Les connecteurs récupèrent les données de sources de données Google et tierces dans Gemini Enterprise, et les stockent dans des datastores dédiés. Ce document présente ces connecteurs. Centraliser vos données dans Gemini Enterprise améliore l'accessibilité, la fonctionnalité de recherche et les capacités d'analyse des données.
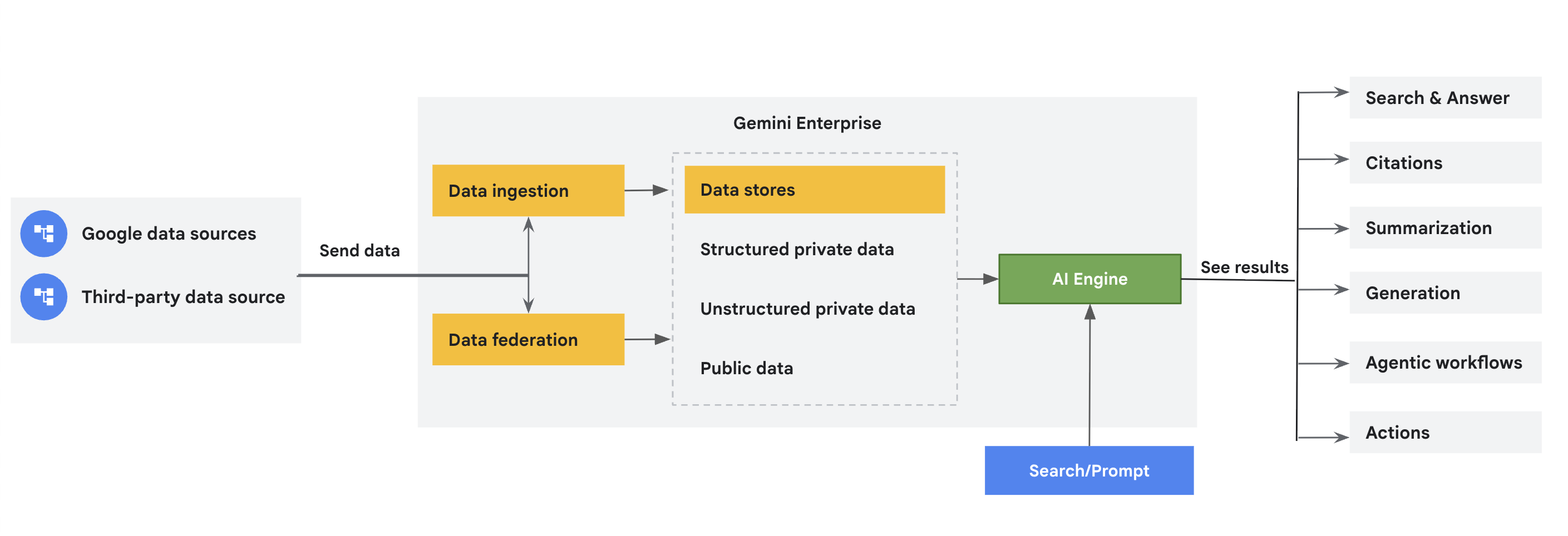
Concepts liés aux connecteurs et data store
Datastores |
| Chaque source de données accepte un ensemble de types d'entités. Par exemple, Jira Cloud comporte des entités telles que les problèmes, les pièces jointes, les commentaires et les journaux de travail, qui sont propres à la source de données. Gemini Enterprise crée un data store distinct pour chaque entité. Par conséquent, lorsque vous créez un data store à l'aide de la console Google Cloud , vous obtenez une collection de datastores représentant ces entités de données ingérées. |
Fédération des données et ingestion (indexation) |
| La fédération de données récupère directement les informations à partir de la source de données spécifiée. Étant donné que les données ne sont pas copiées dans l'index Vertex AI Search, vous n'avez pas à vous soucier du stockage des données. Toutefois, comme les données ne sont pas indexées, la qualité de la recherche peut être inférieure. L'ingestion (indexation) des données copie les données dans l'index Vertex AI Search. Cela peut améliorer la qualité de la recherche. Toutefois, ce processus consomme plus d'espace de stockage et de temps. |
Données non structurées |
| Le format de données accepté dépend de la source de données et du type d'entité. Si le contenu d'une entité est stocké dans un format non structuré (HTML, PDF, TXT, PPTX ou DOCX, par exemple), Vertex AI Search crée un data store non structurées. Pour en savoir plus et connaître les types de fichiers acceptés, consultez Recherche non structurée. |
Données structurées |
| Le format de données accepté dépend de la source de données et du type d'entité. Si le contenu d'une entité est stocké dans un format structuré, Vertex AI Search crée un data store structuré. Pour en savoir plus, consultez Recherche structurée. |
Schémas de données |
| Le schéma de données définit la structure des données. Lorsque vous importez des données structurées à l'aide de Gemini Enterprise, le système détecte automatiquement le schéma. Vous pouvez utiliser le schéma détecté automatiquement ou le définir à l'aide de l'API. Pour en savoir plus, consultez Fournir ou détecter automatiquement un schéma. |
Régions de data stores |
| Lorsque vous ingérez des données, vous devez sélectionner la région dans laquelle vous souhaitez les stocker (par exemple, "Monde", "États-Unis" ou "UE"). Pour en savoir plus, consultez Emplacements Gemini Enterprise. Les données stockées dans les régions des États-Unis ou de l'UE doivent être chiffrées. Le chiffrement par défaut s'effectue avec Google-owned and Google-managed encryption keys, mais vous pouvez également utiliser des clés de chiffrement gérées par le client. |
Synchronisation des données |
Une synchronisation des données extrait et met à jour les données d'identité (comme les rôles, les autorisations et les utilisateurs) et les données d'entité (comme les données liées à une source de données spécifique) à partir de la source de données d'origine. Pour en savoir plus, consultez Types et plannings de synchronisation des données. |
Types et plannings de synchronisation des données
Une synchronisation de données capture les données d'entité, les données d'identité ou les deux, et met à jour le contenu du data store dans Gemini Enterprise.
Types de synchronisation
Les datastores de Gemini Enterprise utilisent deux types essentiels de synchronisation des données :
Une synchronisation complète capture l'intégralité de l'état de l'application ou du service tiers. Cela inclut les ajouts, les modifications et les suppressions. Une synchronisation complète remplace le contenu existant du data store.
Une synchronisation incrémentielle capture périodiquement les données d'entité qui ont été ajoutées ou mises à jour depuis la dernière synchronisation. Elle ne synchronise pas les données d'identité ni les suppressions de données d'entité.
Vous pouvez planifier une synchronisation complète séparément pour les types de données suivants :
Une synchronisation d'entités capture les données spécifiques à la source de données tierce. Par exemple, un data store pour un système tel que Jira peut synchroniser les problèmes, les journaux de travail, les commentaires et les pièces jointes. La synchronisation des entités n'inclut pas les informations d'identité.
Une synchronisation des identités capture les données des comptes utilisateur associés à un groupe de LCA.
Interaction entre la synchronisation des identités et la synchronisation complète
Pour comprendre comment une exécution de synchronisation d'identité individuelle fonctionne avec une exécution de synchronisation complète, prenons l'exemple d'un scénario incluant deux pages : page_1, associée à un groupe de LCA group_1, et page_2, associée à un groupe de LCA group_2.
Une synchronisation initiale des identités s'exécute et récupère des informations sur les groupes
group_1etgroup_2.Supposons que
group_1contienne l'utilisateuruser_1.Supposons que
group_2contienne l'utilisateuruser_2.
Cette synchronisation d'identité établit le mappage suivant :
user_1correspond àgroup_1.user_2correspond àgroup_2.
En parallèle de la synchronisation des identités, une synchronisation complète est exécutée pour récupérer
page_1etpage_2.Cette synchronisation complète établit le mappage suivant :
user_1a accès àpage_1(viagroup_1).user_2a accès àpage_2(viagroup_2).
Synchroniser les programmations
Pour chaque data store, vous pouvez sélectionner une fréquence pour différents types de synchronisation :
Vous pouvez planifier des synchronisations complètes de toutes les données d'identité et d'entité simultanément toutes les trois, six ou douze heures, ou tous les un ou trois jours.
Vous pouvez planifier des synchronisations complètes indépendantes pour toutes les données d'identité et pour toutes les données d'entité séparément, en utilisant l'une des fréquences de synchronisation personnalisées suivantes :
Données sur les entités : toutes les 3 heures, 6 heures, 12 heures, 1 jour, 3 jours, 5 jours et 7 jours.
Données d'identité : toutes les 30 minutes, 1 heure, 3 heures, 6 heures, 12 heures, 1 jour, 3 jours, 5 jours et 7 jours.
Vous pouvez planifier des synchronisations incrémentielles des données d'entité mises à jour ou ajoutées toutes les 3, 6, 12 heures, 1, 3, 5 ou 7 jours. Par défaut, une synchronisation incrémentielle est effectuée toutes les trois heures.
Recommandations de fréquence
Choisissez une fréquence de synchronisation des données qui correspond au volume d'enregistrements récupérés et aux requêtes par seconde (RPS) recommandées.
Le tableau suivant indique le nombre typique d'enregistrements récupérés pour les synchronisations d'un, trois, cinq et sept jours. Le nombre réel d'enregistrements peut varier en fonction de la source de données et de sa configuration.
| RPS | Volume d'enregistrement pour la synchronisation d'un jour | Volume d'enregistrements pour la synchronisation de trois jours | Volume d'enregistrement pour la synchronisation de cinq jours | Volume d'enregistrements pour la synchronisation sur sept jours |
|---|---|---|---|---|
| 5 | 432 000 | 1,296 M | 2,16 M | 3 M |
| 10 | 864 000 | 2,592 M | 4,32 M | 6 M |
| 20 | 1,7 million | 5,1 M | 8,5 M | 11,9 M |
| 50 | 4,3 M | 12,9 M | 21,5 M | 30,1 M |
| 100 | 8,6 M | 25,8 M | 43 M | 60,2 M |
Suspendre et reprendre les synchronisations
Vous pouvez suspendre et reprendre les synchronisations complètes et incrémentielles :
Lorsque vous mettez en veille un type de synchronisation, le data store annule les synchronisations en cours de ce type et arrête de planifier de nouvelles synchronisations de ce type.
Lorsque vous reprenez un type de synchronisation, le data store planifie la nouvelle synchronisation en fonction de la dernière heure de synchronisation planifiée, mais ne poursuit pas la synchronisation précédemment interrompue.
Par exemple, si vous suspendez la synchronisation complète alors qu'elle est en cours, le data store l'annule. Si vous reprenez la synchronisation complète ultérieurement, le data store planifie automatiquement une nouvelle synchronisation complète en fonction de la planification de synchronisation complète.
Sources de données Google
Vous pouvez vous connecter à des sources de données Google, telles que BigQuery, Spanner et Google Drive.
Checklist pour les sources de données Google
Avant d'envoyer des données à Gemini Enterprise, suivez la checklist ci-dessous :
Configurez le contrôle des accès pour votre source de données. Pour en savoir plus, consultez Identité et autorisations.
Déterminez si les données doivent être fédérées ou ingérées (indexées).
Décidez de la fréquence de synchronisation des données.
Si vous utilisez des clés de chiffrement gérées par le client (CMEK), créez des clés multirégionales. Pour en savoir plus, consultez Enregistrer des clés à une seule région pour les sources de données tierces.
Si vous disposez d'informations permettant d'identifier personnellement l'utilisateur et que vous prévoyez d'utiliser la saisie semi-automatique pour les suggestions de requêtes, consultez Protéger contre les fuites d'informations permettant d'identifier personnellement l'utilisateur.
Sources de données Google compatibles
| Google Drive | Gmail | Google Agenda | Recherche de personnes |

|

|

|

|
Sources de données tierces
Les data stores tiers ingèrent les données d'applications tierces dans Gemini Enterprise.
Check-list pour les sources de données tierces
Avant de connecter une source de données tierce à Gemini Enterprise, consultez la checklist suivante :
Des autorisations et des niveaux d'accès spécifiques doivent être configurés pour certaines sources de données. Un administrateur de l'application tierce doit examiner les identifiants requis pour connecter une source de données, et configurer l'authentification et les autorisations. Pour en savoir plus sur les autorisations et les niveaux d'accès spécifiques, consultez la documentation de la source de données tierce concernée.
Configurez le contrôle des accès pour votre data store. Pour en savoir plus, consultez Identité et autorisations.
Déterminez si les données doivent être fédérées ou ingérées (indexées).
Si des données sont ingérées, assurez-vous que les ressources ne sont pas limitées pour les identifiants utilisateur que vous utilisez pour ingérer des données dans la source de données.
Décidez de la fréquence de synchronisation des données.
Si vous utilisez des clés de chiffrement gérées par le client (CMEK), créez des clés multirégionales et monorégionales. Pour en savoir plus, consultez Enregistrer des clés monorégionales pour les magasins de données tiers.
Si vous disposez d'informations permettant d'identifier personnellement l'utilisateur et que vous prévoyez d'utiliser la saisie semi-automatique pour les suggestions de requêtes, consultez Protéger contre les fuites d'informations permettant d'identifier personnellement l'utilisateur.
Sources de données tierces compatibles
| Microsoft Entra ID | Microsoft OneDrive | Microsoft Outlook | Microsoft SharePoint |
|
|
|
|
|
| Jira Cloud | Confluence Cloud | ServiceNow | |
|
|
|
|