借助生成式 AI 训练和提取功能,您可以:
- 使用零样本和少样本技术,通过基础模型获得高性能模型,而无需或只需少量训练数据。
- 随着您提供越来越多的训练数据,可以使用微调功能进一步提高准确性。
生成式 AI 训练方法
您选择的训练方法取决于可用的文档数量以及您愿意投入多少精力来训练模型。您可以通过以下三种方式训练生成式 AI 模型:
| 训练方法 | 零样本 | 少样本 | 微调 |
|---|---|---|---|
| 准确率 | 中 | 中高 | 高 |
| 工作量 | 低 | 低 | 中 |
| 建议的训练文档数量 | 0 | 5 到 10 | 10 至 50+ |
自定义提取器模型版本
以下模型可用于自定义提取器。如需更改模型版本,请参阅管理处理器版本。
1.3、1.4、1.5 和 1.5 Pro 版本支持置信度分数,而 1.2 版本不支持。
| 模型版本 | 说明 | 发布渠道 | 在美国/欧盟境内进行机器学习处理 | 在美国/欧盟境内进行微调 | 发布日期 |
|---|---|---|---|---|---|
pretrained-foundation-model-v1.4-2025-02-05 |
由 Gemini 2.0 Flash LLM 提供支持的正式版模型。还提供高级 OCR 功能,比如复选框检测。 | 稳定版 | 是 | 美国、欧盟 | 2025 年 2 月 5 日 |
pretrained-foundation-model-v1.5-2025-05-05 |
由 Gemini 2.5 Flash LLM 提供支持的正式版候选版本。建议想要试用较新模型的人使用。 | 稳定版 | 是 | 美国及欧盟境内(预览版) | 2025 年 5 月 5 日 |
pretrained-foundation-model-v1.5-pro-2025-06-20 |
由 Gemini 2.5 Pro LLM 提供支持的正式版模型。支持每分钟最多 30 页的在线处理请求配额。与 v1.5 相比,此模型的质量有所提升,但延迟时间可能会更长。 | 稳定版 | 是 | 否 | 2025 年 6 月 20 日 |
如需更改项目中的处理器版本,请参阅管理处理器版本。
如需为默认处理器配额提交配额增加申请 (QIR),请按照管理配额中的步骤操作。
初始设置
如果尚未启用,请启用结算功能和 Document AI API。
构建和评估生成式 AI 模型
创建处理器并按照最佳实践定义要提取的字段,这一点非常重要,因为这会影响提取质量。
- 依次前往工作台 > 自定义提取器 > 创建处理器 > 分配名称。

- 依次前往开始 > 创建新字段。

导入文档
训练模型:
- 依次选择构建和创建新版本。
- 输入名称,然后选择创建。

评估:
- 前往评估和测试,选择您刚刚训练的版本,然后选择查看完整评估结果。

- 现在,您会看到整个文档和每个字段的指标,例如 F1 得分、精确率和召回率。
- 确定效果是否达到生产目标。如果未达到,请重新评估训练集和测试集。
将新版本设置为默认版本:
- 前往管理版本。
- 选择以展开选项,然后选择设为默认。

您的模型现已部署。发送到此处理器的文档将使用您的自定义版本。 您可以评估模型性能,以检查模型是否需要进一步训练。
评估参考
评估引擎可以执行完全匹配或模糊匹配。对于精确匹配,提取的值必须与标准答案完全一致,否则会被视为未命中。
即使模糊匹配提取结果存在细微差异(例如大小写差异),仍视为匹配。可以在评估界面中更改此设置。

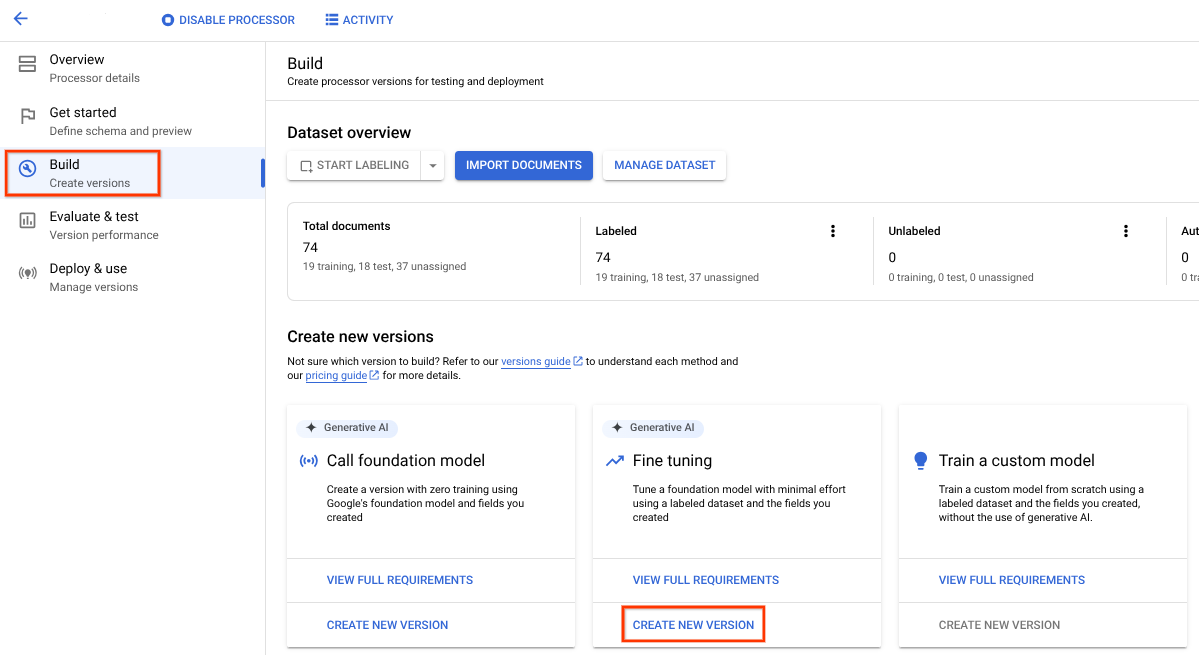
微调
通过微调,您可以使用数百或数千个文档进行训练。
创建处理器并按照最佳实践定义要提取的字段,这一点非常重要,因为这会影响提取质量。
使用自动添加标签功能导入文档,并将文档分配给训练集和测试集。
确认或修改文档中的标签。
训练模型。
- 选择构建标签页,然后在微调框中选择创建新版本。
尝试使用提供的默认训练参数或值。 如果结果不尽如人意,请尝试以下高级选项:
训练步数(介于 100 和 400 之间):控制在调优期间,针对一批数据优化权重的频率。
- 过低表示训练可能在收敛之前结束(欠拟合)。
- 如果值过高,模型在训练期间可能会多次看到同一批数据,从而导致过拟合。
- 步数越少,训练时间越短。如果文档的模板变化较小,则可以采用较高的数量;如果变化较大,则可以采用较低的数量。
学习速率乘数(介于 0.1 和 10 之间):控制模型参数在训练数据上的优化速度。它大致对应于每个训练步的大小。
- 较低的学习速率意味着模型权重在每个训练步骤中变化较小。如果过低,模型可能无法收敛到稳定解。
- 较高的比率表示变化较大,但如果过高,则可能意味着模型跳过了最佳解决方案,反而收敛到次优解决方案。
- 训练时间不受学习率选择的影响。
为处理器版本命名,选择所需的基础处理器版本,然后选择创建。

评估:前往评估和测试,然后选择您刚刚训练的版本,再选择查看完整评估。
- 现在,您可以看到整个文档和每个字段的指标,例如 F1 得分、精确率和召回率。
- 确定性能是否符合您的生产目标。如果不符合,则可能需要进一步的训练文档。
将新版本设为默认版本:
- 前往管理版本。
- 选择以展开选项,然后选择设为默认。
您的模型现已部署,发送到此处理器的文档现在会使用您的自定义版本。 您想评估模型性能,以检查模型是否需要进一步训练。
使用基础模型自动添加标签
基础模型可以准确提取各种文档类型的字段,不过您也可以提供额外的训练数据,提高模型针对特定文档结构的准确率。
Document AI 使用您定义的标签名称和之前的注解,通过自动添加标签功能更加轻松快捷地为文档大规模添加标签。
- 创建自定义处理器后,前往开始使用标签页。
- 选择创建新字段。
为标签提供一个具有描述性且独一无二的名称。选择提取表示值直接来自文档,选择推导表示值由系统推理得出。 这有助于提高基础模型的准确率和性能。

为了提高提取准确性和性能,请为模型应提取的实体类型添加说明(例如为每个实体添加背景信息、数据洞见和先验知识)。

前往构建标签页,然后选择导入文档。

选择文档的路径以及要将文档导入到的数据集。 选中自动加标签选项,然后选择基础模型。
在构建标签页中,选择管理数据集。
看到导入的文档后,选择其中一个。

模型给出的预测结果现在以紫色突出显示。
- 查看模型预测的每个标签,并验证其是否正确。
如果缺少某些字段,请一并添加。

审核完文档后,选择标记为已加标签。现在,该文档已可供模型使用。
确保文档位于测试集或训练集中。
三级嵌套
自定义提取器现在提供三个嵌套级别。此功能可更好地提取复杂表格。
您可以使用以下 API 调用来确定模型类型:
这些方法的响应是一个 ProcessorVersion,其中包含 v1beta3 预览版中的 modelType 字段。
流程和示例
我们使用的是以下示例:

选择开始,然后创建字段:
- 创建顶层。
- 在此示例中,使用了
officer_appointments。 - 选择这是父级标签。
- 选择出现次数:
Optional multiple。



选择添加子字段。现在可以创建第二级标签:
- 为此级别标签创建
officer。 - 选择这是父级标签。
- 选择出现次数:
Optional multiple。


- 为此级别标签创建
从第二级
officer中选择添加子字段。为嵌套的第三级创建子级标签。
设置架构后,您可以使用自动加标签功能,从具有三个嵌套级别的文档中获取预测结果。


为跨网页嵌套实体添加标签
pretrained-foundation-model-v1.5-2025-05-05 处理器支持跨网页的三级嵌套。
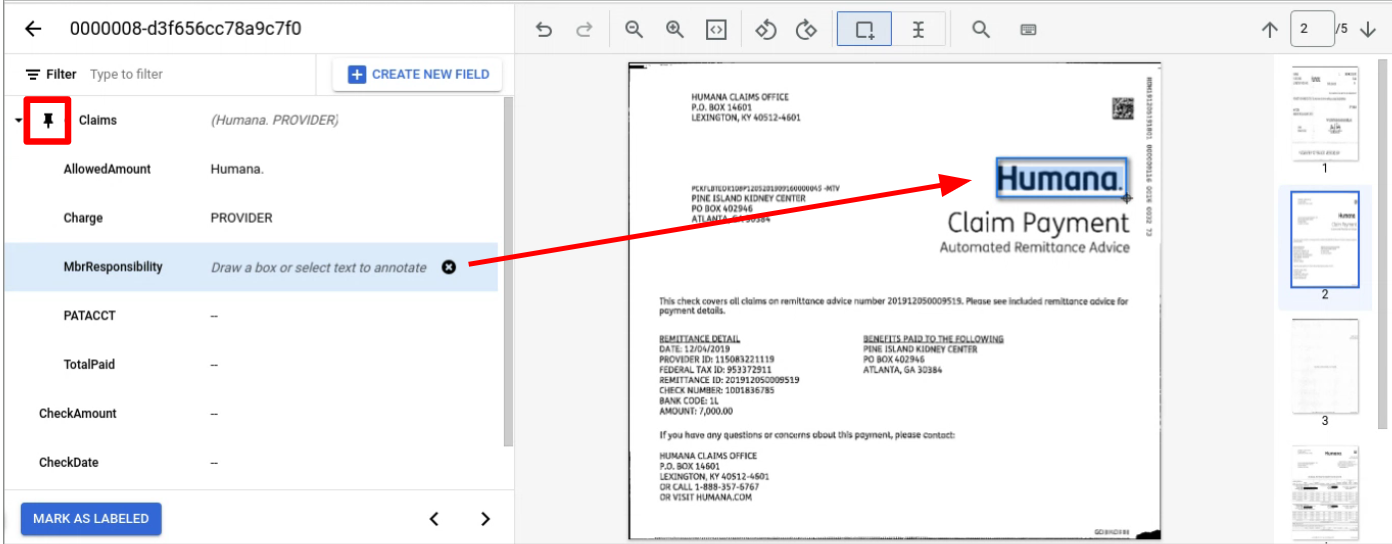
在整个页面上正常标记实体。 注意:带标签的实体仅在添加标签的网页上显示,导航栏会随网页而变化。通过固定父实体,此导航栏会一直显示。
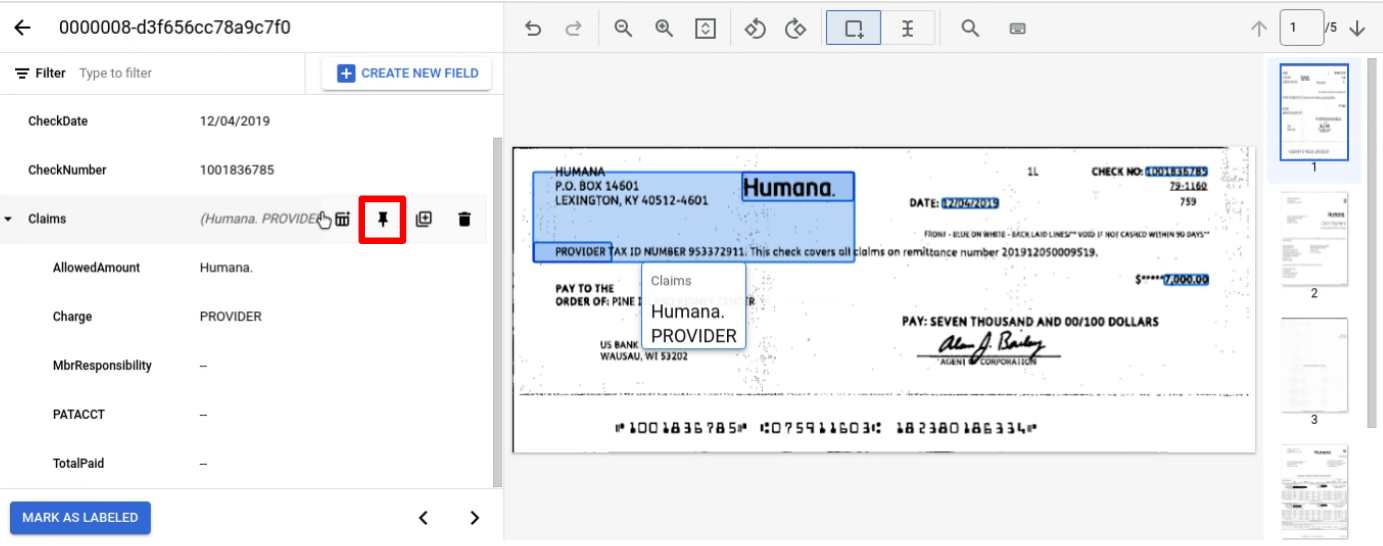
固定包含您要跨网页添加标签的子实体的父实体。
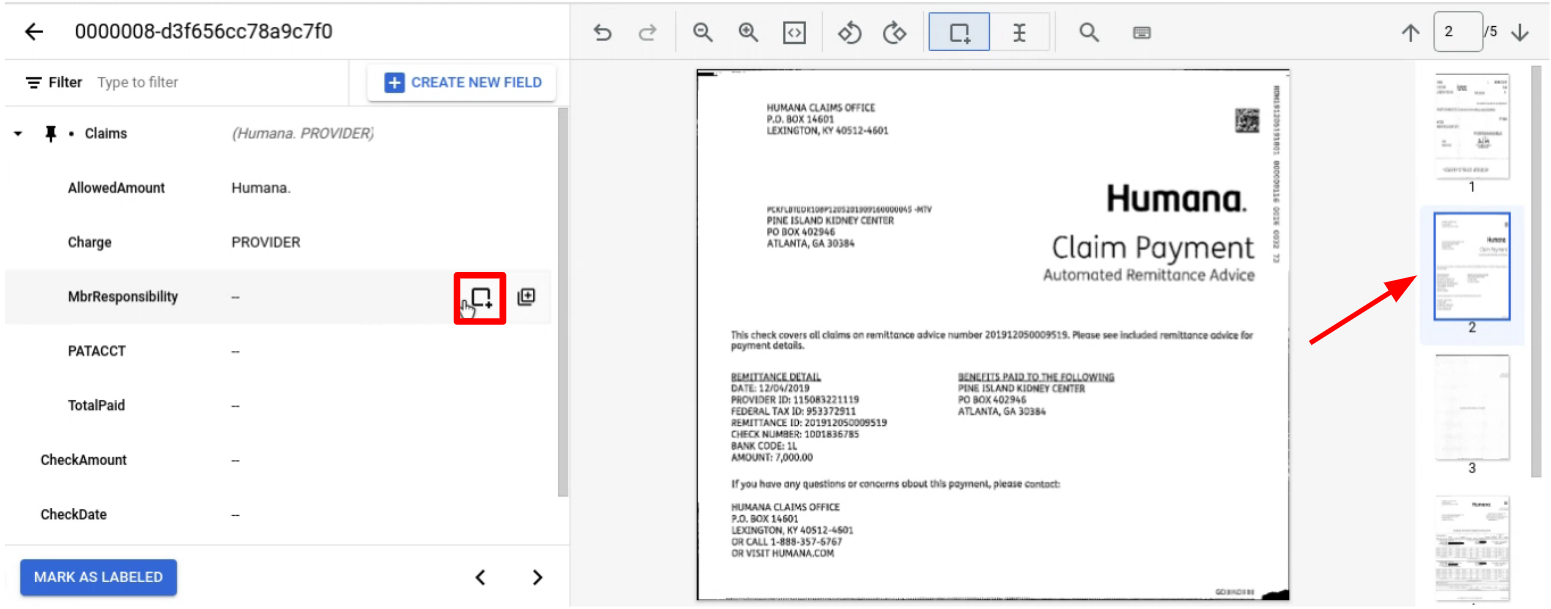
前往包含要添加标签的子实体的页面。
数据集配置
必须使用文档数据集才能训练、追加训练或评估处理器版本。 Document AI 处理器可以像人类一样从示例中学习。数据集可提升处理器在性能方面的稳定性。训练数据集
为了改进模型并提高其准确性,请使用您的文档训练数据集。模型由包含标准答案的文档组成。- 对于微调,您至少需要 1 个文档来训练新模型(版本为
pretrained-foundation-model-v1.2-2024-05-10和pretrained-foundation-model-v1.3-2024-08-31)。 - 对于少样本学习,建议提供 5 个文档。
- 对于零样本学习,只需要架构。
测试数据集
测试数据集是模型用于生成 F1 得分(准确率)的数据集。它由包含标准答案的文档组成。为了了解模型的正确率,系统会使用评估依据将模型的预测结果(从模型中提取的字段)与正确答案进行比较。测试数据集应至少包含一个pretrained-foundation-model-v1.2-2024-05-10 和 pretrained-foundation-model-v1.3-2024-08-31 文档。
具有属性说明的自定义提取器
借助属性说明,您可以通过描述带标签字段的特征来训练模型。您可以为每个实体提供更多背景信息和数据洞见。这样一来,模型就可以通过匹配符合您提供的说明的字段进行训练,从而提高提取准确率。您可以为父实体和子实体指定房源描述。
属性说明的理想示例包括位置信息和属性值的文本模式,这些信息有助于消除文档中可能存在的混淆来源。清晰准确的属性描述可为模型提供规则,从而促进更可靠、更一致的提取,无论具体文档结构或内容如何变化。
更新处理器的文档架构
如需了解如何设置属性说明,请参阅更新文档架构。
发送包含媒体资源说明的处理请求
如果文档架构已设置说明,您可以按照发送处理请求中的说明发送处理请求。
使用属性说明微调处理器
在使用任何请求数据之前,请先进行以下替换:
- LOCATION:处理器的位置,例如:
us- 美国eu- 欧盟
- PROJECT_ID:您的 Google Cloud 项目 ID。
- PROCESSOR_ID:自定义处理器的 ID。
- DISPLAY_NAME:处理器的显示名称。
- PRETRAINED_PROCESSOR_VERSION:处理器版本标识符。如需了解详情,请参阅选择处理器版本。例如:
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- TRAIN_STEPS:模型微调的训练步数。
- LEARN_RATE_MULTIPLIER:用于模型微调的学习速率调节系数。
- DOCUMENT_SCHEMA:处理器的架构。请参阅 DocumentSchema 表示法。
HTTP 方法和网址:
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process
请求 JSON 正文:
{
"rawDocument": {
"parent": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID",
"processor_version": {
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/DISPLAY_NAME",
"display_name": "DISPLAY_NAME",
"model_type": "MODEL_TYPE_GENERATIVE",
},
"base_processor_version": "projects/PROJECT_ID/locations/us/processors/PROCESSOR_ID/processorVersions/PRETRAINED_PROCESSOR_VERSION",
"foundation_model_tuning_options": {
"train_steps": TRAIN_STEPS,
"learning_rate_multiplier": LEARN_RATE_MULTIPLIER,
}
"document_schema": DOCUMENT_SCHEMA
}
}
如需发送请求,请选择以下方式之一:
curl
将请求正文保存在名为 request.json 的文件中,然后执行以下命令:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process"
PowerShell
将请求正文保存在名为 request.json 的文件中,然后执行以下命令:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process" | Select-Object -Expand Content
具有签名检测功能的自定义提取器
(公开预览版)自定义提取器支持签名检测。借助此功能,您可以检测文档中是否存在签名。签名检测仅在使用 derived 方法类型时可用。您可以为这类实体指定实体类型为 signature 的架构。签名实体是根据文档中的视觉提示推导出来的。
如需查看示例和配置说明,请点击具有派生字段和签名检测功能的自定义提取器。
具有派生字段的自定义提取器
自定义提取器支持派生字段。它允许您配置通过基于文档上下文的智能推理或生成(而非直接文本提取)来填充的字段。您可以将此功能用于各种使用情形,例如从地址推断国家/地区、总结文档、统计表格中的项目数,或检测 ID 是否真实,而无需在文本中明确提供相应值。
如需查看示例和配置说明,请点击具有派生字段和签名检测功能的自定义提取器。