Un ensemble de données de documents étiqueté est requis pour entraîner, surentraîner ou évaluer une version de l'outil de traitement.
Cette page explique comment appliquer des libellés du schéma de votre processeur aux documents importés dans votre ensemble de données.
Dans cette page, nous partons du principe que vous avez déjà créé un processeur compatible avec l'entraînement, le surentraînement ou l'évaluation. Si votre processeur est compatible, l'onglet Entraînement s'affiche dans la console Google Cloud . Il suppose également que vous avez créé un ensemble de données, importé des documents et défini un schéma de processeur.
Champs de nom pour l'extraction d'IA générative
La façon dont les champs sont nommés a une incidence sur la précision de leur extraction à l'aide de l'IA générative. Nous vous recommandons de suivre les bonnes pratiques suivantes lorsque vous nommez des champs :
Nommez le champ dans la même langue que celle utilisée pour le décrire dans le document. Par exemple, si un champ d'un document est décrit comme
Employer Address, nommez-leemployer_address. N'utilisez pas d'abréviations telles queemplr_addr.Les espaces ne sont actuellement pas acceptés dans les noms de champs : utilisez
_à la place. Par exemple,First Namesera nomméfirst_name.Itérer sur les noms pour améliorer la précision : Document AI présente une limite qui ne permet pas de modifier les noms de champs. Pour tester différents noms, utilisez l'outil de changement de nom d'entité pour remplacer l'ancien nom d'entité par un nouveau dans l'ensemble de données, importez l'ensemble de données, activez les nouvelles entités dans le processeur, puis désactivez ou supprimez les champs existants.
Apprentissage zero-shot et few-shot
Les modèles avec Gemini disposent d'un apprentissage zero-shot et few-shot, ce qui permet de créer des modèles très performants avec peu ou pas de données d'entraînement.
L'apprentissage zero-shot est un exemple de machine learning dans lequel un modèle pré-entraîné sans entraînement supplémentaire apprend à reconnaître et à classer des classes et des entités qu'il n'a jamais rencontrées auparavant lors des tests.
L'apprentissage few-shot est une méthode qui permet à un modèle d'apprendre à reconnaître et à classer de nouvelles classes et entités avec seulement quelques exemples d'entraînement par classe. Il exploite les connaissances issues de modèles pré-entraînés sur de grands ensembles de données bien étiquetés pour améliorer les performances des tâches few-shot.
L'apprentissage few-shot devient plus efficace lorsque l'ensemble de données d'entraînement est propre et soigneusement étiqueté. En règle générale, cela signifie qu'il faut disposer d'au moins 10 exemples de test et 10 exemples d'entraînement pour que le modèle puisse apprendre.
Options de libellé
Voici les options dont vous disposez pour étiqueter des documents :
Manuelle : étiquetez manuellement vos documents dans la console Google Cloud
Étiquetage automatique : utilisez une version de processeur existante pour générer des étiquettes.
Importer des documents pré-étiquetés : gagnez du temps si vous disposez déjà de documents étiquetés.
Ajouter manuellement des libellés dans la console Google Cloud
Dans l'onglet Entraînement, sélectionnez un document pour ouvrir l'outil d'étiquetage.
Dans la liste des libellés de schéma sur la gauche de l'outil d'étiquetage, sélectionnez le symbole "Ajouter" pour choisir l'outil Cadre de sélection. Il vous permet de mettre en évidence les entités dans le document et de leur attribuer un libellé.
Dans la capture d'écran suivante, des libellés ont été attribués aux champs EMPL_SSN, EMPLR_ID_NUMBER, EMPLR_NAME_ADDRESS, FEDERAL_INCOME_TAX_WH, SS_TAX_WH, SS_WAGES et WAGES_TIPS_OTHER_COMP du document.
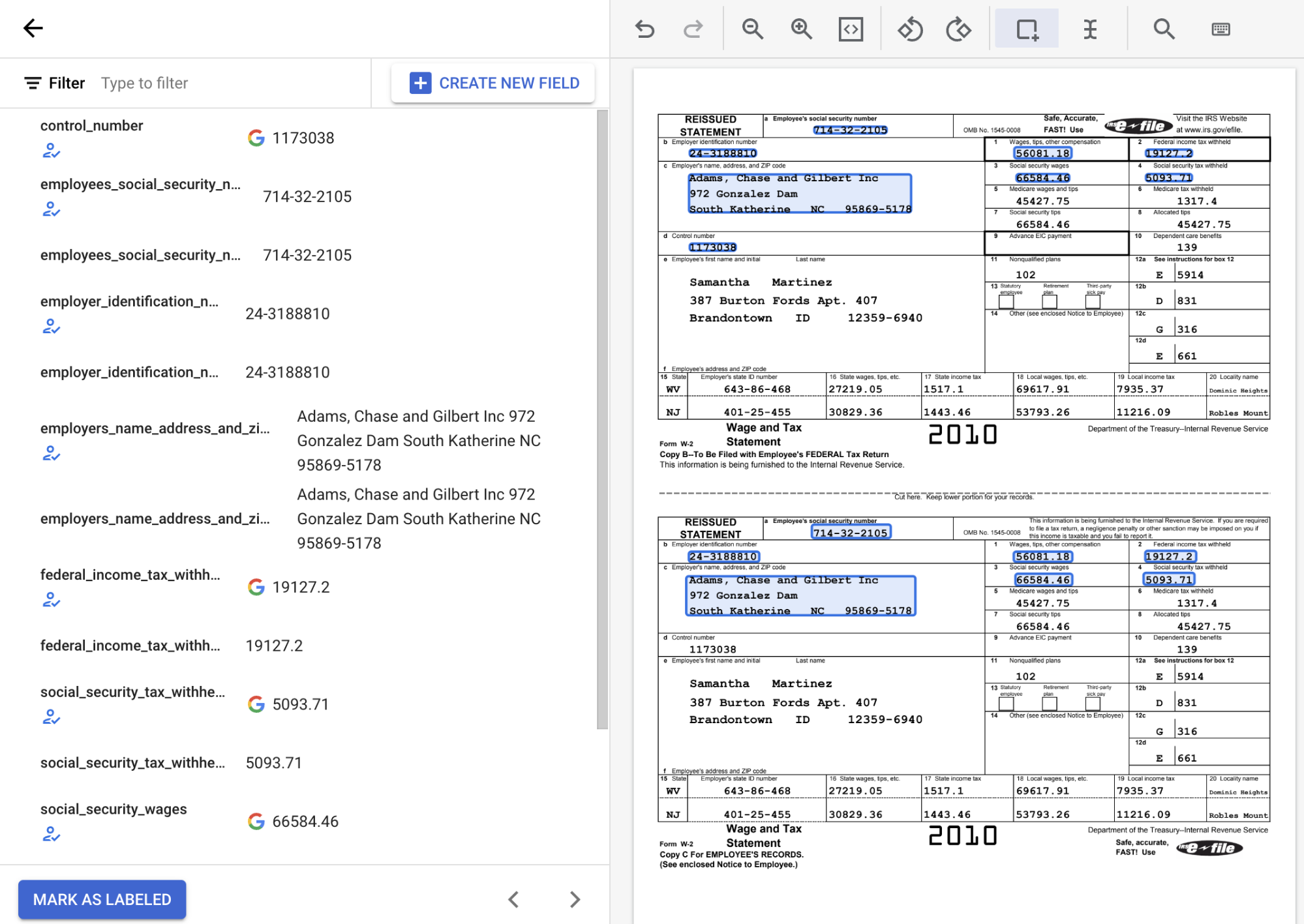
Lorsque vous sélectionnez une entité de case à cocher avec l'outil Cadre de délimitation, ne sélectionnez que la case à cocher elle-même, et non le texte associé. Assurez-vous que la case à cocher affichée à gauche est cochée ou décochée en fonction de ce qui figure dans le document.

Lorsque vous étiquetez des entités parent-enfant, n'étiquetez pas les entités parentes. Les entités parentes ne sont que des conteneurs pour les entités enfants. N'étiquetez que les entités enfants. Les entités parentes sont mises à jour automatiquement.
Lorsque vous labellisez des entités enfants, labellisez la première entité enfant, puis associez les entités enfants associées à cette ligne. Vous le remarquerez au niveau de la deuxième entité enfant la première fois que vous labellisez de telles entités. Par exemple, avec une facture, si vous libellez description, cela ressemble à n'importe quelle autre entité. Toutefois, si vous ajoutez le libellé quantité, vous êtes invité à sélectionner le parent.
Répétez cette étape pour chaque ligne en sélectionnant Nouvelle entité parente.
Les entités parent-enfant sont acceptées pour les tableaux comportant jusqu'à trois niveaux d'imbrication. Les modèles de fondation acceptent trois niveaux de champs (grand-parent, parent, enfant). Les entités enfants peuvent donc avoir un niveau d'enfants. Pour en savoir plus sur l'imbrication, consultez Imbrication à trois niveaux.
Tableaux récapitulatifs
Lorsque vous étiquetez un tableau, il peut être fastidieux d'étiqueter chaque ligne encore et encore. Il existe un outil très pratique qui peut répliquer la structure d'une entité de ligne. Notez que cette fonctionnalité ne fonctionne que sur les lignes alignées horizontalement.
- Commencez par libeller la première ligne comme d'habitude.
Pointez ensuite sur l'entité parente représentant la ligne. Sélectionnez Ajouter des lignes. La ligne devient un modèle permettant de créer d'autres lignes.
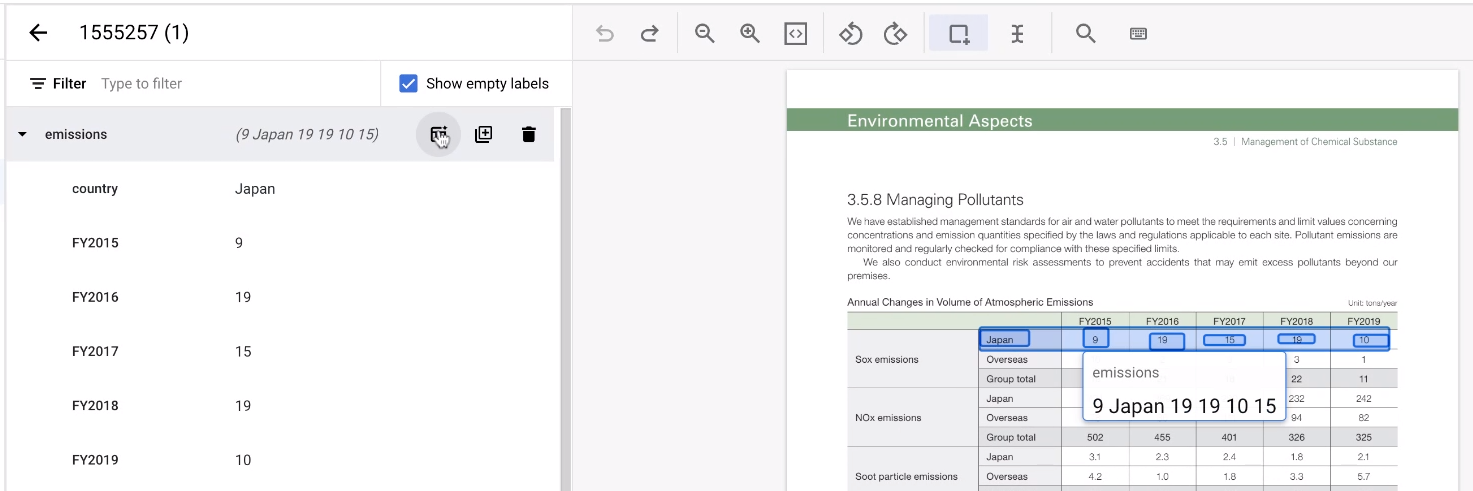
Sélectionnez le reste de la zone du tableau.
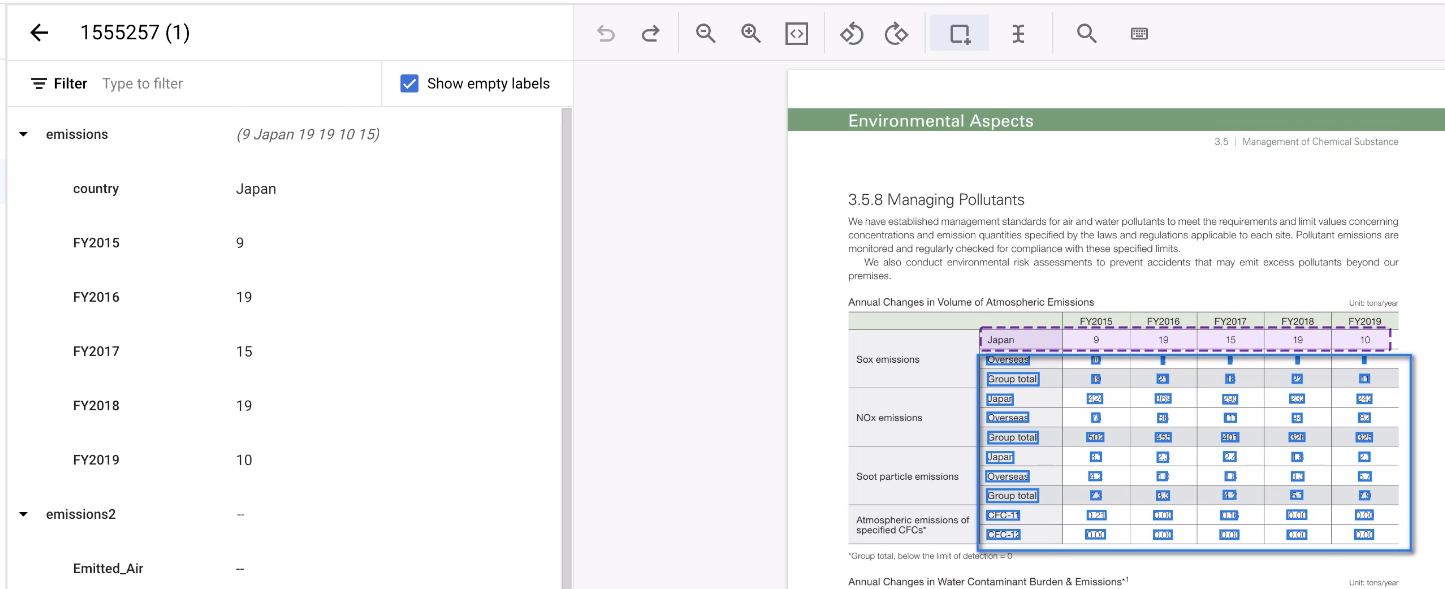
L'outil devine les annotations, et cela fonctionne généralement. Pour toutes les tables qu'il ne peut pas gérer, annotez-les manuellement.
Utiliser les raccourcis clavier dans la console
Pour afficher les raccourcis clavier disponibles, sélectionnez le menu en haut à droite de la console d'annotation. Elle affiche une liste de raccourcis clavier, comme indiqué dans le tableau suivant.
| Action | Raccourci |
|---|---|
| Zoom avant | Alt+ = (Option+ = sur macOS) |
| Zoom arrière | Alt+- (Option+- sur macOS) |
| Zoomer pour ajuster | Alt+0 (Option+0 sur macOS) |
| Faire défiler pour zoomer | Alt+Molette (Option+Molette sur macOS) |
| Panoramique | Défilement |
| Panoramique inversé | Maj+Défilement |
| Faire glisser pour effectuer un panoramique | Espace+faire glisser la souris |
| Annuler | Ctrl+Z (Ctrl+Z sur macOS) |
| Répéter | Ctrl+Maj+Z (Ctrl+Maj+Z sous macOS) |
Étiqueter automatiquement
Si la fonction est disponible, vous pouvez commencer à ajouter des étiquettes en utilisant une version existante de votre processeur.
L'étiquetage automatique peut être lancé lors de l'importation. Tous les documents sont annotés à l'aide de la version du processeur spécifiée.
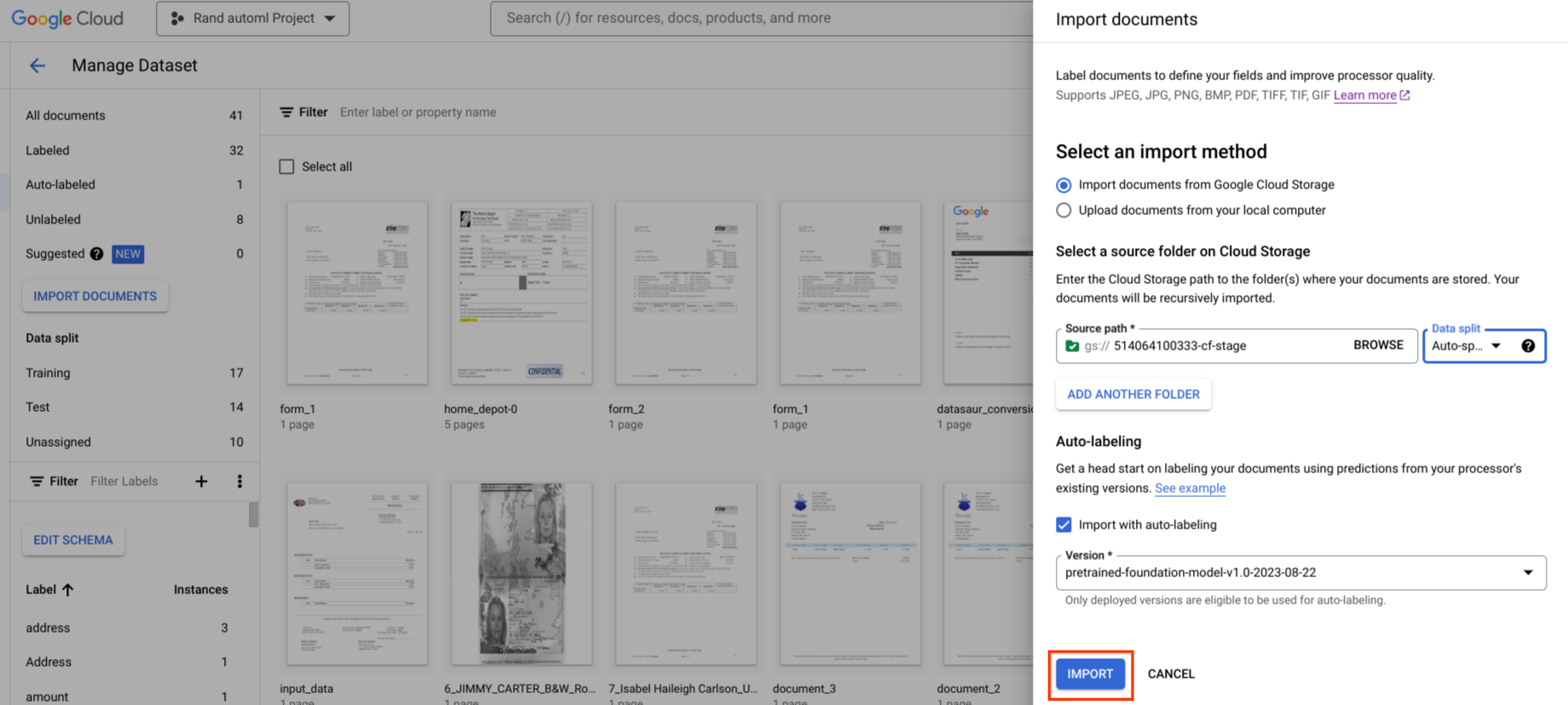
L'étiquetage automatique peut être lancé après l'importation des documents dans la catégorie "Sans étiquette" ou "Étiquette automatique". Tous les documents sélectionnés sont annotés à l'aide de la version du processeur spécifiée.
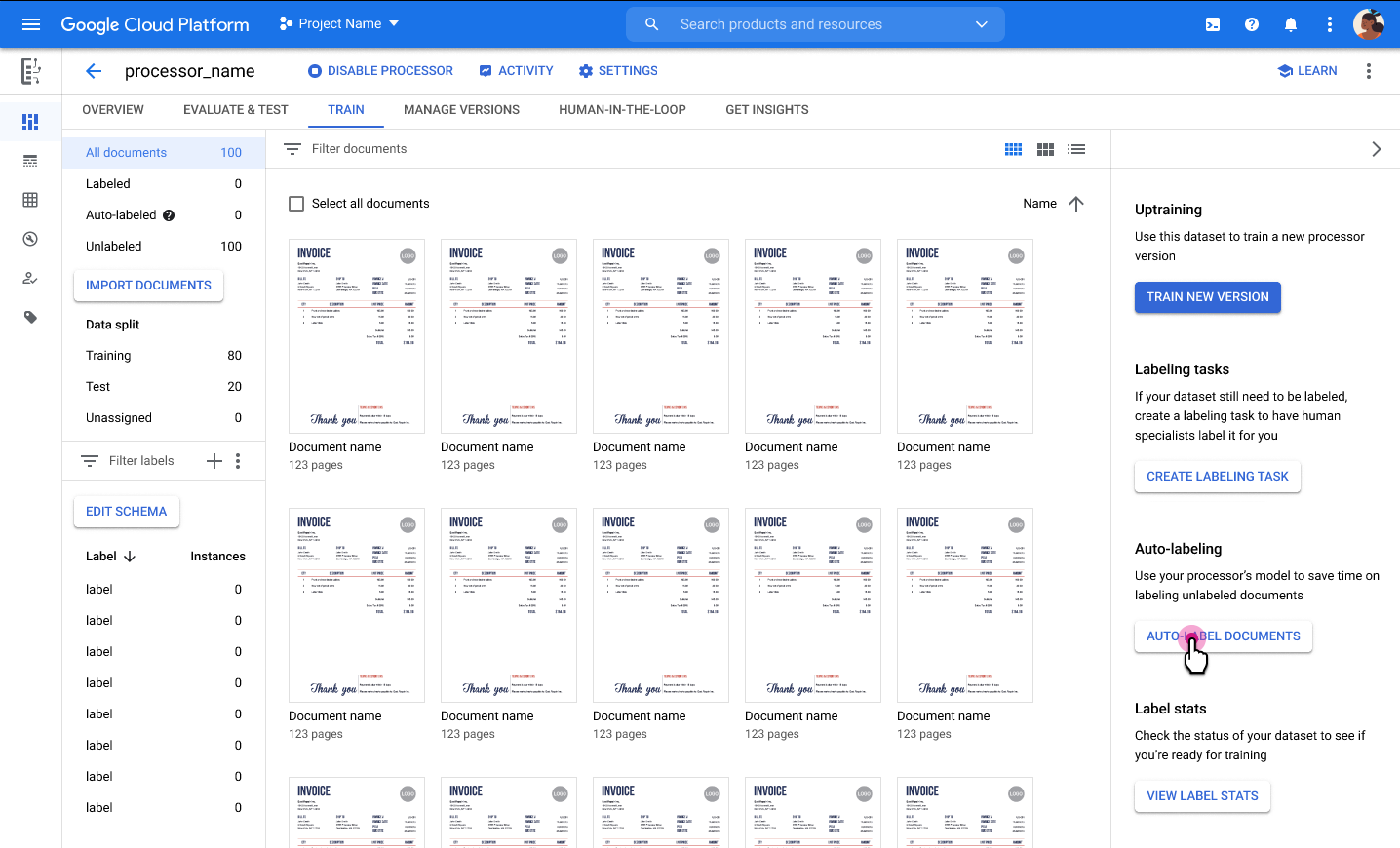
Vous ne pouvez pas entraîner ni surentraîner de documents étiquetés automatiquement, ni les utiliser dans l'ensemble de données de test, sans les marquer comme étiquetés. Examinez et corrigez manuellement les annotations étiquetées automatiquement, puis sélectionnez Marquer comme étiqueté pour enregistrer les corrections. Vous pouvez ensuite attribuer les documents selon vos besoins.
Importer des documents pré-étiquetés
Vous pouvez importer des fichiers JSON Document. Si le entity du document correspond au libellé du schéma du processeur, l'importateur convertit le entity en instance de libellé. Vous pouvez obtenir des fichiers de document JSON de plusieurs façons :
Exporter un ensemble de données depuis un autre processeur Consultez Exporter un ensemble de données.
Envoyer une demande de traitement à un processeur existant.
Utilisez le kit d'importation pour convertir les libellés existants provenant d'un autre système (par exemple, les libellés au format CSV) en documents JSON.
Bonnes pratiques pour étiqueter les documents
Un étiquetage cohérent est nécessaire pour entraîner un processeur de haute qualité. Nous vous recommandons de :
Créez des instructions d'étiquetage : vos instructions doivent inclure des exemples pour les cas courants et les cas limites. Voici quelques conseils :
- Expliquez quels champs doivent être annotés et comment étiqueter les données de manière cohérente. Par exemple, lorsque vous ajoutez un libellé "montant", indiquez si le symbole de la devise doit être libellé. Si les libellés ne sont pas cohérents, la qualité du processeur est réduite.
- Étiquetez toutes les occurrences d'une entité, même si le type d'étiquette est
REQUIRED_ONCEouOPTIONAL_ONCE. Par exemple, siinvoice_idapparaît deux fois dans le document, labellisez toutes les occurrences. - En général, il est préférable d'utiliser d'abord l'outil de cadre de délimitation par défaut. En cas d'échec, utilisez l'outil de sélection de texte.
- Si la valeur du libellé n'est pas correctement détectée par l'OCR, ne la corrigez pas manuellement. Cela le rendrait inutilisable à des fins d'entraînement.
Voici quelques exemples d'instructions de classification :
- Analyseur de relevés bancaires
- Analyseur de fournisseurs d'énergie
- Analyseur de bulletins de salaire
- Analyseur de dépenses
- Analyseur de factures
- Former les annotateurs : assurez-vous que les annotateurs comprennent les consignes et peuvent les suivre sans commettre d'erreurs systématiques. Pour ce faire, vous pouvez demander à différents utilisateurs en formation d'annoter le même ensemble de documents. Le formateur peut ensuite vérifier la qualité du travail d'annotation de chaque stagiaire. Vous devrez peut-être répéter ce processus jusqu'à ce que les modèles atteignent un niveau de précision de référence.
- Examens initiaux : les premiers documents (une dizaine) associés à un cas d'utilisation par un nouveau responsable de l'étiquetage doivent être examinés avant qu'un grand nombre de documents ne soient étiquetés. Cela permet d'éviter un grand nombre d'erreurs qui devront être corrigées.
- Examens de la qualité des annotations : étant donné la nature laborieuse des annotations, même les annotateurs formés peuvent faire des erreurs. Nous vous recommandons de faire vérifier les annotations par au moins un autre annotateur qualifié.
Ajouter une description
Lorsque vous ajoutez des libellés au schéma dans l'extracteur et le classificateur personnalisés, vous pouvez ajouter une description pour le libellé. Cela permet d'entraîner le processeur en fournissant une requête permettant d'identifier le libellé. Vous pouvez essayer de légères variations pour tester la qualité de la réponse. Par exemple, "montant total", "montant total de la facture" ou "montant total de la facture".
Resynchroniser l'ensemble de données
La resynchronisation permet de maintenir la cohérence entre le dossier Cloud Storage de votre ensemble de données et l'index interne des métadonnées de Document AI. Cette option est utile si vous avez accidentellement modifié le dossier Cloud Storage et que vous souhaitez synchroniser les données.
Pour resynchroniser :
Dans l'onglet Détails du processeur, à côté de la ligne Emplacement de stockage, sélectionnez , puis Resynchroniser l'ensemble de données.
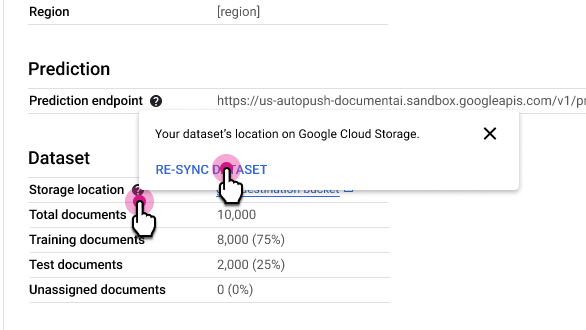
Remarques concernant l'utilisation :
- Si vous supprimez un document du dossier Cloud Storage, la resynchronisation le supprime de l'ensemble de données.
- Si vous ajoutez un document au dossier Cloud Storage, la resynchronisation ne l'ajoute pas à l'ensemble de données. Pour ajouter des documents, importez-les.
- Si vous modifiez les libellés de documents dans le dossier Cloud Storage, la resynchronisation met à jour les libellés de documents dans l'ensemble de données.
Migrer un ensemble de données
L'importation et l'exportation vous permettent de déplacer tous les documents d'un ensemble de données d'un processeur à un autre. Cela peut être utile si vous avez des processeurs dans différentes régions ou différents projets Google Cloud , si vous avez des processeurs différents pour la mise en scène et la production, ou pour la consommation hors connexion générale.
Notez que seuls les documents et leurs libellés sont exportés. Les métadonnées du jeu de données, telles que le schéma du processeur, les affectations de documents (entraînement/test/non attribué) et l'état d'étiquetage des documents (étiqueté, non étiqueté, étiqueté automatiquement) ne sont pas exportées.
La copie et l'importation de l'ensemble de données, puis l'entraînement du processeur cible ne sont pas exactement identiques à l'entraînement du processeur source. En effet, des valeurs aléatoires sont utilisées au début du processus d'entraînement. Utilisez l'appel d'API importProcessorVersion pour importer et migrer exactement le même modèle entre les projets. Il s'agit d'une bonne pratique pour la migration des processeurs vers des environnements de niveau supérieur (par exemple, du développement à la préproduction, puis à la production) si les règles l'autorisent.
Exporter l'ensemble de données
Pour exporter tous les documents sous forme de fichiers JSON Document vers un dossier Cloud Storage, sélectionnez Exporter l'ensemble de données.
Quelques remarques importantes :
Lors de l'exportation, trois sous-dossiers sont créés : Test, Train et Unassigned. Vos documents sont placés dans ces sous-dossiers en conséquence.
L'état de classification d'un document n'est pas exporté. Si vous importez les documents ultérieurement, ils ne seront pas marqués comme libellés automatiquement.
Si votre Cloud Storage se trouve dans un autre projet Google Cloud , assurez-vous d'accorder l'accès afin que Document AI soit autorisé à écrire des fichiers à cet emplacement. Plus précisément, vous devez attribuer le rôle Créateur d'objets Storage à l'agent de service principal de Document AI
service-{project-id}@gcp-sa-prod-dai-core.iam.gserviceaccount.com. Pour en savoir plus, consultez Agents de service.
Importer un ensemble de données
La procédure est la même que pour Importer des documents.
Guide de l'utilisateur pour l'étiquetage sélectif
L'étiquetage sélectif vous aide à identifier les documents à étiqueter. Vous pouvez créer des ensembles de données d'entraînement et de test diversifiés pour entraîner des modèles représentatifs. Chaque fois qu'un étiquetage sélectif est effectué, les documents les plus diversifiés (jusqu'à 30) de l'ensemble de données sont sélectionnés.
Obtenir des suggestions de documents
Créez un processeur CDE et importez des documents.
- Au moins 100 sont nécessaires pour l'entraînement (25 pour les tests).
- Une fois que vous avez importé suffisamment de documents et effectué un étiquetage sélectif, la barre d'informations devrait s'afficher.
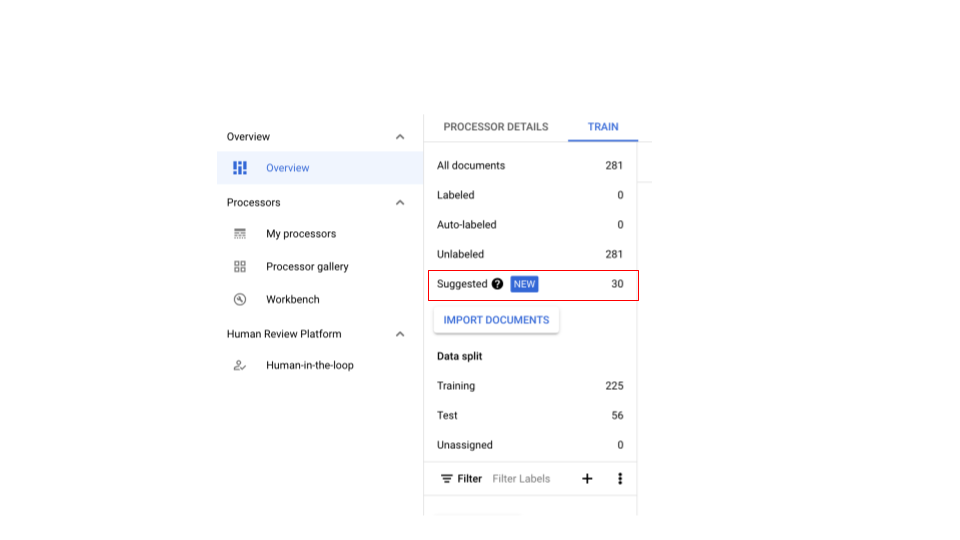
Si le processeur CDE ne suggère aucun document, importez-en d'autres pour avoir suffisamment de documents dans chaque fraction pour l'échantillonnage.
- Cela devrait activer les documents suggérés dans la catégorie "Suggestions". Vous devriez pouvoir demander manuellement les documents suggérés.
- Un nouveau filtre en haut de page vous permet de filtrer les documents suggérés.
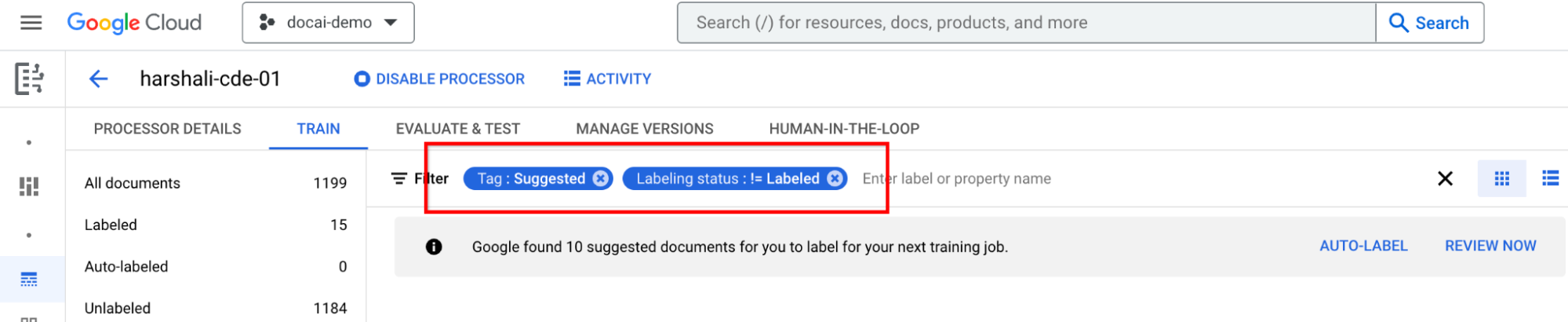
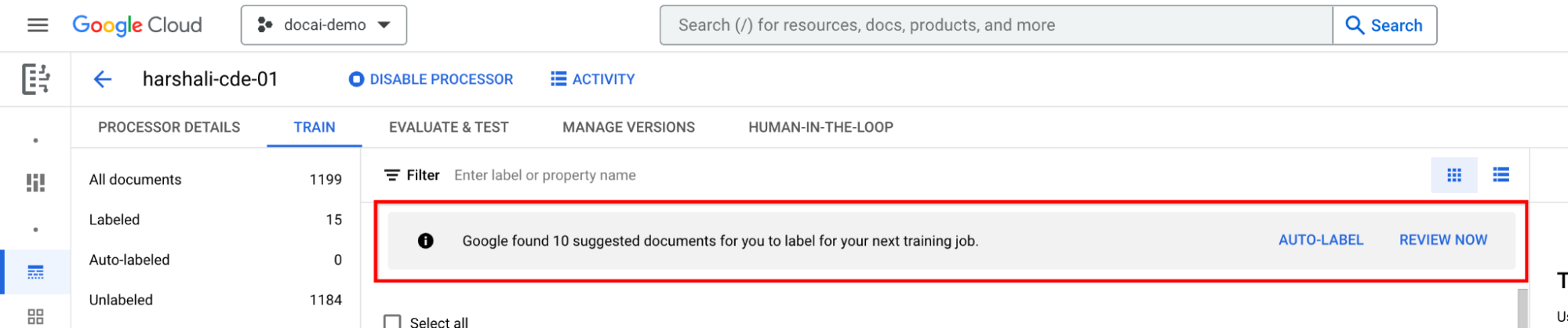
Étiqueter les documents suggérés
Accédez à Catégorie suggérée dans le panneau de liste des libellés à gauche. Commence à étiqueter ces documents.
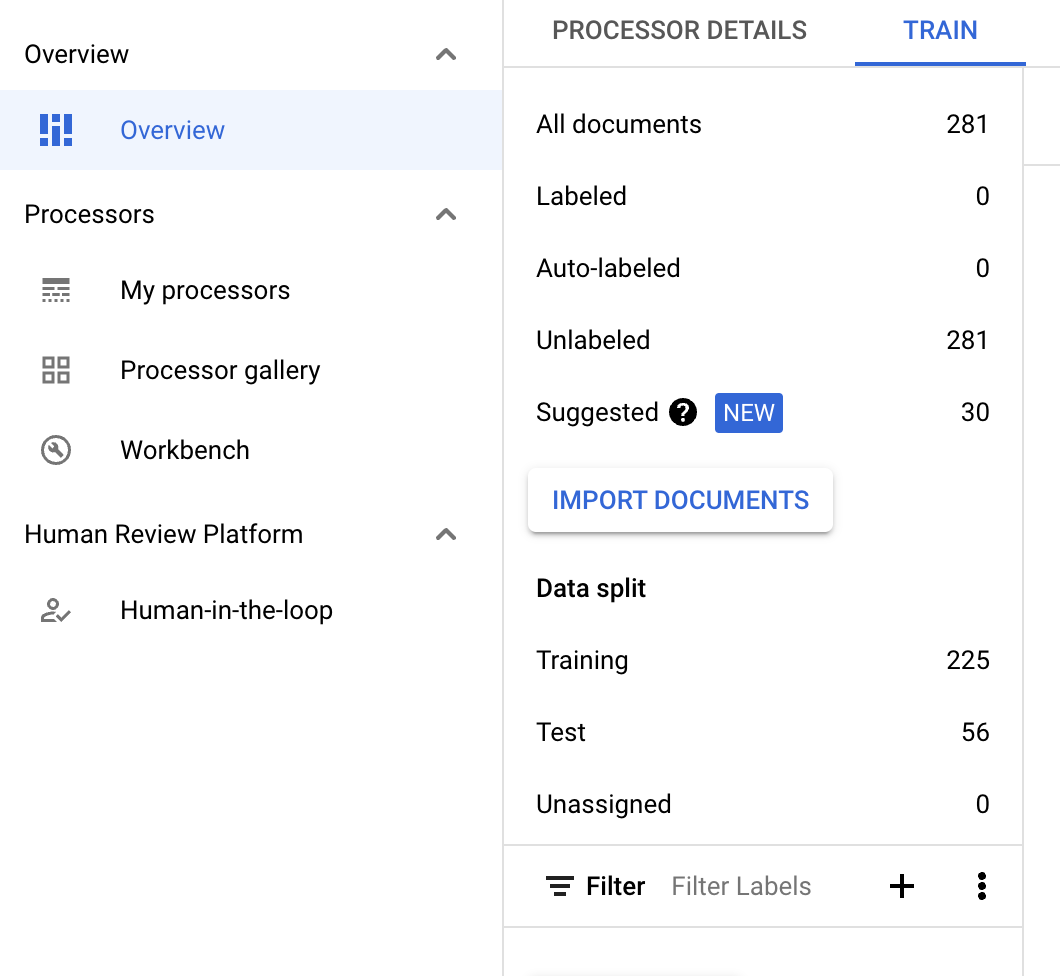
Sélectionnez Étiquetage automatique dans la barre d'informations si le processeur est entraîné. Étiquetez les documents suggérés.
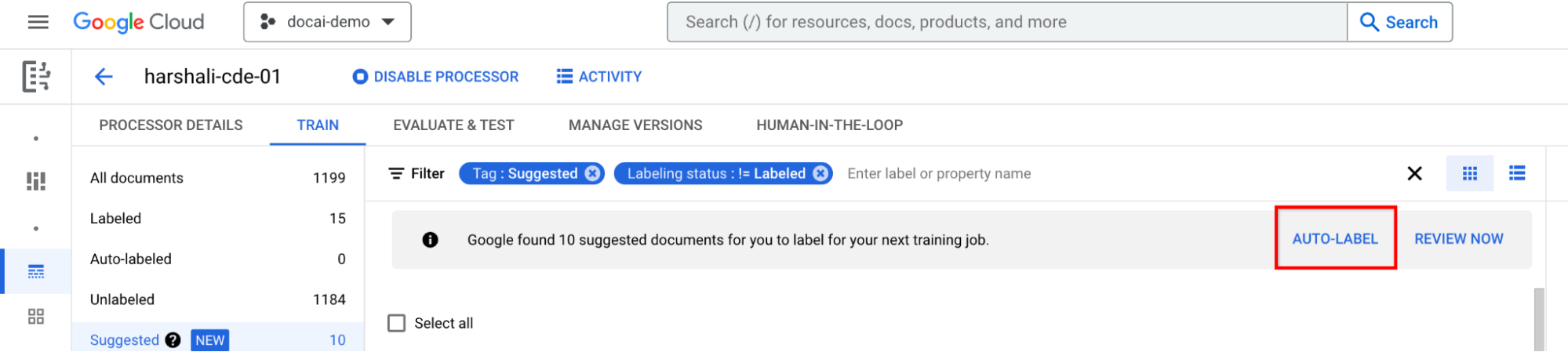
Vous pouvez ensuite sélectionner Examiner maintenant dans la barre lorsque des documents suggérés sont disponibles dans le processeur pour y accéder. Tous les documents étiquetés automatiquement doivent être vérifiés pour s'assurer de leur exactitude. Commencez l'examen.
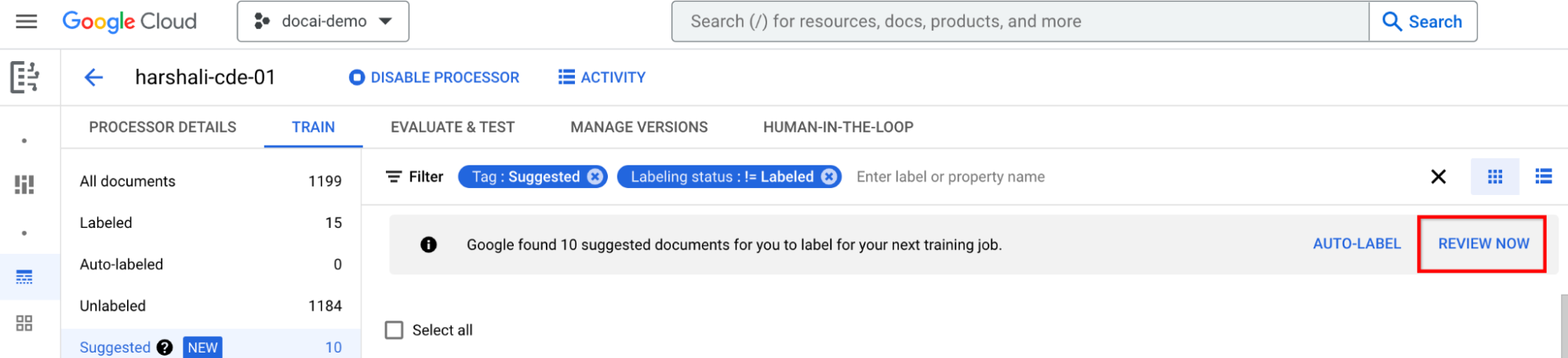
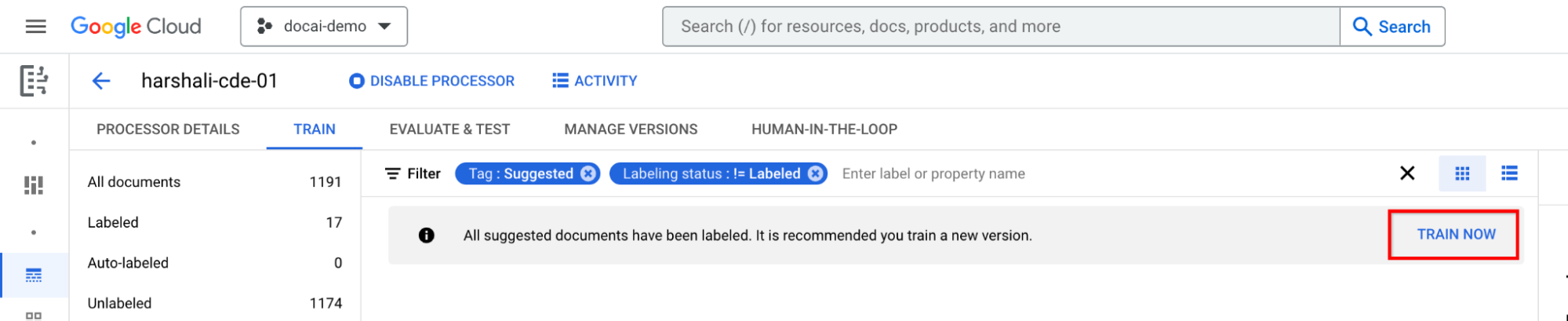
Entraîner après avoir étiqueté tous les documents suggérés
Accédez à Entraîner maintenant dans la barre d'informations. Lorsque les documents suggérés sont libellés, la barre d'informations suivante s'affiche pour vous recommander de suivre une formation.
Fonctionnalités et limites
| Fonctionnalité | Description | Compatible |
|---|---|---|
| Compatibilité avec les anciens processeurs | Peut ne pas fonctionner correctement avec les anciens processeurs et les ensembles de données importés précédemment |