BigQuery
Mit dem BigQuery-Connector können Sie Vorgänge zum Einfügen, Löschen, Aktualisieren und Lesen für Google BigQuery-Daten ausführen. Sie können auch benutzerdefinierte SQL-Abfragen für BigQuery-Daten ausführen. Mit dem BigQuery-Connector können Sie Daten aus mehreren Google Cloud-Diensten oder anderen Drittanbieterdiensten wie Cloud Storage oder Amazon S3 einbinden.
Hinweise
Führen Sie in Ihrem Google Cloud-Projekt die folgenden Aufgaben aus:
- Prüfen Sie, ob eine Netzwerkverbindung eingerichtet ist. Informationen zu Netzwerkmustern finden Sie unter Netzwerkkonnektivität.
- Weisen Sie dem Nutzer, der den Connector konfiguriert, die IAM-Rolle roles/connectors.admin zu.
- Weisen Sie dem Dienstkonto, das Sie für den Connector verwenden möchten, die IAM-Rolle
roles/bigquery.dataEditorzu. Wenn Sie kein Dienstkonto haben, müssen Sie eins erstellen. Der Connector und das Dienstkonto müssen zum selben Projekt gehören. - Aktivieren Sie die folgenden Dienste:
secretmanager.googleapis.com(Secret Manager API)connectors.googleapis.com(Connectors API)
Informationen zum Aktivieren von Diensten finden Sie unter Dienste aktivieren. Wenn diese Dienste oder Berechtigungen für Ihr Projekt zuvor nicht aktiviert wurden, werden Sie aufgefordert, sie beim Konfigurieren des Connectors zu aktivieren.
BigQuery-Verbindung erstellen
Eine Verbindung ist für eine Datenquelle spezifisch. Wenn Sie also viele Datenquellen haben, müssen Sie für jede Datenquelle eine separate Verbindung erstellen. So erstellen Sie eine Verbindung:
- Rufen Sie in der Cloud Console die Seite Integration Connectors > Verbindungen auf und wählen Sie ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Klicken Sie auf + NEU ERSTELLEN, um die Seite Verbindung erstellen zu öffnen.
- Wählen Sie im Bereich Standort einen Standort aus der Liste Region aus und klicken Sie dann auf WEITER.
Eine Liste aller unterstützten Regionen finden Sie unter Standorte.
- Führen Sie im Abschnitt Verbindungsdetails folgende Schritte aus:
- Wählen Sie BigQuery aus der Liste Connector aus.
- Wählen Sie eine Connector-Version aus der Liste Connector-Version aus.
- Geben Sie im Feld Verbindungsname einen Namen für die Verbindungsinstanz ein. Der Verbindungsname darf Kleinbuchstaben, Zahlen oder Bindestriche enthalten. Der Name muss mit einem Buchstaben beginnen und mit einem Buchstaben oder einer Ziffer enden. Er darf nicht länger als 49 Zeichen sein.
- Optional können Sie Cloud Logging aktivieren und dann eine Logebene auswählen. Die Logebene ist standardmäßig auf
Errorfestgelegt. - Dienstkonto: Wählen Sie ein Dienstkonto, das über die erforderlichen Rollen verfügt.
- Optional: Konfigurieren Sie die Verbindungsknoteneinstellungen.
- Mindestanzahl von Knoten: Geben Sie die Mindestanzahl von Verbindungsknoten ein.
- Maximale Anzahl von Knoten: Geben Sie die maximale Anzahl von Verbindungsknoten ein.
- Projekt-ID: Die ID des Google Cloud-Projekts, in dem sich die Daten befinden.
- Dataset-ID:: Die ID des BigQuery-Datasets.
- Wenn Sie den BigQuery-Datentyp „Array“ unterstützen möchten, wählen Sie Native Datentypen unterstützen aus. Die folgenden Arraytypen werden unterstützt: Varchar, Int64, Float64, Long, Double, Bool und Timestamp. Geschachtelte Arrays werden nicht unterstützt.
- Optional: Wenn Sie einen Proxyserver für die Verbindung konfigurieren möchten, wählen Sie Proxy verwenden aus und geben Sie die Proxy-Details ein.
-
Proxy-Authentifizierungsschema: Wählen Sie den Authentifizierungstyp für die Authentifizierung beim Proxyserver aus. Die folgenden Authentifizierungstypen werden unterstützt:
- Standard: Basis-HTTP-Authentifizierung.
- Digest: Digest-HTTP-Authentifizierung.
- Proxy-Nutzer: Ein Nutzername, der für die Authentifizierung beim Proxyserver verwendet werden soll.
- Proxy-Passwort: Das Secret Manager-Secret des Nutzerpassworts.
-
Proxy-SSL-Typ: Der SSL-Typ, der beim Herstellen einer Verbindung zum Proxyserver verwendet werden soll. Die folgenden Authentifizierungstypen werden unterstützt:
- Automatisch: Standardeinstellung. Wenn die URL eine HTTPS-URL ist, wird die Option „Tunnel“ verwendet. Wenn die URL eine HTTP-URL ist, wird die Option „NIE“ verwendet.
- Immer: Die Verbindung ist immer SSL-aktiviert.
- Nie: Die Verbindung ist nicht SSL-fähig.
- Tunnel: Die Verbindung erfolgt über einen Tunneling-Proxy. Der Proxyserver öffnet eine Verbindung zum Remotehost und der Traffic fließt über den Proxy hin und her.
- Geben Sie im Abschnitt Proxyserver die Details des Proxyservers ein.
- Klicken Sie auf + Ziel hinzufügen.
- Wählen Sie einen Zieltyp aus.
- Hostadresse: Geben Sie den Hostnamen oder die IP-Adresse des Ziels an.
Wenn Sie eine private Verbindung zu Ihrem Backend-System herstellen möchten, gehen Sie so vor:
- Erstellen Sie einen PSC-Dienstanhang.
- Erstellen Sie einen Endpunktanhang und geben Sie dann die Details des Endpunktanhangs in das Feld Hostadresse ein.
- Hostadresse: Geben Sie den Hostnamen oder die IP-Adresse des Ziels an.
- Tippen Sie auf Weiter.
Ein Knoten ist eine Einheit (oder ein Replikat) einer Verbindung, die Transaktionen verarbeitet. Zur Verarbeitung von mehr Transaktionen für eine Verbindung sind mehr Knoten erforderlich. Umgekehrt sind weniger Knoten erforderlich, um weniger Transaktionen zu verarbeiten. Informationen zu den Auswirkungen der Knoten auf Ihre Connector-Preise finden Sie unter Preise für Verbindungsknoten. Wenn Sie keine Werte eingeben, ist die Mindestanzahl von Knoten standardmäßig auf 2 (für eine bessere Verfügbarkeit) und die maximale Knotenzahl auf 50 gesetzt.
-
Geben Sie im Abschnitt Authentifizierung die Authentifizierungsdetails ein.
- Wählen Sie aus, ob Sie sich mit OAuth 2.0 – Autorisierungscode authentifizieren möchten oder ohne Authentifizierung fortfahren möchten.
Informationen zum Konfigurieren der Authentifizierung finden Sie unter Authentifizierung konfigurieren.
- Tippen Sie auf Weiter.
- Wählen Sie aus, ob Sie sich mit OAuth 2.0 – Autorisierungscode authentifizieren möchten oder ohne Authentifizierung fortfahren möchten.
- Prüfen Sie Ihre Verbindungs- und Authentifizierungsdetails und klicken Sie dann auf Erstellen.
Authentifizierung konfigurieren
Geben Sie die Details basierend auf der zu verwendenden Authentifizierung ein.
- Keine Authentifizierung: Wählen Sie diese Option aus, wenn keine Authentifizierung erforderlich ist.
- OAuth 2.0 – Autorisierungscode: Wählen Sie diese Option aus, um die Authentifizierung über einen webbasierten Nutzeranmeldevorgang durchzuführen. Geben Sie die folgenden Informationen an:
- Client-ID : Die Client-ID, die für die Verbindung zu Ihrem Backend-Google-Dienst erforderlich ist.
- Bereiche : Eine durch Kommas getrennte Liste der gewünschten Bereiche. Alle unterstützten OAuth 2.0-Bereiche für den erforderlichen Google-Dienst finden Sie im entsprechenden Abschnitt auf der Seite OAuth 2.0-Bereiche für Google APIs.
- Client-Secret: Wählen Sie das Secret Manager-Secret aus. Sie müssen das Secret Manager-Secret erstellt haben, bevor Sie diese Autorisierung konfigurieren.
- Secret-Version: Secret Manager-Secret-Version für den Clientschlüssel.
Für den Authentifizierungstyp Authorization code müssen Sie nach dem Erstellen der Verbindung die Verbindung autorisieren.
Verbindung autorisieren
Wenn Sie OAuth 2.0 – Autorisierungscode verwenden, um die Verbindung zu authentifizieren, führen Sie die folgenden Aufgaben aus, nachdem Sie die Verbindung erstellt haben.
- Suchen Sie auf der Seite „Verbindungen“ nach der neu erstellten Verbindung.
Der Status für den neuen Connector ist Autorisierung erforderlich.
- Klicken Sie auf Autorisierung erforderlich.
Der Bereich Autorisierung bearbeiten wird angezeigt.
- Kopieren Sie den Wert unter Weiterleitungs-URI in Ihre externe Anwendung.
- Überprüfen Sie die Autorisierungsdetails.
- Klicken Sie auf Autorisieren.
Wenn die Autorisierung erfolgreich ist, wird der Verbindungsstatus auf der Seite Verbindungen auf Aktiv gesetzt.
Erneute Autorisierung für Autorisierungscode
Wenn Sie den Authentifizierungstyp Authorization code verwenden und Änderungen an der Konfiguration in BigQuery vorgenommen haben, müssen Sie Ihre BigQuery-Verbindung noch einmal autorisieren. So autorisieren Sie eine Verbindung neu:
- Klicken Sie auf der Seite Verbindungen auf die gewünschte Verbindung.
Dadurch wird die Seite mit den Verbindungsdetails geöffnet.
- Klicken Sie auf Bearbeiten, um die Verbindungsdetails zu bearbeiten.
- Prüfen Sie im Abschnitt Authentifizierung die Details zum OAuth 2.0-Autorisierungscode.
Nehmen Sie bei Bedarf die erforderlichen Änderungen vor.
- Klicken Sie auf Speichern. Sie werden zur Seite mit den Verbindungsdetails weitergeleitet.
- Klicken Sie im Abschnitt Authentifizierung auf Autorisierung bearbeiten. Dadurch wird der Bereich Autorisieren angezeigt.
- Klicken Sie auf Autorisieren.
Wenn die Autorisierung erfolgreich ist, wird der Verbindungsstatus auf der Seite Verbindungen auf Aktiv gesetzt.
BigQuery-Verbindung in einer Integration verwenden
Nachdem Sie die Verbindung erstellt haben, ist sie sowohl in Apigee Integration als auch in Application Integration verfügbar. Sie können die Verbindung in einer Integration über die Aufgabe „Connectors“ verwenden.
- Informationen zum Erstellen und Verwenden der Connectors-Aufgabe in Apigee Integration finden Sie unter Connectors-Aufgabe.
- Informationen zum Erstellen und Verwenden der Connectors-Aufgabe in Application Integration finden Sie unter Connectors-Aufgabe.
Aktionen
In diesem Abschnitt werden die im BigQuery-Connector verfügbaren Aktionen beschrieben.
Die Ergebnisse aller Entitätsvorgänge und -aktionen sind als JSON-Antwort im Antwortparameter connectorOutputPayload der Aufgabe Connectors verfügbar und zwar nach der Ausführung der Integration.
Aktion „CancelJob“
Mit dieser Aktion können Sie einen laufenden BigQuery-Job abbrechen.
In der folgenden Tabelle werden die Eingabeparameter der Aktion CancelJob beschrieben.
| Parametername | Datentyp | Beschreibung |
|---|---|---|
| JobId | String | Die ID des Jobs, den Sie abbrechen möchten. Dies ist ein Pflichtfeld. |
| Region | String | Die Region, in der der Job derzeit ausgeführt wird. Dies ist nicht erforderlich, wenn sich der Job in einer Region in den USA oder der EU befindet. |
GetJob-Aktion
Mit dieser Aktion können Sie die Konfigurationsinformationen und den Ausführungsstatus eines vorhandenen Jobs abrufen.
In der folgenden Tabelle werden die Eingabeparameter der Aktion GetJob beschrieben.
| Parametername | Datentyp | Beschreibung |
|---|---|---|
| JobId | String | Die ID des Jobs, für den Sie die Konfiguration abrufen möchten. Dies ist ein Pflichtfeld. |
| Region | String | Die Region, in der der Job derzeit ausgeführt wird. Dies ist nicht erforderlich, wenn sich der Job in einer Region in den USA oder der EU befindet. |
InsertJob-Aktion
Mit dieser Aktion können Sie einen BigQuery-Job einfügen, der später ausgewählt werden kann, um die Abfrageergebnisse abzurufen.
In der folgenden Tabelle werden die Eingabeparameter der Aktion InsertJob beschrieben.
| Parametername | Datentyp | Beschreibung |
|---|---|---|
| Abfrage | String | Die Abfrage, die an BigQuery gesendet werden soll. Dies ist ein Pflichtfeld. |
| IsDML | String | Sollte auf true gesetzt werden, wenn die Abfrage eine DML-Anweisung ist, andernfalls auf false. Der Standardwert ist false. |
| DestinationTable | String | Die Zieltabelle für die Abfrage im Format DestProjectId:DestDatasetId.DestTable. |
| WriteDisposition | String | Gibt an, wie Daten in die Zieltabelle geschrieben werden sollen, z. B. ob vorhandene Ergebnisse gekürzt, angehängt oder nur geschrieben werden sollen, wenn die Tabelle leer ist. Folgende Werte werden unterstützt:
|
| DryRun | String | Gibt an, ob die Ausführung des Jobs ein Probelauf ist. |
| MaximumBytesBilled | String | Gibt die maximale Anzahl von Byte an, die vom Job verarbeitet werden können. BigQuery bricht den Job ab, wenn versucht wird, mehr Byte als den angegebenen Wert zu verarbeiten. |
| Region | String | Gibt die Region an, in der der Job ausgeführt werden soll. |
Aktion „InsertLoadJob“
Mit dieser Aktion können Sie einen BigQuery-Ladejob einfügen, mit dem Daten aus Google Cloud Storage in eine vorhandene Tabelle eingefügt werden.
In der folgenden Tabelle werden die Eingabeparameter der Aktion InsertLoadJob beschrieben.
| Parametername | Datentyp | Beschreibung |
|---|---|---|
| SourceURIs | String | Eine durch Leerzeichen getrennte Liste von Google Cloud Storage-URIs. |
| SourceFormat | String | Das Quellformat der Dateien. Folgende Werte werden unterstützt:
|
| DestinationTable | String | Die Zieltabelle für die Abfrage im Format DestProjectId.DestDatasetId.DestTable. |
| DestinationTableProperties | String | Ein JSON-Objekt, das den Anzeigenamen, die Beschreibung und die Liste der Labels für die Tabelle angibt. |
| DestinationTableSchema | String | Eine JSON-Liste mit den Feldern, die zum Erstellen der Tabelle verwendet werden. |
| DestinationEncryptionConfiguration | String | Ein JSON-Objekt, das die KMS-Verschlüsselungseinstellungen für die Tabelle angibt. |
| SchemaUpdateOptions | String | Eine JSON-Liste mit den Optionen, die beim Aktualisieren des Schemas der Zieltabelle angewendet werden sollen. |
| TimePartitioning | String | Ein JSON-Objekt, das den Typ und das Feld der Zeitpartitionierung angibt. |
| RangePartitioning | String | Ein JSON-Objekt, das das Feld und die Bereiche für die Bereichspartitionierung angibt. |
| Clustering | String | Ein JSON-Objekt, das die Felder angibt, die für das Clustering verwendet werden sollen. |
| Automatisch erkennen | String | Gibt an, ob Optionen und Schema für JSON- und CSV-Dateien automatisch ermittelt werden sollen. |
| CreateDisposition | String | Gibt an, ob die Zieltabelle erstellt werden muss, wenn sie noch nicht vorhanden ist. Folgende Werte werden unterstützt:
|
| WriteDisposition | String | Gibt an, wie Daten in die Zieltabelle geschrieben werden sollen, z. B. ob vorhandene Ergebnisse gekürzt, angehängt oder nur geschrieben werden sollen, wenn die Tabelle leer ist. Folgende Werte werden unterstützt:
|
| Region | String | Gibt die Region an, in der der Job ausgeführt werden soll. Die Google Cloud Storage-Ressourcen und das BigQuery-Dataset müssen sich in derselben Region befinden. |
| DryRun | String | Gibt an, ob die Ausführung des Jobs ein Probelauf ist. Der Standardwert ist false. |
| MaximumBadRecords | String | Gibt die Anzahl der Datensätze an, die ungültig sein können, bevor der gesamte Job abgebrochen wird. Standardmäßig müssen alle Datensätze gültig sein. Der Standardwert ist 0. |
| IgnoreUnknownValues | String | Gibt an, ob die unbekannten Felder in der Eingabedatei ignoriert oder als Fehler behandelt werden sollen. Standardmäßig werden sie als Fehler behandelt. Der Standardwert ist false. |
| AvroUseLogicalTypes | String | Gibt an, ob logische AVRO-Typen verwendet werden müssen, um AVRO-Daten in BigQuery-Typen zu konvertieren. Der Standardwert ist true. |
| CSVSkipLeadingRows | String | Gibt an, wie viele Zeilen am Anfang von CSV-Dateien übersprungen werden sollen. Diese Option wird normalerweise verwendet, um Kopfzeilen zu überspringen. |
| CSVEncoding | String | Codierungstyp der CSV-Dateien. Folgende Werte werden unterstützt:
|
| CSVNullMarker | String | Falls angegeben, wird dieser String für NULL-Werte in CSV-Dateien verwendet. Standardmäßig kann in CSV-Dateien kein NULL-Wert verwendet werden. |
| CSVFieldDelimiter | String | Das Zeichen, das zum Trennen von Spalten in CSV-Dateien verwendet wird. Der Standardwert ist ein Komma (,). |
| CSVQuote | String | Das Zeichen, das für Felder mit Anführungszeichen in CSV-Dateien verwendet wird. Kann auf leer gesetzt werden, um das Setzen von Anführungszeichen zu deaktivieren. Der Standardwert ist ein doppeltes Anführungszeichen ("). |
| CSVAllowQuotedNewlines | String | Gibt an, ob die CSV-Dateien Zeilenumbrüche in Feldern in Anführungszeichen enthalten dürfen. Der Standardwert ist false. |
| CSVAllowJaggedRows | String | Gibt an, ob die CSV-Dateien fehlende Felder enthalten dürfen. Der Standardwert ist false. |
| DSBackupProjectionFields | String | Eine JSON-Liste der Felder, die aus einer Cloud Datastore-Sicherung geladen werden sollen. |
| ParquetOptions | String | Ein JSON-Objekt, das die Parquet-spezifischen Importoptionen angibt. |
| DecimalTargetTypes | String | Eine JSON-Liste mit der auf numerische Typen angewendeten Prioritätsreihenfolge. |
| HivePartitioningOptions | String | Ein JSON-Objekt, das die Partitionierungsoptionen auf der Quellseite angibt. |
Benutzerdefinierte SQL-Abfrage ausführen
So erstellen Sie eine benutzerdefinierte Abfrage:
- Folgen Sie der detaillierten Anleitung zum Hinzufügen einer Connectors-Aufgabe.
- Wenn Sie die Connector-Aufgabe konfigurieren, wählen Sie unter „Art der auszuführenden Aktion“ die Option Aktionen aus.
- Wählen Sie in der Liste Aktion die Option Benutzerdefinierte Abfrage ausführen aus und klicken Sie dann auf Fertig.
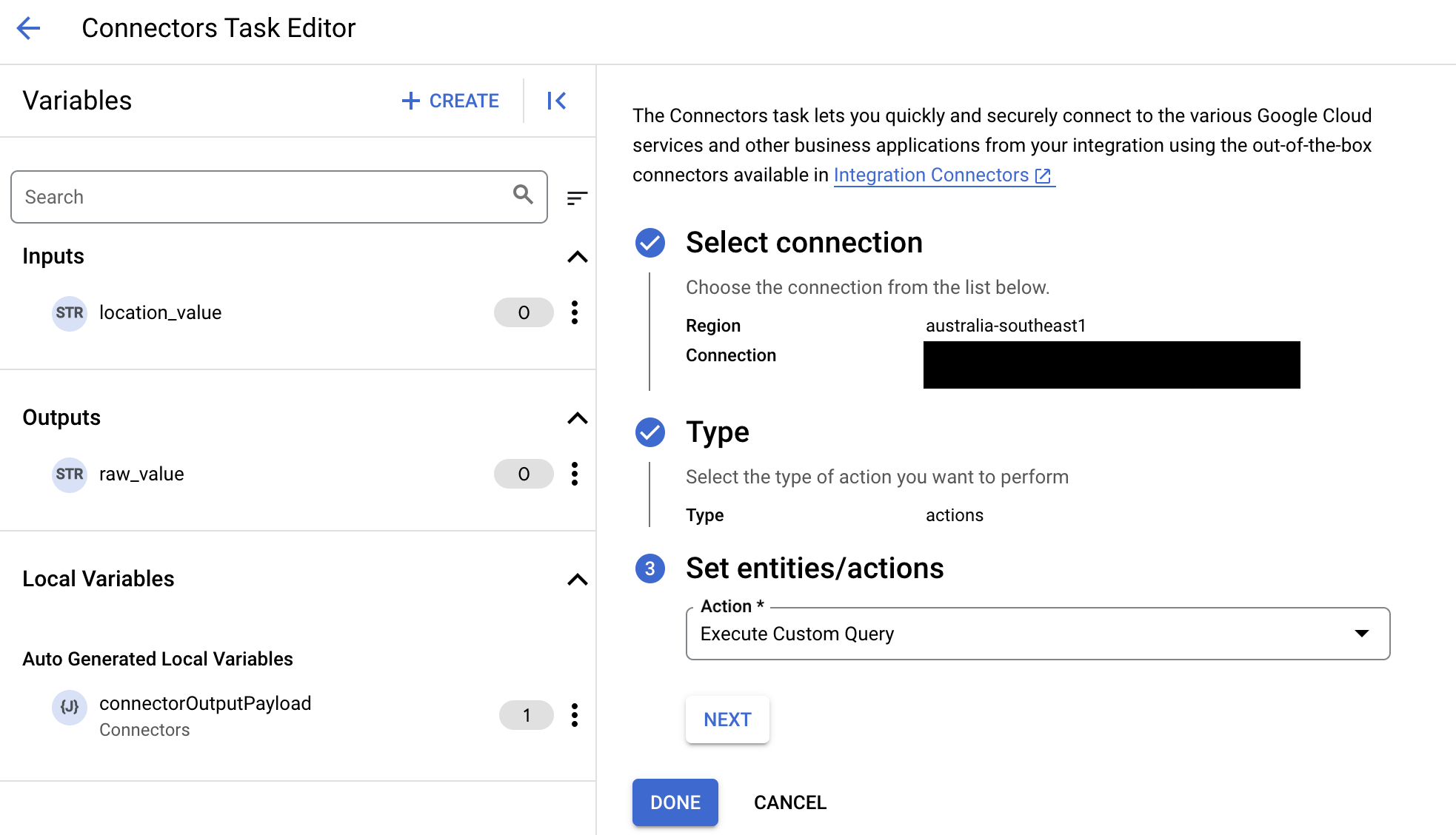
- Maximieren Sie den Abschnitt Aufgabeneingabe und gehen Sie dann so vor:
- Geben Sie im Feld Zeitlimit nach die Anzahl der Sekunden ein, die gewartet werden soll, bis die Abfrage ausgeführt wird.
Standardwert:
180Sekunden. - Geben Sie im Feld Maximale Zeilenanzahl die maximale Anzahl der Zeilen ein, die aus der Datenbank zurückgegeben werden sollen.
Standardwert:
25. - Wenn Sie die benutzerdefinierte Abfrage aktualisieren möchten, klicken Sie auf Benutzerdefiniertes Skript bearbeiten. Das Dialogfeld Skripteditor wird geöffnet.
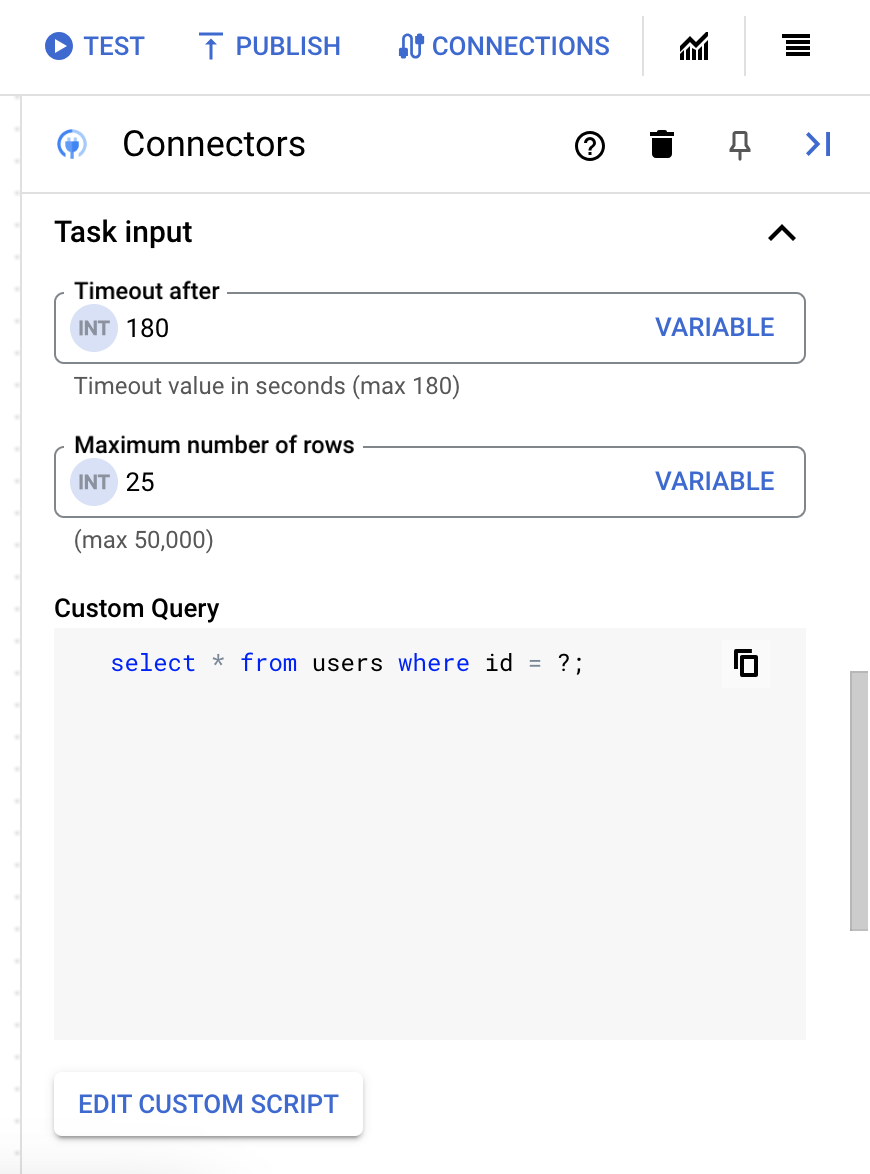
- Geben Sie im Dialogfeld Skripteditor die SQL-Abfrage ein und klicken Sie auf Speichern.
Sie können ein Fragezeichen (?) in einer SQL-Anweisung verwenden, um einen einzelnen Parameter darzustellen, der in der Liste der Abfrageparameter angegeben werden muss. Mit der folgenden SQL-Abfrage werden beispielsweise alle Zeilen aus der Tabelle
Employeesausgewählt, die den für die SpalteLastNameangegebenen Werten entsprechen:SELECT * FROM Employees where LastName=?
- Wenn Sie Fragezeichen in Ihrer SQL-Abfrage verwendet haben, müssen Sie den Parameter hinzufügen, indem Sie für jedes Fragezeichen auf + Parameternamen hinzufügen klicken. Bei der Ausführung der Integration werden diese Parameter sequenziell durch die Fragezeichen (?) in der SQL-Abfrage ersetzt. Wenn Sie beispielsweise drei Fragezeichen (?) hinzugefügt haben, müssen Sie drei Parameter in der richtigen Reihenfolge hinzufügen.
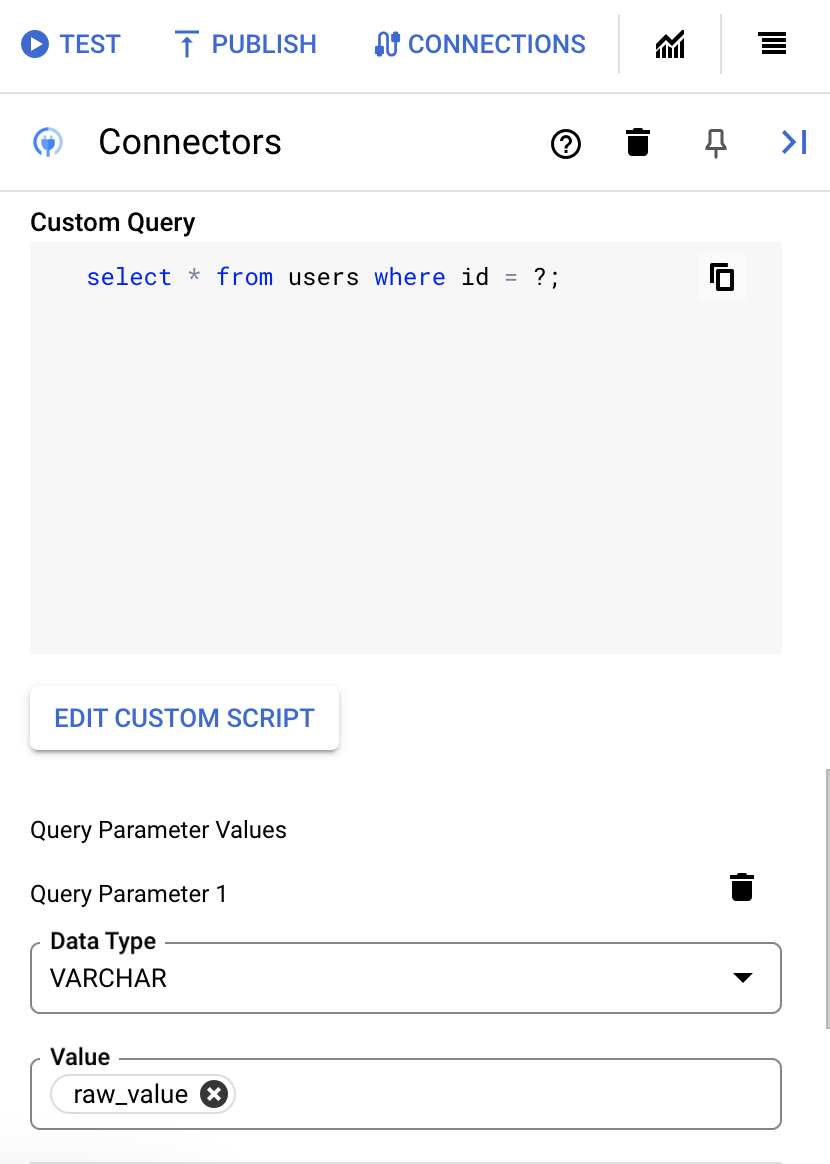
So fügen Sie Abfrageparameter hinzu:
- Wählen Sie in der Liste Typ den Datentyp des Parameters aus.
- Geben Sie im Feld Wert den Wert des Parameters ein.
- Wenn Sie mehrere Parameter hinzufügen möchten, klicken Sie auf + Abfrageparameter hinzufügen.
Die Aktion Benutzerdefinierte Abfrage ausführen unterstützt keine Array-Variablen.
- Geben Sie im Feld Zeitlimit nach die Anzahl der Sekunden ein, die gewartet werden soll, bis die Abfrage ausgeführt wird.
Verbindungen mit Terraform erstellen
Sie können die Terraform-Ressource verwenden, um eine neue Verbindung zu erstellen.
Informationen zum Anwenden oder Entfernen einer Terraform-Konfiguration finden Sie unter Grundlegende Terraform-Befehle.
Ein Beispiel für eine Terraform-Vorlage zum Erstellen einer Verbindung finden Sie hier.
Wenn Sie diese Verbindung mit Terraform erstellen, müssen Sie die folgenden Variablen in Ihrer Terraform-Konfigurationsdatei festlegen:
| Parametername | Datentyp | Erforderlich | Beschreibung |
|---|---|---|---|
| project_id | STRING | Wahr | Die ID des Projekts mit dem BigQuery-Dataset, z. B. „myproject“. |
| dataset_id | STRING | Falsch | Dataset-ID des BigQuery-Datasets ohne den Projektnamen, z. B. „mydataset“. |
| proxy_enabled | BOOLEAN | Falsch | Aktivieren Sie dieses Kästchen, um einen Proxyserver für die Verbindung zu konfigurieren. |
| proxy_auth_scheme | ENUM | Falsch | Der Authentifizierungstyp, der für die Authentifizierung beim ProxyServer-Proxy verwendet werden soll. Unterstützte Werte: BASIC, DIGEST, NONE |
| proxy_user | STRING | Falsch | Ein Nutzername, der für die Authentifizierung beim ProxyServer-Proxy verwendet werden soll. |
| proxy_password | SECRET | Falsch | Ein Passwort, das zur Authentifizierung beim ProxyServer-Proxy verwendet werden soll. |
| proxy_ssltype | ENUM | Falsch | Der SSL-Typ, der beim Herstellen einer Verbindung zum ProxyServer-Proxy verwendet werden soll. Unterstützte Werte: AUTO, ALWAYS, NEVER, TUNNEL |
Systembeschränkungen
Der BigQuery-Connector kann maximal 8 Transaktionen pro Sekunde und Knoten verarbeiten. Alle Transaktionen, die dieses Limit überschreiten, werden gedrosselt. Standardmäßig werden für eine Verbindung zwei Knoten (für eine bessere Verfügbarkeit) zugewiesen.
Informationen zu den für Integration Connectors geltenden Limits finden Sie unter Limits.
Unterstützte Datentypen
Die folgenden Datentypen werden für diesen Connector unterstützt:
- ARRAY
- BIGINT
- BINARY
- BIT
- BOOLEAN
- CHAR
- DATE
- DECIMAL
- DOUBLE
- FLOAT
- INTEGER
- LONGN VARCHAR
- LONG VARCHAR
- NCHAR
- NUMERIC
- NVARCHAR
- REAL
- SMALL INT
- UHRZEIT
- TIMESTAMP
- TINY INT
- VARBINARY
- VARCHAR
Bekannte Einschränkungen
-
Der BigQuery-Connector unterstützt den Primärschlüssel in einer BigQuery-Tabelle nicht. Das bedeutet, dass Sie die Entitätsvorgänge „Abrufen“, „Aktualisieren“ und „Löschen“ nicht mit einem
entityIdausführen können. Alternativ können Sie die Filterklausel verwenden, um Datensätze anhand einer ID zu filtern. -
Wenn Sie Daten zum ersten Mal abrufen, kann es zu einer anfänglichen Latenz von etwa 6 Sekunden kommen. Aufgrund des Caching gibt es bei nachfolgenden Anfragen keine Latenz. Diese Latenz kann nach Ablauf des Cache wieder auftreten.
Hilfe von der Google Cloud-Community erhalten
Sie können Ihre Fragen und Anregungen zu diesem Connector in der Google Cloud-Community unter Cloud-Foren posten.
Nächste Schritte
- Verbindungen anhalten und fortsetzen
- Informationen zum Überwachen der Connector-Nutzung
- Connector-Logs ansehen