Créer, utiliser et gérer un classificateur de documents personnalisé
Le classificateur personnalisé est conçu pour classer des documents. Créez-le de A à Z avec vos propres documents et classes personnalisées. L'IA générative intégrée permet d'utiliser l'apprentissage few-shot et l'affinage. Cela améliore la justesse avec moins d'échantillons et les corrections avec l'étiquetage automatique itératif.
Le classificateur personnalisé couvre ces trois cas d'utilisation généraux.
- Modèle pré-entraîné : utilisez le modèle de fondation d'IA générative pré-entraîné pour classer rapidement les documents avec les étiquettes que vous avez fournies.
- Affiner : améliorez la précision en entraînant le modèle de fondation d'IA générative sur vos propres données et étiquettes.
- Entraîner un modèle personnalisé : entraînez un extracteur personnalisé d'IA non générative à l'aide de vos propres données et étiquettes.
Versions des modèles du classificateur personnalisé
| Version de modèle | Description | Version disponible | Traitement ML aux États-Unis et dans l'UE | Affinage aux États-Unis et dans l'UE | Date de sortie |
|---|---|---|---|---|---|
pretrained-foundation-model-v1.4-2025-05-16 |
Version candidate optimisée par le LLM Gemini 2.0 Flash. Inclut également des fonctionnalités OCR avancées. | Version candidate | Oui | États-Unis, UE (preview) | 16 mai 2025 |
pretrained-classifier-v1.5-2025-08-05 |
Version candidate optimisée par le LLM Gemini 2.5 Flash. Inclut également des fonctionnalités OCR avancées. | Version candidate | Oui | États-Unis, UE (preview) | 5 août 2025 |
Les scores de confiance ne sont pas compatibles avec les modèles de classification personnalisés.
Créer un classificateur personnalisé dans la console Google Cloud
Vous pouvez créer des classificateurs personnalisés spécifiquement adaptés à vos documents, et entraînés et évalués à l'aide de vos données. Cet outil de traitement identifie les classes de documents d'un ensemble de classes défini par l'utilisateur. Vous pouvez ensuite utiliser cet outil de traitement entraîné dans d'autres documents. Vous utiliserez généralement un classificateur personnalisé pour les documents de différents types, puis l'identification pour transmettre les documents à un outil d'extraction afin d'extraire les entités.
Pour connaître le processus général de création et d'utilisation d'un outil de traitement, consultez la section Instructions.
Vous pouvez définir vos propres configurations en fonction de votre workflow.
Pour obtenir des instructions détaillées sur cette tâche directement dans la console Google Cloud , cliquez sur Visite guidée :
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Accédez à Workbench.
Dans le champ "Classificateur de documents personnalisé", sélectionnez
Créer un outil de traitement .
Dans le menu Créer un outil de traitement, saisissez le nom de votre outil de traitement (par exemple,
my-custom-document-classifier).
Sélectionnez la région la plus proche de vous.
Sélectionnez Créer. L'onglet Détails de l'outil de traitement s'affiche.
- Sélectionner Stockage géré par Google si vous souhaitez utiliser Cloud Storage.
- Sélectionner Je spécifierai mon propre emplacement de stockage si vous souhaitez utiliser votre propre espace de stockage afin d'utiliser des clés de chiffrement gérées par le client (CMEK) et suivre la procédure décrite dans Créer un ensemble de données.
Dans l'onglet Compiler, sélectionnez
Importer des documents .
Si vous choisissez d'utiliser un bucket de stockage, vous devez saisir le chemin source du bucket. Pour cet exemple d'entraînement, saisissez le nom de ce bucket dans
Chemin source . Cela renvoie directement vers un document.cloud-samples-data/documentai/Custom/Patents/PDF/computer_vision_20.pdfPour Répartition des données, sélectionnez Non attribué. Le document de ce dossier n'est attribué ni à l'ensemble de test, ni à l'ensemble d'entraînement. Ne cochez pas la case Importer avec l'étiquetage automatique.
Sélectionnez Importer. Document AI lit les documents du bucket dans l'ensemble de données. Il ne modifie pas le bucket d'importation et ne lit pas ses données une fois l'importation terminée.
Facultatif : Pour supprimer des documents importés, dans l'onglet Compiler, accédez à Gérer l'ensemble de données > sélectionnez les documents > cliquez sur Supprimer.
Dans l'onglet Compiler, sélectionnez Gérer l'ensemble de données > Modifier le schéma. La page Modifier le schéma s'ouvre.
Sélectionnez
Créer un libellé .Saisissez le nom de l'étiquette.
Sélectionnez Créer. Consultez la section Définir le schéma de l'outil de traitement pour obtenir des instructions détaillées sur la création et la modification d'un schéma.
Créez chacune des étiquettes suivantes pour le schéma de l'outil de traitement.
computer_visioncryptomed_techother
Sélectionnez
Enregistrer lorsque vos étiquettes sont créées.
Revenez à l'onglet Compiler, puis sélectionnez
un document pour ouvrir la console Gérer l'ensemble de données.Parmi les
options , sélectionnez l'étiquette appropriée pour le document. Si vous utilisez l'exemple de document fourni, sélectionnezcomputer_vision.Une fois étiqueté, le document devrait se présenter comme suit :

Sélectionnez
Marquer comme étiqueté lorsque vous avez terminé d'annoter le document.Dans l'onglet Gérer l'ensemble de données, le panneau Document indique qu'un document a été étiqueté.
Dans l'onglet Gérer l'ensemble de données, cochez la case
Tout sélectionner .Dans la liste
Attribuer à un ensemble , sélectionnez Entraînement.Sélectionnez
Importer des documents .Saisissez le chemin suivant dans
Chemin source . Ce bucket contient des documents préalablement étiquetés au format Document JSON.cloud-samples-data/documentai/Custom/Patents/JSON/Classification-InventionTypeDans la liste Répartition des données, sélectionnez Répartition automatique. Les documents sont automatiquement répartis de la manière suivante : 80 % dans l'ensemble d'entraînement et 20 % dans l'ensemble de test. Ignorez la section Appliquer des étiquettes.
Sélectionnez Importer. L'importation peut prendre plusieurs minutes.
Sélectionnez
Importer des documents .Saisissez le chemin suivant dans
Chemin source . Ce bucket contient des documents sans étiquettes au format PDF.cloud-samples-data/documentai/Custom/Patents/PDF-CDC-BatchLabelDans la liste Répartition des données, sélectionnez Répartition automatique. Les documents sont automatiquement répartis de la manière suivante : 80 % dans l'ensemble d'entraînement et 20 % dans l'ensemble de test.
Dans la section Appliquer des étiquettes, sélectionnez Sélectionner une étiquette.
Pour ces exemples de documents, sélectionnez
other.Sélectionnez Importer et attendez la fin du processus. Vous pouvez quitter cette page et y revenir plus tard. Lorsque vous avez terminé, les documents s'affichent dans l'onglet Gérer l'ensemble de données avec l'étiquette appliquée.
- Sélectionnez
Entraîner une nouvelle version . Dans le champ
Nom de la version , saisissez un nom pour cette version de l'outil de traitement (par exemple,my-cdc-version-1).Facultatif : Sélectionnez Afficher les statistiques relatives aux étiquettes pour afficher des informations sur les étiquettes des documents qui peuvent vous aider à déterminer votre couverture. Sélectionnez Fermer pour revenir à la configuration de l'entraînement.
Sélectionnez
Démarrer l'entraînement . Vous pouvez vérifier l'état dans le panneau latéral.Une fois l'entraînement terminé, accédez à l'onglet
Gérer les versions . Vous pouvez consulter les détails de la version que vous venez d'entraîner.Sélectionnez
à côté de la version que vous souhaitez déployer, puis sélectionnez Déployer la version. Sélectionnez
Déployer dans la boîte de dialogue.Le déploiement prend quelques minutes.
Une fois le déploiement terminé, accédez à l'onglet
Évaluer et tester .Sur cette page, vous pouvez consulter les métriques d'évaluation, y compris le score F1, la précision et le rappel pour le document complet, ainsi que des étiquettes individuelles. Pour en savoir plus sur l'évaluation et les statistiques, consultez Évaluer l'outil de traitement.
Téléchargez un document qui n'a pas été utilisé pour l'entraînement ou les tests précédents afin de pouvoir l'utiliser pour évaluer la version de l'outil de traitement. Si vous utilisez vos propres données, vous devez vous servir d'un document réservé à cette fin.
Sélectionnez
Importer le document de test , puis sélectionnez le document que vous venez de télécharger.La page Analyse du classificateur de documents personnalisé s'ouvre. Le résultat montre la classification du document.
Vous pouvez également réexécuter l'évaluation sur un autre ensemble de test ou une autre version de l'outil de traitement.
Sur la page Gérer l'ensemble de données, cliquez sur
Importer des documents .Copiez et collez le chemin d'accès Cloud Storage suivant. Ce répertoire contient cinq PDF de brevets sans étiquette. Dans la liste déroulante Répartition des données, sélectionnez Entraînement.
cloud-samples-data/documentai/Custom/Patents/PDF-CDC-AutoLabelDans la section Appliquer des étiquettes, sélectionnez Étiquetage automatique.
Sélectionnez une version existante de l'outil de traitement pour étiqueter les documents.
- Par exemple :
2af620b2fd4d1fcf
- Par exemple :
Sélectionnez Importer et attendez la fin du processus. Vous pouvez quitter cette page et y revenir plus tard. Une fois l'opération terminée, les documents apparaissent dans la section Étiquette automatique de la page Gérer l'ensemble de données.
Vous ne pouvez pas utiliser de documents étiquetés automatiquement pour l'entraînement ou les tests sans les marquer comme étiquetés. Accédez à la section
Étiquette automatique pour afficher les documents étiquetés automatiquement.Sélectionnez le premier document pour accéder à la console d'étiquetage.
Vérifiez que l'étiquetage est correct. Ajustez-le si ce n'est pas le cas.
Lorsque vous avez terminé, sélectionnez
Marquer comme étiqueté .Répétez la validation des étiquettes pour chaque document étiqueté automatiquement, puis revenez à la page Gérer l'ensemble de données pour attribuer les données d'entraînement.
Dans le menu de navigation de la console Google Cloud , sélectionnez Document AI, puis Mes processeurs.
Sur la ligne correspondant à l'outil de traitement que vous souhaitez supprimer, sélectionnez
Autres actions .Sélectionnez Supprimer le processeur, saisissez son nom, puis sélectionnez à nouveau Supprimer pour confirmer.
- Pour en savoir plus, consultez Guides.
- Consultez la liste des outils de traitement.
- Séparez les documents en fragments lisibles avec l'analyseur de mise en page.
- Utilisez Enterprise Document OCR pour détecter et extraire du texte.
Créer un outil de traitement
Procédez comme suit :
Configurer l'ensemble de données
Pour entraîner ce nouvel outil de traitement, vous devez créer un ensemble de données contenant des données d'entraînement et de test afin de l'aider à identifier les documents que vous souhaitez scinder et classer. Cet ensemble de données nécessite un nouvel emplacement. Il peut s'agir d'un bucket Cloud Storage ou d'un dossier vide, ou vous pouvez autoriser un emplacement géré en interne.
Lorsque l'onglet Détails de l'outil de traitement s'affiche, vous pouvez :

Importer des documents dans un ensemble de données
Vous allez ensuite importer vos documents dans votre ensemble de données.
Lorsque vous importez des documents, vous pouvez les attribuer aux ensembles d'entraînement ou de test définis lors de l'importation, ou attendre de les attribuer ultérieurement.
Pour en savoir plus sur la préparation de vos données pour l'importation, consultez le guide de préparation des données.
Définir le schéma de l'outil de traitement
Vous pouvez créer le schéma de l'outil de traitement avant ou après l'importation de documents dans votre ensemble de données. Le schéma fournit des étiquettes que vous utilisez pour annoter les documents.
Ajouter une étiquette à un document
Le processus de sélection de texte dans un document et d'application d'étiquettes est appelé annotation.
Attribuer un document annoté à l'ensemble d'entraînement
Maintenant que vous avez étiqueté cet exemple de document, vous pouvez l'attribuer à l'ensemble d'entraînement.
Dans le panneau Documents, vous pouvez voir qu'un document a été attribué à l'ensemble d'entraînement.
Importer des données préalablement étiquetées dans les ensembles d'entraînement et de test
Ce guide contient des données préalablement étiquetées. Si vous utilisez votre propre projet, vous devez déterminer comment étiqueter vos données. Consultez la section Options d'étiquetage.
Les outils de traitement personnalisés de Document AI nécessitent au moins un document dans les ensembles d'entraînement et de test pour chaque type de document à étiqueter. Pour des performances optimales, nous vous recommandons d'avoir au moins 10 documents pour chaque étiquette. Pour cinq étiquettes, vous aurez besoin de 50 documents pour l'entraînement et de 50 documents pour les tests. En général, plus la quantité de données d'entraînement est importante, plus la justesse est élevée.
Une fois l'importation terminée, vous trouverez les documents dans l'onglet Gérer l'ensemble de données.
Étiqueter plusieurs documents lors de l'importation
Une fois le schéma configuré, vous pouvez éventuellement gagner du temps en étiquetant tous les documents situés dans un répertoire spécifique lors de l'importation.

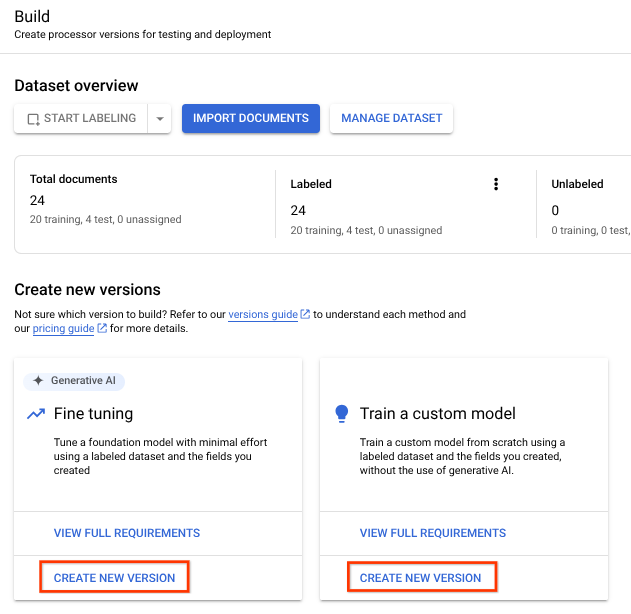
Entraîner l'outil de traitement
Maintenant que vous avez importé les données d'entraînement et de test, vous pouvez entraîner l'outil de traitement. Comme l'entraînement peut prendre plusieurs heures, assurez-vous d'avoir configuré l'outil de traitement avec les données et étiquettes appropriées avant de commencer l'entraînement.
Vous pouvez entraîner des modèles affinés et personnalisés avec vos données étiquetées. Les modèles affinés utilisent l'IA générative. Les modèles personnalisés entraînent un grand modèle de langage unique à l'aide de vos données étiquetées. Vous devez disposer d'au moins deux étiquettes dans le schéma, avec un minimum de 10 documents d'entraînement et 10 documents de test (1 au minimum).
Déployer la version de l'outil de traitement
Évaluer et tester l'outil de traitement
Étiqueter automatiquement les nouveaux documents importés
Après avoir déployé une version d'outil de traitement entraînée, vous pouvez utiliser l'étiquetage automatique pour gagner du temps sur l'étiquetage lorsque vous importez de nouveaux documents.
Utiliser l'outil de traitement
Vous pouvez gérer les versions de votre outil de traitement entraîné personnalisé comme n'importe quelle autre version. Pour en savoir plus, consultez Gérer les versions de l'outil de traitement.
Vous pouvez envoyer une requête de traitement à votre outil de traitement personnalisé. La réponse peut être traitée de la même manière que pour les autres outils de classification.
Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cette démonstration soient facturées sur votre compte Google Cloud , procédez comme suit :