Connectors rufen Daten aus Google- und Drittanbieterdatenquellen in Gemini Enterprise ab und speichern sie in dedizierten Datenspeichern. Dieses Dokument bietet einen Überblick über diese Connectors. Wenn Sie Ihre Daten in Gemini Enterprise zentralisieren, verbessern Sie die Datenzugänglichkeit, die Suchfunktionen und die Analysefunktionen.
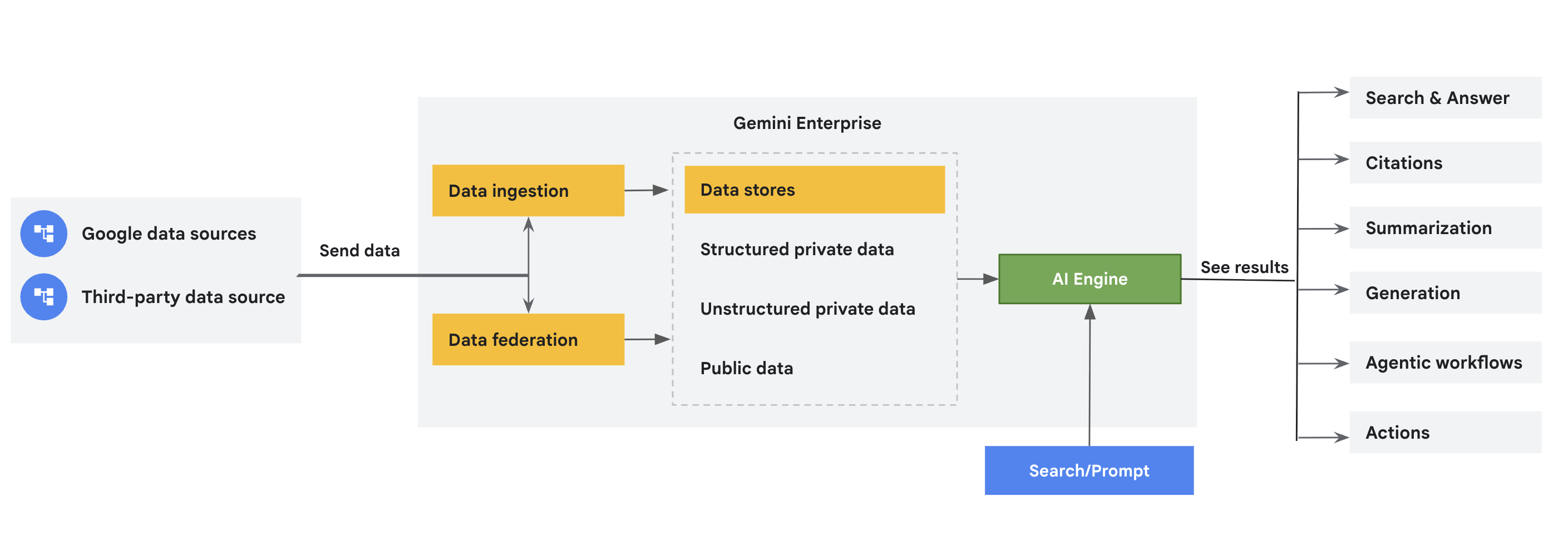
Connector- und Datenspeicherkonzepte
Datenspeicher |
| Jede Datenquelle unterstützt eine Reihe von Entitätstypen. Jira Cloud hat beispielsweise Entitäten wie Probleme, Anhänge, Kommentare und Arbeitsberichte, die für die Datenquelle eindeutig sind. Gemini Enterprise erstellt für jede Einheit einen separaten Datenspeicher. Wenn Sie also einen Datenspeicher über die Google Cloud Console erstellen, erhalten Sie eine Sammlung von Datenspeichern, die diese aufgenommenen Datenentitäten darstellen. |
Datenföderation im Vergleich zur Aufnahme (Indexierung) |
| Bei der Datenföderation werden Informationen direkt aus der angegebenen Datenquelle abgerufen. Da Daten nicht in den Vertex AI Search-Index kopiert werden, müssen Sie sich keine Gedanken über die Datenspeicherung machen. Da die Daten jedoch nicht indexiert werden, kann die Suchqualität geringer sein. Beim Erfassen (Indexieren) von Daten werden Daten in den Vertex AI Search-Index kopiert. Dies kann zu einer besseren Suchqualität führen. Dieser Prozess verbraucht jedoch mehr Speicherplatz und Zeit. |
Unstrukturierte Daten |
| Das unterstützte Datenformat ist spezifisch für die Datenquelle und den Entitätstyp. Wenn der Inhalt einer Entität in einem unstrukturierten Format wie HTML, PDF, TXT, PPTX oder DOCX gespeichert ist, wird von Vertex AI Search ein unstrukturierter Datenspeicher erstellt. Weitere Informationen und unterstützte Dateitypen finden Sie unter Unstrukturierte Suche. |
Strukturierte Daten |
| Das unterstützte Datenformat ist spezifisch für die Datenquelle und den Entitätstyp. Wenn die Inhalte einer Entität in einem strukturierten Format gespeichert sind, wird von Vertex AI Search ein strukturierter Datenspeicher erstellt. Weitere Informationen finden Sie unter Strukturierte Suche. |
Datenschemas |
| Das Datenschema definiert die Datenstruktur. Wenn Sie strukturierte Daten mit Gemini Enterprise importieren, erkennt das System das Schema automatisch. Sie können das automatisch erkannte Schema verwenden oder das Schema über die API definieren. Weitere Informationen finden Sie unter Schema angeben oder automatisch erkennen lassen. |
Regionen für Datenspeicher |
| Beim Erfassen von Daten müssen Sie die Region auswählen, in der Sie die Daten speichern möchten, z. B. global, USA oder EU. Weitere Informationen finden Sie unter Gemini Enterprise-Standorte. Für Daten, die in den USA oder in der EU gespeichert werden, ist eine Datenverschlüsselung erforderlich. Die Standardverschlüsselung erfolgt mit Google-owned and Google-managed encryption key. Alternativ können Sie vom Kunden verwaltete Verschlüsselungsschlüssel verwenden. |
Datensynchronisierung |
Bei einer Datensynchronisierung werden Identitätsdaten (z. B. Rollen, Berechtigungen und Nutzer) und Entitätsdaten (z. B. Daten, die sich auf eine bestimmte Datenquelle beziehen) aus der ursprünglichen Datenquelle abgerufen und aktualisiert. Weitere Informationen finden Sie unter Datensynchronisierungstypen und ‑zeitpläne. |
Arten und Zeitpläne der Datensynchronisierung
Bei einer Datensynchronisierung werden Entitätsdaten, Identitätsdaten oder beides erfasst und der Inhalt des Datenspeichers in Gemini Enterprise aktualisiert.
Synchronisierungstypen
Für Datenspeicher in Gemini Enterprise werden zwei wichtige Arten der Datensynchronisierung verwendet:
Bei einer vollständigen Synchronisierung wird der gesamte Status der Drittanbieter-App oder des Drittanbieterdienstes erfasst. Dazu gehören Hinzufügungen, Aktualisierungen und Löschvorgänge. Bei einer vollständigen Synchronisierung wird der vorhandene Inhalt des Datenspeichers ersetzt.
Bei einer inkrementellen Synchronisierung werden regelmäßig Entitätsdaten erfasst, die seit der letzten Synchronisierung hinzugefügt oder aktualisiert wurden. Identitätsdaten oder Löschungen von Entitätsdaten werden nicht synchronisiert.
Sie können eine vollständige Synchronisierung für die folgenden Datentypen separat planen:
Bei einer Entitätssynchronisierung werden Daten erfasst, die für die Datenquelle des Drittanbieters spezifisch sind. Ein Datenspeicher für ein System wie Jira kann beispielsweise Vorgänge, Arbeitsaufzeichnungen, Kommentare und Anhänge synchronisieren. Bei der Synchronisierung von Einheiten werden keine Identitätsinformationen berücksichtigt.
Bei einer Identitätssynchronisierung werden Daten zu Nutzerkonten erfasst, die mit einer ACL-Gruppe verknüpft sind.
Interaktion zwischen Identitätssynchronisierung und vollständiger Synchronisierung
Um zu verstehen, wie ein einzelner Identitätssynchronisierungslauf mit einem vollständigen Synchronisierungslauf funktioniert, sehen Sie sich ein Beispiel mit zwei Seiten an: page_1, die mit der ACL-Gruppe group_1 verknüpft ist, und page_2, die mit der ACL-Gruppe group_2 verknüpft ist.
Eine erste Identitätssynchronisierung wird ausgeführt und ruft Informationen zu den Gruppen
group_1undgroup_2ab.Angenommen,
group_1enthält den Nutzeruser_1.Angenommen,
group_2enthält den Nutzeruser_2.
Bei dieser Identitätssynchronisierung wird die folgende Zuordnung eingerichtet:
user_1wirdgroup_1zugeordnet.user_2wirdgroup_2zugeordnet.
Neben der Identitätssynchronisierung wird eine vollständige Synchronisierung ausgeführt, bei der sowohl
page_1als auchpage_2abgerufen werden.Bei dieser vollständigen Synchronisierung wird die folgende Zuordnung erstellt:
user_1hat Zugriff aufpage_1(übergroup_1).user_2hat Zugriff aufpage_2(übergroup_2).
Synchronisierungspläne
Für jeden Datenspeicher können Sie eine Häufigkeit für verschiedene Synchronisierungstypen auswählen:
Vollständige Synchronisierungen aller Identitäts- und Entitätsdaten können gleichzeitig alle 3, 6, 12 Stunden, 1 Tag oder 3 Tage geplant werden.
Unabhängige vollständige Synchronisierungen aller Identitätsdaten und unabhängige vollständige Synchronisierungen aller Entitätsdaten können separat mit einer der folgenden benutzerdefinierten Synchronisierungshäufigkeiten geplant werden:
Entitätsdaten: alle 3 Stunden, 6 Stunden, 12 Stunden, 1 Tag, 3 Tage, 5 Tage und 7 Tage.
Identitätsdaten: alle 30 Minuten, 1 Stunde, 3 Stunden, 6 Stunden, 12 Stunden, 1 Tag, 3 Tage, 5 Tage und 7 Tage.
Inkrementelle Synchronisierungen von aktualisierten oder hinzugefügten Entitätsdaten können alle 3, 6, 12 Stunden, 1, 3, 5 oder 7 Tage geplant werden. Standardmäßig wird alle 3 Stunden eine inkrementelle Synchronisierung durchgeführt.
Empfehlungen zur Häufigkeit
Wählen Sie eine Häufigkeit der Datensynchronisierung aus, die dem abgerufenen Datensatzvolumen und den empfohlenen Abfragen pro Sekunde (QPS) entspricht.
In der folgenden Tabelle sehen Sie die typische Anzahl der Datensätze, die für Synchronisierungen von einem, drei, fünf und sieben Tagen abgerufen werden. Die tatsächliche Anzahl der Datensätze kann je nach Datenquelle und ihrer Konfiguration variieren.
| Abfragen pro Sekunde | Aufzeichnungsvolumen für die Synchronisierung an einem Tag | Aufzeichnungsvolumen für die 3‑Tages-Synchronisierung | Aufzeichnungsvolumen für die 5‑Tages-Synchronisierung | Aufnahmevolumen für die 7‑Tage-Synchronisierung |
|---|---|---|---|---|
| 5 | 432.000 | 1,296 Mio. | 2,16 Mio. | 3M |
| 10 | 864.000 | 2,592 Mio. | 4,32 Mio. | 6 Mio. |
| 20 | 1,7 M | 5,1 Mio. | 8,5 Mio. | 11,9 Mio. |
| 50 | 4,3 Mio. | 12,9 Mio. | 21,5 Mio. | 30,1 Mio. |
| 100 | 8,6 Mio. | 25,8 Mio. | 43 Mio. | 60,2 Mio. |
Synchronisierungen pausieren und fortsetzen
Sie können sowohl vollständige als auch inkrementelle Synchronisierungen pausieren und fortsetzen:
Wenn Sie einen Synchronisierungstyp pausieren, werden laufende Synchronisierungen dieses Typs abgebrochen und es werden keine neuen Synchronisierungen dieses Typs mehr geplant.
Wenn Sie einen Synchronisierungstyp fortsetzen, plant der Datenspeicher die neue Synchronisierung basierend auf der letzten geplanten Synchronisierungszeit. Die zuvor unterbrochene Synchronisierung wird jedoch nicht fortgesetzt.
Wenn Sie beispielsweise die vollständige Synchronisierung pausieren, während eine vollständige Synchronisierung ausgeführt wird, wird diese Synchronisierung vom Datenspeicher abgebrochen. Wenn Sie die vollständige Synchronisierung später fortsetzen, wird im Datenspeicher automatisch eine neue vollständige Synchronisierung gemäß dem Zeitplan für die vollständige Synchronisierung geplant.
Datenquellen von Google
Sie können eine Verbindung zu Google-Datenquellen wie BigQuery, Spanner und Google Drive herstellen.
Checkliste für Google-Datenquellen
Bevor Sie Daten an Gemini Enterprise senden, sollten Sie die folgende Checkliste durchgehen:
Zugriffssteuerung für Ihre Datenquelle einrichten Weitere Informationen finden Sie unter Identität und Berechtigungen.
Legen Sie fest, ob Daten föderiert oder aufgenommen (indexiert) werden sollen.
Legen Sie fest, wie oft die Daten synchronisiert werden sollen.
Wenn Sie vom Kunden verwaltete Verschlüsselungsschlüssel (Customer-Managed Encryption Keys, CMEKs) verwenden, erstellen Sie Schlüssel für mehrere Regionen. Weitere Informationen finden Sie unter Schlüssel für einzelne Regionen für Drittanbieter-Datenquellen registrieren.
Wenn Sie personenidentifizierbare Informationen haben und die automatische Vervollständigung für Suchvorschläge verwenden möchten, lesen Sie den Abschnitt Schutz vor PII-Leaks.
Unterstützte Google-Datenquellen
| Google Drive | Gmail | Google Kalender | Personensuche |

|

|

|

|
Datenquellen von Drittparteien
In Datenspeichern von Drittanbietern werden Daten aus Drittanbieteranwendungen in Gemini Enterprise aufgenommen.
Checkliste für Datenquellen von Drittanbietern
Bevor Sie eine Drittanbieterdatenquelle mit Gemini Enterprise verbinden, sollten Sie die folgende Checkliste durchgehen:
Für bestimmte Datenquellen müssen bestimmte Bereiche und Berechtigungen konfiguriert werden. Ein Administrator der Drittanbieteranwendung muss die erforderlichen Anmeldedaten für die Verbindung einer Datenquelle prüfen und die Authentifizierung und Berechtigungen einrichten. Informationen zu den jeweiligen Bereichen und Berechtigungen finden Sie in der Dokumentation der jeweiligen Drittanbieter-Datenquelle.
Zugriffssteuerung für Ihren Datenspeicher einrichten Weitere Informationen finden Sie unter Identität und Berechtigungen.
Legen Sie fest, ob Daten föderiert oder aufgenommen (indexiert) werden sollen.
Wenn Daten aufgenommen werden, prüfen Sie, ob die Ressourcen für die Anmeldedaten des Nutzers, mit denen Sie Daten in die Datenquelle aufnehmen, nicht eingeschränkt sind.
Legen Sie fest, wie oft die Daten synchronisiert werden sollen.
Wenn Sie vom Kunden verwaltete Verschlüsselungsschlüssel (Customer Managed Encryption Keys, CMEK) verwenden, erstellen Sie Schlüssel für mehrere Regionen und einzelne Regionen. Weitere Informationen finden Sie unter Schlüssel für einzelne Regionen für Datenspeicher von Drittanbietern registrieren.
Wenn Sie personenidentifizierbare Informationen haben und die automatische Vervollständigung für Suchvorschläge verwenden möchten, lesen Sie den Abschnitt Schutz vor PII-Leaks.
Unterstützte Datenquellen von Drittanbietern
| Microsoft Entra ID | Microsoft OneDrive | Microsoft Outlook | Hinweise für SharePoint |
|
|
|
|
|
| Jira Cloud | Confluence Cloud | ServiceNow | |
|
|
|
|