其他区域,这有助于避免服务全面中断。
清理
删除项目
为了避免产生费用,最简单的方法是删除您为本教程创建的项目。
要删除项目,请执行以下操作:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
后续步骤
以下页面提供了有关 Google 负载均衡选项的详情和背景: