对于固定布局应用场景,您只需提供 3 份训练文档和 3 份测试文档,即可训练出高性能模型。加快开发速度,缩短 W9、1040、ACORD、调查问卷和调查表等模板化文档类型的生产时间。
数据集配置
必须使用文档数据集才能训练、追加训练或评估处理器版本。 Document AI 处理器可以像人类一样从示例中学习。数据集可提升处理器在性能方面的稳定性。训练数据集
为了改进模型并提高其准确性,请使用您的文档训练数据集。模型由具有标准答案的文档组成。您至少需要三个文档才能训练新模型。测试数据集
测试数据集是模型用于生成 F1 得分(准确率)的数据集。它由包含标准答案的文档组成。为了了解模型的正确率,系统会使用评估依据将模型的预测结果(从模型中提取的字段)与正确答案进行比较。测试数据集应至少包含 3 个文档。准备工作
如果尚未启用,请启用:
模板模式标签的最佳实践
正确的标记是实现高准确度的最重要步骤之一。模板模式采用了一些独特的标记方法,与其他训练模式不同:
- 在文档中,围绕您预计数据会位于的整个区域(每个标签)绘制边界框,即使您要标记的训练文档中的标签为空也是如此。
- 您可以为基于模板的训练标记空白字段。对于基于模型的训练,请勿标记空字段。
以模板模式构建和评估自定义提取器
设置数据集位置。选择默认选项文件夹(Google 管理)。这可能在创建处理器后不久自动完成。
前往构建标签页,然后选择导入文档(自动添加标签功能已启用)。对于基于模板的训练,添加的文档数量通常不会超过所需的最低数量(即 3 个),否则不会提高质量。与其添加更多数据,不如专注于非常准确地标记少量数据。
扩展边界框。模板模式下的这些框应如前面的示例所示。扩展边界框,遵循最佳实践以获得最佳效果。
训练模型。
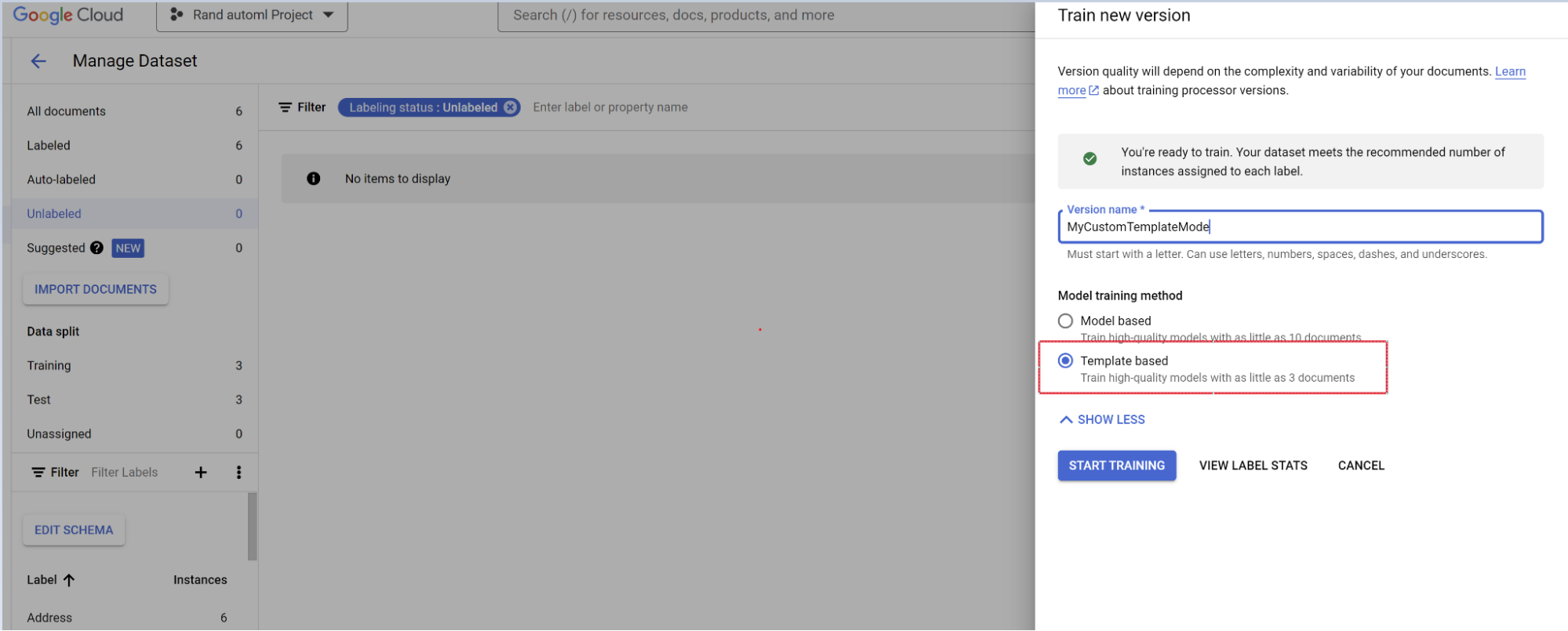
- 选择训练新版本。
- 为处理器版本命名。
- 前往显示高级选项,然后选择基于模板的模型方法。
评估。
- 前往评估和测试。
- 选择刚刚训练的版本,然后选择查看完整评估结果。
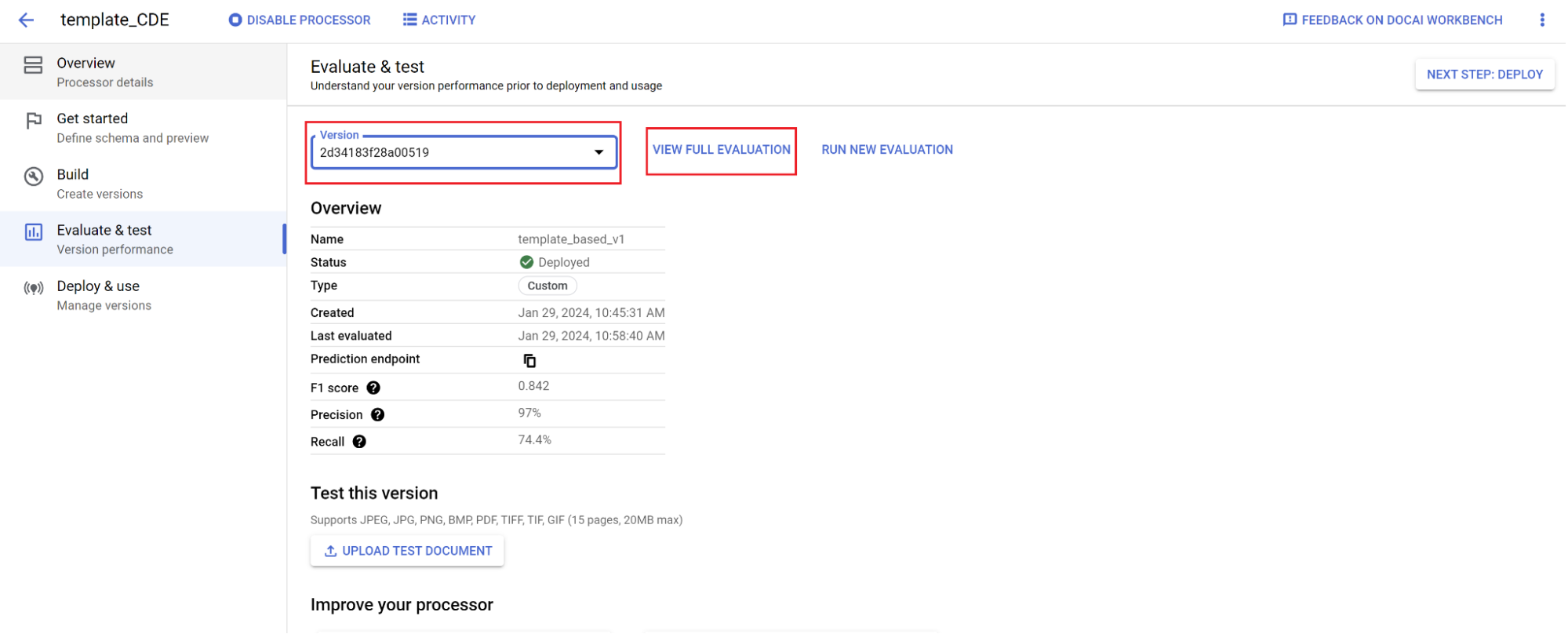
现在,您可以看到整个文档和每个字段的指标,例如 F1 得分、精确率和召回率。 1. 确定效果是否达到生产目标,如果未达到,请重新评估训练集和测试集。
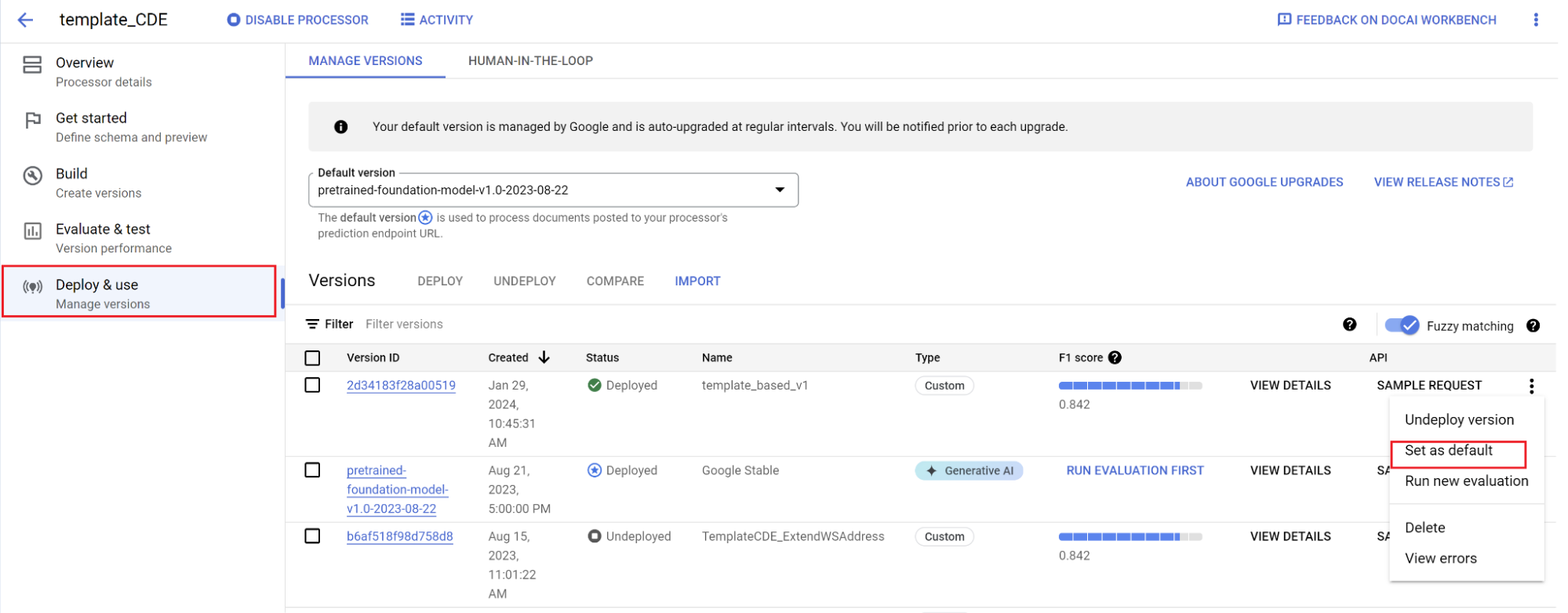
将新版本设为默认版本。
- 前往管理版本。
- 选择以查看“设置”菜单,然后勾选设为默认。
您的模型现已部署,发送给此处理器的文档将使用您的自定义版本。您希望评估模型的性能(更多关于如何执行此操作的详情),以检查模型是否需要进一步训练。
评估参考
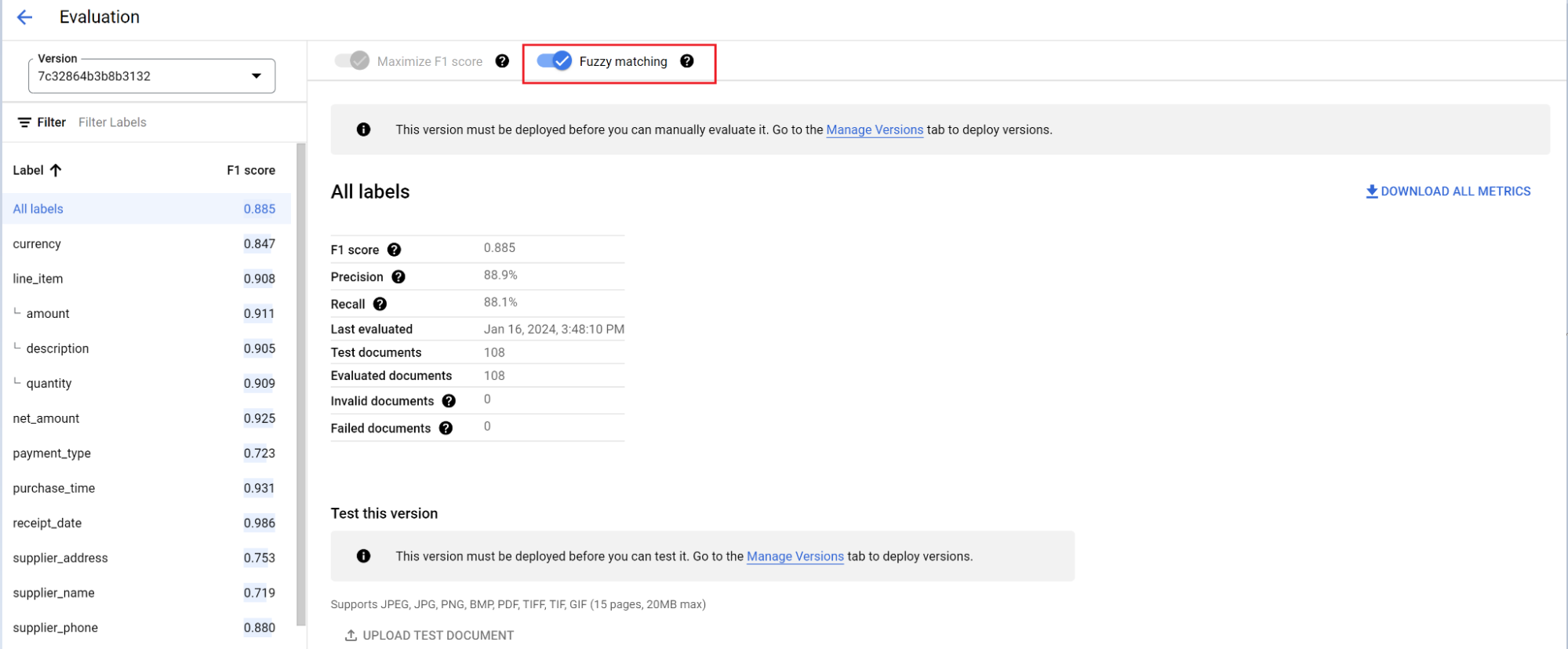
评估引擎可以执行完全匹配或模糊匹配。对于精确匹配,提取的值必须与标准答案完全一致,否则会被视为未命中。
即使模糊匹配提取结果存在细微差异(例如大小写差异),仍视为匹配。可以在评估界面中更改此设置。
使用基础模型自动添加标签
基础模型可以准确提取各种文档类型的字段,不过您也可以提供额外的训练数据,以提高模型针对特定文档结构的准确率。
Document AI 使用您定义的标签名称和之前的注解,通过自动添加标签功能可以更加轻松快捷地为文档大规模添加标签。
- 创建自定义处理器后,前往开始使用标签页。
选择创建新字段。
前往构建标签页,然后选择导入文档。
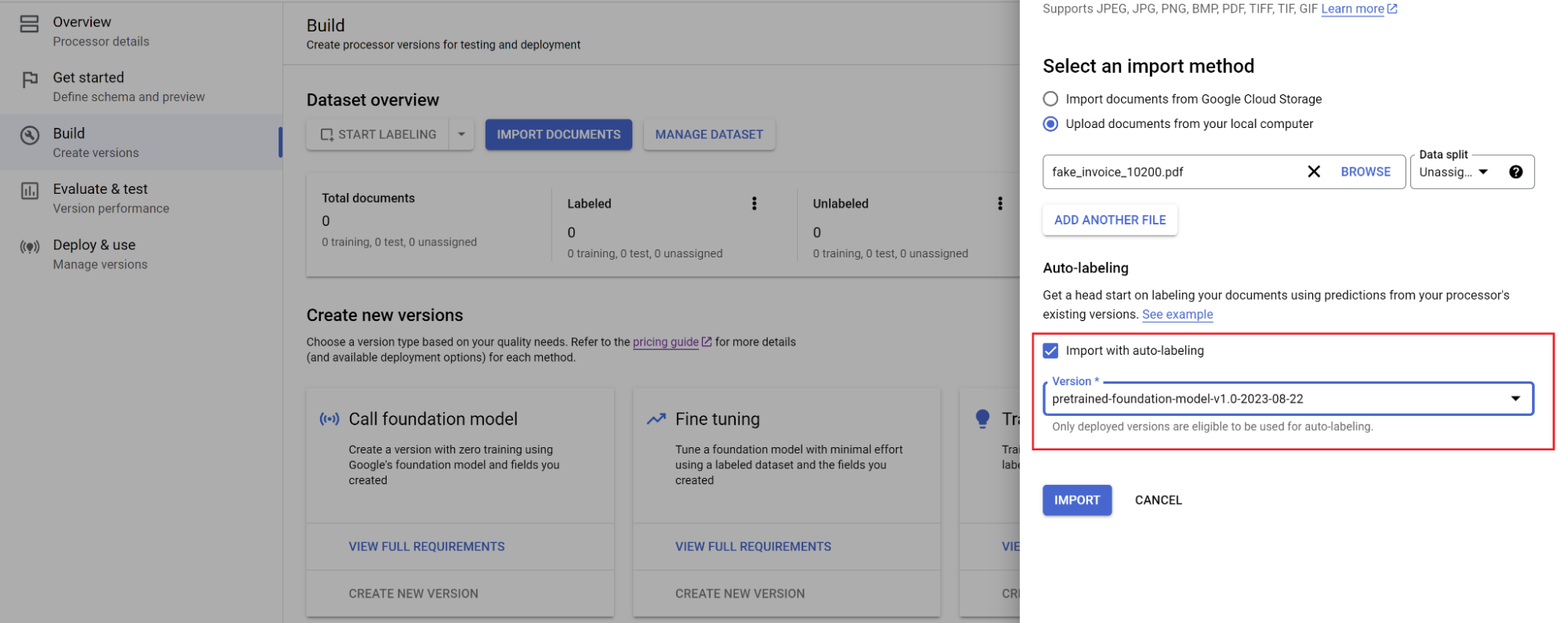
选择文档的路径以及要将文档导入到的集合。选中“自动加标签”复选框,然后选择基础模型。
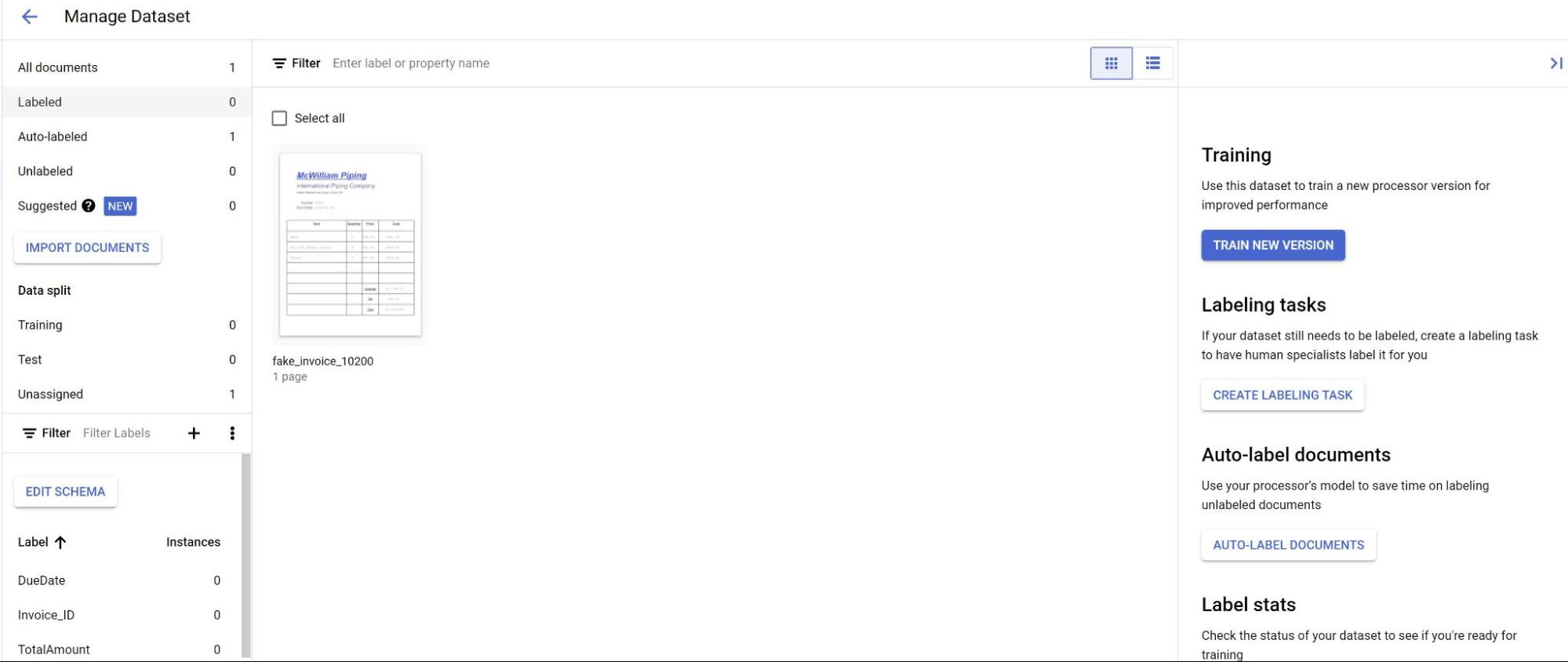
在构建标签页中,选择管理数据集。您应该会看到导入的文档。选择您的某个证件。
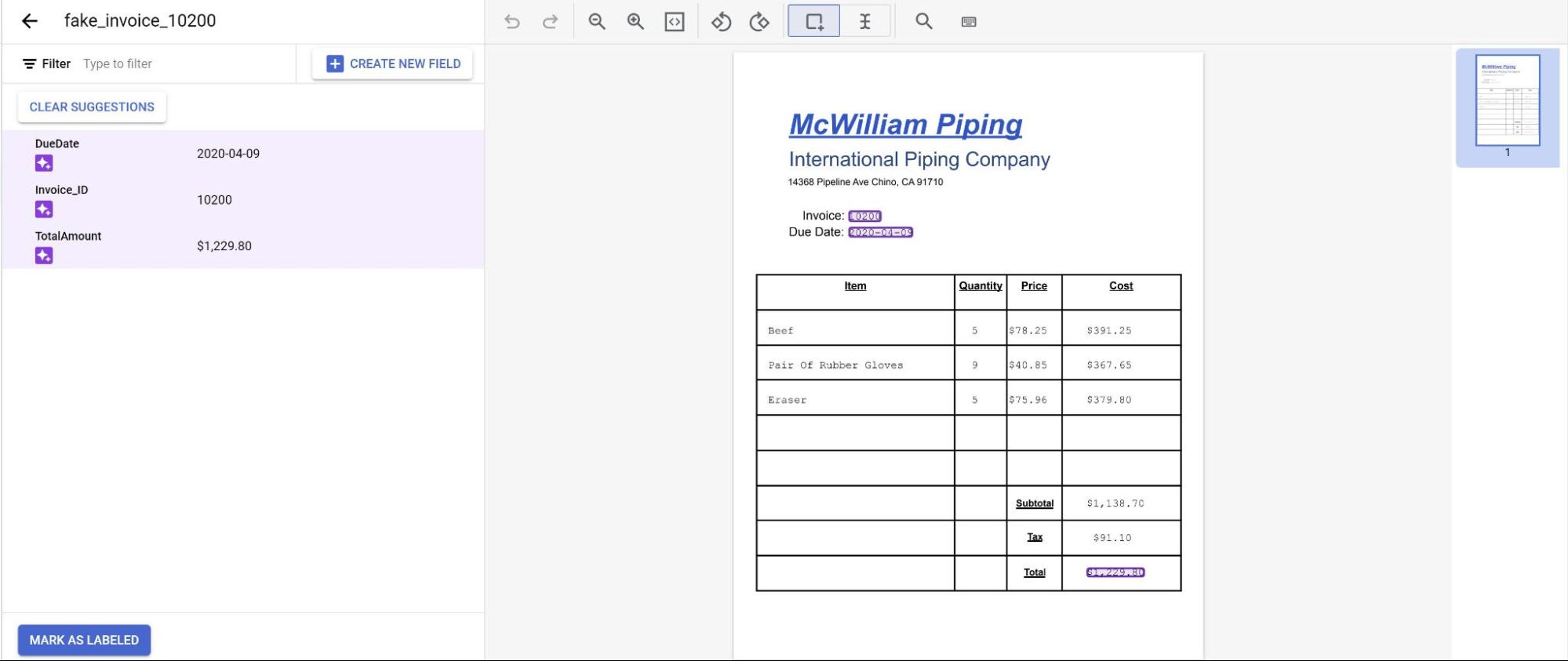
您会看到模型做出的预测以紫色突出显示,您需要检查模型预测的每个标签,确保其正确无误。如果缺少字段,您还需要添加这些字段。
审核完文档后,选择标记为已加标签。
该文档现在可供模型使用。确保相应文档位于测试集或训练集中。